【Linux】第七章 进程控制(进程创建+进程终止+进程等待+进程替换+min_shell)
个人主页:企鹅不叫的博客
专栏
- C语言初阶和进阶
- C项目
- Leetcode刷题
- 初阶数据结构与算法
- C++初阶和进阶
- 《深入理解计算机操作系统》
- 《高质量C/C++编程》
- Linux
⭐️ 博主码云gitee链接:代码仓库地址
⚡若有帮助可以【关注+点赞+收藏】,大家一起进步!
系列文章
【Linux】第一章环境搭建和配置
【Linux】第二章常见指令和权限理解
【Linux】第三章Linux环境基础开发工具使用(yum+rzsz+vim+g++和gcc+gdb+make和Makefile+进度条+git)
【Linux】第四章 进程(冯诺依曼体系+操作系统+进程概念+PID和PPID+fork+运行状态和描述+进程优先级)
【Linux】第五章 环境变量(概念补充+作用+命令+main三个参数+environ+getenv())
【Linux】第六章 进程地址空间(程序在内存中存储+虚拟地址+页表+mm_struct+写实拷贝+解释fork返回值)
文章目录
- 系列文章
- 一、进程创建
-
- 1.fork函数
- 2.写时拷贝
- 二、进程终止
-
- 1.程序退出码
- 2.程序退出方法
-
- 程序退出的几种状态
- exit()和_exit()
- slab 分配器
- 三、进程等待
-
- 1.程序等待的必要性
- 2.进程等待方法(重要)
-
- wait
- waitpid
- 3.status参数
- 4.阻塞等待和非阻塞等待
-
- 阻塞等待
- 非阻塞等待
- 四、进程替换(重点)
-
- 1.替换原理
- 2.替换函数-记得包含头文件
-
- execl
-
- 参数
- 返回值
- execv
- execlp
- execvp
- execle和execve
-
- 用C程序调用C++程序打印换进变量
- 导入环境变量
- 系统接口execve
- 3.函数命名总结
- 五、做一个shell
一、进程创建
1.fork函数
#includepid_t fork(void);//pid_t就是int类型 返回值:子进程中返回0,父进程返回子进程id,出错返回-1
- 将父进程部分数据拷贝给子进程(写时拷贝):环境变量,当前工作目录
- 操作系统会给子进程分配一个新的内存块
mm_struct+页表和内核数据结构task_strcut给子进程- 子进程添加到进程列表
- fork 返回,开始调度
- fork创建子进程就是在内核中通过调用clone实现
fork之前只有父进程单独运行。fork之后父子进程的执行流会分别执行,且相互独立,是父进程先执行还是子进程先执行依赖于调度器的调度,并非一定是父进程先执行。子进程虽然共享父进程的所有代码,但是它只能从fork之后开始执行,在 CPU 里面有一种寄存器eip程序计数器(又称PC指针)能保存当前的执行进度,通过保存当前正在执行指令的下一条指令,拷贝给子进程,子进程就会从该eip所指向的代码处(即fork之后的代码)开始运行
2.写时拷贝
为什么要写时拷贝?详情看这里 传送门
- 父进程的代码和数据,子进程不一定全部都会使用。即便使用、也不一定会进行修改
- 理想状态下,可以把父子进程会修改的内容进行分离,不会修改的部分共享即可。但是这样的实现非常复杂
- 如果fork的时候,就直接分离父子进程的数据,会增加fork运行的时间复杂度和空间复杂度
只会在需要的时候,拷贝父子需要修改的数据。这样延迟拷贝,变相提高了内存的使用率
二、进程终止
1.程序退出码
