程序地址空间
目录
程序地址空间概念
什么是程序地址空间
程序地址空间如何设计
为什么要有程序地址空间
保护物理内存
实现进程管理与内存管理的解耦
实现进程间独立性
再前面学习语言的阶段,我们知道再语言中,不同的变量存储的位置是不同的。
字符常量,全局变量,或者是 malloc/new 出来的空间,他们存放的位置是不同的。
而在语言中,我们常谈的就是局部变量存储在栈区,而动态开辟的空间在堆区,还有常量在字符常量区等...
今天我们看一下操作系统中的程序地址空间。
下面我们的步骤就是:
-
先验证不同的值存储的位置是不同的,也就是看一下程序地址空间。
-
回答什么是程序地址空间。
-
知道程序地址空间是怎么设计的。
-
为什么要有程序地址空间。
程序地址空间概念
程序地址空间大概是什么样子:

程序地址空间按大概就是这样,它是从低地址到高地址增长的,而地址是从全0开始,知道全F,但是代码段并不是从全0开始。
下面先验证一下语言上的地址是否和上面说的相同:
#include
using namespace std;
int g_val = 10; //已初始化数据区
int g_unval; //未初始化数据区
int main(int argc, char* argv[])
{
printf("代码段:%p\n", main);
printf("初始化数据区:%p\n", &g_val);
printf("未初始化数据区:%p\n", &g_unval);
int* heap = (int*)malloc(12);
printf("堆:%p\n", heap);
printf("栈:%p\n", &heap);
printf("命令行参数:%p", argv[0]);
return 0;
} -
为了验证上面说的是否正确,我们写一段代码来打印看一下。
-
首先是代码段,如果想看代码段,那么 main 函数就是代码段的,所以我们可以直接打印 main函数的地址。
-
下面是初始化数据区,我们定义了一个 g_val 还赋值了,所以就是初始化数据区的。
-
下面还有 g_unval 没有初始化,所以是未初始化数据区。
-
堆,我们 malloc 了一段空间,让 heap 指针指向这段空间,所以 heap 就是堆空间的地址。
-
栈,还是上面的 heap 变量,heap变量是在 main 函数的栈帧中定义的一个变量,所以 heap 是栈上的。
-
最后是命令行参数,我们之间打印 argv 里面的第一个指针,他就是命令行参数的地址。
结果:
[lxy@hecs-165234 linux100]$ ./myproc
代码段:0x4006dd
初始化数据区:0x601054
未初始化数据区:0x60105c
堆:0x622c20
栈:0x7fff82d22628
命令行参数:0x7fff82d247e8-
这个结果和我们的预期的是相符的,因为代码段在最下面,而程序地址空间也是从低地址到高地址向上增长。
-
代码段的地址是最小的,而地址也是最小的。
-
初始化数据区和未初始化数据区是紧挨着的,而未初始化数据区确实也比初始化数据区要大一点。
-
堆也是比未初始化数据区要大的。
-
而栈比堆大的多,其实之前也说过,堆栈是相对而生的,这也说明了堆和栈中间有很大的空间。
-
还有就是命令行参数,他在最上面,而它确实也比栈上的地址大。
通过上面的验证,我们发现确实是和上面图片上的地址是相符的。
但是仅仅通过上面,我们得知了确实是有地址空间的,那么现在有一个问题,就是上面的地址空间是真实的地址吗?
这个问题先不急着回答,我们下面写一段代码看一下,我们这次要写的代码就是让 fork 创建子进程,然后让父子进程打印相同的变量,最后让子进程修改变量,然后看一下结果,同时也让父子进程打印该变量的地址:
int num = 10;
void test()
{
pid_t id = fork();
if(id == 0)
{
// child
int count = 0;
while(1)
{
printf("child: pid = %d, ppid = %d, num = %d, numAddress = %p\n", getpid(), getppid(), num, &num);
if(count == 5)
num = 20;
++count;
sleep(1);
}
}
else
{
// parent
while(1)
{
printf("parent: pid = %d, ppid = %d, num = %d, numAddress = %p\n", getpid(), getppid(), num, &num);
sleep(1);
}
}
}
-
上面的这一段代码,首先就是我们有一个全局变量,然后父进程创建子进程后两个进程打印。
-
然后子进程在五秒后修改, num,然后接着打印。
-
同时在打印的时候,我们还打印该全局变量的地址。
结果:
parent: pid = 18791, ppid = 17209, num = 10, numAddress = 0x601070
child: pid = 18792, ppid = 18791, num = 10, numAddress = 0x601070
parent: pid = 18791, ppid = 17209, num = 10, numAddress = 0x601070
child: pid = 18792, ppid = 18791, num = 10, numAddress = 0x601070
parent: pid = 18791, ppid = 17209, num = 10, numAddress = 0x601070
child: pid = 18792, ppid = 18791, num = 10, numAddress = 0x601070
parent: pid = 18791, ppid = 17209, num = 10, numAddress = 0x601070
child: pid = 18792, ppid = 18791, num = 10, numAddress = 0x601070
parent: pid = 18791, ppid = 17209, num = 10, numAddress = 0x601070
child: pid = 18792, ppid = 18791, num = 10, numAddress = 0x601070
parent: pid = 18791, ppid = 17209, num = 10, numAddress = 0x601070
child: pid = 18792, ppid = 18791, num = 10, numAddress = 0x601070
parent: pid = 18791, ppid = 17209, num = 10, numAddress = 0x601070
child: pid = 18792, ppid = 18791, num = 20, numAddress = 0x601070
parent: pid = 18791, ppid = 17209, num = 10, numAddress = 0x601070-
这里看到的结果是,前面的 num 和 num 的地址都是相同的
-
但是五秒后child 修改了变量,但是地址还是相同的。
-
这里就有疑问了,在同一个地址的变量可以存储两份值吗?
