Go语言面经进阶10问
1.Golang可变参数
函数方法的参数,可以是任意多个,这种我们称之为可以变参数,比如我们常用的fmt.Println()这类函数,可以接收一个可变的参数。可以变参数,可以是任意多个。我们自己也可以定义可以变参数,可变参数的定义,在类型前加上省略号…即可。
func main() {
print("1","2","3")
}
func print (a ...interface{}){
for _,v:=range a{
fmt.Print(v)
}
fmt.Println()
}
例子中我们自己定义了一个接受可变参数的函数,效果和fmt.Println()一样。可变参数本质上是一个数组,所以我们向使用数组一样使用它,比如例子中的 for range 循环。
2.Golang Slice的底层实现
切片是基于数组实现的,它的底层是数组,它自己本身非常小,可以理解为对底层数组的抽象。因为基于数组实现,所以它的底层的内存是连续分配的,效率非常高,还可以通过索引获得数据,可以迭代以及垃圾回收优化。
切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性将数据读写操作限定在指定的区域内。切片本身是一个只读对象,其工作机制类似数组指针的一种封装。
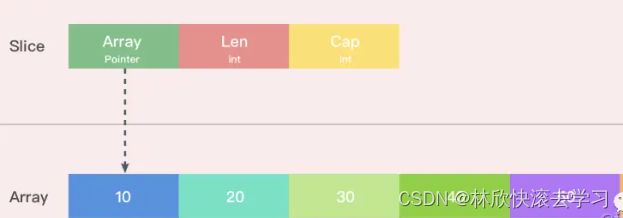
切片对象非常小,是因为它是只有3个字段的数据结构:
- 指向底层数组的指针
- 切片的长度
- 切片的容量
这3个字段,就是Go语言操作底层数组的元数据。
3.Golang Slice的扩容机制,有什么注意点
Go 中切片扩容的策略是这样的:
首先判断,如果新申请容量大于 2 倍的旧容量,最终容量就是新申请的容量。否则判断,如果旧切片的长度小于 1024,则最终容量就是旧容量的两倍。
否则判断,如果旧切片长度大于等于 1024,则最终容量从旧容量开始循环增加原来的 1/4 , 直到最终容量大于等于新申请的容量。如果最终容量计算值溢出,则最终容量就是新申请容量。
情况一:原数组还有容量可以扩容(实际容量没有填充完),这种情况下,扩容以后的数组还是指向原来的数组,对一个切片的操作可能影响多个指针指向相同地址的Slice。
情况二:原来数组的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响原数组。
要复制一个Slice,最好使用Copy函数。
4.Golang Map底层实现
Golang 中 map 的底层实现是一个散列表,因此实现 map 的过程实际上就是实现散表的过程。
在这个散列表中,主要出现的结构体有两个,一个叫hmap(a header for a go map),一个叫bmap(a bucket for a Go map,通常叫其bucket)。
hmap如下所示:


图中有很多字段,但是便于理解 map 的架构,你只需要关心的只有一个,就是标红的字段:buckets 数组。Golang 的 map 中用于存储的结构是 bucket数组。而 bucket(即bmap)的结构是怎样的呢? bucket:

相比于 hmap,bucket 的结构显得简单一些,标橙的字段依然是“核心”,我们使用的 map 中的 key 和 value 就存储在这里。
“高位哈希值”数组记录的是当前 bucket 中 key 相关的”索引”,稍后会详细叙述。还有一个字段是一个指向扩容后的 bucket 的指针,使得 bucket 会形成一个链表结构。
整体的结构应该是这样的:

Golang 把求得的哈希值按照用途一分为二:高位和低位。低位用于寻找当前 key属于 hmap 中的哪个 bucket,而高位用于寻找 bucket 中的哪个 key。
需要特别指出的一点是:map中的key/value值都是存到同一个数组中的。这样做的好处是:在key和value的长度不同的时候,可以消除padding带来的空间浪费。
Map 的扩容:当 Go 的 map 长度增长到大于加载因子所需的 map 长度时,Go 语言就会将产生一个新的 bucket 数组,然后把旧的 bucket 数组移到一个属性字段 oldbucket中。
注意:并不是立刻把旧的数组中的元素转义到新的 bucket 当中,而是,只有当访问到具体的某个 bucket 的时候,会把 bucket 中的数据转移到新的 bucket 中。
5. JSON 标准库对 nil slice 和 空 slice 的处理是一致的吗
首先 JSON 标准库对 nil slice 和 空 slice 的处理是不一致。
通常错误的用法,会报数组越界的错误,因为只是声明了slice,却没有给实例化的对象。
var slice []int
slice[1] = 0
此时slice的值是nil,这种情况可以用于需要返回slice的函数,当函数出现异常的时候,保证函数依然会有nil的返回值。
empty slice 是指slice不为nil,但是slice没有值,slice的底层的空间是空的,此时的定义如下
slice := make([]int,0)
slice := []int{}
当我们查询或者处理一个空的列表的时候,这非常有用,它会告诉我们返回的是一个列表,但是列表内没有任何值。总之,nil slice 和 empty slice是不同的东西,需要我们加以区分的。
6.Golang的内存模型,为什么小对象多了会造成gc压力
通常小对象过多会导致 GC 三色法消耗过多的GPU。优化思路是,减少对象分配。
7.Data Race问题怎么解决?能不能不加锁解决这个问题
同步访问共享数据是处理数据竞争的一种有效的方法。
golang在 1.1 之后引入了竞争检测机制,可以使用 go run -race 或者 go build -race来进行静态检测。其在内部的实现是,开启多个协程执行同一个命令, 并且记录下每个变量的状态。
竞争检测器基于C/C++的ThreadSanitizer 运行时库,该库在Google内部代码基地和Chromium找到许多错误。这个技术在2012年九月集成到Go中,从那时开始,它已经在标准库中检测到42个竞争条件。现在,它已经是我们持续构建过程的一部分,当竞争条件出现时,它会继续捕捉到这些错误。
竞争检测器已经完全集成到Go工具链中,仅仅添加-race标志到命令行就使用了检测器。
$ go test -race mypkg // 测试包
$ go run -race mysrc.go // 编译和运行程序 $ go build -race mycmd
// 构建程序 $ go install -race mypkg // 安装程序
要想解决数据竞争的问题可以使用互斥锁sync.Mutex,解决数据竞争(Data race),也可以使用管道解决,使用管道的效率要比互斥锁高。
8.在 range 迭代 slice 时,你怎么修改值的
在 range 迭代中,得到的值其实是元素的一份值拷贝,更新拷贝并不会更改原来的元素,即是拷贝的地址并不是原有元素的地址。
func main() {
data := []int{1, 2, 3}
for _, v := range data {
v *= 10 // data 中原有元素是不会被修改的
}
fmt.Println("data: ", data) // data: [1 2 3]
}
如果要修改原有元素的值,应该使用索引直接访问。
func main() {
data := []int{1, 2, 3}
for i, v := range data {
data[i] = v * 10
}
fmt.Println("data: ", data) // data: [10 20 30]
}
如果你的集合保存的是指向值的指针,需稍作修改。依旧需要使用索引访问元素,不过可以使用 range 出来的元素直接更新原有值。
func main() {
data := []*struct{ num int }{{1}, {2}, {3},}
for _, v := range data {
v.num *= 10 // 直接使用指针更新
}
fmt.Println(data[0], data[1], data[2]) // &{10} &{20} &{30}
}
9.nil interface 和 nil interface 的区别
虽然 interface 看起来像指针类型,但它不是。interface 类型的变量只有在类型和值均为 nil 时才为 nil如果你的 interface 变量的值是跟随其他变量变化的,与 nil 比较相等时小心。如果你的函数返回值类型是 interface,更要小心这个坑:
func main() {
var data *byte
var in interface{}
fmt.Println(data, data == nil) // true
fmt.Println(in, in == nil) // true
in = data
fmt.Println(in, in == nil) // false // data 值为 nil,但 in 值不为 nil
}
// 正确示例
func main() {
doIt := func(arg int) interface{} {
var result *struct{} = nil
if arg > 0 {
result = &struct{}{}
} else {
return nil // 明确指明返回 nil
}
return result
}
if res := doIt(-1); res != nil {
fmt.Println("Good result: ", res)
} else {
fmt.Println("Bad result: ", res) // Bad result: 10.select可以用于什么
常用于goroutine的完美退出。
golang 的 select 就是监听 IO 操作,当 IO 操作发生时,触发相应的动作每个case语句里必须是一个IO操作,确切的说,应该是一个面向channel的IO操作。