sheng的学习笔记-【中文】【吴恩达课后测验】Course 2 - 改善深层神经网络 - 第二周测验
课程2_第2周_测验题
目录:目录
第一题
1.当输入从第8个mini-batch的第7个的例子的时候,你会用哪种符号表示第3层的激活?
A. 【 】 a [ 3 ] { 8 } ( 7 ) a^{[3]\{8\}(7)} a[3]{8}(7)
B. 【 】 a [ 8 ] { 7 } ( 3 ) a^{[8]\{7\}(3)} a[8]{7}(3)
C. 【 】 a [ 8 ] { 3 } ( 7 ) a^{[8]\{3\}(7)} a[8]{3}(7)
D. 【 】 a [ 3 ] { 7 } ( 8 ) a^{[3]\{7\}(8)} a[3]{7}(8)
答案:
A.【 √ 】 a [ 3 ] { 8 } ( 7 ) a^{[3]\{8\}(7)} a[3]{8}(7)
第二题
2.关于mini-batch的说法哪个是正确的?
A. 【 】mini-batch迭代一次(计算1个mini-batch),要比批量梯度下降迭代一次快
B. 【 】用mini-batch训练完整个数据集一次,要比批量梯度下降训练完整个数据集一次快
C. 【 】在不同的mini-batch下,不需要显式地进行循环,就可以实现mini-batch梯度下降,从而使算法同时处理所有的数据(矢量化)
答案:
A.【 √ 】mini-batch迭代一次(计算1个mini-batch),要比批量梯度下降迭代一次快
第三题
3.为什么最好的mini-batch的大小通常不是1也不是m,而是介于两者之间?
A. 【 】如果mini-batch的大小是1,那么在你取得进展前,你需要遍历整个训练集
B. 【 】如果mini-batch的大小是m,就会变成批量梯度下降。在你取得进展前,你需要遍历整个训练集
C. 【 】如果mini-batch的大小是1,那么你将失去mini-batch将数据矢量化带来的的好处
D. 【 】如果mini-batch的大小是m,就会变成随机梯度下降,而这样做经常会比mini-batch慢
答案:
B.【 √ 】如果mini-batch的大小是m,就会变成批量梯度下降。在你取得进展前,你需要遍历整个训练集
C.【 √ 】如果mini-batch的大小是1,那么你将失去mini-batch将数据矢量化带来的的好处
第四题
4.如果你的模型的成本随着迭代次数的增加,绘制出来的图如下,那么:
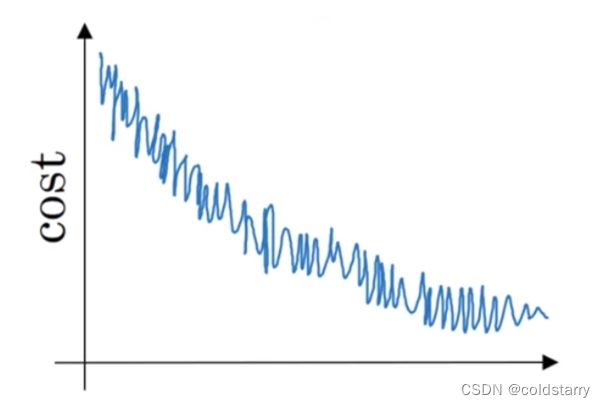
A. 【 】如果你正在使用mini-batch梯度下降,那可能有问题;而如果你在使用批量梯度下降,那是合理的。
B. 【 】如果你正在使用mini-batch梯度下降,那看上去是合理的;而如果你在使用批量梯度下降,那可能有问题。
C. 【 】无论你在使用mini-batch还是批量梯度下降,看上去都是合理的。
D. 【 】无论你在使用mini-batch还是批量梯度下降,都可能有问题。
答案:
B.【 √ 】如果你正在使用mini-batch梯度下降,那看上去是合理的;而如果你在使用批量梯度下降,那可能有问题。
第五题
5.假设一月的前三天卡萨布兰卡的气温是一样的:
- 一月第一天: θ 1 = 10 \theta_1 = 10 θ1=10
- 一月第二天: θ 2 = 10 \theta_2 = 10 θ2=10
假设您使用 β = 0.5 \beta = 0.5 β=0.5的指数加权平均来跟踪温度: v 0 = 0 , v t = β v t − 1 + ( 1 − β ) θ t v_0=0,v_t=\beta v_{t-1}+(1-\beta)\theta_t v0=0,vt=βvt−1+(1−β)θt。如果 v 2 v_2 v2是在没有偏差修正的情况下计算第2天后的值,并且 v 2 c o r r e c t e d v_2^{corrected} v2corrected是您使用偏差修正计算的值。 这些下面的值是正确的是?
A. 【 】 v 2 = 10 , v 2 c o r r e c t e d = 10 v_2=10,v_2^{corrected}=10 v2=10,v2corrected=10
B. 【 】 v 2 = 10 , v 2 c o r r e c t e d = 7.5 v_2=10,v_2^{corrected}=7.5 v2=10,v2corrected=7.5
C. 【 】 v 2 = 7.5 , v 2 c o r r e c t e d = 7.5 v_2=7.5,v_2^{corrected}=7.5 v2=7.5,v2corrected=7.5
D. 【 】 v 2 = 7.5 , v 2 c o r r e c t e d = 10 v_2=7.5,v_2^{corrected}=10 v2=7.5,v2corrected=10
答案:
D.【 √ 】 v 2 = 7.5 , v 2 c o r r e c t e d = 10 v_2=7.5,v_2^{corrected}=10 v2=7.5,v2corrected=10
第六题
6.下面哪一个不是比较好的学习率衰减方法?
