猅猅排牌牌『排序专题』
目录
零.基本概念
一.交换类
1.交换排序
2.冒泡排序
1.基本思想
2.算法步骤
3.优化操作
1.外循环优化
2.内循环优化
3.两种优化结合
4.双向冒泡排序【鸡尾酒排序】
4.稳定性
5.时间复杂度
3.快速排序
1.基本思想
2.算法步骤【单方向扫描分区】
3.优化操作
1.双向扫描分区
2.三指针扫描分区
3.随机化
4.插入排序
5.三数取中
4.稳定性
5.时间复杂度
*双路快速排序
一、概念及其介绍
二、适用说明
三、过程图示
*三路排序算法
一、概念及其介绍
二、适用说明
*小区间优化可用插入排序
二.选择类
1.普通选择排序
1.基本思想
2.算法步骤
3.优化操作
1.双最值选择
4.稳定性
5.时间复杂度
2.树形选择排序【锦标赛排序】
1.基本思路
2.算法步骤
3.稳定性
4.时间复杂度
5.空间复杂度
3.堆排序
1.基本思路
a.堆的定义
b.堆的性质
c.堆的操作
2.算法步骤
3.稳定性
4.时间复杂度
5.空间复杂度
三.插入类
1.直接插入排序『基于顺序查找』
1.基本思想
2.算法步骤
3.优化操作
1.折半插入排序『基于折半查找』
2.双向两路插入排序
3.设置哨兵位
4.稳定性
5.时间复杂度
2.链表插入排序『基于链表的存储结构』
3.希尔排序『基于逐趟缩小增量 gap』
1.基本思想
2.算法步骤
3.优化操作
1.折半查找
4.稳定性
5.时间复杂度
四.归并类
1.归并排序(Merge sort)
1.基本思想
2.算法步骤
3.优化操作
1.递归小区间插入优化
2.自底向上的归并【非递归】
4.稳定性
5.时间复杂度
6.空间复杂度
五.其他类
1.基数排序
1.基本思路
2.算法步骤
3.优化操作
1.链式队列
2.前缀和(无需队列)
4.稳定性
5.时间复杂度
6.空间复杂度
2.桶排序
1.基本思路
2.算法步骤
3.稳定性
4.时间复杂度
5.空间复杂度
零.基本概念
内部排序的过程是一个将已有有序序列不断扩大的过程。
【有序序列区不断增大,无序序列区不断减小】
交换类:交换序列中的记录,从而得到关键字最小或者最大的记录,并把它加入到有序序列中。
选择类:从无序序列中选择出关键字最小或者最大的关键字,再加入到有序序列中去。
插入类:将无序子序列中的一个记录插入到有序序列中。
归并类:将两个或两个以上的有序序列合并。
考察一个排序算法的性能,主要是考虑基本操作——也就是比较操作和移动操作的次数。
还有辅助的存储空间。
然后是算法本身的时间复杂度。
【一般来说需要将多种排序算法相结合:大的递归成小的,小的再用好的算法】

一.交换类
1.交换排序
最简单的一种排序方法
就是利用两个循环去遍历数组,列举出每一种可能。
【也就是两两比较,较大者放后面,较小者放前面】
void Exchange_Sort(int a[],int n)
{
for(int i=0; i2.冒泡排序
1.基本思想
相邻的元素之间两两比较,较小的数下沉(也就是留在左侧),较大的数上浮(也就是去往右侧),这样每走完一趟,最大值就会排列在右侧。
2.算法步骤
1.比较相邻元素。如果左侧大于右侧,则进行交换操作。
2.设置两层循环,内层循环用于对每一对相邻的数据,进行比较和交换操作。
3.外层循环用于控制遍历数据表的循环次数。
4.每一趟走完后,最右侧的数都是当前搜索范围内的最大值,固定后不需要再处理它。
void Bubble_Sort(int *a,int n)
{
int temp; //用于辅助交换操作,也可以用sort咯
for(int i=0; i3.优化操作
1.外循环优化
如果某次比较过程中,发现没有任何元素移动,则不再进行接下来的比较。具体的做法是在每趟比较时,引入一个变量flag,来判断下次比较还有没有必要进行。
//
a[0]:1 a[1]:5 a[2]:4 a[3]:3 a[4]:2 a[5]:8 a[6]:7 a[7]:6
第1次遍历后: a[0]:1 a[1]:4 a[2]:3 a[3]:2 a[4]:5 a[5]:7 a[6]:6 a[7]:8
第2次遍历后: a[0]:1 a[1]:3 a[2]:2 a[3]:4 a[4]:5 a[5]:6 a[6]:7 a[7]:8
第3次遍历后: a[0]:1 a[1]:2 a[2]:3 a[3]:4 a[4]:5 a[5]:6 a[6]:7 a[7]:8
第4次遍历后: a[0]:1 a[1]:2 a[2]:3 a[3]:4 a[4]:5 a[5]:6 a[6]:7 a[7]:8
本来要比较7次, 现在减少为了4次!void Bubble_Sort_Pro(int *a,int n)
{
int temp; //用于辅助交换操作,也可以用sort咯
for(int i=0; i缺点:如果开始了遍历,那么哪怕数组元素已经有序,也会把数据表遍历完全。
2.内循环优化
记录下最后一次发生交换的位置,由于后面没有进行交换了,那么必然是有序的
下一次排序只需要从第一个比较到上次记录的位置即可。
//
pos a[0]:1 a[1]:5 a[2]:4 a[3]:3 a[4]:2 a[5]:8 a[6]:7 a[7]:6
第1次遍历后: 6 a[0]:1 a[1]:4 a[2]:3 a[3]:2 a[4]:5 a[5]:7 a[6]:6 a[7]:8
第2次遍历后: 5 a[0]:1 a[1]:3 a[2]:2 a[3]:4 a[4]:5 a[5]:6 a[6]:7 a[7]:8
第3次遍历后: 1 a[0]:1 a[1]:2 a[2]:3 a[3]:4 a[4]:5 a[5]:6 a[6]:7 a[7]:8
第4次遍历后: 0 a[0]:1 a[1]:2 a[2]:3 a[3]:4 a[4]:5 a[5]:6 a[6]:7 a[7]:8void Bubble_Sort_X(int *a,int n)
{
int temp; //用于辅助交换操作,也可以用sort咯
int pos = n-1; //每一次遍历完后,最后一次进行交换的位置。多减去1,防止数组越界
for(int i=0; i3.两种优化结合
void Bubble_Sort_Pro_X(int *a,int n)
{
int temp; //用于辅助交换操作,也可以用sort咯
int pos = n-1;
for(int i=0; i4.双向冒泡排序【鸡尾酒排序】
遍历的过程可以从两端进行,从而提升效率。
冒泡排序其实也可以进行双向循环:
正向循环把最大元素移动到数组末尾,逆向循环把最小元素移动到数组首部。
void Bubble_Sort_Two_Way(int *a,int n)
{
int left = 0;
int right = n;
int i=0;
while(left4.稳定性
在冒泡排序中,遇到相等的值是不进行交换的,所以是稳定的排序方式。
5.时间复杂度
如果待排序序列的初始状态恰好是我们希望的排序结果(如升序或降序),一趟扫描即可完成排序。所需的关键字比较次数C和记录移动次数M均达到最小值:最好的时间复杂度为O(n)。
如果待排序序列是反序(如我们希望的结果是升序,待排序序列是降序)的,需要进行n-1趟排序。每趟排序要进行n-i次关键字的比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:最坏时间复杂度为O(n2)。
平均时间复杂度为O(n^2)。
3.快速排序
1.基本思想
任意选取待排序序列中的某个元素 v ,称之为—— 支点 / 基准 / 枢轴。
按照该元素 v 的关键字的大小,将整个序列划分成左右两个子序列:
以轴为分界线,从两侧往中间走,比轴小的交换到左侧,比轴大的交换到右侧。
最后,左侧子序列中的所有关键字都要小于等于 v ,右侧子序列中的所有关键字都要大于等于 v。而 v 则排在这两个子序列中间,也就是它最终的排放位置。『这里就直接确定了 v 的位置了』
然后再按此方法对这左右两个子序列分别进行快速排序。
整个排序过程可以递归进行,最后整个数组变成有序序列。
【二叉树的前序遍历,二分拆分数组!!!!】
“另一种描述”:
利用分治的思想将大问题转化成若干相同小问题。
在一组无序的数中,不断选定一个主元,将这个主元放到这组数合适位置(使主元左侧都小于主元,不保证依次有序;使主元右侧都大于主元,不保证依次有序)。然后不断递归调用,直到一组数完全有序。
2.算法步骤【单方向扫描分区】
1.先定主元,一般为数组的第一个值。
(要按它为中间值进行划分,其左侧小于他,不一定有序;其右侧大于他,不一定有序)
2.scan指针(指向主元的下一个值),移动指针,小于等于主元,scan指针继续往右移动。3.bigger指针(指向数组的最后一个值),如果scan指针遇到大于主元的值,将scan指针所指向的值与bigger指针所指向的值,进行交换,并且将bigger指针往前移动。
4.指针移动的前提条件是scan<=bigger。
5.利用递归不断缩小分区,实现快速排序。
1.先从数列中取出一个数作为基准数 pivot。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间递归式地重复第二步,直到各区间只有一个数为止。
【详细步骤 + 举例说明】
在一个数组中选择一个基点,比如第一个位置的 4,然后把4挪到正确位置。
使得之前的子数组中数据小于 4,之后的子数组中数据大于 4。
然后逐渐递归下去完成整个排序。
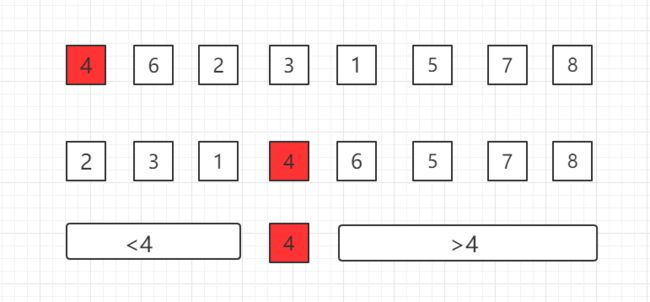
如何和把选定的基点数据挪到正确位置上,这是快速排序的核心。
我们称为 Partition。
过程如下所示,其中 i 为当前遍历比较的元素位置:

//
| !
