【LittleXi】cache_lab超简单详解
【LittleXi】cache_lab
- 版权所有 抄袭必究
-
- part A
-
- lab 介绍
- 转化后
- 思路分析
- 代码实现
- 完整AC代码
- AC效果展示
- part B
-
- lab介绍
- 提要
- 开始实验!
- 32x32矩阵
- 64x64矩阵
- 61x67矩阵
版权所有 抄袭必究
part A
lab 介绍
本实验在学习csapp上的高速缓存cache的命中、不命中、LRU替换等机制后,在LINUX机器上使用C语言模拟缓存行为。
ps:这个题看似是模拟cache的行为的题目,实际上是一个模拟LRU机制的算法题,阅读完实验PDF介绍后,我们可以将其转化为算法题来做
转化后
input
./csim-ref -v -s 4 -E 1 -b 4 -t traces/yi.
I 10,1
L 10,1
M 20,1
L 22,1
S 18,1
L 110,1
L 210,1
M 12,1
output
hits:4 misses:5 evictions:3
思路分析
这里我们简单介绍一下hits、misses、evictions数量的由来
第一行的I 10,1是初始化,不用管他
首先我们理解一下“地址”的概念
地址:标记标…标记标记 组索引组…索引组索引 块偏移…块块偏移
写代码中我们只需要将组索引和标记拿到手,然后用组索引去定位高速缓存阵列中的组,用标记去检测是否匹配就行了
首先我们观察一下第二行的 L 10,1这个可以拆分为L 0000 0001 , 1四个部分,其中L是指的load data(加载数据),0000就是指的是target,0001就是指的组索引,逗号后面的部分是size不用去管它
然后就拿这个去匹配,为了方便匹配我们可以开一个二维数组记录高速缓存中的每行的的状态
如果冲突了就采用LRU替换策略,如果不懂LRU策略,可以去刷刷这个题
代码实现
前期准备工作做好了之后,我们就可以开始写代码了
首先定义一个记录每行信息的结构体block,在这里为了实现LRU缓存,我们增加一个时间戳time
struct block
{
bool valid;
long long target;
int time;
};
然后就可以定义我们需要的一系列变量了
int hit=0; //命中的次数
int miss=0;//错过的次数
int evictions=0;//冲突并替换的次数
int nowtime=1;//现在的时间
int m=(sizeof(void *)*8);//地址的大小
int verbose=false;//是否打印每次去匹配的log
char str[256];//获取输入的字符串
struct block ***cache;//我们定义的二维数组,数组内容是结构体
int s,E,b,S,B,t,C;//高速缓存的大小参数
FILE *fp;//即将读取的文件
接着读取初始化数据
void getoptions(int argc,char* argv[])
{
int op;
while((op=getopt(argc,argv,"hvs:E:b:t:"))!=-1)
{
switch(op)
{
case 'h':
printf("This is help~");
exit(0);
case 'v':
verbose=true;
break;
case 's':
s=atoi(optarg);
S=1<<s;
break;
case 'E':
E=atoi(optarg);
break;
case 'b':
b=atoi(optarg);
B=1<<b;
break;
case 't':
fp=fopen(optarg,"r");
if(fp==NULL)
{
printf("CAN'T OPREN THE FILE!");
exit(0);
}
break;
default:
break;
}
}
t=m-s-b;
C=B*E*S;
}
获取数据后对cache进行初始化
void init()
{
cache=malloc(sizeof(void*)*S);
for(int i=0;i<S;i++)
{
cache[i]=malloc(sizeof(void*)*E);
for(int j=0;j<E;j++)
{
struct block *temp=malloc(sizeof(struct block));
temp->target=0;
temp->time=0;
temp->valid=false;
cache[i][j]=temp;
}
}
}
初始化了cache,在结束时当然要释放内存
void freecache()
{
for(int i=0;i<S;i++)
{
for(int j=0;j<E;j++)
