Redisson sentinel模式下"is not active"问题的分析与解决
背景
- RedisConnection is not active是个大坑是个Bug,在某些情况下必定出现,而且这些情况还挺常见
- 测试过的版本有2.5.1,3.8.1,3.8.2,据说更高的版本仍旧存在
- 单从日志上面分析,很难定位该问题的原因,不知道原因也就没法重现问题,但问题总是时不时出现,真是压力山大
- 最后多亏有两位牛人相助,RuBing & Kevin,终于攻破了此难题
Sentinel模式下的类关系图

上图列出的方法和字段只是一部分,是需要特别注意的地方。下面叙述的时候,如无特殊说明,ReadMode默认为SLAVE。
类图说明:
- Redisson 实现了 RedissonClient 接口(上图省略),它拥有一个ConnectionManager,其类型是根据配置来决定的,在 Sentinel 模式下,ConnectionManager 的类型为 SentinelConnectionManager
- RedisClient 负责解析地址,创建 Netty 的 Channel 和 RedisConnection
- Netty 的 Channel 具有自愈能力,能自动重连。当发现没法连接到 remote host 时,它的状态会变成 not active,但它会不断地尝试重连,一旦连上,那么又会变回 active 状态。如果 Channel 被显式关闭,则不会再重连,状态也会一直处于 not active。
- RedisConnection 提供发送 Redis 命令的功能,每个 RedisConnection 都有一个独立的 Netty Channel。
- ClientConnectionsEntry 对应一个 Master 或者 Slave 节点,提供新建 Connection 和从可用队列(freeConnections)中获取 Connection 的功能,它包含了
- 连接到某个节点的所有 Connection 的队列(allConnections)
- 当前可用的 Connection 队列(freeConnections,它是 allConnections 的子集)
- 节点状态(freezed 还是 unfreezed)
- 第一次发现 Connection 不可用的时间(firstFailTime,非常重要,后面会说)
- ConnectionPool 是对 ClientConnectionsEntry 的一个整合,分成 MasterConnectionPool 和 SlaveConnectionPool。
- MasterConnectionPool 只包含一个 ClientConnectionsEntry,也就是对应 master 节点,注意,这个 pool 提供的 Connection,绝大多数情况下都是用于写数据到 Redis 的,但是当 slaveEntry(Slave 对应的 ClientConnectionsEntry)被down掉的时候,slaveEntry 上面未完成的命令将会转交给这个 pool 来继续执行;
- SlaveConnectionPool 包含多个 ClientConnectionsEntry,对应每个 Slave 节点,除此之外,还包含一个对应 master 节点的 ClientConnectionsEntry,这个 entry 是用于从 master 读取数据的。一般情况下它都处于 freezed 状态,但是当其他所有 slaveEntry 都被 freezed 时,它就会被 unfreeze,然后用作 slave 提供读取服务(为了叙述方便,称其为 readMasterEntry)。
- LoadBalancerManager 拥有一个 SlaveConnectionPool,提供对 slaveEntry 进行 freeze 和 unfreeze 的功能。unfreeze 会重置 slaveEntry 的 firstFailTime。
- MasterSlaveEntry 拥有一个 LoadBalancerManager(间接支配了 SlaveConnectionPool)和一个 MasterConnectionPool,提供对 slaveEntry 进行 slaveDown 和 slaveUp 的功能:
- slaveDown 会通过 LoadBalancerManager 对 slaveEntry 进行 freeze,然后把 slaveEntry 所有 Connection 都关闭,但并不从移除;如果发现所有 slaveEntry 都 down 了,则会 unfreeze readMasterEntry(如果Slave 都不可用,就从 Master 读);
- slaveUp 会通过 LoadBalancerManager 对 slaveEntry 进行 unfreeze,如果发现有 slaveEntry 处于 unfreezed 状态,则 freeze readMasterEntry(如果Slave 可用,就只从 Slave 读)。
- SentinelConnectionManager 继承了 MasterSlaveConnectionManager,实现了 ConnectionManager 接口。它的作用是:
- 根据配置连接上 Sentinel,获取 Master,Slave 和 Sentinel 的信息;
- 初始化 MasterSlaveEntry;
- 启动调度,定时连接 Sentinel,获取 Master 和 Slave 的信息,更新 masterEntry 和 slaveEntry 的状态(包括变更 masterEntry,增加新的 slaveEntry,调用 MasterSlaveEntry 上的 slaveDown 和 slaveUp)
关键过程解说
从 ConnectionPool 获取连接
- 遍历 ConnectionPool 中的所有 ClientConnectionsEntry,找出第一个可用的 entry
- 可用的 entry 需要满足以下条件:
- entry 没有被 freeze
- entry 被 freezed,但是配置了 ReadMode=MASTER_SLAVE(这个 entry 是 readMasterEntry,意味着允许从 master 读取)
- entry 可以获取 Connection。判定能够获取 Connection 的条件是:
- entry 对应的节点是 Master
- entry 对应的节点是 Slave,但是 entry 没有 failed(下面会介绍 entry failed)。
- 从可用 entry 的 freeConnections 中尝试 poll 一个 Connection 出来:
- 如果 poll 不到,则新建一个 Connection 并加入到 entry 的 allConnections 中(新建成功的话)
