Linux 进程替换深剖
目录
-
- 传统艺能
- 概念
- 细则
- 原理
- exec 函数
-
- execl
- execlp
- execle
- execv
- execvp
- execve
- 实现简易 shell
- 程序替换
传统艺能
小编是双非本科大二菜鸟不赘述,欢迎米娜桑来指点江山哦

1319365055
非科班转码社区诚邀您入驻
小伙伴们,满怀希望,所向披靡,打码一路向北
一个人的单打独斗不如一群人的砥砺前行
这是和梦想合伙人组建的社区,诚邀各位有志之士的加入!!
社区用户好文均加精(“标兵”文章字数2000+加精,“达人”文章字数1500+加精)
直达: 社区链接点我

概念
你是否遇到过这样一个场景,**在一个多人项目中,有人用 Java 实现部分功能,有人用 C++ 实现部分功能,有人用 PHP,go,Python……**那该如何将这些不同的逻辑语言统一进来呢?
当我们 fork() 生成子进程后,子进程的代码与数据可以来自其他可执行程序。把磁盘上其他程序的数据以覆盖的形式给子进程。这样子进程就可以执行全新的程序了,这种现象称为 程序替换 \color{red} {程序替换} 程序替换
细则
首先需要知道进程替换是有原则的:
-
进程替换不会创建新进程,因为他只是将该进程数据替换为指定的可执行程序。而进程 PCB 没有改变,所以不是新的进程,进程替换后不会改变 pid
-
替换成功后,替换函数后的代码不会执行,因为进程替换是覆盖式的,替换成功后进程原来的代码就消失了,同理替换失败会执行替换函数后的代码
-
进程替换函数在进程替换成功后不返回,函数的返回值只会表示替换失败;进程替换成功后,退出码为替换后进程的退出码
原理
替换是用的是替换函数: e x e c 函数 \color{red} {exec 函数} exec函数
该函数类型使用头文件:
函数原型:int execl(const char *path,const char *arg,…)
path:可执行程序的路径
arg:如何执行可执行程序
… :可变参数,是给执行程序携带的参数,在参数末尾加 NULL 表示参数结束
返回值:替换失败返回-1,替换成功不返回
当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,并从新程序的启动例程开始执行,本质上和虚拟内存和写时拷贝机制有点类似,通过在页表上进行映射操作进行替换:
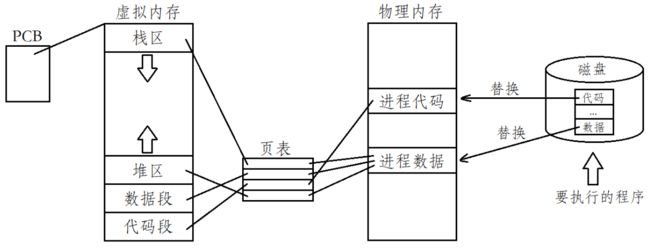
那么子进程程序替换后,会对父进程产生印象吗?
毫无疑问,子进程被创建时是与父进程共享代码和数据,但当程序替换时,也就意味着需要进行写入操作,这时便需要将父子进程共享的代码和数据进行写时拷贝,此后父子进程的代码和数据也就分离了,因此进行程序替换后不会影响父进程的代码和数据!
exec 函数
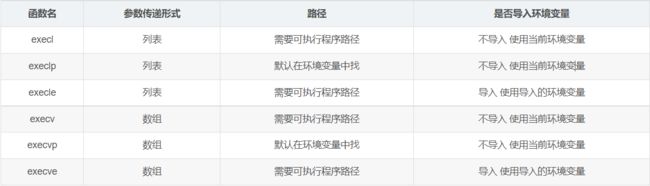
进程替换有六种替换函数,他们是以 exec 开头的函数,统称为 exec 函数:
execl
int execl(const char *path, const char *arg, ...);
第一个参数是要执行程序的路径,第二个参数是可变参数列表,代表我们需要以 list 的形式处理各种操作,内容是各个指令选项,并以NULL结尾
以 ls 命令为例:
execl("/usr/bin/ls", "ls", "-a", "-i", "-l", NULL);
execlp
int execlp(const char *file, const char *arg, ...);
第一个参数是要执行程序的名字,第二个参数是可变参数列表,代表我们需要以 list 的形式处理各种操作,内容是各个指令选项,并以NULL结尾
同样以 ls 命令为例:
execlp("ls", "ls", "-a", "-i", "-l", NULL);
execle
int execle(const char *path, const char *arg, ..., char *const envp[]);
第一个参数是要执行程序的路径,第二个参数是可变参数列表,代表我们需要以 list 的形式处理各种操作,内容是各个指令选项,并以NULL结尾,第三个参数是你自己设置的环境变量,比如我们设置了自己的 MYVAL 环境变量,在 mypro 程序内就可以使用该环境变量:
char* myenvp[] = { "MYVAL=2021", NULL };
execle("./mypro", "mypro", NULL, myenvp);
execv
int execv(const char *path, char *const argv[]);
第一个参数是要执行程序的路径,第二个参数是一个指针数组,代表我们需要以 vector 的形式处理各种操作,数组当中的内容是各个指令选项,数组以 NULL 结尾
还是以 ls 命令为例:
char* myargv[] = { "ls", "-a", "-i", "-l", NULL };
execv("/usr/bin/ls", myargv);
execvp
int execvp(const char *file, char *const argv[]);
第一个参数是要执行程序的名字,第二个参数是一个指针数组,代表我们需要以 vector 的形式处理各种操作,数组当中的内容是各个指令选项,数组以 NULL 结尾
例如,要执行的是ls程序:
char* myargv[] = { "ls", "-a", "-i", "-l", NULL };
execvp("ls", myargv);
execve
int execve(const char *path, char *const argv[], char *const envp[]);
第一个参数是要执行程序的路径,第二个参数是一个指针数组,代表我们需要以 vector 的形式处理各种操作,数组以NULL结尾,第三个参数是你自己设置的环境变量,比如我们设置了自己的 MYVAL 环境变量,在 mypro 程序内就可以使用该环境变量:
char* myargv[] = { "mypro", NULL };
char* myenvp[] = { "MYVAL=2021", NULL };
execve("./mypro", myargv, myenvp);
为了方便记忆,这里根据各个函数的后缀进行了归纳:
l:表示参数采用 list 列表的形式
v:表示参数采用 vector 数组的形式
p:表示能自动搜索环境变量 PATH 进行程序查找,即不需要列举程序路径
e:表示可以传入自己设置的环境(env)变量
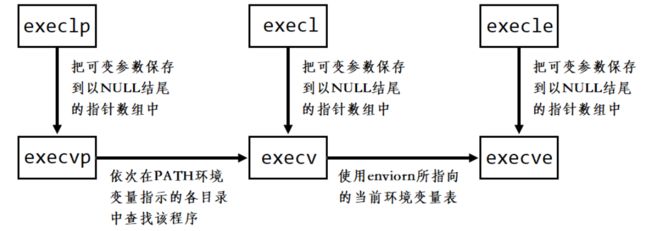
但是事实上, 只有 e x e c v e 才是真正的系统调用 \color{red} {只有 execve 才是真正的系统调用} 只有execve才是真正的系统调用,其它 5 个函数都是调用的execve,也就是说其他 5 个函数实际上是对 execve 的系统调用进行了封装,以满足不同用户的不同调用场景,下图就是各成员间的关系:
实现简易 shell
shell 也就是之前说的命令行解释器,运行原理就是:当有命令需要执行时,shell 创建子进程,让子进程执行命令,而 shell 只需等待子进程退出即可

