分词.join 保存txt
要求
分词.join 保存txt
第1种方法
分词.join 保存txt
input多行文本 /storage/emulated/0/数据中心/txt没有就新建
为什么会想到这么做
1. 是因为有分词文件要处理
2. 对各种词语和线索进行分类
3. 解释一下生活中不常见的现象,但是深刻的符合社会现象傅里叶
4. 傅里叶、语义函数、与贝叶斯的问题
以下是每行代码注释版本:
import os # 首先,我们导入操作系统模块,这样就能够与文件和目录进行互动了。
input_path = "/storage/emulated/0/数据中心/txt" # 我们要处理的输入文件的路径,希望你已经准备好了。
output_path = "/storage/emulated/0/数据中心/output.txt" # 将结果保存到这个输出文件中,让它成为你的杰作之一。
delimiter = " " # 这是分隔符,用于连接分词后的单词。当然,你可以选择任何你喜欢的字符。
if not os.path.exists(output_path):
open(output_path, 'w').close() # 如果所选的输出文件不存在,那就新建一个吧!一张空白的文本等待我们的创作。
with open(input_path, 'r') as f: # 打开输入文件,用'with'来确保文件在使用完毕后被正确关闭,r表示读模式。
lines = f.readlines() # 逐行读取文件内容,将每行存储为一个列表元素,每次都会给我们带来新的想法。
with open(output_path, 'a') as f: # 接着,打开(或创建)输出文件,以追加模式a打开,用f表示文件句柄。
for line in lines: # 好了,现在我们开始一行一行地创作了。在这个循环中,每次处理一个输入文件的输出。
words = line.strip().split() # 首先,我们去掉每行的首尾空白,然后以空格为分隔符将每行拆分成一个个的单词。
joined_line = delimiter.join(words) # 接下来,我们使用我们最喜欢的连接符将这些单词连接起来,构建我们的艺术品。
f.write(joined_line + "\n") # 最后,我们把这行代码加入我们构建的作品中,每行之间留下一点空隙,让它看起来更美观。
希望以上代码注释能够启发你,同时也让你感到愉悦!
第2种方法
input写入多行文本 2333.3结束
随后:分词 去重 删除空行
.join 每行保存一个词语
将文本保存txt
/storage/emulated/0/数据中心/txt/
文件夹没有就新建 print控制台和保存txt
文件命名规则:
1. input手动输入(如果输入的是控制或者回车的话,直接进入第2条)
2. 编号. 第1个分词词语 时间戳
好的,我已经根据你的要求进行修改,代码如下:
import os
import jieba
import time
# 定义输入文件路径和输出文件路径
folder_path = "/storage/emulated/0/数据中心/txt" # 文件夹路径
input_file = os.path.join(folder_path, "input.txt") # 输入文件路径
output_file = os.path.join(folder_path, "output.txt") # 输出文件路径
# 创建文件夹(如果不存在)
if not os.path.exists(folder_path):
os.makedirs(folder_path)
print("文件夹创建成功!")
# 写入多行文本到输入文件
print("请输入多行文本,以'2333.3'结束:")
lines = []
while True:
line = input()
if line == '2333.3':
break
lines.append(line)
input_text = '\n'.join(lines)
with open(input_file, mode="w", encoding="utf-8") as f:
f.write(input_text)
print("文本已保存到输入文件!")
# 读取输入文件内容并进行分词、去重和删除空行
with open(input_file, mode="r", encoding="utf-8") as f:
content = f.readlines()
words = []
for line in content:
line = line.strip()
if line:
seg_list = jieba.cut(line)
words.extend(seg_list)
unique_words = list(set(words))
# 将分词结果逐行保存到输出文件
output_text = '\n'.join(unique_words)
output_filename = f"{len(unique_words)}. {unique_words[0]}_{int(time.time())}.txt"
output_path = os.path.join(folder_path, output_filename)
with open(output_path, mode="w", encoding="utf-8") as f:
f.write(output_text)
print("分词结果已保存到输出文件!")