{
free(cache[i][j]);
}
free(cache[i]);
}
free(cache);
}
关键部分:利用LRU机制去尝试命中高速缓存
void m_visit_cache()
{
char op;
unsigned long long add;
int size;
sscanf(str," %c %llx,%d",&op,&add,&size);
long long se=(add<<t)>>(t+b);
long long tar=add>>(s+b);
int min_time_po=0;
int temp_time=cache[se][0]->time;
for(int i=0;i<E;i++)
{
if(cache[se][i]->target==tar&&cache[se][i]->valid)
{
if(verbose)
{
printf("%s ",str);
printf("hit\n");
}
hit++;
cache[se][i]->time=nowtime;
return;
}
if(cache[se][i]->time<=temp_time)
{
temp_time=cache[se][i]->time;
min_time_po=i;
}
}
if(verbose)
{
printf("%s ",str);
printf("miss ");
}
miss++;
if(cache[se][min_time_po]->time!=0)
{
if(verbose)
printf("evictions");
evictions++;
}
if(verbose&&op!='M')
printf("\n");
cache[se][min_time_po]->target=tar;
cache[se][min_time_po]->time=nowtime;
cache[se][min_time_po]->valid=true;
}
从文件中读取每一行操作
void m_input()
{
while(fgets(str,256,fp))
{
nowtime++;
if(str[strlen(str)-1]=='\n')
str[strlen(str)-1]='\0';
if(strlen(str)==0) return;
if(str[0]=='I')
continue;
else if(str[1]=='M')
{
m_visit_cache();
m_visit_cache();
}
else
m_visit_cache();
}
}
主函数:调用上面的函数,并将结果返回到需要的函数中
int main(int argc, char* argv[])
{
getoptions(argc,argv);
init();
m_input();
fclose(fp);
freecache();
printSummary(hit, miss, evictions);
return 0;
}
完整AC代码
#include"stdio.h"
#include"string.h"
#include"stdbool.h"
#include"stdlib.h"
#include"getopt.h"
#include"unistd.h"
#include "cachelab.h"
//定义需要的变量
struct block
{
bool valid;
long long target;
int time;
};
int hit=0;
int miss=0;
int evictions=0;
int nowtime=1;
int m=(sizeof(void *)*8);
int verbose=false;
char str[256];
struct block ***cache;
int s,E,b,S,B,t,C;
FILE *fp;
//读取初始换内容
void getoptions(int argc,char* argv[])
{
int op;
while((op=getopt(argc,argv,"hvs:E:b:t:"))!=-1)
{
switch(op)
{
case 'h':
printf("This is help~");
exit(0);
case 'v':
verbose=true;
break;
case 's':
s=atoi(optarg);
S=1<<s;
break;
case 'E':
E=atoi(optarg);
break;
case 'b':
b=atoi(optarg);
B=1<<b;
break;
case 't':
fp=fopen(optarg,"r");
if(fp==NULL)
{
printf("CAN'T OPREN THE FILE!");