我们将 shell 的运行逻辑分为下面的五步:
- 获取命令行
- 解析命令行
- 创建子进程
- 替换子进程
- 等待子进程退出
我们之前学习了 fork 函数可以进行进程创建,exec系列函数可以进行子进程替换,wait 或者 waitpid 函数可以等待子进程,那么基础框架就勾勒出来了:
#include 我们自己实现的 shell 在子进程退出后都会打印子进程的退出码,我们可以根据这一点来区分当前使用的是 Linux 的 shell 还是我们自己实现的 shell
程序替换
以前我们的程序由很多函数组成,一个函数可以调用另一个函数,同时可以传递一些参数;被调用的函数执行一定的操作,然后返回一个值。
不同函数通过call/return系统进行通信。这种通过参数和返回值,在拥有私有数据的函数间通信的模式是结构化程序设计的基础,Linux 鼓励将这种应用于程序之内的模式扩展到程序之间
其次我在开始说过,一个程序如果要做到完美,那么就需要杂糅各种语言来完成不同的功能,因为每种语言的优劣各有不同,所以程序的替换就可以很自然的处理各个语言之间的衔接
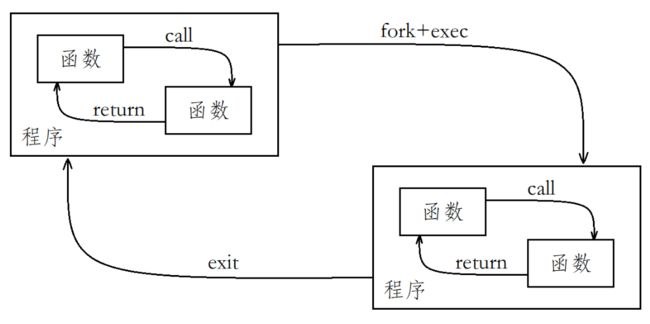
在 fork 子进程后,再用 exec 的替换函数进行进程替换即可,从而达到程序之间的相互调用:
pid_t id = fork();
if (id == 0){
execvp(myargv[0], myargv);
exit(1);
}
这里 exit() 返回进程的调用结果,在原来进程里面是用 wait 或者 waitpid 进行接收即可:
wait(&status);
waitpid(id, &status, 0);
aqa 芭蕾 eqe 亏内,代表着开心代表着快乐,ok 了家人们