[4] [6] [2] [3] [1] [5] [7] [8]
| !
[4] [8] [2] [3] [1] [5] [7] [6]
| !
[4] [7] [2] [3] [1] [5] [8] [6]
| !
[4] [5] [2] [3] [1] [7] [8] [6]
! |
[4] [1] [2] [3] [5] [7] [8] [6]
——————————————————————————————————————
[3] [1] [2] [4] [5] [7] [8] [6]
______________________________________
左:
| !
[3] [1] [2]
! |
[3] [1] [2]
! |
[2] [1] [3]
! |
[2] [1]
!
[1] [2]
右:同理//
int partion(int *a,int left,int right);
void Quick_Sort_Unit(int *a,int left,int right);
void Quick_Sort(int *a,int n);
int partion(int *a,int left,int right)
{
int temp = a[left]; //确定主元,并同时挖出这个空,一般选区间内的第一个数
int scan = left+1; //从第一个不是空的位置开始,也就是第二个数
int bigger = right; //指向子序列的最右侧,用于放置较大数
while(scan <= bigger)
{
if(a[scan] <= temp) //不断寻找大于temp的且在bigger左侧的数
scan++;
else //此时找到了符合要求的数
{
swap(a[scan],a[bigger]); //把该数换到bigger所指位置处
bigger--; //此时将bigger左移
Print(a,8);
}
//这里不管bigger所指的数是否比temp大,都要进行交换,是可以改进的点
}
//当scan > bigger时,bigger所指位置即为主元所应插入位置
swap(a[bigger],a[left]); //将bigger所指位置(是小于主元的数)与主元进行交换
Print(a,8);
return bigger; //返回该位置
}
void Quick_Sort_Unit(int *a,int left,int right)
{
if(left >= right)
return;
int mid = partion(a,left,right); //返回的是基准应当插入的位置
Quick_Sort_Unit(a,left,mid-1);
Quick_Sort_Unit(a,mid+1,right);
}
void Quick_Sort(int *a,int n)
{
Quick_Sort_Unit(a,0,n-1);
}
void Print(int *a,int n)
{
for(int i=0;i3.优化操作
1.双向扫描分区
【双指针法(对撞指针)】
1.定主元,一般以第1个为主元。
2.begin指针指向主元的下一个数,end指针指向数组的最后一个数。
3.工作原理非常类似单向扫描分区,不同之处在于:
双向扫描中的end指针每次也要进行判断并移动;
单向扫描中的bigger指针只在scan指针遇到比主元更大的数时,
然后与bigger指针所指的数交换之后才向前移动;
双向扫描的工作原理:
(1)begin指针所指向的数小于等于主元时,begin++,向后移动。
(2)end指针所指向的数大于主元时,end - - ,向前移动。
(3)当begin遇到比主元大的数,停止移动;当end遇到小于等于主元的数,停止移动;
(4)当两个指针都停止后,交换两个指针所指的数。【截止条件是:begin>end】
(5)将end所指的数与主元交换,就完成了划分,将本次主元放到了合适位置。
//
| !
[4] [6] [2] [3] [1] [5] [7] [8]
| !
[4] [6] [2] [3] [1] [5] [7] [8]
(交换一次)
| !
[4] [1] [2] [3] [6] [5] [7] [8]
(指针继续移动)
! |
[4] [1] [2] [3] [6] [5] [7] [8]
(完成交错就马上终止:交换主元和end所指——!)
——————————————————————————————————————
[3] [1] [2] [4] [6] [5] [7] [8]
(即交换[4]与[3])2.三指针扫描分区
在排序过程中容易出现:数组中存在大量相同的相同元素.
当这样的元素作为主元时,为了进一步提高效率,减小下一步的递归区间,可以将与主元相同的元素划分出去。也就是分成三个区间:
第一个区间是小于主元的值;
第二个区间是等于主元的值;
第三个区间是大于主元的值。
三指针扫描的工作原理:
1.定主元,一般是以数组第1个值为主元。
2.scan指针和 e 指针初始状况都是指向指向主元的下一个数,bigger指针指向最后一个元素。
当scan所指值小于主元时,scan所指元素与 e 所指元素交换,scan++后移,e++后移;
当scan所指值等于主元时,scan++后移;
当scan所指值大于主元时,scan所指值与bigger所指值交换,bigger - - 前移。
3.最后 e - - 前移,移动到第一个等于主元的元素的前一个。
4.然后将主元与此时 e 指针所指值交换,这样次趟就完成了将主元放到合适位置的任务。
5.反复递归剩下的无序区间,直到有序为止。
//
| —— begin指针
* —— equal指针
!—— bigger指针
|* !
[4] [6] [2] [3] [1] [5] [7] [8]
|* !
[4] [8] [2] [3] [1] [5] [7] [6]
|* !
[4] [7] [2] [3] [1] [5] [8] [6]
|* !
[4] [5] [2] [3] [1] [7] [8] [6]
|* !
[4] [1] [2] [3] [5] [7] [8] [6]
! |*
[4] [1] [2] [3] [5] [7] [8] [6]
!* |
[4] [1] [2] [3] [5] [7] [8] [6]
______________________________________
!* |
[3] [1] [2] [4] [5] [7] [8] [6]
另一个例子:
//
| —— scan 指针
* —— equal 指针
!—— bigger 指针
^^ 表示发生了交换
|* !
[4] [6] [2] [3] [4] [1] [5] [7] [8] [4]
|* !
[4] [4] [2] [3] [4] [1] [5] [7] [8] [6] ^^
* | !
[4] [4] [2] [3] [4] [1] [5] [7] [8] [6]
* | !
[4] [2] [4] [3] [4] [1] [5] [7] [8] [6] ^^
* | !
[4] [2] [4] [3] [4] [1] [5] [7] [8] [6]
* | !
[4] [2] [3] [4] [4] [1] [5] [7] [8] [6] ^^
* | !
[4] [2] [3] [4] [4] [1] [5] [7] [8] [6]
* | !
[4] [2] [3] [1] [4] [4] [5] [7] [8] [6] ^^
* | !
[4] [2] [3] [1] [4] [4] [5] [7] [8] [6]
* | !
[4] [2] [3] [1] [4] [4] [8] [7] [5] [6] ^^
* |!
[4] [2] [3] [1] [4] [4] [7] [8] [5] [6] ^^
* ! |
[4] [2] [3] [1] [4] [4] [7] [8] [5] [6] ^^ (无效交换哈哈)
* ! |
[4] [2] [3] [1] [4] [4] [7] [8] [5] [6] 【equal--】
____________________________________________________
* ! |
[1] [2] [3] [4] [4] [4] [7] [8] [5] [6] ^^
^ ^
| |
low high
void partion_Three_Way(int *a,int left,int right,int &low,int &high);
void Quick_Sort_Three_Way_Unit(int *a,int left,int right);
void Quick_Sort_Three_Way(int *a,int n);
void partion_Three_Way(int *a,int left,int right,int &low,int &high)//引用返回——等数值区域的左边界与右边界
{
int temp = a[left]; //确定主元,并同时挖出这个空,一般选区间内的第一个数
int scan = left+1; //扫描指针,从第一个不是空的位置开始,也就是第二个数
int equal = left+1; //相等指针
int bigger = right; //指向子序列的最右侧
while(scan <= bigger)
{
if(a[scan] < temp) //不断寻找大于temp的且在bigger左侧的数
{
if(scan != equal)
{
swap(a[scan],a[equal]);
Print(a,10);
}
scan++;
equal++;
}
if(scan > bigger) //一旦完成交错就马上终止
break;
while(a[scan] == temp)
scan++;
if(scan > bigger) //一旦完成交错就马上终止
break;
if(a[scan] > temp) //此时找到了符合要求的数
{
swap(a[scan],a[bigger]); //把两个数交换位置
bigger--;