main函数结束时会return 0,这个0就是程序退出码
查看当前程序的退出码
echo $? // $? 就是 bash 中最近一次执行完毕时对应的进程退出码
利用以下程序打印一下库函数中
strerrror函数内记录的错误码#include#include int main() { int i=0; for(i=0;i<134;i++) { printf("[%d] %s\n",i,strerror(i)); } return 0; } 以下是部分错误码,发现返回0代表成功,其他都是异常
[Jungle@VM-20-8-centos:~/lesson14_进程控制]$ ./main [0] Success [1] Operation not permitted [2] No such file or directory [3] No such process [4] Interrupted system call [5] Input/output error [6] No such device or address [7] Argument list too long [8] Exec format error [9] Bad file descriptor [10] No child processes [11] Resource temporarily unavailable [12] Cannot allocate memory [13] Permission denied [14] Bad address [15] Block device required [16] Device or resource busy [17] File exists [18] Invalid cross-device link [19] No such device [20] Not a directory [21] Is a directory [22] Invalid argument [23] Too many open files in system [24] Too many open files [25] Inappropriate ioctl for device [26] Text file busy
2.程序退出方法
程序退出的几种状态
- 代码跑完,结果正确
- 代码跑完,结果错误
- 代码没有跑完,提前出现异常终止
错误码表征了程序退出的信息,交由父进程进行读取
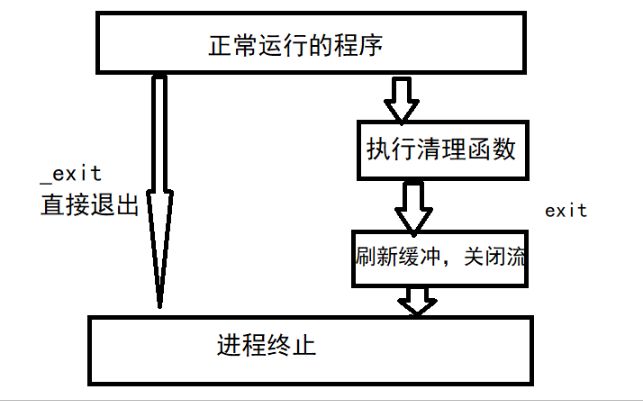
exit()和_exit()
一般情况下,我们可以在
main函数中return,或者在任何地方使用exit()和_exit()来终止程序,exit 调用是终止进程并且刷新缓冲区关闭文件流,而 _exit 是直接终止进程,不会有任何其他动作,记得包含头文件< unistd.h >< stdlib.h >
slab 分配器
进程=内核结构task/mm_struct等+进程代码、数据,创建对象的过程包括了开辟空间和初始化,对象创建了像 task_struct/mm_struct 这种内核数据结构可能并不会被系统释放,系统就会使用内核的数据结构缓冲池,又称slab分派器,来管理这些仍待使用的内核结构。当有新进程出现的时候,更新内核结构的信息,并将其插入到运行队列中
三、进程等待
1.程序等待的必要性
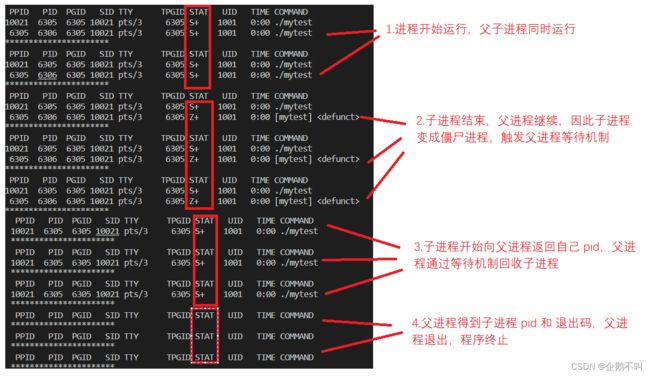
这个概念是根据僵尸进程提出的,为什么进程结束后不直接终止(X 状态)而是要先进入僵尸进程(Z 状态)?