-
其实这里的问题在前面说 fork 创建子进程的时候是一样的,为什么 pid_t id 这个变量既可以存储 0 也可以存储子进程的id?
通过上面的试验,我们得出结论,上面的程序地址空间不可能是物理地址!
那么前面的程序地址空间到底是什么?我们下面回答!
什么是程序地址空间
在实际中,我们的程序是如何访问内存的呢?
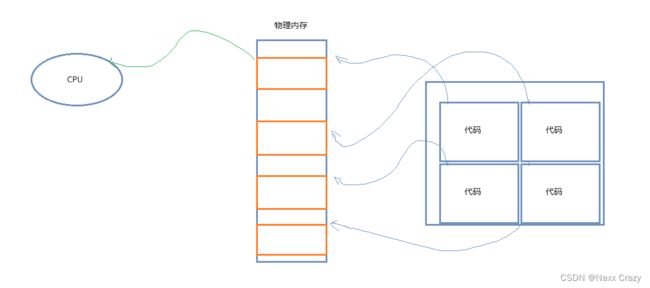
是上面的这样吗?
-
也就是CPU直接访问我们的物理内存?
-
显然不是上面的这个样子。
-
如果是上面这样的话,那么假如我们有一个程序不小心越界访问了,修改到其他程序的数据了,那么就是有问题的。
-
而且,我们的进程都是由独立性的,如果是上面这样的话,那么进程之间就不具有独立性了。
所以实际上,我们是通过程序地址空间(虚拟内存/线性内存)来实现的。
实际上应该想下图一样。
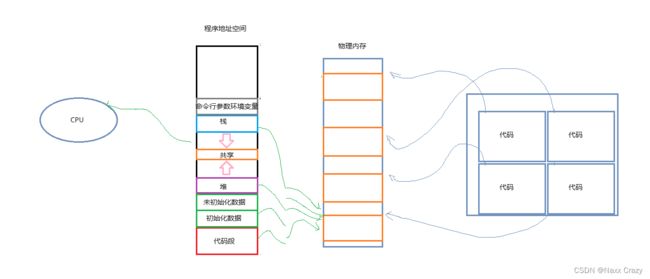
应该是 CPU 通过虚拟内存区找物理内存中的数据。
下面来介绍一下什么是程序地址空间。
在回答这个问题之前,先说一个故事!
有一个老板,他非常的有钱,它也有三个私生子,他的三个私生子都互相不知道对方,而老板对自己的孩子也是很宽容,让他们作自己想做的事情,同时他告诉自己的孩子,钱随便花,并且告诉自己的孩子,自己的钱以后都是他的,由于孩子们都互相不知道对方的存在,所以认为父亲的钱以后都是自己的,自己拥有父亲所有的钱,而每一个孩子都是这样认为的。
-
这里的孩子就可以理解为进程,而父亲就可以理解为操作系统,而钱就可以理解为内存。
-
每一个进程都认为自己拥有系统中所有的内存。
-
而既然每一个进程都认为自己拥有一整个内存,那么每个进程在内存中存储的数据地址又是不同的。
-
所以每一个进程都右一个自己独立的虚拟地址空间。
-
正是因为每一个进程都有,所以可想而知,操作系统中的虚拟地址空间一定是很多的,那么操作系统要不要管理呢?当然是要的,那么如何管理?先描述,再组织。
-
既然是先描述,那么如何描述?一定是使用数据结构描述,程序地址空间实际上就是一个数据结构。
程序地址空间如何设计
那么这个数据结构里面可能会有哪些字段呢?
struct roomAddress
{
unit32_t code_start;
unit32_t code_end;
unit32_t init_val_start;
unit32_t uninit_val_end;
unistd_32_t heap_start;
unistd_32_t heap_end;
unistd_32_t stack_start;
unistd_32_t stack_end;
....