Print(a,10);
}
}
equal--;
//当scan > bigger时,bigger所指位置即为主元所应插入位置
swap(a[equal],a[left]); //将bigger所指位置(是小于主元的数)与主元进行交换
Print(a,10);
low = equal;
high = bigger;
}
void Quick_Sort_Three_Way_Unit(int *a,int left,int right)
{
if(left >= right)
return;
int low; //等数值区域的左边界
int high; //等数值区域的右边界
partion_Three_Way(a,left,right,low,high);
Quick_Sort_Three_Way_Unit(a,left,low-1);
Quick_Sort_Three_Way_Unit(a,high+1,right);
}
void Quick_Sort_Three_Way(int *a,int n)
{
Quick_Sort_Three_Way_Unit(a,0,n-1);
}3.随机化
如果是对近乎有序的数组进行快速排序,每次 partition 分区后子数组大小极不平衡。
容易退化成 O(n^2) 的时间复杂度算法。
【快速排序会退化为冒泡排序】
我们需要对上述代码进行优化,随机选择一个基点做为比较,并非一定要从第一个数开始。
4.插入排序
当待排序序列的长度分割到一定大小 (如 < 10) 后,使用插入排序。
5.三数取中
前提背景:
在选择基准值的时候,越靠近中间,性能越好;越靠近两边,性能越差。
第三版随机选一个数进行划分的目的就是让好情况和差情况都变成概率事件。
把每一种情况都列出来,会有每种情况下的时间复杂度,但概率都是1/N。
那么所有情况都考虑,时间复杂度就是这种概率模型下的长期期望。
时间复杂度O(N*logN),额外空间复杂度O(logN)都是这么来的。
选取基准值时,不再取固定位置(如第一个元素、最后一个元素)的值。
因为这种固定取值的方式在面对随机输入的数组时,效率是非常高的。
但是一旦输入数据是有序的,使用固定位置取值,效率就会非常低。
因此为了避免这种情况,需要在每次划分之前,进行预处理操作。
方法一:先对 rs,rt,r(s+t)/2 ,相互进行比较,然后取中间大小的元素为枢轴。
方法二:引入了三数取中,即在数组中随机选出三个元素,然后取三者的中间值做为基准值。
4.稳定性
在使用快速排序时,每次元素分堆都要选择基准因子。
此时,基准因子两边都有可能出现和基准因子相同的元素。
如序列[1,3,2,4,3,4,6,3],如果选择了a[4]作为基准因子,那么a[1]和a[7]势必会被分到同一侧。
序列的稳定性被破坏。
所以,快速排序是一种不稳定的排序算法。
5.时间复杂度
平均运行时间是 O(n*logn),之所以特别快是由于非常精练和高度优化的内部循环。
最坏的情形性能为 O(n^2)。
像归并一样,快速排序也是一种分治的递归算法。
从空间性能上看,快速排序只需要一个元素的辅助空间。
但快速排序需要一个栈空间来实现递归,因此空间复杂度也为O(logn)。
快速排序的适用场景是:待排序序列元素较多,并且元素较无序。
*双路快速排序
一、概念及其介绍
partition 过程使用两个索引值(i、j)用来遍历数组
v 代表标定值
将小于 v 的元素放在索引 i 所指向位置的左边
而将大于 v 的元素放在索引 j 所指向位置的右边
二、适用说明
时间和空间复杂度同随机化快速排序
平均运行时间是 O(nlogn)
空间复杂度为O(logn)
对于有大量重复元素的数组,如果使用随机化快速排序效率是非常低的
导致 partition 后大于基点或者小于基点数据的子数组长度会极度不平衡
甚至会退化成 O(n*2) 时间复杂度的算法
对这种情况可以使用双路快速排序算法
三、过程图示
使用两个索引值(i、j)用来遍历我们的序列
将 小于等于v 的元素放在索引 i 所指向位置的左边
而将 大于等于v 的元素放在索引 j 所指向位置的右边
平衡左右两边子数组

#include
#include
#include
void Quick_Sort(int a[],int left,int right)
{
if(left>=right)
return;
int i=left; //计数器i初始化在该区间的最左侧
int j=right; //计数器j初始化在该区间的最右侧
srand(time(NULL));
int h=rand()%(right-left+1)+left; //随机选一个数,其位置在区间内,并除开第一个数
int temp;
temp=a[left];
a[left]=a[h];
a[h]=temp; //将随机的某个数与区间内第一个交换,就相当于随机抽取一个数作为基准
while(i=a[left]) //从右往左去比较,直到找到第一个比基准点小的数为止
{
j--;
}
while(i *三路排序算法
一、概念及其介绍
三路快速排序是双路快速排序的进一步改进版本
把排序的数据分为三部分
分别为小于 v,等于 v,大于 v(v 为标定值)
这样三部分的数据中,等于 v 的数据在下次递归中不再需要排序
二、适用说明
时间和空间复杂度同随机化快速排序
使用三路划分策略对数组进行划分
对处理大量重复元素的数组非常有效
它添加处理等于划分元素值的逻辑
将所有等于划分元素的值集中在一起
三、过程图示

我们分三种情况进行讨论 partiton 过程,i 表示遍历的当前索引位置:
(1)当前处理的元素 e=V,元素 e 直接纳入蓝色区间,同时i向后移一位。
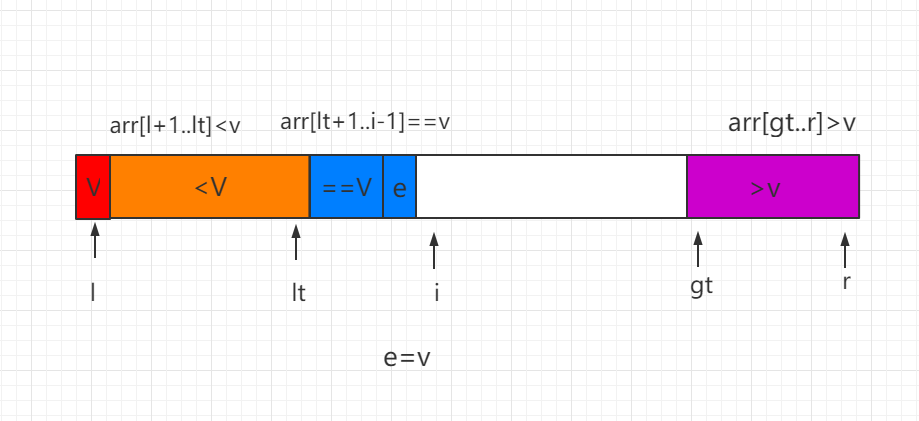
(2)当前处理元素 e (3)当前处理元素 e>v,e 和 gt-1 索引位置的数值进行交换,同时 gt 索引向前移动一位。 最后当 i=gt 时,结束遍历,同时需要把 v 和索引 lt 指向的数值进行交换,这样这个排序过程就完成了,然后对 但是问题在于怎么高效地将序列划分为三部分! 我们可以设置四个游标,左端a、b,右端c、d b、c的作用跟之前两路划分时候的左右游标相同 就是从两端向中间遍历序列,并将遍历到的元素与pivot比较 如果等于pivot,则移到两端(b对应的元素移到左端,c对应的元素移到右端) 移动的方式就是拿此元素和a或d对应的元素进行交换 所以a和d的作用就是记录等于pivot的元素移动过后的边界 反之,如果大于或小于pivot,还按照之前两路划分的方式进行移动 这样一来,中间部分就和两路划分相同,两头是等于pivot的部分 我们只需要将这两部分移动到中间即可 当快排不断递归处理子区间时,随着子区间的不断缩短,子区间数量快速增加。 普通选择排序 每一次遍历,都从数据表中中选出最小(或最大)的元素,存放在序列的起始位置。 1.首先在 未排序序列 中找到最小(大)元素,存放到排序序列的起始位置。 在一趟遍历中同时找出最大值与最小值,放到数组两端,这样就能将遍历的趟数减少一半。 在选择排序中,每趟都会选出最大元素与最小元素,然后与两端元素交换。 选择排序的时间复杂度为O(n^2)。 【目的是减少选择排序中的重复比较次数】 一开始,在 n 个关键字中选出最小值,肯定需要进行 n-1 次比较。 1.对 n 个关键字两两一组进行比较,决出较小者,ceil(n / 2) 个。 树形选择排序方法是稳定的。 ————O(n*log2n)。 ————O(n)。 利用前一次比较的结果,减少“比较”的次数。 把具有如下性质的数组 A 表示的完全二叉树称为小根堆: 1. 若 2*i ≤ n,则 A[ i ].key ≤ A[ 2*i ].key ; 2. 若 2*i+1 ≤ n,则 A[ i ].key ≤ A[ 2*i+1 ].key。 把具有如下性质的数组 A 表示的完全二叉树称为大根堆: 1. 若 2*i ≤ n,则 A[ i ].key ≥ A[ 2*i ].key ; 2. 若 2*i+1 ≤ n,则 A[ i ].key ≥ A[ 2*i+1 ].key。 1.对于任意一个非叶结点的关键字,都不大于其左、右儿子结点的关键字: 2.在堆中,以任意结点为根的子树仍然是堆。 3.在堆中(包括各子树对应的堆),其根结点的关键字是最小的,且去掉堆中编号最大的叶结点后,仍然是堆。 若将此序列对应的一维数组看成一个完全的二叉树。 若输出堆顶的最小值后,让剩余n-1个元素的序列重建成一个堆,则得到n个元素的次小值。 【以堆的规模不断扩大的方式进行初始建堆】 排序需解决两个问题: (1) 由一个无序序列建成一个堆。 堆排序的算法(采用大根堆) 1.按关键字建立A[1],A[2],…A[n]的大根堆; 2.输出堆顶元素,采用堆顶元素A[1]与最后一个元素A[n]交换,最大元素被放到了正确的位置; 3.此时前n-1个元素不再满足堆的特性,需重建堆;【自底向上调整】 4.循环执行2,3两步,到排序完成。 堆排序是不稳定的排序。 ——————O(nlog2n)。 ——————O(1)。 一般被称为直接插入排序。 基本思想是将一个记录插入到已经排好序的有序表中,从而一个新的、记录数增 1 的有序表。 将初始数据分为有序部分和无序部分,每一次遍历将一个无序部分的数据插入到前面已经排好序的有序部分中,直到插完所有元素为止。 在其实现过程使用双层循环: 1.外层循环从第二个元素开始,从无序部分中取出一个元素。 2.内层循环,在前面已经排好序的有序表中,查找合适的待插入位置,并移动数据以留出空位。 运用二分的思想来进行优化。 Q : 折半查找中如果查找失败返回的 left,mid,right 的含义是什么呢? 如果选取的是左闭右闭区间,那么跳出循环的时候为 left > right 。【实际上就是 left = right +1】 可以看到,此时 mid 所在位置并不固定,而 right 始终为 left+1 ,因此不能使用 mid 进行操作。 缺点:该移动元素的时候,还是要顺序遍历一遍捏。 在折半插入排序的基础上再进行改进,其目的是减少排序过程中移动记录的次数。 1.假设原数组为arr,设置一个辅助数组 tempArr,先将arr[0]赋值给tempArr[0]。 