子进程退出后如果父进程不管就会造成所谓的僵尸进程,从而造成内存泄漏,另外一旦变成僵尸进程连 kill 指令也束手无策,因为逻辑上你无法杀死一个已经死去的进程。其次,父进程有义务知道子进程的完成情况且结果是否正确,我们说到的退出码这里也是这样,确认子进程的退出状态就是子进程的退出码需要被父进程所读取。
所以进程等待实际上是父进程回收子进程资源,获取子进程退出信息的重要渠道
2.进程等待方法(重要)
使用到的两个函数和头文件
#include#include pid_t wait(int*status); pid_t waitpid(pid_t pid, int *status, int options);
wait
#include#include pid_t wait(int *status);
作用:等待子进程退出
返回值:等待成功则返回等待进程的PID,等待失败,返回-1
参数为输出型参数,获取子进程退出状态,不关心则可以设置成为 NULL,status是从子进程的
task_struct中拿出来的,子进程会将自己的退出码写入task_struct下面是错误写法,正确写法具体看status参数这段
#include#include #include #include #include int main() { pid_t id = fork(); if(id == 0){ int ret = 5; while(ret--){ printf("child[%d] is running:ret is %d\n", getpid(), ret); sleep(1); } exit(0); } printf("father wait begin..\n"); pid_t cur = wait(NULL); if(cur > 0){ printf("father wait:%d success\n", cur); //printf("father wait:%d success\n", cur);//直接打印status是错误的! //status的低16位才有效,其中这16位的高8位是状态码 } else{ printf("father wait failed\n"); } } 运行程序时,SSH 渠道的 shell 脚本来进行监视功能
while :; do ps axj | head -1 && ps axj | grep mytest | grep -v grep; sleep 1; echo "**********************"; done监视窗口大致分为以下四步
waitpid
#include#include pid_t waitpid(pid_t pid, int *status, int options);
- 返回值:正常返回子进程的pid;如果设置了options,而调用中 waitpid 发现没有已退出的子进程可收集,则返回0;如果调用中出错,则返回 -1,这时 errno 会被设置成相应的值以指示错误所在
- pid:
大于0等待其进程ID与pid相等的子进程;等于-1等待任意一个子进程- status:同wait,为输出型参数,WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)- options:若设置为0,则进行阻塞等待,若设置为WNOHANG(非阻塞) 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的PID。
waitpid两种使用方式
pid_t cur = waitpid(id, NULL, 0);//等待指定一个子进程 pid_t cur = waitpid(-1, NULL, 0);//等待任意一个子进程pid_t cur = waitpid(-1, NULL, 0);//等待任意一个子进程 if(cur > 0){ printf("father wait:%d success\n", cur); } else{ printf("father wait failed\n"); }
3.status参数
包含退出码和退出信号,int* status 是一种输出型参数,其中 status 是由32个比特位构成的一个整数,目前阶段我们只使用低16个位来表示进程退出的结果,正常终止的话 8 比特位保存退出状态,7 比特位保存退出码 0;而如果是被信号 kill 了,他就会大有不同,在未使用空间后面的结尾空间用于保存终止信号,在未使用空间和终止信号之间还有一个比特位大小的core dump 标志
正确访问状态码的方式,用次低8位表示进程退出时的退出状态,也就是退出码;用低7位表示进程终止时所对应的信号,我们想要拿到这个退出码和信号的值,只要拿到低 16 个比特位中的次低 8 位和低 7 位就可以了
status >> 8 & 0xFF;//次低8位,退出码 status & 0x7F;//低7位,退出信号以下才是wait那一段的正确用法:
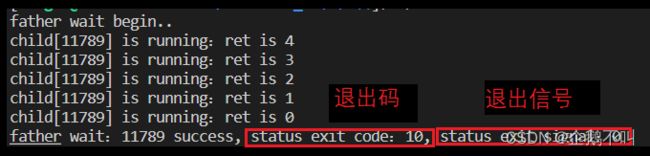