# 成功是脚下那片秘密花园,感谢你和我一起创造美妙的代码!
这段代码会根据你的输入创建一个存放文本的文件夹(如果不存在)。然后,它会让你输入多行文本,以"2333.3"结束。接着,它会将输入的文本写入到输入文件中。然后,它会读取输入文件,进行分词、去重和删除空行的操作。最后,它会将分词结果逐行保存到输出文件中,并按照指定的命名规则进行命名。
请确保你已将/storage/emulated/0/数据中心/txt/替换为你真正想要存放文件的路径。
第3种调试方法:
文本分词,去重词语和竖排,并且打印原文和分词后的结果
input写入多行文本 2333.3结束
随后:分词 去重 删除空行
.join 每行保存一个词语
将文本保存txt
/storage/emulated/0/数据中心/txt/
文件夹没有就新建 print控制台和保存txt
保存的文件命名规则:
input手动输入(文件名).txt
如果输入的是空值或者回车,
则:编号. 第1个分词词语 时间戳
结巴分词啊 还有不要以展现列表的方式啊
.join 去除列表各种符号
打印原文
打印分词
保存为一个文件
请确认您的需求是对多行文本进行分词、去重,并将结果打印原文和分词后的结果保存为一个文件。如果我理解错误,请及时指正。
以下是满足您需求的代码示例:
import jieba
# 输入文本
lines = []
print("请输入多行文本,以\"2333.3\"结束:")
while True:
line = input()
if line == "2333.3":
break
lines.append(line)
# 对每行文本进行分词和去重
words = set()
for line in lines:
seg_list = jieba.cut(line)
for word in seg_list:
words.add(word)
# 原文和分词结果打印
print("原文:")
for line in lines:
print(line)
print("\n分词结果:")
for word in words:
print(word)
# 保存为txt文件
file_name = input("请输入文件名(不需要加后缀):")
if file_name.strip() == "":
file_name = "编号. 第1个分词词语 时间戳"
file_path = "/storage/emulated/0/数据中心/txt/" + file_name + ".txt"
with open(file_path, "w", encoding="utf-8") as f:
# 写入原文
f.write("原文:\n")
for line in lines:
f.write(line + "\n")
# 写入分词结果
f.write("\n分词结果:\n")
for word in words:
f.write(word + "\n")
print("文件保存成功!路径:%s" % file_path)
请注意,代码中使用了jieba库进行中文分词,请确保已安装该库(可通过pip install jieba进行安装)。
此外,保存文件的路径为/storage/emulated/0/数据中心/txt/,如果该路径不存在,请确保在手机上创建了相应的文件夹。
结果
/data/user/0/org.qpython.qpy/files/bin/qpy thon3.sh "/storage/emulated/0/qpython/分词 .join保存txt1.2.2.1.py" && exit
oin保存txt1.2.2.1.py" && exit < 请输入多行文本,以"2333.3"结束:
import jieba
# 输入文本
lines = []
print("请输入多行文本,以\"2333.3\"结束:" )
while True:
line = input()
if line == "2333.3":
break
lines.append(line)
# 对每行文本进行分词和去重
words = set()
for line in lines:
seg_list = jieba.cut(line)
for word in seg_list:
words.add(word)
# 原文和分词结果打印
print("原文:")
for line in lines:
print(line)
print("\n分词结果:")
for word in words:
print(word)
# 保存为txt文件
file_name = input("请输入文件名(不需要加后缀):")
if file_name.strip() == "":
file_name = "编号. 第1个分词词语 时间戳"
file_path = "/storage/emulated/0/数据中心/ txt/" + file_name + ".txt"
with open(file_path, "w", encoding="utf-8" ) as f:
# 写入原文
f.write("原文:\n")
for line in lines:
f.write(line + "\n")
# 写入分词结果
f.write("\n分词结果:\n")
for word in words:
f.write(word + "\n")
print("文件保存成功!路径:%s" % file_path )
2333.3
Building prefix dict from the default dict ionary ...
Loading model from cache /storage/emulated /0/qpython/cache/jieba.cache
Loading model cost 1.282 seconds.
Prefix dict has been built successfully.
原文:
import jieba
# 输入文本
lines = []
print("请输入多行文本,以\"2333.3\"结束:" )
while True:
line = input()
if line == "2333.3":
break
lines.append(line)
# 对每行文本进行分词和去重
words = set()
for line in lines:
seg_list = jieba.cut(line)
for word in seg_list:
words.add(word)
# 原文和分词结果打印
print("原文:")
for line in lines:
print(line)
print("\n分词结果:")
for word in words:
print(word)
# 保存为txt文件
file_name = input("请输入文件名(不需要加后缀):")
if file_name.strip() == "":
file_name = "编号. 第1个分词词语 时间戳"
file_path = "/storage/emulated/0/数据中心/ txt/" + file_name + ".txt"
with open(file_path, "w", encoding="utf-8" ) as f:
# 写入原文
f.write("原文:\n")
for line in lines:
f.write(line + "\n")
# 写入分词结果
f.write("\n分词结果:\n")
for word in words:
f.write(word + "\n")
print("文件保存成功!路径:%s" % file_path )
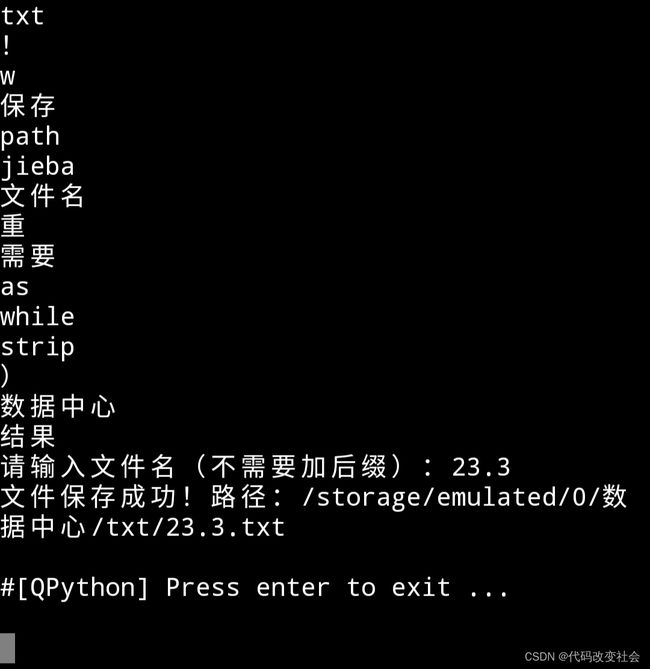
分词结果:
file
打印
_
结束
(
,
storage
0
8
import
open
print
分词
for
每行
lines
词语
append
words
[
name
第
成功
不
\
,
%
)
input
-
1
with
=
多行
write
list
加
进行
原文
]
"
后缀
if
set
in
encoding
.
seg
为
:
个
True
路径
utf
请
2333.3
:
f
文本
以
word
n
break
emulated
戳
文件
#
对
+
/
写入
add
编号
和
时间
输入
(
cut
line
去
s
txt
!
w
保存
path
jieba
文件名
重
需要
as
while
strip
)
数据中心
结果
请输入文件名(不需要加后缀):23.3
文件保存成功!路径:/storage/emulated/0/数 据中心/txt/23.3.txt
#[QPython] Press enter to exit ...
图片
有时候之所以找不到问题的答案,是因为表述不清楚问题模糊就会产生各种分支,