exit(0);
}
break;
default:
break;
}
}
t=m-s-b;
C=B*E*S;
}
//初始化高速缓存阵列
void init()
{
cache=malloc(sizeof(void*)*S);
for(int i=0;i<S;i++)
{
cache[i]=malloc(sizeof(void*)*E);
for(int j=0;j<E;j++)
{
struct block *temp=malloc(sizeof(struct block));
temp->target=0;
temp->time=0;
temp->valid=false;
cache[i][j]=temp;
}
}
}
//释放高速缓存chenlie
void freecache()
{
for(int i=0;i<S;i++)
{
for(int j=0;j<E;j++)
{
free(cache[i][j]);
}
free(cache[i]);
}
free(cache);
}
//尝试去命中高速缓存
void m_visit_cache()
{
char op;
unsigned long long add;
int size;
sscanf(str," %c %llx,%d",&op,&add,&size);
long long se=(add<<t)>>(t+b);
long long tar=add>>(s+b);
int min_time_po=0;
int temp_time=cache[se][0]->time;
for(int i=0;i<E;i++)
{
if(cache[se][i]->target==tar&&cache[se][i]->valid)
{
if(verbose)
{
printf("%s ",str);
printf("hit\n");
}
hit++;
cache[se][i]->time=nowtime;
return;
}
if(cache[se][i]->time<=temp_time)
{
temp_time=cache[se][i]->time;
min_time_po=i;
}
}
if(verbose)
{
printf("%s ",str);
printf("miss ");
}
miss++;
if(cache[se][min_time_po]->time!=0)
{
if(verbose)
printf("evictions");
evictions++;
}
if(verbose&&op!='M')
printf("\n");
cache[se][min_time_po]->target=tar;
cache[se][min_time_po]->time=nowtime;
cache[se][min_time_po]->valid=true;
}
//输入字符串
void m_input()
{
while(fgets(str,256,fp))
{
nowtime++;
if(str[strlen(str)-1]=='\n')
str[strlen(str)-1]='\0';
if(strlen(str)==0) return;
if(str[0]=='I')
continue;
else if(str[1]=='M')
{
m_visit_cache();
m_visit_cache();
}
else
m_visit_cache();
}
}
int main(int argc, char* argv[])
{
getoptions(argc,argv);
init();
m_input();
fclose(fp);
freecache();
printSummary(hit, miss, evictions);
return 0;
}
AC效果展示
在linux机器中输入
make
./test-csim
得到一份满分的AC图
Your simulator Reference simulator
Points (s,E,b) Hits Misses Evicts Hits Misses Evicts
3 (1,1,1) 9 8 6 9 8 6 traces/yi2.trace
3 (4,2,4) 4 5 2 4 5 2 traces/yi.trace
3 (2,1,4) 2 3 1 2 3 1 traces/dave.trace
3 (2,1,3) 167 71 67 167 71 67 traces/trans.trace
3 (2,2,3) 201 37 29 201 37 29 traces/trans.trace
3 (2,4,3) 212 26 10 212 26 10 traces/trans.trace