2.此时将 tempArr[0] 看成是在有序序列中处于中间位置的元素,运用循环数组的特性来操作。 3.先将待插入元素和 tempArr[0] 做比较: 4.设置辅助变量 left 和 right 指向有序序列中的第一个元素和最后一个元素在tempArr中的位置。 5.在实现算法时,可将tempArr看成一个循环数组。 循环数组中的下标细节:【这里 n 代表的是数组的长度】 2.对于下标减 1 : num = (num - 1 + n) % n; 3.对于取中间位置的下标 :如果起始点下标在终端点下标的左侧,那么则直接相加除以 2 ; 反之,则为 mid = (left + right + n)/ 2 。 此处不做详细阐述了,需要牺牲 a【0】来充当哨兵捏,这样可以省去对数组边界的判断了。 在使用插入排序时,元素从无序部分移动到有序部分时,必须是不相等时才会移动。 平均时间复杂度也是 O(n^2),空间复杂度为常数阶 O(1)。 具体和数组的有序性也是有关联的。 当待排序数组是有序时,是最优的情况,只需比较 N-1 次,时间复杂度为 O(N)。 最坏的情况是待排序数组是逆序的,此时需要比较次数最多,最坏的情况是 O(n^2)。 静态链表:对于一个有序的循环链表,当我们插入一个新的元素时,只需要改变指针的指向即可,不需要移动或者交换元素。 使用头结点,且头结点中的数据域中的值应当不小于序列中的最大值。 ————未完待续———— 【Shell_Sort】(又称缩小增量排序) 针对直接直接插入排序算法的改进——比较相距一定间隔的元素。 先进行宏观调整,也就是跳跃式的插入排序,再进行微观调整。 分成若干个子序列,分别进行插入排序,其中 d 为增量。 1.选取合适的 gap ,划分成若干个逻辑数组,每个逻辑数组内各自独立地进行直接插入排序。 —————————————————————————————————————————————————————————————————————————————————————— 在此选择增量 gap=length/2 缩小增量以 gap = gap/2 的方式,用序列 {n/2,(n/2)/2...1} 来表示。 如图示例: (1)初始增量第一趟 gap == length/2 ==4 (2)第二趟,增量缩小为 2 (3)第三趟,增量缩小为 1,得到最终排序结果 进行希尔排序时,在不同的逻辑分组中,有可能将相同元素的相对位置改变。 如 [2,2,4,1],按间隔为2,降序排序,前两个元素的相对位置就会改变。 因此,希尔排序是不稳定的排序方式。 希尔排序时间复杂度是 O(n^(1.3-2)),空间复杂度为常数阶 O(1)。 希尔排序没有时间复杂度为 O(n(logn)) 的快速排序算法快 ,因此对中等大小规模表现良好。 对规模非常大的数据排序不是最优选择,但比一般 O(n^2 ) 复杂度的算法快得多。 归并排序适用于数据量大,并且对稳定性有要求的场景。 采用分治法。(Divide and Conquer)—— 将已有序的子序列合并,得到完全有序的序列。 即先使每个子序列有序,再让子序列段之间排好顺序。 【若将两个有序表合并成一个有序表,称为二路归并,同理也有多路归并】 归并排序是递归算法的一个实例——这个算法中基本的操作是合并两个已排序的数组。 1.取两个输入数组 A 和 B,一个输出数组 C 。 2.设置三个计数器 i、j、k,它们初始位置置于对应数组的开始端。 3.将A[ i ] 和 B[ j ] 中较小者拷贝到 C 中的下一个位置,相关计数器向前推进一步。 4.当两个输入数组有一个用完的时候,则将另外一个数组中剩余部分拷贝到 C 中。 【自顶向下的归并排序,递归分组图示】 【对第三行两个一组的数据进行归并排序】 【对第二行四个一组的数据进行归并排序】 【整体进行归并排序】 *归并排序和前面那些排序有一点不同的是: 归并中用到了递归,且使用了一个新数组用于保存有序数列。 而其他排序都是在修改原数组中的元素排放顺序。 当子集合的元素很少时,归并算法多数时间消耗在递归的处理上。 所以,当划分的子区间够小时(一般认为 <= 15 个元素),采用插入排序法,能够加快排序过程。但要注意插入排序函数放置的位置! 10000个数据时,优化前:0.047s;优化后:0.007s 。 50000个数据时,优化前:1.027s;优化后:0.012s 。 200000个数据时,优化前:15.375s;优化后:0.036s 。(!!!) 归并算法也可以不依赖递归,实现自底向上的归并。 对于非 2^n 个元素的序列,排序时总是残留一个小于每次合并size的子序列,例如7这个元素。 10000个数据时,优化前:0.047s;优化后:0.006s (版本一)0.007s(版本二)。 50000个数据时,优化前:1.027s;优化后:0.011s (版本一)0.015s(版本二)。 200000个数据时,优化前:15.375s;优化后:0.031s (版本一)0.046s(版本二)。 版本一:辅助数组充当参数,且一次性申请了等长度的辅助空间。 版本二:辅助数组在函数中临时申请,且每次只申请了当前子序列长度的辅助空间。 归并排序是稳定的排序方法。 当有 n 个记录时,需进行 logn 轮归并排序。 归并排序时需要和待排序记录个数相等的存储空间,所以空间复杂度为 O(n)。 1.对于基于关键字之间比较的排序,无论用什么方法都至少需要进行 log2(n!) 次比较。 2.基于关键字比较的排序时间的下界是O(nlog2n)。 因此不存在时间复杂性低于此下界的基于关键字比较的排序。 只有不通过关键字比较的排序方法,才有可能突破此下界。 基数(radix): 基数排序——时间复杂性可达到线性级O(n)。 1.不比较关键字的大小,而根据构成关键字的每个分量的值 ,排列记录顺序。 【称为分配法排序 / 基数排序】 2.把关键字各个分量所有可能的取值范围的最大值(取值情况的总数)称为 基数 / 桶 / 箱。 适用范围:要求关键字分量的取值范围必须是有限的,否则可能要无限多的桶。 设待排序的序列的关键字都是位数相同的整数,不相同时,取位数的最大值。 每个关键字可以各自含有 figure 个分量; 1.首先把全部数据装入一个队列A。 2.初态:设置 figure 个队列,分别为Q【0】、Q【1】……Q【figure-1】,且均为空队列。 3.分配:依次从队列A中取出每个数据 data 。 【另一种表述:从最低位(个位)开始,扫描关键字的 pass 位,等于 r 的插入 Q【r】中去】 4.收集:从Q【0】开始,依次取出Q【0】、Q【1】……Q【figure-1】中的全部数据。 5.pass++,然后重复2、3、4,直到进行了 figure 次。 具体案例: emmm,队列版本就不再实现了。 ——————有时间再弄—————— 如果采用数组表示队列,则长度很难确定, 太大造成浪费,太小会产生溢出。 一个队列有两个指针:头指针和尾指针。 收集过程: 每个队列的最后一个结点指向下一个队列的第一个结点。 将所有关键字都收集到Q【0】中。 顺序需要入队和出队操作,但是链式只需要修改指针就可以了。 【直接简化步骤】 基数排序是稳定的。 设关键字位数为 d,则时间复杂性为O(d*n)。 空间复杂性O(n)。 ————————新增内容: ①LSD–Least Significant Digit first 从低位(个位)向高位排。 图解 对a[n]按照个位0~9进行桶排序: 对b[n]进行累加得到c[n],用于b[n]中重复元素计数 temp数组为排序后的数组,写回a[n]。temp为按顺序倒出桶中的数据(联合b[n],c[n],a[n]得到),重复元素按顺序输出: 计数排序是一个非基于比较的排序算法。 它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中 k 是整数的范围),快于任何比较排序算法。 当然这是一种牺牲空间换取时间的做法,而且当 1.找出待排序的数组中最大和最小的元素。 计数排序是稳定的。 ————————O(n+k) ————————O(k) 【桶排序是计数排序的升级版】 它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。 为了使桶排序更加高效,我们需要做到这两点: 1.在额外空间充足的情况下,尽量增大桶的数量。 2.使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中。 同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。 把计数排序中相邻的m个”小桶”放到一个”大桶”中。 适用于数据分配均匀,数据比较大,相对集中的情况。 1.把待排序序列中的数据根据函数映射方法分配到若干个桶中。 元素分布在桶中: 然后,元素在每个桶中排序: 桶排序是稳定的。 1.最好时间复杂度 : O(n + k) 当输入的数据可以均匀的分配到每一个桶中。 当数据是均匀分散排列的,每个桶分到的数据个数都是一样的,这个步骤需要O(k)的时间复杂度。 在对每个桶进行排序的时候,最好情况下是数据都已经是有序的了,那么最好的排序算法的时间复杂度会是O(n),因此总的时间复杂度是 O(n + k) 。 2.最坏时间复杂度:O(n^2) 当输入的数据被分配到了同一个桶中,所使用的排序算法,最坏情况下是O(n^2),因此总的最坏情况下的时间复杂度为O(n^2)。 平均时间复杂度:O(n + n²/k + k) <=> O(n) 如果k是根据Θ(n)来获取的,那么平均时间复杂度就是 O(n)。 ————————O(n) 首先是空间复杂度比较高,需要的额外开销大。 其次待排序的元素都要在一定的范围内。 一位农场主在对自己的牛群产奶量作统计,想找出“中位数”母牛的产奶量。 算法的平均时间复杂度不得大于(log2) 。 1 ≤ k ≤ n ≤ 1000 算法的平均时间复杂度不得大于(log2) 。 统计同学们空闲的时间段,故需要统计人数最多的时间段,从而调配疫苗的供应量。 首先输入两个数字N,M,表示N个空闲时间段,M个学生。 