Ubuntu 22.04 安装Nvidia显卡驱动、CUDA、cudnn
GPU做深度学习比CPU要快很多倍,用Ubuntu跑也有一定的优势,但是安装Nvidia驱动有很多坑
Ubuntu版本:22.04.3 LTS
分区: /boot分配 1G ,剩下都分给根目录/
显卡:GTX 1050 Ti
坑1:用Ubuntu自带的 Additional Drivers可能会出问题,应该从官网下载驱动文件
坑2:用deb文件安装可能会出问题,最好用.run文件安装
0. 卸载自带驱动
删除自带的驱动
sudo apt purge nvidia*
禁用开源驱动nouveau
sudo vi /etc/modprobe.d/blacklist.conf
在尾部添加两行:
blacklist nouveau
options nouveau modeset=0
保存后更新一下,并重启系统
sudo update-initramfs -u
reboot
正式开始安装前,安装一下所需的软件包(可能需要):
sudo apt update
sudo apt install build-essential
sudo apt install python3-pip
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
1. 安装Nvidia显卡驱动
下载驱动安装文件NVIDIA-Linux-x86_64-535.113.01.run
下载地址:https://www.nvidia.cn/geforce/drivers/
535.113(linux runfile)下载地址:https://www.nvidia.cn/geforce/drivers/results/211913/
进入黑屏文本终端(关闭图形界面)
sudo telinit 3
输入用户名密码登录,然后结束桌面服务
sudo service gdm3 stop
进入.run下载好的目录
chmod +x *.run
sudo ./NVIDIA-Linux-x86_64-535.113.01.run
根据提示安装,如果出现错误,到网上搜索,安装成功后reboot
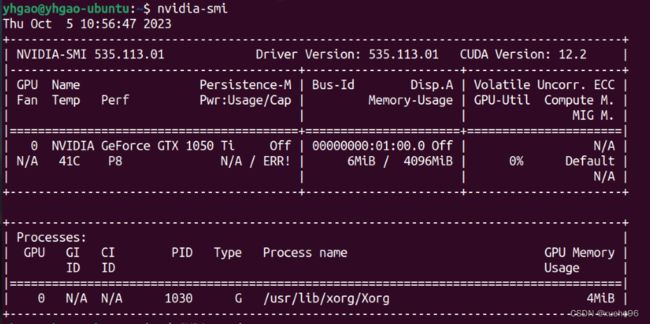
重启后通过 nvidia-smi 查看驱动是否装好
2. 安装CUDA
由于Pytorch需要CUDA11.8(https://pytorch.org/),因此装CUDA11
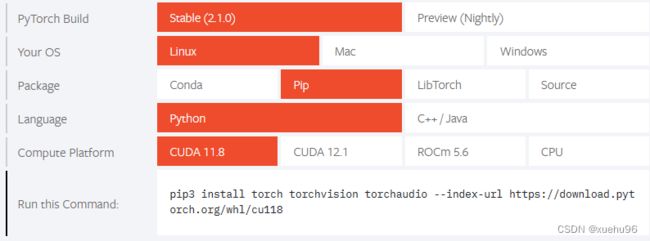
如果需要其他版本CUDA,也可以通过下面的链接找安装包
CUDA下载地址:https://developer.nvidia.com/cuda-toolkit-archive
CUDA11.8下载地址:https://developer.nvidia.com/cuda-11-8-0-download-archive?target_os=Linux

最后一个Installer Type一定要选 runfile deb文件安装可能是坑
进入.run 下载好的目录
chmod +x *.run
sudo ./cuda_11.8.0_520.61.05_linux.run
- 需要注意的是,安装CUDA过程中,如果出现
Install NVIDIA ...... Driver for linux ...?的提示,一定要输入N,否则之前安装的显卡驱动会被覆盖
最后,vi ~/.bashrc 在尾部添加三行:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.8/lib64
export PATH=$PATH:/usr/local/cuda-11.8/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.8
保存后source .bashrc应用
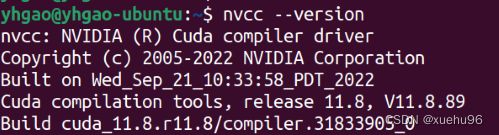
然后输入nvcc --version 试一下,有提示版本就对了
3. 安装cudnn_linux
cudnn下载地址:https://developer.nvidia.com/rdp/cudnn-download
下载cudnn-linux-x86_64-8.9.4.25_cuda11-archive.tar.xz以后, 解压到一个目录,进入这个目录后执行:
sudo cp cuda/include/cudnn* /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn*
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
4. 安装Pytorch、Tensorflow测试
安装pytorch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
安装tensorflow
pip3 install --upgrade tensorflow
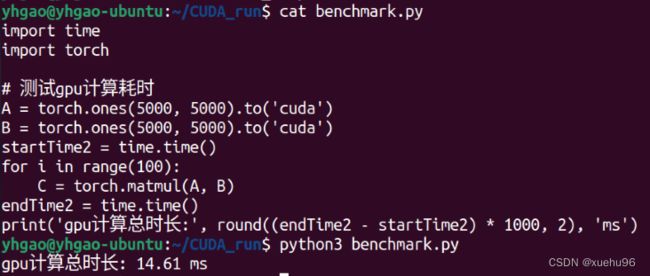
跑个代码试一试:
import time
import torch
A = torch.ones(5000, 5000).to('cuda')
B = torch.ones(5000, 5000).to('cuda')
startTime2 = time.time()
for i in range(100):
C = torch.matmul(A, B)
endTime2 = time.time()
print('gpu计算总时长:', round((endTime2 - startTime2) * 1000, 2), 'ms')