大数据毕设 - 深度学习车牌识别系统(python 机器视觉 opencv)
文章目录
- 1 前言
- 1 课题背景
- 2 效果演示
-
- 2.1 图片检测识别
- 2.2视频检测识别
- 3 车牌检测与识别
- 4 HyperLPR库
-
- 4.1 简介
- 4.2 特点
- 4.3 HyperLPR的检测流程
- 4.4 安装
- 4.5 Python 依赖
- 5 最后
1 前言
Hi,大家好,这里是丹成学长的毕设系列文章!
对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
基于python 机器视觉 的车牌识别系统
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
1 课题背景
车牌识别其实是个经典的机器视觉任务了,通过图像处理技术检测、定位、识别车牌上的字符,实现计算机对车牌的智能管理功能。如今在小区停车场、高速公路出入口、监控场所、自动收费站等地都有车牌识别系统的存在,车牌识别的研究也已逐步成熟。尽管该技术随处可见了,但其实在精度和识别速度上还需要进一步提升,自己动手实现一个车牌识别系统有利于学习和理解图像处理的先进技术。
本文详细介绍基于深度学习的中文车牌识别与管理系统,在介绍算法原理的同时,给出Python的实现代码以及PyQt的简单UI界面。在界面中可以选择需要识别的车牌视频、图片文件等。
2 效果演示
首先还是用动图先展示一下效果,系统主要实现的功能是对图片、视频中的车牌进行检测和识别,演示效果如下。
2.1 图片检测识别
2.2视频检测识别
3 车牌检测与识别
目前,智能交通系统中集成运用计算机视觉、物联网、人工智能等多种技术成为未来发展方向。其中,车牌识别(License Plate Recognition, LPR)技术作为一项重要技术,从获取的图像中提取目标车辆的车牌信息,成为完善智能交通管理运行的基础。
由于本文介绍的是中文车牌,所以可以简单了解一下国内汽车拍照的特点:字符数为七个,包括汉字、字母和数字。车牌颜色组合中,其中最常见的组合为普通小型汽车蓝底白字和新能源汽车的渐变绿底黑字。
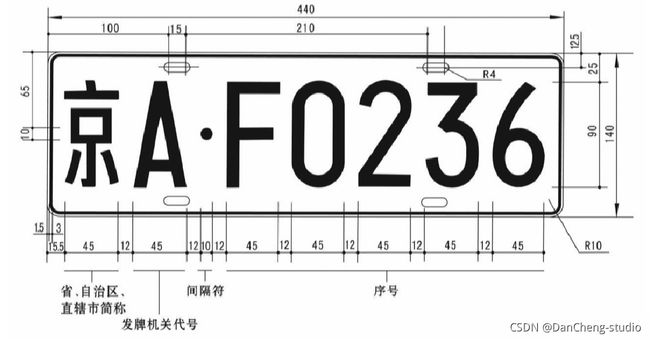
总结来说,车牌是一个有特点的图像区域,几种特征可以综合起来确定车牌定位,所以之前就有利用车牌与周围环境的差异的算法。目前常见的车牌定位算法有以下 4 种:基于颜色、纹理、边缘信息的车牌定位算法和基于人工神经网络的车牌定位算法。
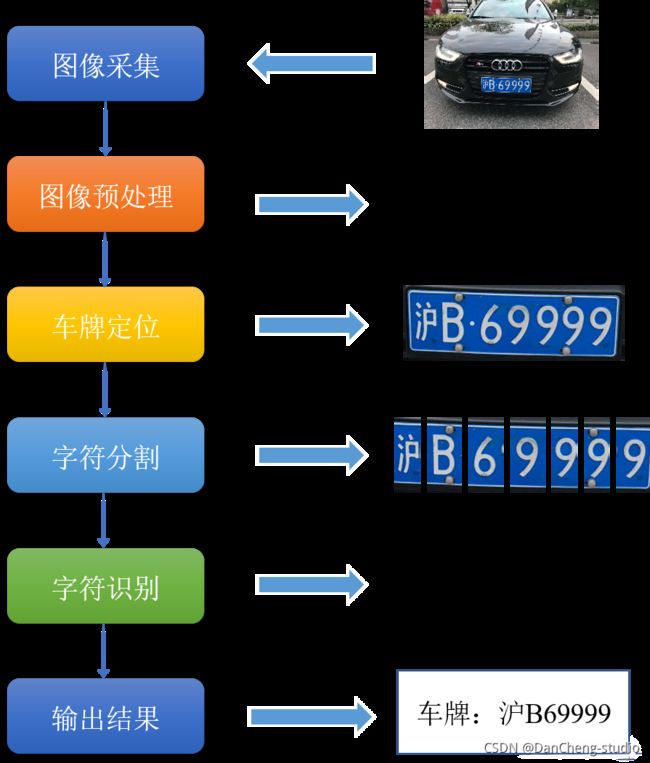
如下图所示,常规的步骤包括图像采集、预处理、车牌定位、字符分割、字符识别、输出结果。深度学习技术成熟之后,端到端的网络模型使得这一过程变得简单起来。从思想上来说,基于深度学习的车牌识别实现思路主要包括两个部分:(1)车牌检测定位;(2)车牌字符识别。
其中,车牌的检测定位本质是一个特定的目标检测任务,即通过算法框选出属于车牌的位置坐标,以便将其与背景区分开来。可以认为检测出的车牌位置才是我们的感兴趣区域。好用的方法如Cascade LBP,它是一种机器学习的方法,可以利用OpenCV训练级联分类器,依赖CPU进行计算,级联分类器的方法对于常用场景效果比较好,检测速度较快,曾经一度比较流行,但准确率一般。基于深度学习的检测算法有Mobilene-SSD、YOLO-v5等,利用大批量的标注数据进行训练.