程序输出成对的数字,表示空闲人数最多时间段的起始时间和终止时间。 当两个时间段的空闲学生不完全一致时,我们认为其为不同时间段。 要求:排序算法的平均时间复杂度不得大于 (log2)。 小明是一个年轻有为的小伙子,对自己的未来充满了期待和希望。他对生活有着清晰的规划和计划,其中最重要的一项就是在S市买一套自己的房子。他知道这并不容易,但他相信这是他人生中最重要的决定之一,值得冒险一试。 为了实现这个目标,小明不得不想办法借一笔房贷。不幸的是,小明在两年前因为睡过了头忘记还款导致自己的信用卡逾期了,这让他的信用评分降低了很多。由于他的信用评分太低,天使银行不愿意给他贷款。沮丧的小明最终找到了恶魔银行。 众所周知,恶魔银行的借贷利率非常高,而且按日计息。尽管有些不安,但他决定冒险一试。他提交了申请,并很快就得到了批准。最终,小明买了一套他梦寐以求的房子,并开始还贷。 不幸的是,恶魔银行的贷款合同上并没有写明真正的利率,现在小明想要计算一下真正的利率是多少。 思路:通过借贷金额 X 、每日还款数额 Y 、总共的还款时间 T 来计算日利率。 数学公式: 利息 = 本金 × 实际天数 × 日利率 利息 = 借款金额 × 贷款天数 × 日利率 日利率 = 年利率 ÷ 365 在使用日利率计算公式时,需要注意以下几点: 1. 年利率必须是实际年利率,即包括所有费用和利息的总和。 2. 365是指一年中的实际天数,包括闰年和平年。 3. 日利率计算公式只适用于按日计息的贷款、存款和投资。如果计息周期不是一天,需要使用其他公式进行计算。 这里的不一样!!! 期中考试结束了,张老师有一份原始的成绩单,这份成绩单是基于学号排序的。 尽管现在的新规定要求不允许公布排名,但是张老师是一个非常认真负责的老师,他希望考察一下班里学生的进步与退步。为此,他希望你能帮他将这份成绩单按照一定的规则排序。 成绩单包括语文、数学、 英语、科学、政治五门课程的成绩。张老师会给出每门课的权重和优先级,请你按照相应的权重计算加权总分并以此为依据执行降序排序。当加权总分相等时,你需要按照给出的优先级顺序基于其原始成绩进行排序。优先级表示为 1,2,3,4,5 一共五个整数,其中 1 表示优先级最高。当两位同学成绩完全一致时,请你按照学号升序排序。 重点在于条件处理,也就是排序规则理解: 最近,Tom和Jerry在上数据分析课。今天的课程内容是一个人类称之为“逆序对”的东西。 逆序对的定义如下: 对于给定的一段正整数序列 {a_i} ,逆序对就是序列中满足 a_i > a_j 且 < 的有序对。 学习了这个概念后,他们决定比赛谁先算出给定的一段正整数序列中逆序对的数目。 可怜的 Tom 还在研究如何更快的暴力求解,你能帮 Jerry 想出一个更快的方法吗? 注:序列中可能有重复数字。 需要比较 a[i] 和 a[j] 的大小,其中 i 在 j 的左侧。 归并排序利用分治思想,先把原始数组不断“分”,分成只有一个元素的“有序”序列。 1.树状数组,又称二进制索引树,英文名Binary Indexed Tree。 a.可以解决大部分区间上面的修改以及查询的问题: 1.单点修改,单点查询 2.区间修改,单点查询 3.区间查询,区间修改 线段树能解决的问题,树状数组大部分也可以,但是并不一定都能解决,因为线段树的扩展性比树状数组要强。树状数组的作用就是为了简化线段树,某些简单的问题,我们没必要用到功能性强但实现复杂的线段树(杀鸡焉用宰牛刀)。 b.用来求前缀和,可以把时间复杂度从O(n)降到O(log10 n)。 假如我们要求从1~1000的前缀和,普通方法需要遍历1000次,而树状数组只需要遍历5次。 优点:修改和查询操作复杂度与线段树一样都是O(logN),但是常数比线段树小,并且实现比线段树简单。 缺点:扩展性弱,线段树能解决的问题,树状数组不一定能解决。 它是在二叉树的结构上删除了一些中间节点。 这是二叉树的结构 这就和树状数组的一些性质(lowbit)有关了。 如何计算一个非负整数n在二进制下的最低为1及其后面的0构成的数? 2.性质: 1.底部确定,顶部无穷大。 【a[4]代表的是a[1]+a[2]+a[3]+a[4],a[5]就是自己】 可以看出每次最后的一个结点的下标必定是2的次方。 因为只需要跳到最外面的一个结点就不需要在往下求了,而最外面的结点一定是2的n次方。 
#include*小区间优化可用插入排序
用快排处理这些区间很小且数量很多的子区间时,系统要为每次的函数调用分配栈帧空间。
因此当待排序序列的长度分割到一定大小后,继续分割的效率比插入排序要差。
此时使用插入排序对其优化。#include二.选择类
树形选择排序【锦标赛排序】
堆排序1.普通选择排序
1.基本思想
2.算法步骤
2.以此类推,直到所有元素均排序完毕。void Choose_Sort(int a[],int n)
{
int temp;
int index;
for(int i=0; i3.优化操作
1.双最值选择
void Choose_Sort_Pro(int a[],int n)
{
int temp;
int index_min;
int index_max;
for(int i=0,k = n-1; i<=k; i++,k--)
{
index_min = i;
index_max = k;
for(int j=i; j<=k; j++)
{
if(a[index_min]>a[j])
index_min = j; //记录当前的最小数值所在位置
if(a[index_max]4.稳定性
此时,待排序序列中如果存在与原来两端元素相等的元素,稳定性就可能被破坏。
所以选择排序是一种不稳定的排序算法。5.时间复杂度
2.树形选择排序【锦标赛排序】
1.基本思路
但是如果继续在剩余的 n-1 个关键字中选择次小值,则并非一定要比较 n-2次。
我们利用好前 n-1 次比较的信息即可减少后续遍历中的比较次数捏。
例如,在8个运动员中决出前三名,则至多需要11场比赛,而不是18场比赛(7+6+5)。
【前提是如果甲能赢乙且乙能赢丙,那么甲一定能赢丙,也就是必须是全序关系】2.算法步骤
2.依次操作,每次都能减少大约一半的数目,直到选出最小的关键字为止。
3.把先前放置最小关键字的位置设置成无穷『避免影响后续操作捏』,再去选出次小值。
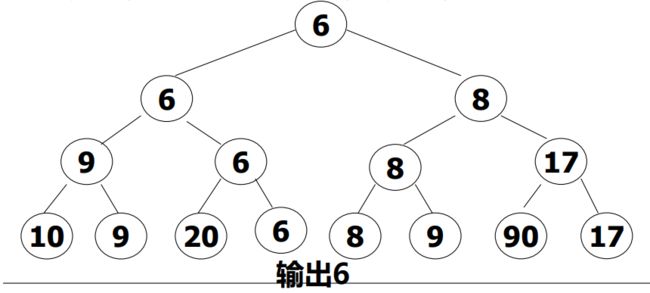

3.稳定性
4.时间复杂度
5.空间复杂度
3.堆排序
1.基本思路
也就是在找出关键字值最小记录的同时,也找出关键字值较小的记录。
可减少后面的选择中所用的比较次数,从而提高整个排序过程的效率。a.堆的定义
b.堆的性质
1.A[ i/2 ].key ≤ A[ i ].key ;
2.A[ i ].key ≤ A[ 2*i ].key && 2*i <= n && A[ i ].key ≤ A[ 2*i ].key;
【1 ≤ i/2 < i ≤ n】
【特别地,每个 叶结点也可视为堆】【每个结点都代表(是)一个堆】
c.堆的操作
堆的含义表明:完全二叉树中所有非终端节点的值均不大于(或不小于)其左右儿子的值。
如此反复执行,便得到一个有序序列,这个过程称为“堆排序”。
【以堆的规模逐渐缩小的方式进行“堆排序”】 2.算法步骤
(2) 在输出堆顶元素之后,调整剩余元素成为一个新的堆。void Heap_Adjust_max(int *a,int index,int n)//这里是大根堆算法(根最大)
{
int temp = a[index]; //开始时,需要第一个调整的数
for(int i=2*index; i<=n; i*=2) //从它的双亲结点开始
{
if(i+1 <= n && a[i] < a[i+1]) //如果有右兄弟结点,且右兄弟更大
i++; //则优先与右兄弟进行调换
if(temp >= a[i]) //比当前结点大(或者相等),符合要求则直接跳出循环
break;
a[index] = a[i]; //比当前结点小,不符合要求,把结点下移,留出空位,然后继续调整
index = i; //移动到双亲结点处,再判断需不需要继续调整
}
a[index] = temp; //此时,找到了合适的位置,直接放入即可(因为已经留出了空位)
}
void Heap_Adjust_min(int *a,int index,int n)//这里是小根堆算法(根最小)
{
int temp = a[index]; //开始时,需要第一个调整的数
for(int i=2*index; i<=n; i*=2) //从它的双亲结点开始
{
if(i+1 <= n && a[i] > a[i+1]) //如果有右兄弟结点,且右兄弟更小
i++; //则优先与右兄弟进行调换
if(temp <= a[i]) //比当前结点小(或者相等),符合要求则直接跳出循环
break;
a[index] = a[i]; //比当前结点大,不符合要求,把结点下移,留出空位,然后继续调整
index = i; //移动到双亲结点处,再判断需不需要继续调整
}
a[index] = temp; //此时,找到了合适的位置,直接放入即可(因为已经留出了空位)
}
void Heap_Sort(int *a, int n)
{
int *temp = (int*)malloc(sizeof(int)*(n+1));
//辅助数组用于创建小根堆(或者大根堆)
memcpy(temp,a,sizeof(int)*n);
for(int i=n/2; i>0; i--) //建堆过程
Heap_Adjust_min(temp,i,n); //从下向上,从右向左调整
for(int i=n; i>1; i--) //堆排序过程
{
a[n-i] = temp[1]; //输出并赋值给原数组
swap(temp[1],temp[i]);
Heap_Adjust_min(temp,1,i-1); //从上到下,从左向右调整
}
a[n-1] = temp[1]; //将最后一个数输出并赋值给原数组
}
3.稳定性
4.时间复杂度
最坏情况下时间复杂度为O(n*log2n)的算法。5.空间复杂度
三.插入类
1.直接插入排序『基于顺序查找』
1.基本思想