#include#include #include #include #include int main() { pid_t id = fork(); if(id == 0){ int ret = 5; while(ret--){ printf("child[%d] is running:ret is %d\n", getpid(), ret); sleep(1); } exit(10); } printf("father wait begin..\n"); int status = 0; pid_t cur = waitpid(id, &status, 0);//指定等待上面创建的子进程 //status的低16位才有效,其中这16位的高8位是状态码 if(cur > 0){ printf("father wait:%d success, status exit_code:%d, status exit_signal:%d\n", cur, (status >> 8)& 0xFF, status & 0x7F); } else printf("father wait failed\n"); } 进程结束看退出码,进程异常看退出信号,如果子进程被
kill -9干掉,则退出信号返回9
关于位运算,库里面提供了以下宏
WIFEXITED(status)查看子进程是否是正常退出的,正常退出为真WIFSIGNALED(status)查看子进程是否为信号终止,信号终止返回真WEXITSTATUS(status)提取子进程退出码WTERMSIG(status)提取子进程退出信号//其余部分代码和上面相同,子进程exit(11) int status = 0; pid_t cur = waitpid(id,&status,0);//指定等待上面创建的子进程 if(WIFEXITED(status))//子进程正常退出返回真 { printf("等待成功,子进程pid:%d, 状态:%d,信号:%d\n",cur,WEXITSTATUS(status),WTERMSIG(status)); } else { printf("非正常退出,子进程pid:%d, 状态:%d,信号:%d\n",cur,WEXITSTATUS(status),WTERMSIG(status)); }

4.阻塞等待和非阻塞等待
waitpid函数中的option参数和阻塞/非阻塞有关0 阻塞 WNOHANG 非阻塞
阻塞等待
阻塞时,在调用结果返回前,当前线程会被挂起,并在得到结果之后返回
给
waitpid的option传入0,即为阻塞等待pid_t id = waitpid(-1,&status,0);//阻塞等待在子进程被信号干掉或者执行完毕退出之前,父进程不会向后执行代码。在用户层面看来,就是程序被卡住了
非阻塞等待
非阻塞时,如果不能立刻得到结果,则该调用者不会阻塞当前线程,因此对应非阻塞的情况,调用者需要定时轮询查看处理状态。
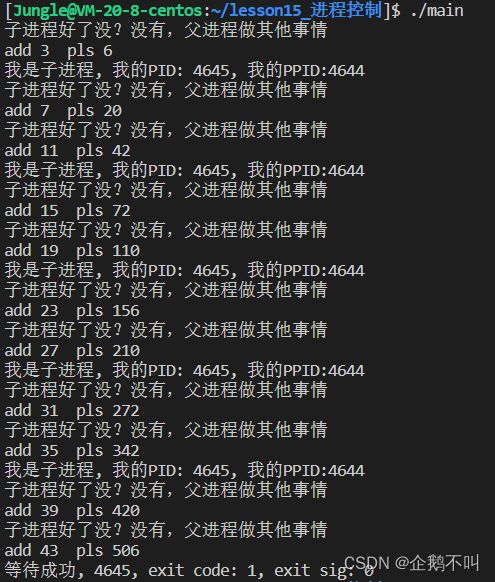
给waitpid的option传入WNOHANG,即为非阻塞等待,期间父进程可以做其他事情,这种多次调用waitpid接口的方式又被称为轮询检测#include#include #include #include #include int add(int a, int b) { return a + b; } int pls(int a, int b) { return a * b; } int main() { pid_t id = fork(); if (id == 0) { // 子进程 int i = 5; while (i--) { printf("我是子进程, 我的PID: %d, 我的PPID:%d\n", getpid(), getppid()); sleep(2); } exit(0); } // 父进程 // 基于非阻塞的轮询等待方案 int status = 0; int i = 1, j = 2; while (1) { pid_t ret = waitpid(id, &status, WNOHANG); //正常返回子进程 if (ret > 0) { printf("等待成功, %d, exit code: %d, exit sig: %d\n", ret, WIFEXITED(status), WTERMSIG(status)); break; } //发现没有已退出的子进程可收集 else if (ret == 0) { //等待成功了,但子进程没有退出 printf("子进程好了没?没有,父进程做其他事情\n"); printf("add %d ", add(i++, j++)); printf("pls %d\n", pls(i++, j++)); sleep(1); } else { //err printf("父进程等待出错!\n"); break; } } return 0; } 输出结果:
四、进程替换(重点)
子进程都是运行的已经预先写好的代码,可能用的是C++,现在希望子进程调用其他程序,而且其他程序可能是用其他语言写的,就要用到程序替换
1.替换原理
- 将磁盘中的程序加载进入内核结构
- 重新建立页表映射,谁执行程序替换,就建立谁的映射,如果是子进程调用的程序替换,那么就会修改子进程的页表映射
- 效果:子进程代码和父进程彻底分离,子进程执行了一个全新的程序