当ROI被检测出来,如何对这一区域中的字符进行识别,这就涉及到采取的处理方式。第一种处理方式,首先利用一系列字符分割的算法将车牌中的字符逐个分开,然后基于深度学习进行字符分类,得到识别结果;第二种,区别于第一种先分割再分类的两步走方式,利用端到端的CTC( Connectionist Temporal Classification)网络直接进行识别。
这里我们使用网上开源的HyperLPR中文车牌识别框架,首先导入OpenCV和hyperlpr,读取一张车牌图片调用架构中的车牌识别方法获得结果,以下代码来自官方的示例:
#导入包
from hyperlpr import *
#导入OpenCV库
import cv2
#读入图片
image = cv2.imread("demo.jpg")
#识别结果
print(HyperLPR_plate_recognition(image))
以上代码运行结果如下,可以看出该方法识别了车牌的车牌字符、置信度值、车牌位置坐标、图片尺寸等结果。

这样的结果还不够直观,我们写一个函数将车牌的识别结果标注在图片上,首先导入相关依赖包,其代码如下:
# 导入包
from hyperlpr import *
# 导入OpenCV库
import cv2 as cv
from PIL import Image, ImageDraw, ImageFont
import numpy as np
新建一个函数drawRectBox,将图像数据、识别结果、字体等参数传入,函数内部利用OpenCV和PIL库添加标注框和识别结果的字符,其代码如下:
def drawRectBox(image, rect, addText, fontC):
cv.rectangle(image, (int(round(rect[0])), int(round(rect[1]))),
(int(round(rect[2]) + 8), int(round(rect[3]) + 8)),
(0, 0, 255), 2)
cv.rectangle(image, (int(rect[0] - 1), int(rect[1]) - 16), (int(rect[0] + 75), int(rect[1])), (0, 0, 255), -1, cv.LINE_AA)
img = Image.fromarray(image)
draw = ImageDraw.Draw(img)
draw.text((int(rect[0] + 1), int(rect[1] - 16)), addText, (255, 255, 255), font=fontC)
imagex = np.array(img)
return imagex
我们首先读取图片文件,利用前面的HyperLPR_plate_recognition方法识别出车牌结果,调用以上函数获得带标注框的图片,利用OpenCV的imshow方法显示结果图片,其代码如下:
image = cv.imread('test3.jpeg') # 读取选择的图片
res_all = HyperLPR_plate_recognition(image)
fontC = ImageFont.truetype("./platech.ttf", 14, 0)
res, confi, axes = res_all[0]
image = drawRectBox(image, axes, res, fontC)
cv.imshow('Stream', image)
c = cv.waitKey(0) & 0xff
此时运行以上代码可以得到如下结果:

同理,识别视频中的车牌也可以做类似的操作,不过我们需要先对视频文件进行逐帧读取,然后采用以上的方式在图片中标识出车牌并显示。
这部分代码如下:
capture = cv.VideoCapture("./车牌检测.mp4") # 读取视频文件
fontC = ImageFont.truetype("./platech.ttf", 14, 0) # 字体,用于标注图片
i = 1
while (True):
ref, frame = capture.read()
if ref:
i = i + 1
if i % 5 == 0:
i = 0
res_all = HyperLPR_plate_recognition(frame) # 识别车牌
if len(res_all) > 0:
res, confi, axes = res_all[0] # 获取结果
frame = drawRectBox(frame, axes, res, fontC)
cv.imshow("num", frame) # 显示画面
if cv.waitKey(1) & 0xFF == ord('q'):
break # 退出
else:
break
以上代码每5帧识别一次视频中的车牌,将车牌的结果标注在画面中进行实时显示,运行结果的截图如下所示:

车牌的识别部分代码演示完毕,对此我们完成了图片和视频的识别,然而这些还是简单的脚本呈现。为了方便更换图片、视频以及管理车牌,还需要设计文件选择功能以及系统的UI界面。这部分代码如下:
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(800, 600)
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.openimage = QtWidgets.QPushButton(self.centralwidget)
self.openimage.setGeometry(QtCore.QRect(20, 40, 91, 51))