2.算法步骤
void Insertion_Sort(int *a,int n)
{
int temp;
for(int i=1; i3.优化操作
1.折半插入排序『基于折半查找』
在前面已经排好序的有序表中查找合适的待插入位置时,使用二分查找的方式来查找。//
a[0]:3 a[1]:2 a[2]:1 a[3]:8 a[4]:7 a[5]:6 a[6]:5 a[7]:4
____________________________
left:0 mid:0 right:-1
a[0]:2 a[1]:3 a[2]:1 a[3]:8 a[4]:7 a[5]:6 a[6]:5 a[7]:4
____________________________
left:0 mid:0 right:-1
a[0]:1 a[1]:2 a[2]:3 a[3]:8 a[4]:7 a[5]:6 a[6]:5 a[7]:4
____________________________
left:3 mid:2 right:2
a[0]:1 a[1]:2 a[2]:3 a[3]:8 a[4]:7 a[5]:6 a[6]:5 a[7]:4
____________________________
left:3 mid:3 right:2
a[0]:1 a[1]:2 a[2]:3 a[3]:7 a[4]:8 a[5]:6 a[6]:5 a[7]:4
____________________________
left:3 mid:3 right:2
a[0]:1 a[1]:2 a[2]:3 a[3]:6 a[4]:7 a[5]:8 a[6]:5 a[7]:4
____________________________
left:3 mid:3 right:2
a[0]:1 a[1]:2 a[2]:3 a[3]:5 a[4]:6 a[5]:7 a[6]:8 a[7]:4
____________________________
left:3 mid:2 right:2
a[0]:1 a[1]:2 a[2]:3 a[3]:4 a[4]:5 a[5]:6 a[6]:7 a[7]:8void Insertion_Sort_Pro(int *a,int n)
{
int temp;
for(int i=1; i
类似于二叉排序树的查找失败结点,最后找到的位置是在最接近 target 的两个一大一小的数中间。
同时,right 所在位置为有序序列中第一个小于 a【i】的数;
left 所在位置为有序序列中第一个大于 a【i】的数,我们需要插在第一个小于 a【i】的数的右边。
所以此时要把 left 所标志的数及其右侧的数据全部右移一位。2.双向两路插入排序
付出的代价是 n 个记录的辅助空间。
若小于tempArr[0],则插入tempArr[0]之前的有序部分;
反之,将其插入tempArr[0]之后的有序部分中。
1.对于下标加 1 : num = (num + 1) % n ;//
a[0]:8 a[1]:7 a[2]:6 a[3]:5 a[4]:4 a[5]:3 a[6]:2 a[7]:1
a[0]:8 a[1]:0 a[2]:0 a[3]:0 a[4]:0 a[5]:0 a[6]:0 a[7]:7
a[0]:8 a[1]:0 a[2]:0 a[3]:0 a[4]:0 a[5]:0 a[6]:6 a[7]:7
a[0]:8 a[1]:0 a[2]:0 a[3]:0 a[4]:0 a[5]:5 a[6]:6 a[7]:7
a[0]:8 a[1]:0 a[2]:0 a[3]:0 a[4]:4 a[5]:5 a[6]:6 a[7]:7
a[0]:8 a[1]:0 a[2]:0 a[3]:3 a[4]:4 a[5]:5 a[6]:6 a[7]:7
a[0]:8 a[1]:0 a[2]:2 a[3]:3 a[4]:4 a[5]:5 a[6]:6 a[7]:7
a[0]:8 a[1]:1 a[2]:2 a[3]:3 a[4]:4 a[5]:5 a[6]:6 a[7]:7
a[0]:1 a[1]:2 a[2]:3 a[3]:4 a[4]:5 a[5]:6 a[6]:7 a[7]:8void Insertion_Sort_Pro_X(int *a,int n)
{
int *tempArr = new int[n] ;
memset(tempArr,0,sizeof(int)*n);
tempArr[0] = a[0];
int left = 0; //临时数组中,第一个已排好顺序的元素的位置
int right = 0; //临时数组中,最后一个已排好顺序的元素的位置
for(int i=1; i3.设置哨兵位
4.稳定性
相等时不处理,所以直接插入排序是稳定的。5.时间复杂度
2.链表插入排序『基于链表的存储结构』
【避免移动,用空间换时间】
初始化双向循环带头结点的链表,有一个首元结点,肯定是有序的。
缺点是——表插入排序无法再实现随机查找了。#include 3.希尔排序『基于逐趟缩小增量 gap』
1.基本思想
【d 也可以用 gap 表示,它的数值从大到小逐渐减小,直到减为1为止】2.算法步骤
2.逐步减小 gap ,并进行划分与直接插入排序。
3.当 gap == 1 时,此时的序列中包含所有元素(即原数组大小),进行最后一次直接插入排序。
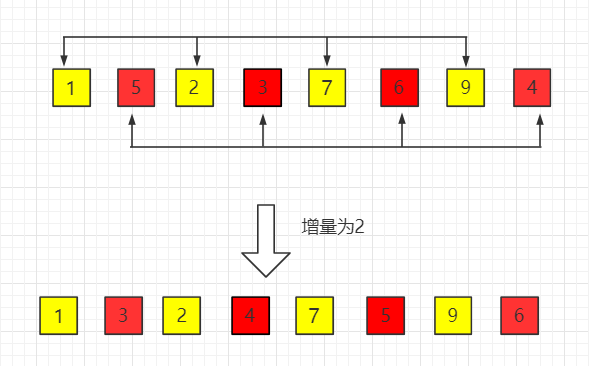
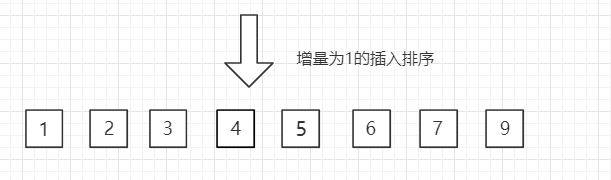
void Shell_Sort(int a[],int n)
{
int temp;
//规定初始间隔 gap 为(n/2),不用管能否整除
for(int gap=n/2; gap>0; gap/=2) //最外层循环:控制间隔大小,且每次更新都变为原来的一半,直到变为1
{
for(int i=0; i3.优化操作
1.折半查找
void Shell_Sort_Pro(int a[],int n)
{
//规定初始间隔 gap 为(n/2),不用管能否整除
for(int gap=n/2; gap>0; gap/=2) //最外层循环:控制间隔大小,且每次更新都变为原来的一半,直到变为1
{
for(int i=gap; i4.稳定性
5.时间复杂度
四.归并类
1.归并排序(Merge sort)
1.基本思想
2.算法步骤
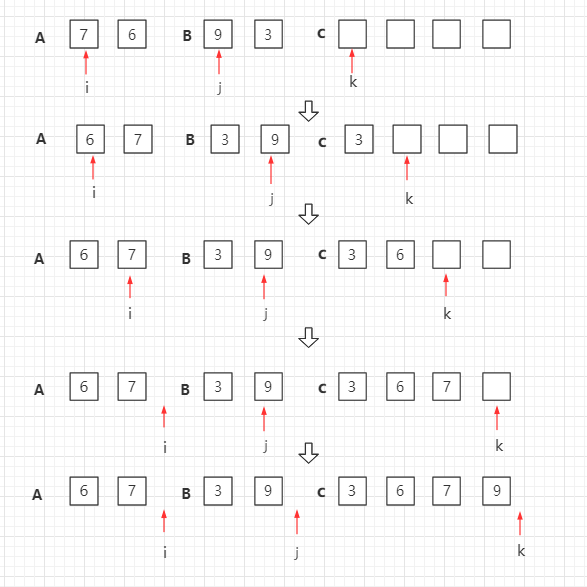



void Merge(int *a,int left,int mid,int right)//归并函数
{
int *temp = (int*)malloc(sizeof(int)*(right-left+1));
int i,j,k;
//左:left——mid
//右:mid+1——right
i=left; //i定位到左半部分数组的第一个数
j=mid+1; //j定位到右半部分数组的第一个数
k=0;
//不可以写成k=0;【因为当前区间的起点就是left捏】(这样会把之前的存入的数据全部覆盖)
while(i <= mid && j <= right)//直到一边没有数据时
{
if(a[i] <= a[j])
temp[k++] = a[i++]; //先存入较小的数
else
temp[k++] = a[j++]; //先存入较小的数
}
while(i <= mid)
temp[k++] = a[i++]; //将剩余的的数据存入(如果还有的话)
//(注意这里没办法保证他是排好序了的)所以要分割到只剩一个数
while(j <= right)
temp[k++] = a[j++]; //将剩余的的数据存入(如果还有的话)
//p定位到左半部分数组的第一个数(也就是上次被分割后的最左边那个数)
for(int q=0, p=left; q3.优化操作
1.递归小区间插入优化
因此,当子集合的元素个数较少时,采用在小规模集合上能高效工作的排序方法,而非继续划分。void Insert_Sort(int *a,int left,int right)
{
for(int i=left+1; i<=right; i++)
{
int temp = a[i];
int j;
for(j=i-1; j>=left; j--)
{
if(a[j] > temp)
a[j+1] = a[j];
else
break;
}
a[j+1] = temp;
}
}
void Merge(int *a,int left,int mid,int right)//归并函数
{
int *temp = (int*)malloc(sizeof(int)*(right-left+1));
int i,j,k;
//左:left——mid
//右:mid+1——right
i=left; //i定位到左半部分数组的第一个数
j=mid+1; //j定位到右半部分数组的第一个数
k=0;
//不可以写成k=0;【因为当前区间的起点就是left捏】(这样会把之前的存入的数据全部覆盖)
while(i <= mid && j <= right)//直到一边没有数据时
{
if(a[i] <= a[j])
temp[k++] = a[i++]; //先存入较小的数
else
temp[k++] = a[j++]; //先存入较小的数
}
while(i <= mid)
temp[k++] = a[i++]; //将剩余的的数据存入(如果还有的话)
//(注意这里没办法保证他是排好序了的)所以要分割到只剩一个数
while(j <= right)
temp[k++] = a[j++]; //将剩余的的数据存入(如果还有的话)
//p定位到左半部分数组的第一个数(也就是上次被分割后的最左边那个数)
for(int q=0, p=left; q2.自底向上的归并【非递归】
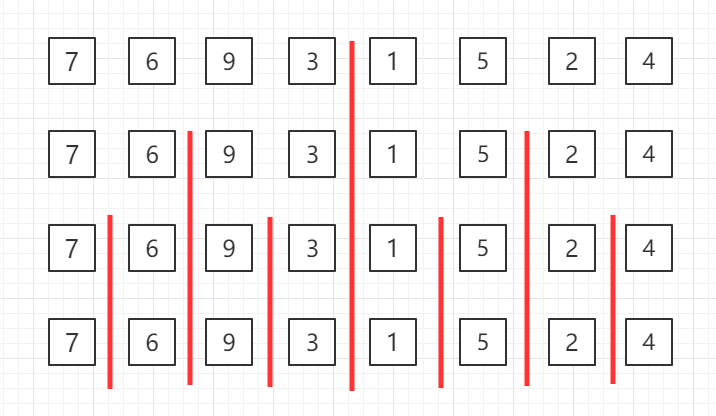
自底向上的归并没有问题的分解过程,直接从元素数只有一个的问题开始。
首先进行两两归并,然后四四归并,再之后八八归并,一直下去。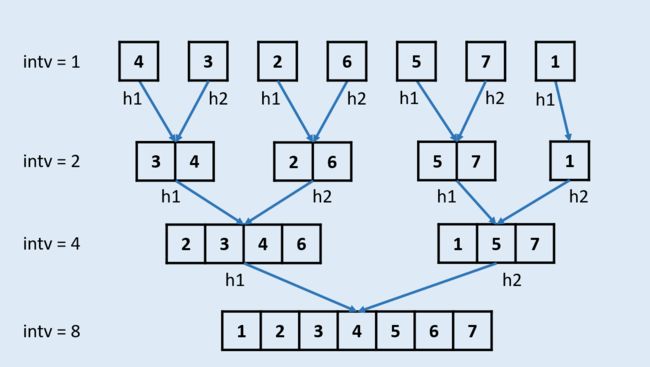 自底向上的归并算法也是使用分治思想解决问题。
