C++ 动态链接库和静态链接库
今天对C++生成动态链接路和静态链接库非常感兴趣,必须搞定,否则都没有心情干其他事了。Let’s go~
文章目录
- 源程序编译链接生成文件格式
-
- 预编译
- 编译和优化
-
- 编译
- 优化
- 生成目标文件
- 链接
- 什么是库?
- 动态静态的区别
- 静态链接库
-
- 静态链接库的创建方法
- lib的调用
- 动态链接库
-
- 动态链接库的创建方法
- dll的使用
-
- 隐式链接
- 显式链接
源程序编译链接生成文件格式
首先贴出从源程序生成可执行文件的过程。
源程序(source code)->预处理(preprocessor) ->编译和优化 (compiler) - >生成目标文件(object code) ->链接(Linker)->可执行文件
生成文件个是对应表
| 源程序 | 预处理 | 编译和优化 | 生成目标文件 | 链接 | 可执行文件 | |
|---|---|---|---|---|---|---|
| 文件后缀 | .h、.cpp、.c | .i | .s | .o | .out | .exe |
| 语言 | c\c++ | c\c++ | 汇编 | 二进制 | 二进制 | 二进制 |
下面是实际举例说明:
1.h
#pragma once
void print(); //我是1.h的注释
1.cpp
#include "1.h"
#include
//我是1.cpp的注释
void print()
{
std::cout << "print函数运行成功" << std::endl;
}
main.cpp
#include
#include "1.h"
#define AA "this is a macro!"
int main()
{
#ifdef AA //我是main.cpp的注释
print();
std::cout << AA << std::endl;
#endif
int a = 1;
int b = 5;
int c = a + b;
std::cout << c << std::endl;
system("pause");
return 0;
}
预编译
预编译阶段先介绍编译器。先介绍几个概念:GNU、GCC、gcc、g++
按照概念范围大小排序如下:
GNU:GNU是一个操作系统。1971年贝尔实验室汤姆森和里奇完成了unix的的基本工作,1973年写成了C语言版本,但是unix并不是贝尔实验室的正式项目,所以也没有商业应用,这两个人就用写论文发表,在学术圈技术交流,高校教授觉得很好,学生也学习,汤姆森和里奇都是免费拷贝分享,一起发展修改进步,结果AT&T公司觉得很有前景,于是选择申请专利商业闭源,这样学生就得花钱买,1985年,Richard Stallman 愤怒的认为unix大家都有过添砖加瓦的建设,应该共享。随即,发起GNU(GNU is not unix)自由操作系统,软件共享运动。本来GNU就是要做一个完整的操作系统来取代unix,但是当编译器、编辑器等其他的外围都写完后,操作系统的内核Hurd一直没有搞定,1991年一个叫Linus Torvalds的学生写了自己的linux,也就是操作系统内核,于是Linux和GNU组合起来成了现在的GNU/Linux操作系统,也就是常简说的Linux操作系统。
GCC:GNU Compiler Collection(GUN 编译器集合),它可以编译C、C++、JAV、Fortran、Pascal、Object-C、Ada等语言。
g++:GCC中的GUN C++ Compiler(C++编译器)
gcc:GCC中的GUN C Compiler(C 编译器)
由于编译器是可以更换的,所以gcc不仅仅可以编译C文件,更准确的说法是:gcc调用了C compiler,而g++调用了C++ compiler。
gcc and g++分别是gnu的c & c++编译器,gcc/g++在执行编译工作的时候,总共需要4步:
1.预处理,生成.i的文件[预处理器cpp];
2.将预处理后的文件转换成汇编语言,生成文件.s[编译器egcs];
3.由汇编变为目标代码(机器代码)生成.o的文件[汇编器as];
4.连接目标代码,生成可执行程序[链接器ld]。
gcc和g++的主要区别:
-
对于 .c和.cpp文件,gcc分别当做c和cpp文件编译(c和cpp的语法强度是不一样的)
-
对于 .c和.cpp文件,g++则统一当做cpp文件编译
-
使用g++编译文件时,g++会自动链接标准库STL,而gcc不会自动链接STL
-
gcc在编译C文件时,可使用的预定义宏是比较少的
-
gcc在编译cpp文件时/g++在编译c文件和cpp文件时(这时候gcc和g++调用的都是cpp文件的编译器),会加入一些额外的宏,这些宏如下:
#define GXX_WEAK 1
#define __cplusplus 1
#define __DEPRECATED 1
#define GNUG 4
#define __EXCEPTIONS 1
#define private_extern extern -