3 (5,1,5) 231 7 0 231 7 0 traces/trans.trace
6 (5,1,5) 265189 21775 21743 265189 21775 21743 traces/long.trace
27
TEST_CSIM_RESULTS=27
至此part_A就结束啦
part B
经过一周的酝酿,终于把partB肝完啦
lab介绍
矩阵的转置学过吧?这个题就是将矩阵A转置为矩阵B,就结束了,听着是不是很简单?不过你先别急。我们先看看实验要求,要求32x32的矩阵的缓存miss<300,64x64的缓存miss<1300,61x67的缓存miss<2000。高速缓存学过吧,当我们拿地址去命中高速缓存时,若没有这个目标或者高速缓存满了,那么就会miss一次,所以我们在设计转置方案的时候尽可能要减少miss次数
提要
- 学过ics课程吧,我们设计的时候尽可能满足空间局部性
- 转置小tip,我们需要访问矩阵中的所有元素一次,并且操作
B[ j ] [ i ]=A[i] [j]
开始实验!
32x32矩阵
非常简单地,我们会想到逐层遍历访问A中的每个点,的确,这样对A具有很好的空间局部性,但是!我们这时的B时依次从上往下访问的,空间局部性非常不好!所以我们尝试以下优化
-
优化一
我们为了保持良好的空间局部性,(根据PDF中的分块提示),高速缓存中s=5,可知一共有32组,每行有2^5=32个字节,可以存储8个int,所以我们可以将32x32矩阵分为每块8x8的小块,满足空间局部性
-
优化二
我们在访问对角线元素的时候,比如
B[0] [0]=A[0] [0],高速缓存会同时寻找同一个set,必定会发生一次miss,所以我们为了避免这种情况,可以尝试将最后一层循环展开,利用变量先存储已经访问的目标
AC代码
if(M==32)
{
for(int i=0;i<32;i+=8)
{
for(int j=0;j<32;j+=8)
{
for(int k=0;k<8;k++)
{
int num1=A[i+k][j];
int num2=A[i+k][j+1];
int num3=A[i+k][j+2];
int num4=A[i+k][j+3];
int num5=A[i+k][j+4];
int num6=A[i+k][j+5];
int num7=A[i+k][j+6];
int num8=A[i+k][j+7];
B[j][i+k]=num1;
B[j+1][i+k]=num2;
B[j+2][i+k]=num3;
B[j+3][i+k]=num4;
B[j+4][i+k]=num5;
B[j+5][i+k]=num6;
B[j+6][i+k]=num7;
B[j+7][i+k]=num8;
}
}
}
}
64x64矩阵
虽然64x64放在了第二个题,但是这个题非常难。如果采取和32x32矩阵同样的方式,则高速缓存里面最多只能存储4x8的小矩阵方块,运行后发现和朴素的遍历方式没有什么区别,所以我们在这里要进一步优化。如果采用4x4的方式,则会在每一行中存储4个int,对高速缓存的空间利用很低,运行后miss次数也挺大的(虽然确实有巨大优化,但不能get满分),不妨换个思路,既然高速缓存不够,那么我们就自己造一个缓存!注意到A矩阵不能被修改,那么我们造缓存的原料就是B喽。 既然有了更多的“缓存”,我们继续采用8x8的分块方式,不过在这里有些神奇的操作,注意A中的8x8方块可以经变换后完全放进B中对应的8x8方块中
- 首先将A中黄色部分平移到B中
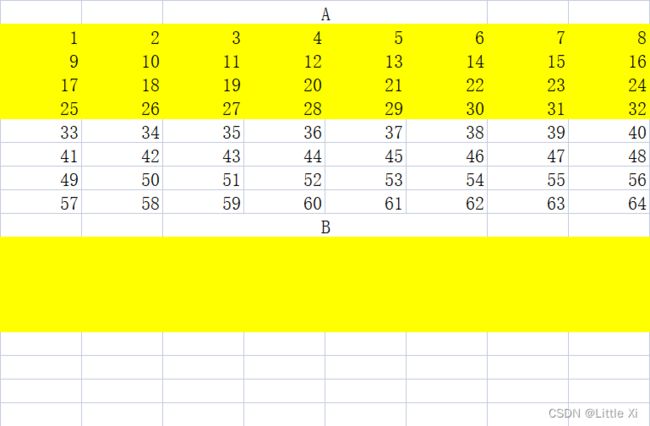
实现代码
for(int k=0;k<4;k++) //黄色->黄色
{
int a1=A[i+k][j];
int a2=A[i+k][j+1];
int a3=A[i+k][j+2];
int a4=A[i+k][j+3];
int a5=A[i+k][j+4];
int a6=A[i+k][j+5];
int a7=A[i+k][j+6];
int a8=A[i+k][j+7];
B[j][i+k]=a1;
B[j+1][i+k]=a2;
B[j+2][i+k]=a3;
B[j+3][i+k]=a4;
B[j][i+k+4]=a5;
B[j+1][i+k+4]=a6;
B[j+2][i+k+4]=a7;
B[j+3][i+k+4]=a8;
}
-
然后这一步非常关键,用变量存储蓝色部分,用变量存储绿色部分,将绿色部分移动到红色位置,将蓝色部分移动到绿色位置,注意顺序!!!同样的操作对棕色部分进行同样的操作。为什么这一步很重要呢,因为在这里我们相当于把绿色部分极其以下3行当作了缓存,暂时转移存储了起来,在操作这一步的时候符合空间局部性,先后进行了两次访问,第二次访问的时候必然不会miss,减少了1/4的miss!