自底向上的归并算法也是使用分治思想解决问题。
时间复杂度也是O(nlogn),由于使用辅助数组存储空间复杂度也是O(n)。
自底向上的归并没有分解过程,不依赖与递归实现,不需要使用系统递归栈。
所以虽然时间复杂度相同,但性能上自底向上的归并要优于自顶向下归并。
要使得排序函数具有普适性,就要单独把残留项保留下来。
然后在最后一步时,将前面排好的序列(一定含有2^n个元素)与残留项一起合并,得到结果。void Merge_BTU(long long *a,long long *b,long long left,long long mid,long long right)//归并函数
{
long long i,j,k;
//左:left——mid
//右:mid+1——right
i=left; //i定位到左半部分数组的第一个数
j=mid+1; //j定位到右半部分数组的第一个数
k=left;
//不可以写成k=0;【因为当前区间的起点就是left捏】(这样会把之前的存入的数据全部覆盖)
while(i <= mid && j <= right)//直到一边没有数据时
{
if(a[i] <= a[j])
b[k++] = a[i++]; //先存入较小的数
else
b[k++] = a[j++]; //先存入较小的数
}
while(i <= mid)
b[k++] = a[i++]; //将剩余的的数据存入(如果还有的话)
//(注意这里没办法保证他是排好序了的)所以要分割到只剩一个数
while(j <= right)
b[k++] = a[j++]; //将剩余的的数据存入(如果还有的话)
//p定位到左半部分数组的第一个数(也就是上次被分割后的最左边那个数)
for(long long p=left; p<=right; p++) //复制到原数组中去
a[p] = b[p];
}
//从按照划分的子序列长度进行每一轮的合并
void Merge_Pass(long long *a,long long *b,long long sum,long long size)
{
long long i;
//判断条件是以防止出现畸形序列而无法进行正常合并,因此预留出最后的一部分单独考虑
//每一次合并的对象总跨度为 2*size ,所以 i 也是一次跨越 2*size
for(i=0; i <= sum-2*size; i += 2*size)
Merge_BTU(a,b,i,i+size-1,i+2*size-1);
/** i :左侧序列的左端
// size: 前面非畸形序列(2^n)的长度
// i+size-1:左侧序列的右端
// i+size:右侧序列的左端
// i+2*size-1:右侧序列的右端
*/
if(i+sizevoid Merge_BTU(long long *a,long long left,long long mid,long long right)//归并函数
{
long long i,j,k;
long long *b = (long long*)malloc(sizeof(long long)*(right-left+1)); //辅助数组
//左:left——mid
//右:mid+1——right
i=left; //i定位到左半部分数组的第一个数
j=mid+1; //j定位到右半部分数组的第一个数
k=0;
//不可以写成k=0;【因为当前区间的起点就是left捏】(这样会把之前的存入的数据全部覆盖)
while(i <= mid && j <= right)//直到一边没有数据时
{
if(a[i] <= a[j])
b[k++] = a[i++]; //先存入较小的数
else
b[k++] = a[j++]; //先存入较小的数
}
while(i <= mid)
b[k++] = a[i++]; //将剩余的的数据存入(如果还有的话)
//(注意这里没办法保证他是排好序了的)所以要分割到只剩一个数
while(j <= right)
b[k++] = a[j++]; //将剩余的的数据存入(如果还有的话)
//p定位到左半部分数组的第一个数(也就是上次被分割后的最左边那个数)
for(long long p=left,q=0; q4.稳定性
5.时间复杂度
每一轮归并,其比较次数不超过 n 次,元素移动次数都是 n 次。
因此,归并排序的时间复杂度为 O(n*logn) 。6.空间复杂度
五.其他类
1.基数排序
1.基本思路
基数为 r ——可以简单理解为 “逢 r 进 1”。
【例如二进制是逢二进一的,二进制的基数为 r,同理十进制的基数为 10,r 进制的基数为 r】
设位数为figure:
每个分量的值取值范围为 0,1,…,n,基数为(n+1)【0,1,…,9,即基数为10】
依次从低位考查每个分量。2.算法步骤
第pass遍时,设data.key的从右往左数的第pass位数字为r,把 data 插入到Q【r】中去。
取完队列A后,此时全部的数据都被分配到了队列Q【0】、Q【1】……Q【figure-1】中。
按照从左到右的顺序依次一次性取完队列中的所有数据,取出的数据插入到队列A中。
对于关键字中有 figure 位数字的数据进行 figure 遍处理,即可得到按关键字有序的序列了捏。//
待排序关键字:321 986 123 432 543 018 765 678 987 789 098 890 109 901 210 012
——————————————————————————————————————————————————————————————————————————————————————
【第一遍:pass == 1】
Q[0]:890 210
Q[1]:321 901
Q[2]:432 012
Q[3]:123 543
Q[4]:
Q[5]:765
Q[6]:986
Q[7]:987
Q[8]:018 678 098
Q[9]:789 109
//
待排序关键字:890 210 321 901 432 012 123 543 765 986 987 018 678 098 789 109
——————————————————————————————————————————————————————————————————————————————————————
【第二遍:pass == 2】
Q[0]:901 109
Q[1]:210 012 018
Q[2]:321 123
Q[3]:432
Q[4]:543
Q[5]:
Q[6]:765
Q[7]:678
Q[8]:986 987 789
Q[9]:890 098
//
待排序关键字:901 109 210 012 018 321 123 432 543 765 678 986 987 789 890 098
——————————————————————————————————————————————————————————————————————————————————————
【第三遍:pass == 3】
Q[0]:012 018 098
Q[1]:109 123
Q[2]:210
Q[3]:321
Q[4]:432
Q[5]:543
Q[6]:678
Q[7]:765 789
Q[8]:890
Q[9]:901 986 987
最终输出有序序列:012 018 098 109 123 210 321 432 543 678 765 789 890 901 986 9873.优化操作
1.链式队列
因此一般采用链队列。
让头指针指向链表的头节点, 尾指针指向最后一个节点。2.前缀和(无需队列)
#include 4.稳定性
5.时间复杂度
考虑到 d 是一个常数,因此时间复杂性为O(n)。6.空间复杂度
②MSD– Most Significant Digit first 从高位向低位(个位)排。
!!!b[n]中的元素为temp中的位置!!!跳跃的用++补上:
//基数排序
//LSD 先以低位排,再以高位排
//MSD 先以高位排,再以低位排
void LSDSort(int *a, int n)
{
assert(a); //判断a是否为空,也可以a为空||n<2返回
int digit = 0; //最大位数初始化
for (int i = 0; i < n; ++i)
{
//求最大位数
while (a[i] > (pow(10,digit))) //pow函数要包含头文件math.h,pow(10,digit)=10^digit
{
digit++;
}
}
int flag = 1; //位数
for (int j = 1; j <= digit; ++j)
{
//建立数组统计每个位出现数据次数(Digit[n]为桶排序b[n])
int Digit[10] = { 0 };
for (int i = 0; i < n; ++i)
{
Digit[(a[i] / flag)%10]++; //flag=1时为按个位桶排序
}
//建立数组统计起始下标(BeginIndex[n]为个数累加c[n],用于记录重复元素位置
//flag=1时,下标代表个位数值,数值代表位置,跳跃代表重复)
int BeginIndex[10] = { 0 };
for (int i = 1; i < 10; ++i)
{
//累加个数
BeginIndex[i] = BeginIndex[i - 1] + Digit[i - 1];
}
//建立辅助空间进行排序
//下面两条可以用calloc函数实现
int *tmp = new int[n];
memset(tmp, 0, sizeof(int)*n);//初始化
//联合各数组求排序后的位置存在temp中
for (int i = 0; i < n; ++i)
{
int index = (a[i] / flag)%10; //桶排序和位置数组中的下标
//计算temp相应位置对应a[i]中的元素,++为BeginIndex数组数值加1
//跳跃间隔用++来补,先用再++