这个过程中并没有创建新的子进程,本质上还是当前子进程
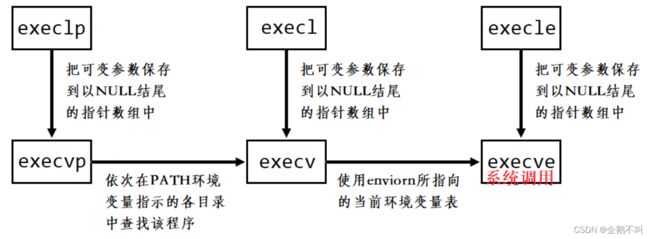
2.替换函数-记得包含头文件
execl
参数
int execl(const char *path, const char *arg, ...);
- path是需要运行程序的路径
arg代表需要执行的程序...是可变参数,可以传入不定量的参数,这里我们填入的是命令行的参数,填入命令行参数的时候,必须要以NULL作为参数的结尾#include#include #include #include int main() { printf("开始测试\n\n"); execl("/usr/bin/ls","ls","-l",NULL); //execl("/home/Jungle/lesson15_进程控制","gcc","mytest.c",NULL);//调程序也是一样的 printf("执行结束\n"); return 0; } 输出结果:
调用了其他可执行程序之后,第二个
printf函数并没有被执行,因为用这个函数来调用其他可执行程序,本质上已经把当前的代码和数据替换掉了,那么原本的printf("执行结束 %d\n",ret);肯定也不会执行

返回值
程序正常执行,不会有返回值,只有出错的时候才会返回-1,同时会更新
ERRNO,比如将 /usr/bin/ls 修改,下面程序就会报错,没有这个abc文件#include#include #include #include int main() { printf("开始测试\n\n"); int ret = execl("/usr/bin/abc","ls","-l",NULL); printf("执行结束: %d\n",ret); printf("错误原因: %s\n",strerror(errno)); return 0; }
execv
int execv(const char *path, char *const argv[]);需要我们用一个指针数组来传入命令行参数,其他都和execl一样
#include#include #include #include int main() { printf("开始测试\n\n"); char*const arg[]={ "ls", "-l", "-a", NULL }; execv("/usr/bin/ls",arg); printf("错误原因: %s\n",strerror(errno)); return 0; }
execlp
int execlp(const char *file, const char *arg, ...);参数的说明从
path变成了file这个函数和
execl的区别在于,它会自己去系统环境变量的PATH里面查找可执行程序,下面程序出现两个ls,含义不一样,第一个代表文件,第二个代表以怎样的方式打开
#include#include #include #include int main() { printf("开始测试\n\n"); execlp("ls","ls","-l",NULL); return 0; }
execvp
int execvp(const char *file, char *const argv[]);和execlp只有传参的区别
#include#include #include #include int main() { printf("开始测试\n\n"); char*const arg[]={ "ls", "-l", "-a", NULL }; execvp("ls",arg); return 0; }
execle和execve
int execle(const char *path, const char *arg, ..., char * const envp[]); int execve(const char *filename, char *const argv[], char *const envp[]);作用:利用可变参数传入命令行参数和利用数组传入命令行参数
参数:可执行文件的完整路径,命令行参数,环境变量e代表的是环境变量,代表我们可以把特定的环境变量传入其中进行处理。它们的环境变量都是在最末尾传的
用C程序调用C++程序打印换进变量
C++程序,mytest.cpp
#include#include using namespace std; int main() { cout << "hello c++" << endl; cout << "-------------------------------------------\n"; cout << "PATH:" << getenv("PATH") << endl; cout << "-------------------------------------------\n"; cout << "MYPATH:" << getenv("MYPATH") << endl; cout << "-------------------------------------------\n"; return 0; } execle调用