在用gcc编译c++文件时,为了能够使用STL,需要加参数 –lstdc++ ,但这并不代表 gcc –lstdc++ 和 g++等价,它们的区别不仅仅是这个。
主要参数:
-g - turn on debugging (so GDB gives morefriendly output)
-Wall - turns on most warnings
-O or -O2 - turn on optimizations
-o - name of the output file
-c - output an object file (.o)
-I - specify an includedirectory
-L - specify a libdirectory
-l - link with librarylib.a
使用示例:g++ -ohelloworld -I/homes/me/randomplace/include helloworld.C
以上参考来源于下面链接。感谢原作者。https://www.cnblogs.com/oxspirt/p/6847438.html
预处理器主要负责以下的几处:
1.宏的替换
2.删除注释
3.处理预处理指令,如#include,#ifdef
下面进行实例验证。
现找到:

点击进入你的工程目录对应的cpp位置。
输入g++ –E main.cpp>main.i进行预编译生成main.i文件。

打开main.i发现里面内容实在很多,前面一大堆不知道啥,大概就是在干#include 和#include "1.h"这两件事。到文件最后:

看看行号,就简简单单的main函数,就那么多行了。重点是:main函数中的头文件被替换了(不管替换成什么了),注释不见了,宏被替换了。
同理生成1.i文件

也是相同的处理。
当相同地编译运行1.h文件时,有了如下警告:
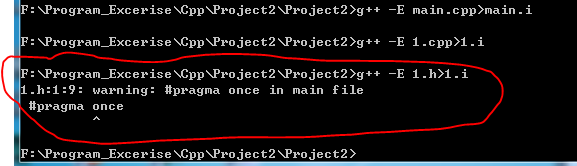
单词“pragma”就是编译指示的意思,警告你1.h只在main文件中编译一次,此操作不可行。
编译和优化
这个步骤作用如下:
词法分析 – 识别单词,确认词类;比如int i;知道int是一个类型,i是一个关键字以及判断i的名字是否合法。
语法分析 – 识别短语和句型的语法属性;
语义分析 – 确认单词、短语和句型的语义特征;
代码优化 – 修辞、文本编辑;
代码生成 – 生成译文。
内联函数的替换就发生在这一阶段
预编译和编译都是GCC来完成的。
编译
按照g++ –E main.cpp>main.i文件的语句写g++ –E main.i>main.s,然后报错了。

然后用g++ –E main.cpp>main.s也是相同的报错。
后来搜到有人使用g++ -S main.cpp,生成成功。.s文件表示是汇编文件,用编辑器打开就都是汇编指令。
.file "main.cpp"
.lcomm __ZStL8__ioinit,1,1
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "this is a macro!\0"
LC1:
.ascii "pause\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
leal 4(%esp), %ecx
andl $-16, %esp
pushl -4(%ecx)
pushl %ebp
movl %esp, %ebp
pushl %ecx
subl $36, %esp
call ___main
call __Z5printv
movl $LC0, 4(%esp)
movl $__ZSt4cout, (%esp)
call __ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc
movl $__ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, (%esp)
movl %eax, %ecx
call __ZNSolsEPFRSoS_E
subl $4, %esp
movl $1, -12(%ebp)
movl $5, -16(%ebp)
movl -12(%ebp), %edx
movl -16(%ebp), %eax
addl %edx, %eax
movl %eax, -20(%ebp)
movl -20(%ebp), %eax
movl %eax, (%esp)
movl $__ZSt4cout, %ecx
call __ZNSolsEi
subl $4, %esp
movl $__ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, (%esp)
movl %eax, %ecx
call __ZNSolsEPFRSoS_E
subl $4, %esp
movl $LC1, (%esp)
call _system
movl $0, %eax
movl -4(%ebp), %ecx
leave
leal -4(%ecx), %esp
ret
.def ___tcf_0; .scl 3; .type 32; .endef