tmp[BeginIndex[index]++] = a[i];
}
//将数据重新写回原空间
for (int i = 0; i < n; ++i)
{
a[i] = tmp[i];
}
flag = flag * 10;
delete[] tmp;
}
}2.计数排序
1.基本思路
元素从未排序状态变为已排序状态的过程,是由额外空间的辅助和元素本身的值决定的。![]() 的时候其效率反而不如基于比较的排序,因为基于比较的排序的时间复杂度在理论上的下限是
的时候其效率反而不如基于比较的排序,因为基于比较的排序的时间复杂度在理论上的下限是  。
。2.算法步骤:
2.统计数组中每个值为 i 的元素出现的次数,存入数组C的第 i 项。
3.对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)【前缀和】
4.反向填充目标数组:将每个元素 i 放在新数组的第C(i)项,每放一个元素就将C(i)减去1。#define NUM_RANGE 1000 //预定义数据范围上限,即K的值
void Count_Sort(int *a,int n) //所需空间为 2*n+k
{
int *bucket = (int*)malloc(sizeof(int)*NUM_RANGE);
int *temp = (int*)malloc(sizeof(int)*n);
int i;
int j;
//初始化统计数组元素为值为零
for(i=0; i3.优化操作
1.最值压缩区间
//利用最大数和最小数来压缩桶的数目(平移区间)
void Count_Sort_Pro(int *a,int n)
{
int min_num = a[0];
int max_num = a[0];
for(int i=1; i#include 4.稳定性
5.时间复杂度
6.空间复杂度
3.桶排序
1.基本思路
在分完桶后,对每个桶进行排序(一般用快排),然后合并成最后的结果。2.算法步骤
2.再分别对各个桶进行排序。
3.最后依次按顺序取出桶中的数据。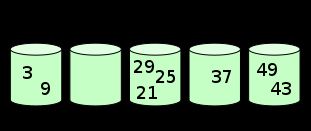

#include 另一种解法
#include 3.稳定性
4.时间复杂度
5.空间复杂度
排序有两个数组的空间开销,一个存放待排序数组,一个就是所谓的桶。
比如待排序值是从0到m-1,那就需要m个桶,这个桶数组就要至少m个空间。七.相关习题



1.中位数
即一半的母牛产奶量等于或高于该母牛产奶量,一半的母牛产奶量等于或低于该母牛的产奶量。
奶牛数量为N。
【1≤N<10000,产奶量∈[0,1000000] 】2.前k大的数
3.时间段
空闲时间被分为了N个时间段,其中N可能会非常大,可以假设N为1亿,也就是100000000。
(这要求程序不能声明长度为N的数组或定义N个变量),若未考虑此情况则不能得分。
接着程序输入M行,每行两个数字,表示第i名同学空闲时间的开始时间段与终止时间段。
其中: 1 ≤ ≤ 100000000 , 1 ≤ M ≤ 1000 。
如若有多对,请以递增形式在一行中输出。
不同对之间用英文逗号“,”分隔,对内元素用空格隔开。
如若完全一致,则为相同时间段。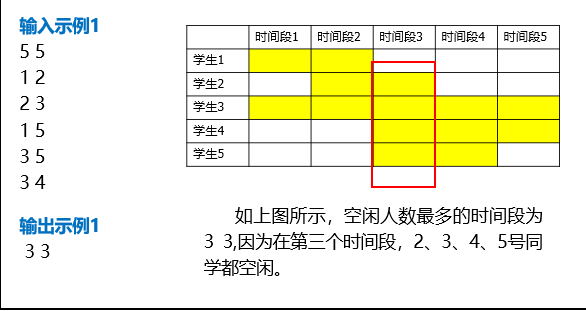

4.银行贷款


//
3
20000 2500 10
20000 3000 10
20000 3000 20
4.28%
8.14%
13.89%
double check(double x,double y,int t)
{
double ret = x;
double rate = 0.500f;
while(true)
{
for(int i=0; i5.成绩排名
1.首先计算加权总分,如果加权总分都不相同,按加权总分降序排序;
2.加权总分相同时,按优先级顺序基于原始成绩排序;
3.分数完全一致时,按学号升序排序,且排名是一样的。//
5
1 2 3 4 5
1.0 1.1 1.0 1.2 0.9
1001 90 80 70 60 50
1002 80 90 60 80 40
1003 80 90 60 80 40
1004 90 90 100 90 60
1005 100 100 100 100 80
1 1005
2 1004
3 1002
3 1003
5 1001
//_________________________________________________________________________________________
6
1 2 3 4 5
1.0 1.1 1.0 1.2 0.9
1001 90 80 70 60 50
1002 80 90 60 80 40
1003 80 90 60 80 40
1004 90 90 100 90 60
1005 100 100 100 100 80
1006 80 90 60 80 40
1 1005
2 1004
3 1002
3 1003
3 1006
6 1001typedef struct student
{
char ID[10];
int Score[5];
} Stu;
int Prior[5];
double Weight[5];
double Compute(Stu student)
{
double ret = 0;
for(int i=0; i<5; i++)
ret += Weight[i]*student.Score[i];
return ret;
}
int Cmp(Stu s1,Stu s2) //左边 VS 右边
{
if(Compute(s1) - Compute(s2) > delta)
return 1;
else if(Compute(s1) - Compute(s2) < -delta)
return 0;
else
{
for(int i=0; i<5; i++)
{
int j = 0; //用来找优先级为i+1的学科是哪一个
while(Prior[j] != i+1)
j++;
if(s1.Score[j] > s2.Score[j])
return 1;
else if(s1.Score[j] < s2.Score[j])
return 0;
else
continue;
}
//到这里了就说明两个学生成绩完全一致
return -1;
}
}
void Sort(Stu *student,int n)
{
for(int i=0; i#include 6.逆序对
//
6
5 4 2 6 3 1
111.暴力解法
int Count(int *a,int n)
{
int cnt = 0;
for(int i=0; i2.归并排序
如果 a[j] 小于 a[i] ,因为左半数组是有序(递增)的,所以左半部分剩下的所有元素均大于 a[j]。
也就是说左半部分剩下的所有数均可以和 a[j] 构成逆序对。
左半部分剩下元素为 mid-i+1 个,所以对 a[j] 而言,有 mid-i+1 个逆序对。
再把相邻两个数组不断合并也就是“治”。
在对任意两个有序序列合并时,在判断大小时只要多加一行代码。
判断此时指标 j 指向的右边数组里的元素是不是小于指标 i 指向左边数组里的元素。
如果是,那么 i 到左边数组的最后一个都会比 j 指向的元素大。
i~最后一个元素之间的所有元素都和j是逆序对,那么就把这之间的个数加起来就是最终答案。
归并排序是稳定的,相等的元素位置不会改变。//
5 4 2 6 3 1
5 | 4 | 2 | 6 | 3 | 1
【 5 与 4 ; 3 与 1】
4 5 | 2 6 | 1 3
【2 与 4 ; 2 与 5】
2 4 5 6 | 1 3
【1 与 2、4、5、6 ; 3 与 4、5、6】
1 2 3 4 5 6
2+2+4+3 = 11
int cnt;
int *temp;
void Func(int *a,int left,int mid,int right)
{
int i = left;
int j = mid+1;
int k = left;
while(i <= mid && j <= right)
{
if(a[i] <= a[j])
temp[k++] = a[i++];
else
{
temp[k++] = a[j++];
cnt += mid-i+1;
//核心,逆序对在这里
}
}
while(i <= mid)
temp[k++] = a[i++];
while(j <= right)
temp[k++] = a[j++];
for(int i=left;i<=right;i++)
a[i] = temp[i];
}
void Merge(int *a,int left,int right)
{
if(left >= right)
return;
int mid = (left+right)/2;
Merge(a,left,mid);
Merge(a,mid+1,right);
Func(a,left,mid,right);
}
void Count_Pro(int *a,int n)
{
cnt = 0;
Merge(a,0,n-1);
}
int main()
{
int n;
cin>>n;
int *a = (int*)malloc(sizeof(int)*n);
temp = (int*)malloc(sizeof(int)*n);
for(int i=0; i3.树状数组
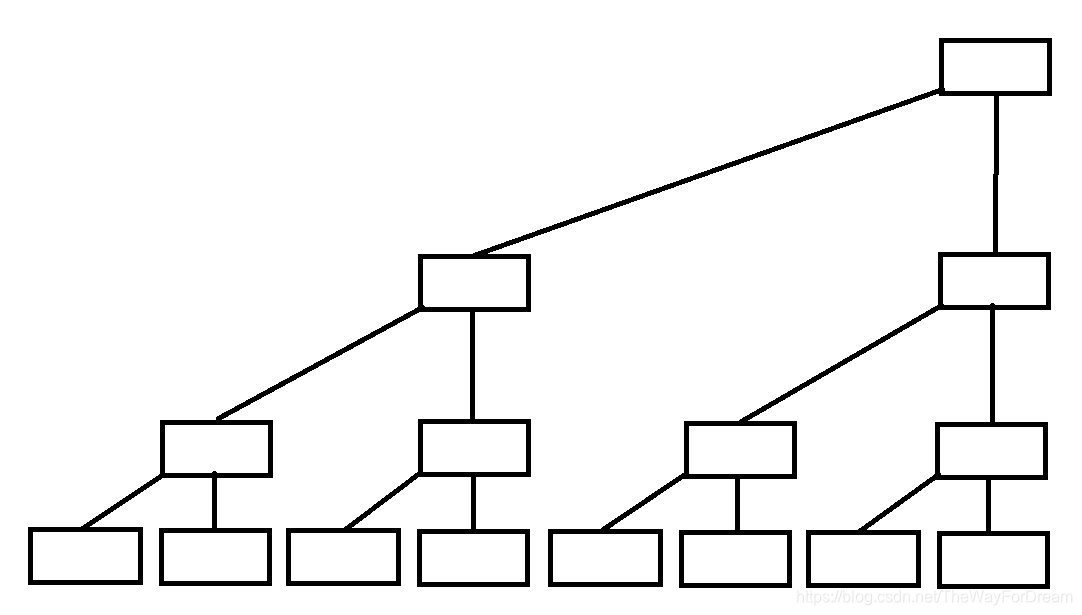
.这是树状数组的结构
不难发现,树状数组相比于二叉树删除了一些节点,但是为什么要删除呢?前置知识—lowbit(x)运算
2.最外面的结点的下标是2的n次方。
3.下标为奇数的结点一定是叶子结点。
4.数组的首个元素的下标要从1开始。
5.每一个非叶子节点都代表一个区间的和。
例如我们需要求1~11的和,我们就只需要求出a[11] ,a[10] ,a[8]的和。
同样的,假如求1~1000的和,那么只需要求a[1000] ,a[992] ,a[960], a[896], a[768],a[512]的和。