实现代码
for(int k=0;k<4;k++) //蓝色->绿色,绿色->红色 { int x=i+4; int y=j; int aa1=A[x][y+k]; int aa2=A[x+1][y+k]; int aa3=A[x+2][y+k]; int aa4=A[x+3][y+k]; x=j; y=i+4; int a1=B[x+k][y]; int a2=B[x+k][y+1]; int a3=B[x+k][y+2]; int a4=B[x+k][y+3]; x=i+4; y=j; B[y+k][x]=aa1; B[y+k][x+1]=aa2; B[y+k][x+2]=aa3; B[y+k][x+3]=aa4; x=j; y=i+4; B[x+k+4][y-4]=a1; B[x+k+4][y-3]=a2; B[x+k+4][y-2]=a3; B[x+k+4][y-1]=a4; } -
最后一步就非常简单啦,将紫色部分正常转置就行啦

实现代码
for(int k=0;k<4;k++) //紫色->紫色 { int x=i+4; int y=j+4; int a1=A[x+k][y]; int a2=A[x+k][y+1]; int a3=A[x+k][y+2]; int a4=A[x+k][y+3]; B[y][x+k]=a1; B[y+1][x+k]=a2; B[y+2][x+k]=a3; B[y+3][x+k]=a4; }
64x64完整AC代码
if(M==64)
{
for(int i=0;i<64;i+=8)
{
for(int j=0;j<64;j+=8)
{
for(int k=0;k<4;k++) //将A中的8x8左上角直接转置,右上角平移到B的对应位置
{
int a1=A[i+k][j];
int a2=A[i+k][j+1];
int a3=A[i+k][j+2];
int a4=A[i+k][j+3];
int a5=A[i+k][j+4];
int a6=A[i+k][j+5];
int a7=A[i+k][j+6];
int a8=A[i+k][j+7];
B[j][i+k]=a1;
B[j+1][i+k]=a2;
B[j+2][i+k]=a3;
B[j+3][i+k]=a4;
B[j][i+k+4]=a5;
B[j+1][i+k+4]=a6;
B[j+2][i+k+4]=a7;
B[j+3][i+k+4]=a8;
}
for(int k=0;k<4;k++) //!这里明显符合空间局部性原则,在中间两步同时访问了同一块地址,必定不会miss
{
int x=i+4;
int y=j;
int aa1=A[x][y+k];
int aa2=A[x+1][y+k];
int aa3=A[x+2][y+k];
int aa4=A[x+3][y+k];
x=j;
y=i+4;
int a1=B[x+k][y];
int a2=B[x+k][y+1];
int a3=B[x+k][y+2];
int a4=B[x+k][y+3];
x=i+4;
y=j;
B[y+k][x]=aa1;
B[y+k][x+1]=aa2;
B[y+k][x+2]=aa3;
B[y+k][x+3]=aa4;
x=j;
y=i+4;
B[x+k+4][y-4]=a1;
B[x+k+4][y-3]=a2;
B[x+k+4][y-2]=a3;
B[x+k+4][y-1]=a4;
}
for(int k=0;k<4;k++) //这里把A的8x8矩阵的右下角正常转置就行了
{
int x=i+4;
int y=j+4;
int a1=A[x+k][y];
int a2=A[x+k][y+1];
int a3=A[x+k][y+2];
int a4=A[x+k][y+3];
B[y][x+k]=a1;
B[y+1][x+k]=a2;
B[y+2][x+k]=a3;
B[y+3][x+k]=a4;
}
}
}
61x67矩阵
这是一共不规则的矩阵,但是由于限制条件非常宽松miss<2000,实际上不用做非常多的优化,就和32x32矩阵一样,只不过关于分块有些不同,8x8过不了,于是我们可以尝试一些比较大的分块方法,比如分块32x8,运行后miss=1962,就顺利满分通过啦~
61x67AC代码
if(M==61)
{
for(int i=0;i<67;i+=32)
{
for(int j=0;j<61;j+=8)
{
for(int k=0;k<32;k++)
{
for(int l=0;l<8;l++)
{
if(j+l>=61||i+k>=67)
continue;
B[j+l][i+k]=A[i+k][j+l];
}
}
}
}
}
完整AC代码展示
if(M==32)
{
for(int i=0;i<32;i+=8)
{
for(int j=0;j<32;j+=8)
{
for(int k=0;k<8;k++)
{
int num1=A[i+k][j];
int num2=A[i+k][j+1];
int num3=A[i+k][j+2];
int num4=A[i+k][j+3];
int num5=A[i+k][j+4];
int num6=A[i+k][j+5];
int num7=A[i+k][j+6];
int num8=A[i+k][j+7];
B[j][i+k]=num1;