}-
如果使用语言表示的花,大概就是这个样子,但是并不是只有这些字段,一定还有很多其他的字段。
既然我们也知道了程序地址空间是什么,那么我们也要知道他是如何与我们的操作系统,以及物理内存是一起工作的。
其实上面我们的回答并不是很准确,而CPU也并不是直接通过程序地址空间就可以找到,而是还需要一个“页表”。
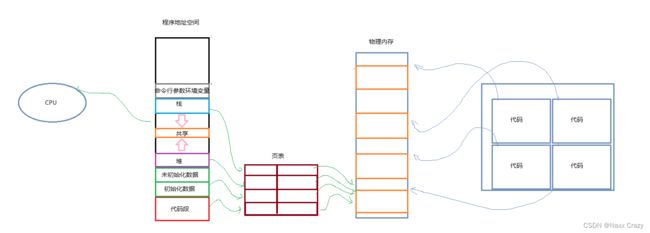
-
在程序运行期间,如果我们想找一个变量,但是变量在内存中,我们就需要通过程序地址空间。
-
而程序地址空间里面的地址就是虚拟地址,通过页表映射找到物理地址。
-
而页表就可以理解为左边存储的是虚拟地址,而右边存储的是实际地址。
-
而程序地址空间,在 Linux 中也被叫做 mm_struct
通过上面的理解,我们也可以回答 fork 在创建子进程的时候为什么 num 被修改,相同的地址里面存储的值是不同的。
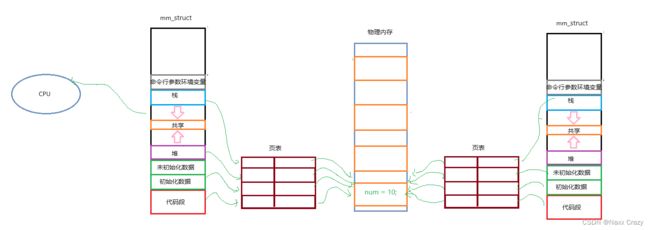
在创建子进程后,子进程大多数都是按照父进程直接拷贝的,所以页表的映射也基本是一样的,只有少数私有数据是分开的,没有共享。
-
开始的时候 num 是共享的,而页表的隐射也是相同的,所以打印出来的值是一样的。
-
但是过了五秒后,由于子进程要修改 num 值,但是在修改之前,操作系统说:“你先别修改,我给你拷贝一份”,然后操作系统给子进程拷贝了一份,才让子进程修改,但是虚拟内存并没有改变,而只是页表映射的物理内存改变了,所以这就出现了相同的地址下,变量的值是不同的。
-
既然回答了这个问题,那么其实 fork 创建子进程返回的 id 也是同一个道理,id 刚开始也是共享的,但是在返回接受的时候,那么也是对 id 的修改,所以此时也会对该数据拷贝一份给子进程。
-
而上面父子进程在不修改的时候共享,修改的时候拷贝一份周期修改,这个就叫做“写时拷贝”。
现在,我们已经知道虚拟内存是如何找到物理内存的,那么我们继续理解一下。
提问:在一个可执行程序没有加载到内存中的时候,有虚拟内存的地址吗?
-
回答:是有的!
-
我们的 windows 下写代码调试的时候,我们发现无论是什么都是有地址的,不管书变量还是函数。
-
如果调用函数,那么就跳转到这个函数的地址上继续执行。
-
实际上,程序地址空间这个设定,并不是光给操作系统的,而编译器也会遵守这个原则。
-
在程序编译的时候,每一个变量,每一个函数都被编译了地址,所以一颗可执行程序并不是只有代码,而是还有地址。

在 CPU 执行的时候,会通过虚拟内存然后继续通过页表映射,找到物理内存,然后执行对应的代码,如果执行的是一个函数,然后 CPU 发现是一个函数,在物理内存中取到了一个虚拟内存(函数的虚拟内存),接着又会通过虚拟内存和页表映射找到该函数的地址,然后执行该函数。
为什么要有程序地址空间
为什么要有程序地址空间,这里我们会通过三个方面来回答这个问题。
保护物理内存
-
还是我们刚开始说的,如果这里直接使用的是物理内存,那么有可能会发生越界,并且修改数据。
-
一旦误删或者操作了其他进程里面的数据,然后导致其他数据错误,所以这样就是物理内存是不安全的。
-
而加入虚拟地址,每个进程都有自己的虚拟内存,在通过页表映射到真实的物理空间。
-
从而不会映射到其他的物理空间上,以此来保护物理内存。
实现进程管理与内存管理的解耦
-
这里先像一个问题,既然每个进程都有自己的页表与虚拟内存,而且页表也可以让虚拟内存与物理空间进行随意映射。
-
那么是不是,进程的代码和数据可以加载到任意物理内存的任意位置?
-
是的!可以加载到内存的任意位置。
-
既然可以加载到内存的任意位置,那么是不是进程只需要管理好自己的虚拟内存,而物理内存实则并不需要进程担心。
-
所以加入虚拟内存还可以让进程管理与内存管理实现解耦。
实现进程间独立性
-
前面我们一直说,进程之间是独立的。
-
那么进程如何算是独立的呢?其中当进程的数据是独立的,那么进程就是独立的。
-
只要任意的进程不会影响到其他进程的数据,那么任意的两个进程也是不会被互相影响到的。
-
结合上面说的,每个进程都有自己的虚拟内存与页表,而通过页表也可以将进程的数据和代码映射到不同的位置。
-
那么只要将每个进程的数据都映射到不同的位置,那么是不是就起到的对进程间数据进行了隔离呢?
-
将进程间的数据进行了隔离,那么进程之间就不会影响到其他的进程,那么是不是就起到了,进程之间是互相独立的呢?