___tcf_0:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl $__ZStL8__ioinit, %ecx
call __ZNSt8ios_base4InitD1Ev
leave
ret
.def __Z41__static_initialization_and_destruction_0ii; .scl 3; .type 32; .endef
__Z41__static_initialization_and_destruction_0ii:
pushl %ebp
movl %esp, %ebp
subl $24, %esp
cmpl $1, 8(%ebp)
jne L4
cmpl $65535, 12(%ebp)
jne L4
movl $__ZStL8__ioinit, %ecx
call __ZNSt8ios_base4InitC1Ev
movl $___tcf_0, (%esp)
call _atexit
L4:
leave
ret
.def __GLOBAL__sub_I_main; .scl 3; .type 32; .endef
__GLOBAL__sub_I_main:
pushl %ebp
movl %esp, %ebp
subl $24, %esp
movl $65535, 4(%esp)
movl $1, (%esp)
call __Z41__static_initialization_and_destruction_0ii
leave
ret
.section .ctors,"w"
.align 4
.long __GLOBAL__sub_I_main
.ident "GCC: (i686-posix-sjlj, built by strawberryperl.com project) 4.9.2"
.def __Z5printv; .scl 2; .type 32; .endef
.def __ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc; .scl 2; .type 32; .endef
.def __ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_; .scl 2; .type 32; .endef
.def __ZNSolsEPFRSoS_E; .scl 2; .type 32; .endef
.def __ZNSolsEi; .scl 2; .type 32; .endef
.def _system; .scl 2; .type 32; .endef
.def __ZNSt8ios_base4InitD1Ev; .scl 2; .type 32; .endef
.def __ZNSt8ios_base4InitC1Ev; .scl 2; .type 32; .endef
.def _atexit; .scl 2; .type 32; .endef
汇编咱也看不懂,咱也不敢说,只是看明白了1+5,add 了存在1和5的地址。
同理生成1.s文件。也是看不懂。
优化
优化处理是编译系统中一项比较艰深的技术。它涉及到的问题不仅同编译技术本身有关,而且同机器的硬件环境也有很大的关系。优化一部分是对中间代码的优化。这种优化不依赖于具体的计算机。另一种优化则主要针对目标代码的生成而进行的。上图中,我们将优化阶段放在编译程序的后面,这是一种比较笼统的表示。
对于前一种优化,主要的工作是删除公共表达式、循环优化(代码外提、强度削弱、变换循环控制条件、已知量的合并等)、复写传播,以及无用赋值的删除,等等。
后一种类型的优化同机器的硬件结构密切相关,最主要的是考虑是如何充分利用机器的各个硬件寄存器存放的有关变量的值,以减少对于内存的访问次数。另外,如何根据机器硬件执行指令的特点(如流水线、RISC、CISC、VLIW等)而对指令进行一些调整使目标代码比较短,执行的效率比较高,也是一个重要的研究课题。
经过优化得到的汇编代码必须经过汇编程序的汇编转换成相应的机器指令,方可能被机器执行。
详细可见下面链接,感谢原作者。
https://blog.csdn.net/qq_30647245/article/details/80558
生成目标文件
这一步是从汇编程序生成目标代码(机器代码)。
GCC语句是g++ -c main.cpp
功能:.o是GCC生成的目标文件,除非你是做编译器和连接器调试开发的,否则打开这种.o没有任何意义。二进制机器码一般人也读不了,就是下图这样。

链接
连接各个.o目标代码文件,生成可执行程序。必须已经生成1.o和main.o,这样才能链接需要的.o文件生成.exe。
g++语句为 g++ 1.o main.o -o Test.exe
双击生成的Test.exe
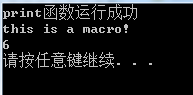
这样,完整的从源程序到exe就结束了。其中的g++命令语句参考链接为https://www.jianshu.com/p/e5e9925a6158,感谢原作者。
下面终于要进入今天的正题链接库是怎么回事?
什么是库?