B[j+1][i+k]=num2;
B[j+2][i+k]=num3;
B[j+3][i+k]=num4;
B[j+4][i+k]=num5;
B[j+5][i+k]=num6;
B[j+6][i+k]=num7;
B[j+7][i+k]=num8;
}
}
}
}
if(M==64)
{
for(int i=0;i<64;i+=8)
{
for(int j=0;j<64;j+=8)
{
for(int k=0;k<4;k++) //将A中的8x8左上角直接转置,右上角平移到B的对应位置
{
int a1=A[i+k][j];
int a2=A[i+k][j+1];
int a3=A[i+k][j+2];
int a4=A[i+k][j+3];
int a5=A[i+k][j+4];
int a6=A[i+k][j+5];
int a7=A[i+k][j+6];
int a8=A[i+k][j+7];
B[j][i+k]=a1;
B[j+1][i+k]=a2;
B[j+2][i+k]=a3;
B[j+3][i+k]=a4;
B[j][i+k+4]=a5;
B[j+1][i+k+4]=a6;
B[j+2][i+k+4]=a7;
B[j+3][i+k+4]=a8;
}
for(int k=0;k<4;k++) //!这里明显符合空间局部性原则,在中间两步同时访问了同一块地址,必定不会miss
{
int x=i+4;
int y=j;
int aa1=A[x][y+k];
int aa2=A[x+1][y+k];
int aa3=A[x+2][y+k];
int aa4=A[x+3][y+k];
x=j;
y=i+4;
int a1=B[x+k][y];
int a2=B[x+k][y+1];
int a3=B[x+k][y+2];
int a4=B[x+k][y+3];
x=i+4;
y=j;
B[y+k][x]=aa1;
B[y+k][x+1]=aa2;
B[y+k][x+2]=aa3;
B[y+k][x+3]=aa4;
x=j;
y=i+4;
B[x+k+4][y-4]=a1;
B[x+k+4][y-3]=a2;
B[x+k+4][y-2]=a3;
B[x+k+4][y-1]=a4;
}
for(int k=0;k<4;k++) //这里把A的8x8矩阵的右下角正常转置就行了
{
int x=i+4;
int y=j+4;
int a1=A[x+k][y];
int a2=A[x+k][y+1];
int a3=A[x+k][y+2];
int a4=A[x+k][y+3];
B[y][x+k]=a1;
B[y+1][x+k]=a2;
B[y+2][x+k]=a3;
B[y+3][x+k]=a4;
}
}
}
printf("%d",A[0][0]);
}
if(M==61)
{
for(int i=0;i<67;i+=32)
{
for(int j=0;j<61;j+=8)
{
for(int k=0;k<32;k++)
{
for(int l=0;l<8;l++)
{
if(j+l>=61||i+k>=67)
continue;
B[j+l][i+k]=A[i+k][j+l];
}
}
}
}
}
然后将我们的代码填充进trans.c的
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
}
函数中
运行
make
python2 ./driver.py
即可得到一份满分AC图
Your simulator Reference simulator
Points (s,E,b) Hits Misses Evicts Hits Misses Evicts
3 (1,1,1) 9 8 6 9 8 6 traces/yi2.trace
3 (4,2,4) 4 5 2 4 5 2 traces/yi.trace
3 (2,1,4) 2 3 1 2 3 1 traces/dave.trace
3 (2,1,3) 167 71 67 167 71 67 traces/trans.trace
3 (2,2,3) 201 37 29 201 37 29 traces/trans.trace
3 (2,4,3) 212 26 10 212 26 10 traces/trans.trace
3 (5,1,5) 231 7 0 231 7 0 traces/trans.trace
6 (5,1,5) 265189 21775 21743 265189 21775 21743 traces/long.trace
27
Part B: Testing transpose function
Running ./test-trans -M 32 -N 32
Running ./test-trans -M 64 -N 64
Running ./test-trans -M 61 -N 67
Cache Lab summary:
Points Max pts Misses
Csim correctness 27.0 27
Trans perf 32x32 8.0 8 287
Trans perf 64x64 8.0 8 1236
Trans perf 61x67 10.0 10 1962
Total points 53.0 53
至此,partB完结撒花~