指针笔试题
目录
一维数组
1
2
3
4
二维数组
辨析题
1
2
3
4
5
一维数组
1
数组名是数组首元素的地址 但是有2个例外: 1. sizeof(数组名) - 数组名表示整个数组,计算的是整个数组的大小,单位是字节 2. &数组名 - 数组名也表示整个数组,取出的是整个数组的地址
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));//16,a作为数组名单独放在sizeof内部,计算的是数组的总大小,单位是字节
printf("%d\n", sizeof(a + 0));//a并非单独放在sizeof内部,也没有&,所以数组名a就是数组首元素的地址
//a+0还是数组首元素的地址,是地址大小就是 4/8 个字节
printf("%d\n", sizeof(*a));//a是首元素的地址,*a就是首元素,sizeof(*a)就算的就是首元素的大小 - 4
printf("%d\n", sizeof(a + 1));//a是首元素的地址,a+1是第二个元素的地址,sizeof(a+1)计算的是指针的大小 - 4/8
printf("%d\n", sizeof(a[1]));//a[1]就是数组的第二个元素,sizeof(a[1])的大小 - 4个字节
printf("%d\n", sizeof(&a));//&a取出的数组的地址,数组的地址,也是地址,sizeof(&a)就是 4/8 个字节
printf("%d\n", sizeof(*&a));//&a是数组的地址,是数组指针类型,*&a是都数组指针解引用,访问一个数组的大小
//16字节
//sizeof(*&a) ==> sizeof(a) =16
printf("%d\n", sizeof(&a + 1));//&a数组的地址,&a+1跳过整个数组,&a+1还是地址,是 4/8 个字节
printf("%d\n", sizeof(&a[0]));//a[0]是数组的第一个元素,&a[0]是第一个元素的地址,是 4/8 个字节
printf("%d\n", sizeof(&a[0] + 1));//&a[0]是第一个元素的地址,&a[0]+1就是第二个元素的地址,是 4/8 个字节2
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr));//随机值,arr是数组名,但是没有放在sizeof内部,也没&,arr就是首元素的地址
//strlen得到arr后,从arr数组首元素的地方开始计算字符串的长度,直到\0,但是arr数组中没有\0,arr内存的后边是否有\0,在什么位置
//是不确定的,所以\0之前出现了多少个字符是随机的。
printf("%d\n", strlen(arr + 0));//arr是数组首元素的地址,arr+0还是首元素的地址
//随机值
printf("%d\n", strlen(*arr));//arr是数组首元素的地址,*arr 是首元素 - ‘a’ - 97
/*strlen就把‘a’的ASCII码值 97 当成了地址
err 会非法访问内存*/
printf("%d\n", strlen(arr[1]));//arr[1] - 'b' - 98 - err
printf("%d\n", strlen(&arr));//随机值,&arr是数组的地址,数组的地址也是指向数组起始位置,和第一个案例一样
printf("%d\n", strlen(&arr + 1));//随机值,数组指针不兼容
printf("%d\n", strlen(&arr[0] + 1));//随机值
printf("%d\n", sizeof(arr));//arr是数组名,并且是单独放在sizeof内部,计算的是数组总大小,单位是字节 - 6
printf("%d\n", sizeof(arr + 0));//arr是数组名,并非单独放在sizeof内部,arr表示首元素的地址,arr+0还是首元素的地址
//是地址大小就是4/8
printf("%d\n", sizeof(*arr));//arr是首元素的地址,*arr就是首元素,sizeof计算的是首元素的大小,是1字节
printf("%d\n", sizeof(arr[1]));//arr[1]是数组的第二个元素,sizeof(arr[1])计算的是第二个元素的大小,1个字节
printf("%d\n", sizeof(&arr));//&arr- 取出的是数组的地址,sizeof(&arr))计算的是数组的地址的大小,是地址就是4/8字节
printf("%d\n", sizeof(&arr + 1));//&arr是数组的地址,&arr+1跳过整个数组,指向'f'的后边,&arr+1的本质还是地址,是地址就是4/8字节
printf("%d\n", sizeof(&arr[0] + 1));//&arr[0]是‘a’的地址,&arr[0]+1是'b'的地址,是地址就是4/8字节其中:
printf("%d\n", strlen(&arr + 1));是数组指针类型,而strlen的参数是const char* 类型,编译时可能会报错,我们可以这样写:
printf("%d\n", strlen((char*)(&arr + 1)));//随机值
区分sizeof(&arr + 1)和strlen(*arr):
按理说两者都访问了不该访问的地址,为什么只有后者报错?我们可以把前者的行为比作去银行门口看一眼,访问的是数组后的一块有效的未初始化空间,并没有访问其数据,是不会有任何问题的。而后者是一块未定义的空间,所以会崩溃。
3
char arr[] = "abcdef";
printf("%d\n", strlen(arr));//6
printf("%d\n", strlen(arr + 0));//6
printf("%d\n", strlen(*arr));//非法访问
printf("%d\n", strlen(arr[1]));//非法访问
printf("%d\n", strlen(&arr));//6
printf("%d\n", strlen(&arr + 1));//随机值
printf("%d\n", strlen(&arr[0] + 1));//5
printf("%d\n", sizeof(arr));//7
printf("%d\n", sizeof(arr + 0));// 4/8
printf("%d\n", sizeof(*arr));//1
printf("%d\n", sizeof(arr[1]));//1
printf("%d\n", sizeof(&arr));// 4/8
printf("%d\n", sizeof(&arr + 1)); // 4/8
printf("%d\n", sizeof(&arr[0] + 1)); //4/84
const char* p = "abcdef";
printf("%d\n", strlen(p));//6
printf("%d\n", strlen(p + 1));//5
printf("%d\n", strlen(*p));//非法访问
printf("%d\n", strlen(p[0]));//非法访问
printf("%d\n", strlen(&p));//随机值
printf("%d\n", strlen(&p + 1));//随机值
printf("%d\n", strlen(&p[0] + 1));//5
printf("%zu\n", sizeof(p));// 4/8
printf("%zu\n", sizeof(p + 1));// 4/8
printf("%zu\n", sizeof(*p));//1
printf("%zu\n", sizeof(p[0]));//1
printf("%zu\n", sizeof(&p));// 4/8,二级指针
printf("%zu\n", sizeof(&p + 1));// 4/8
printf("%zu\n", sizeof(&p[0] + 1)); // 4/8
为什么strlen(&p)是随机值呢?
假设p的地址为0x12345600,在小端模式机器下得到的值就是0,当strlen获得p的地址时,会一个字节一个字节向后访问,直到取到0,所以是随机值。

二维数组
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));//a是二维数组的数组名,数组名单独放在sizeof内部,计算的是数组的总大小,单位是字节
//48
printf("%d\n", sizeof(a[0][0]));//a[0][0]是一个整型元素,大小是4个字节
printf("%d\n", sizeof(a[0]));//把二维数组的每一行看做一维数组的时候,a[0]是第一行的数组名,第一行的数组名单独放在sizeof内部
//计算的是第一行的总大小,单位是字节 - 16
printf("%d\n", sizeof(a[0] + 1));//a[0]虽然是第一行的数组名,但是并非单独放在sizeof内部
//a[0]作为第一行的数组名并非表示整个第一行这个数组,a[0]就是第一行首元素的地址,a[0]--> &a[0][0] - int*
//a[0]+1,跳过一个int,是a[0][1]的地址 4/8字节
printf("%d\n", sizeof(*(a[0] + 1)));//a[0]+1是第一行第二个元素的地址,所以*(a[0]+1)就是a[0][1],大小是4个字节
printf("%d\n", sizeof(a + 1));//a是二维数组的数组名,没单独放在sizeof内部,也没有&,所以a就是数组首元素的地址
//二维数组,我们把它想象成一维数组,它的第一个元素就是二维数组的第一行
//a就是第一行的地址,a+1 是第二行的地址,是地址,大小就是 4/8 个字节
//a - &a[0]
//a+1 - &a[1]
//a+2 - &a[2]