self.openimage.setObjectName("openimage")
self.showlabel = QtWidgets.QLabel(self.centralwidget)
self.showlabel.setGeometry(QtCore.QRect(110, 10, 471, 441))
self.showlabel.setObjectName("showlabel")
self.LPRdetect = QtWidgets.QPushButton(self.centralwidget)
self.LPRdetect.setGeometry(QtCore.QRect(20, 150, 81, 51))
self.LPRdetect.setObjectName("LPRdetect")
self.LPR_Rec = QtWidgets.QPushButton(self.centralwidget)
self.LPR_Rec.setGeometry(QtCore.QRect(20, 292, 75, 31))
self.LPR_Rec.setObjectName("LPR_Rec")
self.lineEdit_result = QtWidgets.QLineEdit(self.centralwidget)
self.lineEdit_result.setGeometry(QtCore.QRect(20, 400, 101, 41))
self.lineEdit_result.setObjectName("lineEdit_result")
self.openvideo = QtWidgets.QPushButton(self.centralwidget)
self.openvideo.setGeometry(QtCore.QRect(20, 360, 75, 23))
self.openvideo.setObjectName("openvideo")
MainWindow.setCentralWidget(self.centralwidget)
self.menubar = QtWidgets.QMenuBar(MainWindow)
self.menubar.setGeometry(QtCore.QRect(0, 0, 800, 23))
self.menubar.setObjectName("menubar")
MainWindow.setMenuBar(self.menubar)
self.statusbar = QtWidgets.QStatusBar(MainWindow)
self.statusbar.setObjectName("statusbar")
MainWindow.setStatusBar(self.statusbar)
self.retranslateUi(MainWindow)
QtCore.QMetaObject.connectSlotsByName(MainWindow)
def retranslateUi(self, MainWindow):
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "MainWindow"))
self.openimage.setText(_translate("MainWindow", "打开图片"))
self.showlabel.setText(_translate("MainWindow", "TextLabel"))
self.LPRdetect.setText(_translate("MainWindow", "车牌检测"))
self.LPR_Rec.setText(_translate("MainWindow", "车牌识别"))
self.openvideo.setText(_translate("MainWindow", "PushButton"))
4 HyperLPR库
4.1 简介
HyperLPR是一个使用深度学习针对对中文车牌识别的实现,与较为流行的开源的EasyPR相比,它的检测速度和鲁棒性和多场景的适应性都要好于目前开源的EasyPR,HyperLPR可以识别多种中文车牌包括白牌,新能源车牌,使馆车牌,教练车牌,武警车牌等。
4.2 特点
- 基于端到端sequence模型,无需进行字符分割,识别速度更快。
- 速度快 720p ,单核 Intel 2.2G CPU (macbook Pro 2015)平均识别时间<=90ms
- 识别率高,仅仅针对车牌ROI在EasyPR数据集上,0-error达到 95.2%, 1-error识别率达到 97.4% (指在定位成功后的车牌识别率)
- 轻量总代码量不超1k行。
- 带有Android实现,其Android Demo可解决一些在一些普通业务场景(如执法记录仪)下的车牌识别任务。
- 支持多种车牌的识别,详情见如下
4.3 HyperLPR的检测流程
- 使用opencv的HAAR Cascade检测车牌大致位置
- Extend检测到的大致位置的矩形区域
- 使用类似于MSER的方式的多级二值化和RANSAC拟合车牌的上下边界
- 使用CNN Regression回归车牌左右边界
- 使用基于纹理场的算法进行车牌校正倾斜
- 使用CNN滑动窗切割字符
- 使用CNN识别字符
4.4 安装
pip install hyperlpr
4.5 Python 依赖
- Keras (>2.0.0)
- Theano(>0.9) or Tensorflow(>1.1.x)
- Numpy (>1.10)
- Scipy (0.19.1)
- OpenCV(>3.0)
- Scikit-image (0.13.0)
- PIL
- 使用CNN识别字符