- 如果 poll 到了 Connection,则检查 Connection 是否 active:
- active == true && entry 对应的节点为 Slave,则调用 entry 的 resetFirstFail(重置 entry firstFailTime 为0),这个操作可以使原来被判定为 failed 的 entry,变成 not failed(具体查看下面 entry failed 的说明)
- active == false && entry 对应的节点为 Slave:
- 尝试设置 currTime(当前时间) 到 entry 的 firstFailTime(firstFailTime != 0的时候跳过)
- 如果 entry is failed,则关闭连接,对该 entry 调用 MasterSlaveEntry#slaveDown(具体参考上面 MasterSlaveEntry 的介绍)。注意,这里没有把 is not active & closed 的 Connection 归还,也就是说该 Connection 已从 freeConnections 里面移除了
- 如果 entry is not failed,则归还 Connection 到 entry 的 freeConnections
- active == false && entry 对应的节点为 Master,则归还 Connection 到 entry 的 freeConnections
- 可用的 entry 需要满足以下条件:
- 如果所有 entry 都不可用就报错
- 如果有 entry 处于 freezed 状态,则错误信息包含:"Disconnected hosts: " + freezedHosts
- 如果有 entry is failed,则错误信息包含:"Hosts disconnected due to errors during
failedSlaveCheckInterval: " + failedHosts - 错误信息可以同时包含以上两条
entry failed 的说明
之前在介绍 ClientConnectionsEntry 的时候说过 entry 包含了一个字段 firstFailTime(第一次发现 Connection 不可用的时间),entry failed 的判定就是用到了这个字段。
当以下条件满足,则认定 entry is failed:
firstFailTime != 0 && currentTime - firstFailTime > failedSlaveCheckInterval
(failedSlaveCheckInterval 可配置,在3.8.1版本默认是60s)。
firstFailTime 一旦被设置了,后面对它的更新都不会有效,除非通过 resetFirstFail 让它先重置为0,因此,上面的条件所表达的意思是:
在 failedSlaveCheckInterval 时间段内(60s),entry 的 Connection 都没有从 not active 变回 active 状态(Connection 底下的 Netty Channel 具有自愈能力,具体参考上面的介绍),意味着远端节点很可能已经 down了(当然,网络不通也被看成是 down 了)。
SentinelConnectionManager 的 updateState
SentinelConnectionManager 在初始化的最后一步做的是启动调度,定时连接 sentinel(3.8.1版本的调度间隔为1s),然后调用 updateState 方法。
updateState 的过程:
- 从 sentinel 查询 Master 的地址,如果发现 Master 变更了,则删除旧的 masterEntry,重建一个新的 masterEntry;
- 如果允许从 Slave 读取(本篇上下文默认允许),则从 sentinel 查询所有 Slave 的信息:
- 如果 Slave 的 flags 包含有 “s_down” 或者 “disconnected”,则表示 Slave 不可用,查找对应其地址的 slaveEntry,并调用 MasterSlaveEntry#slaveDown
- 如果 Slave 可用,则检查该地址是否已有对应的 slaveEntry
- 如果没有,就创建一个对应的 slaveEntry
- 如果有,则尝试对该 slaveEntry 调用 MasterSlaveEntry#slaveUp(如果 slaveEntry 本身处于 unfreezed 状态,将忽略 slaveUp,具体查看上面 slaveUp 的介绍)
- 计算出有哪些 slaveEntry 没有出现在 Sentinel 返回的 Slave 列表中,表示这些 slaveEntry 所对应的 Slave 节点很可能已经被移除,因此需要对这些 slaveEntry 调用 MasterSlaveEntry#slaveDown。
- 从 Sentinel 查询最新的 Sentinel 信息列表,更新状态。
“is not active” 问题分析
由于过程太复杂,采用的技巧太多,发散面太广,这里将直接给出分析结果。
简化后的规则
- Connection 的状态:
- 没有关闭时,能连上 => is active
- 没有关闭时,连不上 => is not active
- 关闭后 => is not active
- 如何选择 slaveEntry 获取 Connection:
- unfreezed
- READ_MODE == MASTER_SLAVE(本篇忽略此条件)
- (对应节点为 Slave && entry not failed) || 对应节点为 Master
- ConnectionPool 检查 slaveEntry 是否可用时:
- unfreezed && failed => slaveDown,并且认为不可用
- slaveDown 的影响:
- slaveEntry 状态 unfreezed -> freezed
- slaveEntry close all connections
- slaveUp 的影响:
- slaveEntry 状态 freezed -> unfreezed
- slaveEntry resetFirstFail(重置 firstFailTime 为0)
- 从 freeConnections 中获取的 Connection,当处于 is not active 时:
- 对应节点为 Master => 归还到 freeConnections
- 对应节点为 Slave =>
- 尝试设置 firstFailTime
- entry is failed => close Connection,尝试 slaveDown entry