printf("%d\n", sizeof(*(a + 1)));//a+1是第二行的地址,*(a+1) 找到的就是第二行,sizeof(*(a + 1))计算的就是第二行的大小
//16
//*(a+1) --> a[1]
//sizeof(*(a + 1)) --> sizeof(a[1])
//
printf("%d\n", sizeof(&a[0] + 1));//&a[0]是第一行的地址,&a[0]+1就是第二行的地址,sizeof(&a[0] + 1)计算的第二行地址大小
//单位是字节 - 4/8
printf("%d\n", sizeof(*(&a[0] + 1)));//&a[0] + 1是第二行的地址,*(&a[0] + 1)拿到的就是第二行,大小就是16个字节
//*(&a[0]+1) --> a[1]
printf("%d\n", sizeof(*a));//a表示首元素的地址,就是第一行的地址 - &a[0]
//*a - 拿到的就是第一行 - 大小就是16个字节
//*a -> *(a+0) -> a[0]
//
printf("%d\n", sizeof(a[3]));//代码没问题
//a[3]是二维数组的第4行,虽然没有第四行,但是类型能够确定,大小就是确定的。大小就是一行的大小,单位是字节 - 16
//能够分析出 a[3]的类型是:int [4]任何一个表达式有2个属性——值属性和类型属性,越界无法判断值但可以判断类型。
sizeof在程序编译过程执行表达式的运算,所以里边并不会对值进行动态地运算。
short num = 20;
int a = 1;
printf("%d", sizeof(num = a + 5));//只会取得表达式类型,a+5提升为int,通过截断存放到short里
//2字节辨析题
1
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);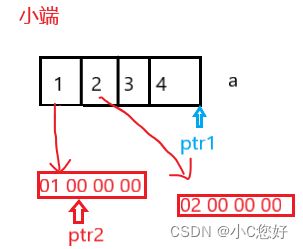
*ptr2得到4个字节(整形),注意小端模式下取出的值也要倒过来。%x打印(值打印)区别于地址的16进制打印会省略前面多余的0和0X。
2
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
//int a[3][2] = {{0,1}, {2,3}, {4,5}};
int* p;
p = a[0];
printf("%d", p[0]);区分{}和(),()里为逗号表达式,而{}能规定二维数组里的一维数组初始化顺序。
把一行想象成一维数组,a[0]等价于拿到了一维数组的数组名,用p接收得到首元素地址。
p[0]意为对首元素解引用得到1。
3
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);p是能储存一行4个int类型的数组指针,当它接收二维数组a的数组名时,它能访问的元素个数取决于p的类型而不是a。

指针-指针结果为相差的元素个数,所以结果是:FFFFFFFC(-4补码按16进制地址格式打印),-4
4
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
pa指向指针数组a的首元素地址,+1跳过一个指针,通过解引用得到char*类型存放地址的内容。
5
const char* c[] = { "ENTER","NEW","POINT","FIRST" };
const char** cp[] = { c + 3,c + 2,c + 1,c };
const char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);这里连续三个const是因为字符串常量最好由指向常量的指针接收,并且与它相关联的指针或指针数组都得加上cosnt防止修改字符串常量以保持权限一致 。
区分:
char arr[][4] = { "acv","cc" };
char(*a)[4] = arr;
*(*(a + 1) + 0) = 'a';
printf("%s", a[1]);数组里的每个元素都是char类型,可以被修改。
int a = 0;
const int* p = &a;
const int** pp = &p;
**pp = 2;//ERR
*pp = NULL;//正确进入正题,我们先来画出程序的指向关系: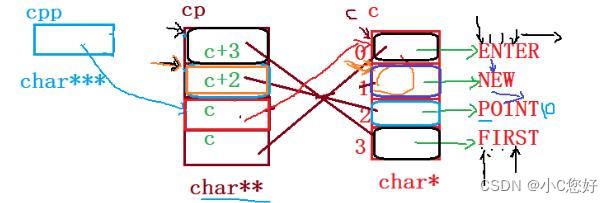
注意cpp的指向会被++改变,而printf("%s\n", *-- * ++cpp + 3); 这段代码看似等价于>>>printf("%s\n", *--(c+1) + 3);
>>>++cpp;
实则等价于:
>>>printf("%s\n", *--(cp[2]) + 3);
>>>++cpp;
前者--是修改了数组的首地址c,而后者修改了cp[2]里的元素,而cpp修改的是指针变量,所以不能直接用(c+1)这种方式。