分享9个已开源的GPT4平替,用过感觉还不错

对于想要研究大模型的同学来说,目前ChatGPT无疑是最好的学习对象,但等它开源估计是不太可能了,所以学姐今天整理了一些开源的类GPT模型,帮助大家更好的理解大模型背后的机理。(文末有论文资料)
PS:有的功能还不错,也可以上手玩耍玩耍。
1.Colossal AI
“夸父”AI,大规模并行AI训练系统,基于LLaMA预训练模型。作为ChatGPT的平替,开源了完整的RLHF流水线,包括,监督数据收集、监督微调、奖励模型训练和强化学习微调等。
优势:高效、简单、可扩展,功能多,包含AIGC
缺点:不完全支持中文,基于GPT-3
模型能力:集成现有的GPT-3 、GPT-2模型,能够提升模型效率
训练:
- 第一阶段(stage1_sft.py):SFT监督微调阶段,该开源项目没有实现,这个比较简单,因为ColossalAI无缝支持Huggingface,本人直接用Huggingface的Trainer函数几行代码轻松实现,在这里我用了一个gpt2模型,从其实现上看,其支持GPT2、OPT和BLOOM模型;
- 第二阶段(stage2_rm.py):奖励模型(RM)训练阶段,即项目Examples里train_reward_model.py部分;
- 第三阶段(stage3_ppo.py):强化学习(RLHF)阶段,即项目train_prompts.py。
代码中的cores即原始工程中的chatgpt,cores.nn在原始工程中变成了chatgpt.models。
开源地址:https://github.com/hpcaitech/ColossalAI
2.ChatGLM
智谱AI研发,基于千亿参数大模型的支持中英双语的对话机器人。
网址:ChatGLM
优势:支持中英双语、开源平替里面参数规模较大的对话大模型
缺点:模型记忆和语言能力较弱,数学、编程类解答能力较弱
模型能力:
- 自我认识
- 提纲写作
- 文案写作
- 邮件写作助手
- 信息抽取
- 角色表演
- 评论比较
- 旅游方向
训练:
- 62亿参数
- 针对中文提问和对话进行了优化
- 经过约1T标准符号的中英双语训练,辅以监督微调、反施自助、人类反施强化学习等技术的支持
开源地址:https://github.com/THUDM/ChatGLM-6B
3.LLaMa
Meta打造的一个650 亿参数的大语言模型,可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者。
优势:在生成文本、对话、总结书面材料、等任务上方面表现良好,支持20种语言。
缺点:对中文支持不足
开源地址:https://github.com/facebookresearch/llama
4.LLaMa-ChatLLaMA
由于 LLaMA 大模型系列没有使用 RLHF 方法,因此初创公司 Nebuly AI 开源了 RLHF 版 LLaMA(ChatLLaMA)的训练方法。
优势:
- 更便宜,完整的开源实现,允许用户基于预训练的 LLaMA 模型构建 ChatGPT 风格的服务;
- LLaMA 架构更小,使得训练过程和推理速度更快,成本更低;
- 内置了对 DeepSpeed ZERO 的支持,以加速微调过程;
- 支持各种尺寸的 LLaMA 模型架构,用户可以根据自身偏好对模型进行微调
缺点:不支持中文
5.BELLE
精通中文,基于斯坦福 Alpaca项目,70 亿参数的中文对话大模型。
优势:
- 数据:参考斯坦福大学的Alpaca项目,针对中文场景进行了优化,利用ChatGPT生了多样化、高质量的数据,包括日常对话、知识问答、文本生成等,有助于模型在各种中文场景中的表现。
- 模型:基于Bloom和LLAMA,训练了出具效果的对话模型,并完全开放了这些模型的参数,大大降低使用和科研的门槛
- 轻量化:开源了对话模型的量化版本,包括8bit, 4bit, 其中4bit版本模型checkpoint大小仅为6.9G,运行仅需8.4G显存。
开源地址:https://github.com/LianjiaTech/BELLE
6.PaLM-rlhf-pytorch
作者Phil Wang,在 PaLM 架构之上实现 RLHF,它基本上是使用 PaLM 的 ChatGPT
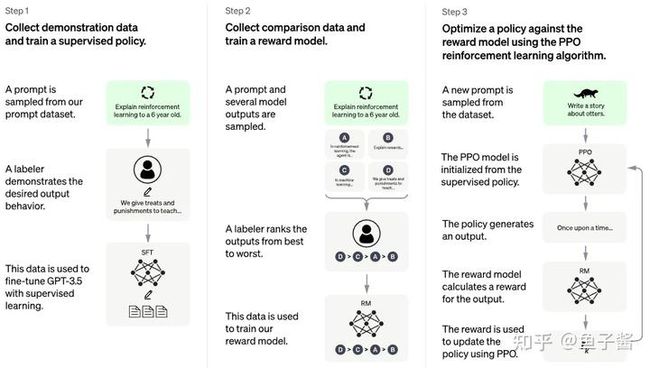

优势:
- 基于谷歌语言大模型PaLM架构,以及使用从人类反馈中强化学习的方法(RLHF)
- 采用了ChatGPT一样的强化学习机制,能让AI的回答更加符合情景要求,降低模型毒性
开源地址:https://github.com/lucidrains/PaLM-rlhf-pytorch
7.OpenAssistant
旨在让每一个人都可以访问基于聊天的大语言模型。
优势:
- 开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。
- 据说是第一个在人类数据上进行训练的完全开源的大规模指令微调模型
缺点:中文效果不佳、受底层模型的限制
开源地址:https://github.com/LAION-AI/Open-Assistant
8.OpenChatKitk
前OpenAI研究员所在的Together团队,以及LAION、Ontocord.ai团队共同打造,包含200亿个参数,用GPT-3的开源版本GPT-NoX-20B进行微调
优势:
- 提供了一个强大的的开源基础,为各种应用程序创建专用和通用的聊天机器人
- 该 kit 包含了一个经过指令调优的 200 亿参数语言模型、一个 60 亿参数调节模型和一个涵盖自定义存储库最新响应的可扩展检索系统
开源地址:https://github.com/togethercomputer/OpenChatKit
9.stanford_alpaca
Stanford Alpaca是一个Instruction-following的LLaMA模型,即一个对LLaMA模型进行指令调优的结果模型
开源地址:https://github.com/tatsu-lab/stanford_alpaca
资料整理自网络,有问题欢迎大家评论区友好讨论哈!
关注一下学姐
5.15更新------
整理了一部分大模型的论文,PDF格式的,关注“学姐带你玩AI”(不懂的看我主页签名)后台回复“大模型”直接领取