#include#include #include #include int main() { extern char ** environ;//环境变量指针声明 printf("开始测试\n\n"); execle("./mytest","mytest","NULL",environ);//mytest是可执行程序 return 0; } execve调用
#include#include #include #include int main() { extern char ** environ;//环境变量指针声明 printf("开始测试\n\n"); char*const arg[]={ "./mytest", NULL }; execve("./mytest",arg,environ); return 0; } 打印结果不会打印MYPATH,是因为环境变量中没有MYPATH
导入环境变量
用数组来传入环境变量,自己定义环境变量的时候记得带上系统环境变量,传入的时候,是会覆盖掉系统的环境变量的
#include#include #include #include int main() { extern char ** environ;//环境变量指针声明 printf("开始测试\n\n"); char*const arg[]={ "./mytest", NULL }; char*const env[]={ "PATH=path test",//记得带上系统中的环境变量 "MYPATH=this is c test", NULL }; execve("./mytest",arg,env); return 0; }
系统接口execve
实际上只有
execve是Linux系统提供的接口,其他函数都是C语言库中对execve的二次封装,来适应不同的使用场景
3.函数命名总结
- l(list):使用可变参数列表
- v(vector):用数组传参
- p(path):自动在环境变量PATH中搜索
- e(env):表示自己维护环境变量
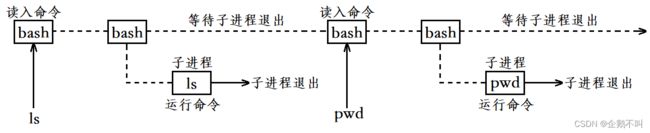
五、做一个shell
shell也就是命令行解释器,其运行原理就是:当有命令需要执行时,shell创建子进程,让子进程执行命令,而shell只需等待子进程退出即可。
#include#include #include #include #include #include #define NUM 1024 #define CMD_NUM 128 #define SEP " " char command[NUM]; char *argv[CMD_NUM]={NULL};//存放各个命令 int main() { while(1) { char *argv[CMD_NUM]={NULL};//存放各个命令 //1.打印提示符 printf("[Jungle@VM-20-8-centos:~]$"); fflush(stdout);//输出缓冲区内容 //2.获取用户输入 memset(command, sizeof(char), sizeof(char)*sizeof(command)); fgets(command,NUM,stdin); command[strlen(command)-1]='\0';//清空'\n' //3.解析命令字符串 //"ls -a -l -i\0";->"ls" "-a" "-l" "-i" argv[0]=strtok(command,SEP);//将字符串按sep分隔符分开 int i=1; //strtok截取成功返回字符串起始地址,截取失败返回NULL while(argv[i]=strtok(NULL,SEP)) { i++; } //4.TODO,检测命令是否是需要shell本身执行的,内建命令 if(strcmp(argv[0],"cd")==0 && argv[1]!=NULL)//如果调用的是cd命令 { chdir(argv[1]);//chdir改变当前工作目录,父进程 continue; } if(strcmp(argv[0],"export")==0 && argv[1]!=NULL)//如果调用的是export命令 { putenv(argv[1]);//putenv导入环境变量 continue; } //5.创建进程,执行 pid_t id = fork(); if(id==0)//child { //6.程序替换 execvp(argv[0],argv);//第一个参数保存的是我们需要执行的程序的名字 exit(1);//替换失败 } //parent int status = 0; pid_t ret = waitpid(id,&status,0); if(WIFEXITED(status))//子进程正常退出返回真 { printf("等待成功,子进程pid:%d, 状态:%d,信号:%d\n",ret,WEXITSTATUS(status),WTERMSIG(status)); } else { printf("非正常退出,子进程pid:%d, 状态:%d,信号:%d\n",ret,WEXITSTATUS(status),WTERMSIG(status)); } } }