- entry is not failed => 归还到 freeConnections
- entry failed 的计算:
- firstFailTime != 0 && currentTime - firstFailTime > failedSlaveCheckInterval
- SentinelConnectionManager 周期性地查询 Sentinel,通过 slaveDown 和 slaveUp 更新 slaveEntry 状态
问题定位
- 当 Slave 不可用时,Sentinel 马上就能知道,从 Sentinel 上查询到的 Slave flags 会带有 “s_down”, "disconnected"等
- 只要1s,SentinelConnectionManager 通过 Sentinel 就能知道 Slave 不可用,从而发起 slaveDown(通过 MasterSlaveEntry),把对应的 slaveEntry 的 allConnections 全部关闭(freeConnections 是 allConnections 的子集)
- 如果这时候从 ConnectionPool 获取 Connection,这个 slaveEntry 是会被跳过的(slaveDown 把它的状态设置成了 freezed)
- 后来 Slave 又可用了,SentinelConnectionManager 顶多隔了1s,就通过 Sentinel 知道了这个变化,然后把对应的 slaveEntry 进行 slaveUp,slaveEntry 状态从 freezed 变回 unfreezed
- 再次从 ConnectionPool 获取 Connection 时,这个 slaveEntry 又可以被选中了,但是它的 allConnections 之前已经全部被关闭,freeConnections 是 allConnections 的子集,也就是说,从 freeConnections 中 poll 到的 Connection,状态永远处于 “is not active”,于是报错。又因为 slaveEntry is not failed(unfreeze 重置了 firstFailTime),于是该 Connection 又再次被归还到 freeConnections 中。
- 接下来,只要从这个 slaveEntry 获取 Connection,都会报错:“is not active”
问题来了
问题1:
Connection is not active 出现后,会设置 firstFailTime,只要等到超过 failedSlaveCheckInterval,entry 就会被判定为 failed,按照上面规则 6.2.2,Connection 最后是不会被归还到 freeConnections 中的,但事实并非如此,为什么?
解答:
判定 entry 是否 failed,最早是在 ConnectionPool 选择 slaveEntry 时进行的,参考规则 3,该 entry 会被 slaveDown,并且不会作为候选者提供 Connection。再参考规则 8,因为当前 Slave 是可用的,所以1s后 SentinelConnectionManager 会把该 slaveEntry 重新进行 slaveUp,按照规则 5,firstFailTime 会被重置,于是 entry 被判定为 is not failed。绝大多数情况下,规则 6.2.2其实是无法进入的。
问题2:
- shutdown Slave
- 等待 slaveDown 对应的 slaveEntry(close all connections)
- restart Slave
- 等待 slaveUp 对应的 slaveEntry
- 从 ConnectionPool 获取 Connection 会报错:“is not active”
按照以上步骤,绝大多数情况下可以重现问题,但有时却不出现,为什么?
解答:
在我的实验环境里:
- 2个 Sentinel,1个 Master(port:6379) 和1个 Slave(port:6380)
- READ_MODE=SLAVE
- Redisson 只读取数据
SentinelConnectionManager 的日志如下:
####<2019-08-16 17:25:04.407> -
####<2019-08-16 17:25:04.425> -
####<2019-08-16 17:25:04.426> -
####<2019-08-16 17:25:04.426> -
####<2019-08-16 17:25:04.656> -
####<2019-08-16 17:25:04.656> -
####<2019-08-16 17:25:04.656> -
####<2019-08-16 17:25:04.656> -
####<2019-08-16 17:25:04.663> - <1 connections initialized for 127.0.0.1/127.0.0.1:6379>
####<2019-08-16 17:25:04.663> -
####<2019-08-16 17:25:04.666> -
####<2019-08-16 17:25:04.667> - <5 connections initialized for 127.0.0.1/127.0.0.1:6379>
从日志可以看出,Sentinel 返回的信息里面显示 Slave “flags=s_down,slave,disconnected”,但实际上 Slave 那时候是可用的,不清楚 Sentinel 为什么会这样。根据上面的类图说明可知,当前的 slaveEntry 其实是处于 freezed 中的,所以不会新建和初始化任何 Connection。当没有可用的 slaveEntry 时,readMasterEntry 会被用作 slaveEntry,所以 Connection 都是来自于 readMasterEntry 的。这时候shutdown Slave,根据规则8,是要 slaveDown slaveEntry 的,但是因为它本身就已经处于 freezed 状态,所以会跳过。接着 startup Slave,根据规则8,slaveEntry 会被 slaveUp,于是它会初始化它的 ConnectionPool,这时候才开始创建 Connection,新建的 Connection 当然不会有问题了。
如果现在再做多一次上述步骤,那么 “is not active” 问题就会重现了。
问题3:
如果把 SentinelConnectionManager 查询 Sentinel 的调度间隔从1s改成20s,然后 Slave 从 shutdown 到 restart 的时间间隔 < 20s,那么还会出现 “is not active” 问题吗?