库是写好的现有的,成熟的,可以复用的代码。现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始,因此库的存在意义非同寻常。本质上来说库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。库有两种:静态库(.a、.lib)和动态库(.so、.dll)。所谓静态、动态是指链接。

动态静态的区别
上面刚刚提到了静态链接库和动态链接库,如果采用静态链接库,则无论你愿不愿意,在链接程序时,lib中的指令都被直接(通过拷贝的方式)包含在最终生成的EXE文件中了,这是在第5步链接程序中可以知道的。动态链接库在链接程序时,只是记录了少量必要信息,在实际程序执行时才动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。所以,当单独执行debug文件或者release文件中的exe的时候,静态链接库不需要放在exe的目录下,但是动态链接库必须放在exe的目录下。
静态链接库
之所以成为静态库,是因为在链接阶段,会将汇编生成的目标文件.o与引用到的库一起链接打包到可执行文件中。因此对应的链接方式称为静态链接。
试想一下,静态库与汇编生成的目标文件一起链接为可执行文件,那么静态库必定跟.o文件格式相似。其实一个静态库可以简单看成是一组目标文件(.o/.obj文件)的集合,即很多目标文件经过压缩打包后形成的一个文件。静态库特点总结:
1 静态库对函数库的链接是放在编译时期完成的。
2 程序在运行时与函数库再无瓜葛,移植方便。
3 浪费空间和资源,因为所有相关的目标文件与牵涉到的函数库被链接合成一个可执行文件。
静态链接库的优点和缺点:
1.代码装载速度快,执行速度略比动态链接库快;
2.只需保证在开发者的计算机中有正确的.LIB文件,在以二进制形式发布程序时不需考虑在用户的计算机上.LIB文件是否存在及版本问题,可避免DLL地狱等问题。
3.使用静态链接生成的可执行文件体积较大,包含相同的公共代码,造成浪费;
lib文件是必须在编译期就连接到应用程序中的,而dll文件是运行期才会被调用的。如果有dll文件,那么对应的lib文件一般是一些索引信息,具体的实现在dll文件中。如果只有lib文件,那么这个lib文件是静态编译出来的,索引和实现都在其中。
静态链接库的创建方法
首先创建静态库,要封装的函数只是一系列子函数:
//main_test.cpp
#include
#include "1.h"
#define AA "this is a macro!"
void main_test()
{
#ifdef AA //我是main.cpp的注释
print();
std::cout << AA << std::endl;
#endif
int a = 1;
int b = 5;
int c = a + b;
std::cout << c << std::endl;
}
void my_func()
{
std::cout << "我是第二个函数" << std::endl;
}
//main_test.h
#pragma once
void main_test();
void my_func();
在工程属性里更改如下:不生成exe,就生成静态库lib
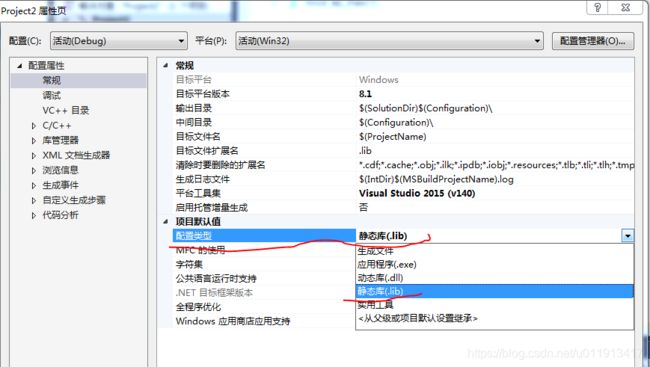
按F7或者点击生成解决方案之后就可以在Debug里看到生成的lib文件了。
lib的调用
将这里的.lib文件和.h文件拷贝,到要引用的目录下,#include “*.h”和#pragma comment (lib,".lib"),在当前工程中就可以直接用里面的函数了。lib文件还有其他方法添加,这里就不赘述了。
动态链接库
代码复用是提高软件开发 效率的重要途径。一般而言,只要某部分代码具有通用性,就可将它构造成相对独立的功能模块并在之后的项目中重复使用。比较常见的例子是各种应用程序框架, 如ATL、MFC等,它们都以源代码的形式发布。由于这种复用是“源码级别”的,源代码完全暴露给了程序员,因而称之为“白盒复用”。“白盒复用”的缺点比较多,总结起来有4点:
1 暴露了源代码;
2 容易与程序员的“普通”代码发生命名冲突;
3 多份拷贝,造成存储浪费;
4 更新功能模块比较困难。
实际上,以上4点概括起来就是“暴露的源代码”造成“代码严重耦合”。为了弥补这些不足,就提出了“二进制级别”的代码复用。使用二进制级别的代码复用一定程度上隐藏了源代码,对于缓解代码耦合现象起到了一定的作用。这样的复用被称为“黑盒复用”。
另一个问题是静态库对程序的更新、部署和发布页会带来麻烦。如果静态库liba.lib更新了,所以使用它的应用程序都需要重新编译、发布给用户(对于玩家来说,可能是一个很小的改动,却导致整个程序重新下载,全量更新)。
lib文件是必须在编译期就连接到应用程序中的,而dll文件是运行期才会被调用的。如果有dll文件,那么对应的lib文件一般是一些索引信息,具体的实现在dll文件中。如果只有lib文件,那么这个lib文件是静态编译出来的,索引和实现都在其中。
动态链接库的创建方法
创建动态库的方法略有不同。先是将属性里的配置类型改为动态库(dll)。
在头文件中需要加入宏命令。
#pragma once
#ifdef __DLLEXPORT
#define __DLL_EXP _declspec(dllexport) // 导出函数 - 生成dll文件时使用
#else
#define __DLL_EXP _declspec(dllimport) // 导入函数 -使用dll是使用
#endif // __DLLEXPORT
void main_test();
void my_func();
如果是生成dll文件,需要在属性->C\C+±>预处理器->预处理器定义中加上宏。
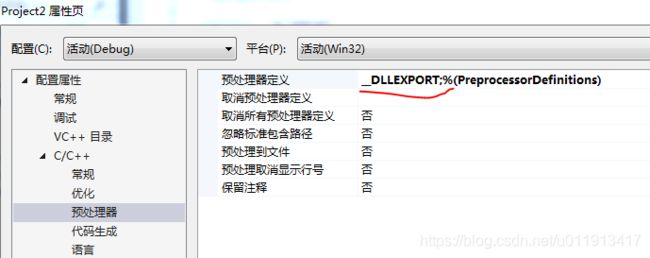
生成解决方案后在Debug中就生成了 .dll和.lib文件。我开始的时候怎么都只有dll,没有lib,后来参考别人的建议,在在工程上右键 -> 添加 -> 新建项 -> 选"模块定义文件(.def)" -> 随便输入个名字 -> 添加,添加的名字任意,可以默认,里面只有LIBRARY这一句,不用管,这时候再生成解决方案,Debug里就有lib和dll了。
def文件中内容要加上函数名
//Source.def
LIBRARY Project2
EXPORTS
main_test @1
my_func @2
注意:.def文件中的第一条 LIBRARY 语句不是必须的,但LIBRARY 语句后面的 DLL 的名称必须正确,即与生成的动态链接库的名称必须匹配。
EXPORTS 语句列出名称,可能的话还会列出 DLL 导出函数的序号值。通过在函数名的后面加上 @ 符和一个数字,给函数分配序号值。当指定序号值时,序号值的范围必须是从 1 到 N,其中 N 是 DLL 导出函数的个数。
main_test.cpp文件为:
#include
#include "main_test.h"
#pragma comment(lib, "Project2.lib")
void main()
{
main_test();
my_func();
system("pause");
}
F7生成解决方案就会生成dll、lib文件。
dll的使用
调用分为2种。
隐式链接
需要用到.dll、.lib和.h文件。
这里的.lib文件不再是静态链接库的意思,而是导入库的意思。
将三个文件复制到需要使用的工程目录中,
将.dll和.lib放在一个文件夹内。
测试工程main.cpp
#include
#include "main_test.h"
#pragma comment(lib, "ku\\Project2.lib")
void main()
{
main_test();
my_func();
system("pause");
}
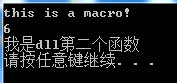
运行结果
显式链接
需要用到.dll和.h文件。
我暂时不需要用显式调用,所以以后用到再说。
That’s all. Let’s enjoy it ~