A. 【 】 α = 1 1 + 2 ∗ t α 0 \alpha = \frac{1}{1+2*t}\alpha_0 α=1+2∗t1α0
B. 【 】 α = 1 t α 0 \alpha=\frac{1}{\sqrt{t}}\alpha_0 α=t1α0
C. 【 】 α = 0.9 5 t α 0 \alpha=0.95^t\alpha_0 α=0.95tα0
D. 【 】 α = e t α 0 \alpha=e^t\alpha_0 α=etα0
答案:
D.【 √ 】 α = e t α 0 \alpha=e^t\alpha_0 α=etα0
第七题
7.您在伦敦温度数据集上使用指数加权平均, 使用以下公式来追踪温度: v t = β v t − 1 + ( 1 − β ) θ t v_t=\beta v_{t-1}+(1-\beta)\theta_t vt=βvt−1+(1−β)θt。下图中红线使用的是 β = 0.9 \beta=0.9 β=0.9来计算的。当你改变 β \beta β时,你的红色曲线会怎样变化?(选出所有正确项)
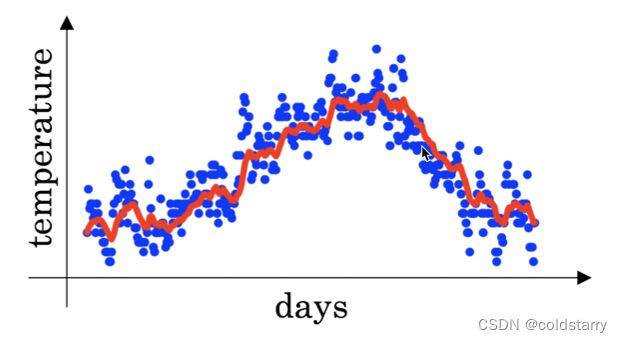
A. 【 】减小 β \beta β,红色线会略微右移
B. 【 】增加 β \beta β,红色线会略微右移
C. 【 】减小 β \beta β,红线会更加震荡
D. 【 】增加 β \beta β,红线会更加震荡
答案:
B.【 √ 】增加 β \beta β,红色线会略微右移
C.【 √ 】减小 β \beta β,红线会更加震荡
第八题
8.下图中的曲线是由:梯度下降,动量梯度下降( β = 0.5 \beta=0.5 β=0.5)和动量梯度下降( β = 0.9 \beta=0.9 β=0.9)。哪条曲线对应哪种算法?
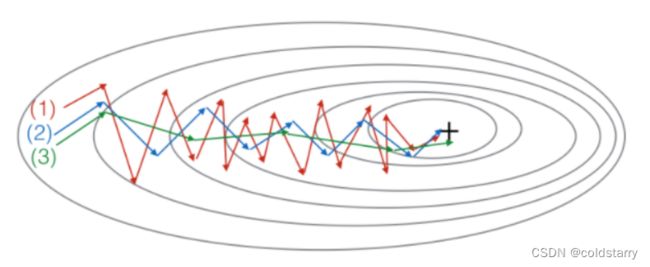
A. 【 】(1)是梯度下降;(2)是动量梯度下降( β = 0.9 \beta=0.9 β=0.9);(3)是动量梯度下降( β = 0.5 \beta=0.5 β=0.5)
B. 【 】(1)是梯度下降;(2)是动量梯度下降( β = 0.5 \beta=0.5 β=0.5);(3)是动量梯度下降( β = 0.9 \beta=0.9 β=0.9)
C. 【 】(1)是动量梯度下降( β = 0.5 \beta=0.5 β=0.5);(2)是动量梯度下降( β = 0.9 \beta=0.9 β=0.9);(3)是梯度下降
D. 【 】(1)是动量梯度下降( β = 0.5 \beta=0.5 β=0.5);(2)是梯度下降;(3)是动量梯度下降($\beta=0.9
$)
答案:
B.【 √ 】(1)是梯度下降;(2)是动量梯度下降( β = 0.5 \beta=0.5 β=0.5);(3)是动量梯度下降( β = 0.9 \beta=0.9 β=0.9)
第九题
9.假设在一个深度学习网络中,批量梯度下降花费了大量时间时来找到一组参数值,使成本函数 ( J ( W [ 1 ] , b [ 1 ] , … , W [ L ] , b [ L ] ) (J(W^{[1]},b^{[1]},…,W^{[L]},b^{[L]}) (J(W[1],b[1],…,W[L],b[L])小。以下哪些方法可以帮助找到 J J J值较小的参数值?
A. 【 】令所有权重值初始化为0
B. 【 】尝试调整学习率
C. 【 】尝试mini-batch梯度下降
D. 【 】尝试对权重进行更好的随机初始化
E. 【 】尝试使用 Adam 算法
答案:
B.【 √ 】尝试调整学习率
C.【 √ 】尝试mini-batch梯度下降
D.【 √ 】尝试对权重进行更好的随机初始化
E.【 √ 】尝试使用 Adam 算法
第十题
10.关于Adam算法,下列哪一个陈述是错误的?
A. 【 】Adam结合了Rmsprop和动量的优点
B. 【 】Adam中的学习率超参数 α \alpha α通常需要调整
C. 【 】我们经常使用超参数的“默认”值 β 1 = 0 , 9 , β 2 = 0.999 , ϵ = 1 0 − 8 \beta_1=0,9,\beta_2=0.999,\epsilon=10^{-8} β1=0,9,β2=0.999,ϵ=10−8
D. 【 】Adam应该用于批梯度计算,而不是用于mini-batch
答案:
D.【 √ 】Adam应该用于批梯度计算,而不是用于mini-batch