解答:
以下用 T1,T2 表示 Slave shutdown,restart 完成的时间点,T3 表示 SentinelConnectionManager#updateState 发生的时间点。
- T2 - T1 < 60s (failedSlaveCheckInterval),所以 ConnectionPool 不可能发起 slaveDown,但是由于 Netty Channel 感知到了 Slave 连接不上,所以 Connection 会暂时处于 is not active 状态,一段时间内报错。
- T3 < T1 || T3 >= T2,SentinelConnectionManager 感知不到 Slave 状态的变化,因此不会发起 slaveDown,allConnections 不会被关闭,等到 Slave 可用后,Netty Channel 会重连成功,Connection 会再次变回 active 状态。
- T1 <= T3 < T2,SentinelConnectionManager 可以感知到 Slave 不可用,从而发起 slaveDown,根据规则4,allConnections 都被关闭,Connection 永远处于 “is not active” 状态。等到 Slave 再次可用后,slaveEntry 会被 slaveUp,当从它那里获取 Connection 时,就会一直报错:“is not active”。
解决办法
分析那么多,原因其实就是 slaveDown 的时候,allConnections 关闭了,但是关闭了的 Connection 没有从 allConnections 和 freeConnections 移除掉。
方法1
修改 ClientConnectionsEntry 的源码,如果发现从 freeConnections poll 出来的 Connection 已经 closed,就重新 poll 一次。
public RedisConnection pollConnection() {
RedisConnection conn;
while (true) {
conn = freeConnections.poll();
if (conn == null || !conn.isClosed())
return conn;
else {
allConnections.remove(conn);
logger.debug("{} is closed, remove it, after remove: {}", conn, this);
}
}
}
方法2
- 修改 ClientConnectionsEntry 源码,新增一个方法:
public void removeRedisConnection(RedisConnection conn) {
freeConnections.remove(conn);
allConnections.remove(conn);
}
- 修改 MasterSlaveEntry 源码,在 slaveDown 关闭 allConnections 之后,调用1新增的方法移除 Connection
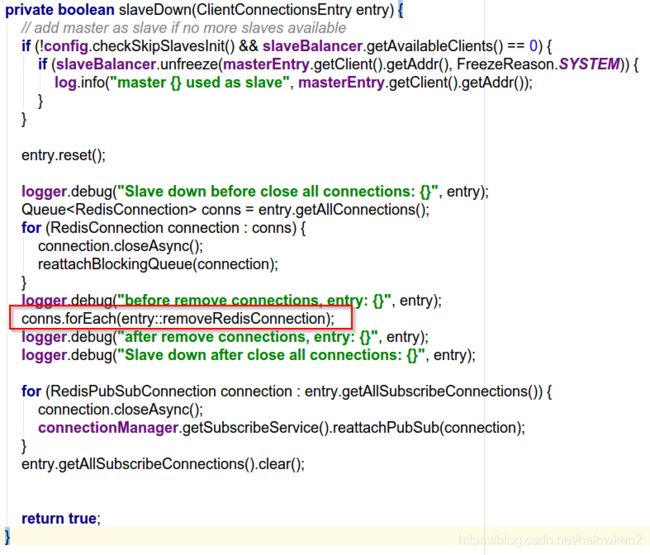
方法3
升级 Redisson 版本到 3.11.2,据 Redisson 作者说,他在这个版本修复了,我只是稍微测试了一下,发现是没有这个问题了(slaveDown 的时候把 allConnections 和 freeConnections 都清空了),但是不知道有木有引入其他 Bug。
方法4
把 READ_MODE 改成 MASTER。当处于这个模式的时候,不会创建任何 slaveEntry,只创建了一个 masterEntry 对外提供读写。当发现 Master 发生变更后,masterEntry 会被重建,所有 Connection 也重新创建。
以下用 T1 表示 Master down 的时刻,T2 表示 Sentinel 切换 Slave 成为 Master 的时刻。
[T1, T2) => 所有读写都失败。
[T2, ) => Redisson 把原来的 masterEntry 删掉,创建 newMasterEntry 对应原来的 Slave 节点,然后使用 newMasterEntry 对外提供读写。