一文教你搞懂Redis集群
一、Redis主从
1.1、搭建主从架构
单节点的Redis的并发能力是有上限的,要进一步的提高Redis的并发能力,据需要大家主从集群,实现读写分离。

共包含三个实例,由于资源有限,所以在一台虚拟机上,开启多个redis的实例,端口不同,下面是具体的配置
| IP | PORT | 角色 |
|---|---|---|
| 192.168.152.133 | 7001 | master |
| 192.168.152.133 | 7002 | slave/replica |
| 192.168.152.133 | 7003 | slave/replica |
第一步:准备实例和配置
要在同一台虚拟机上开启三个redis实例,就必须要准备三分不同的redis.conf的配置文件,为了方便管理,这里创建三个文件夹,存放不同的配置文件
- 创建目录
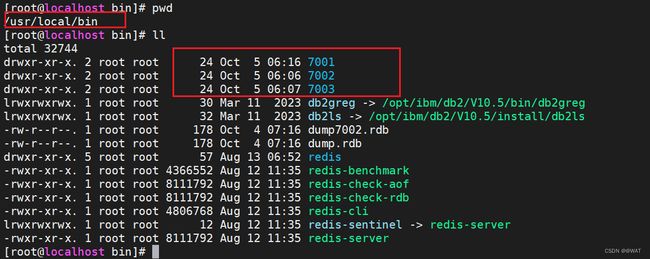
创建出三个分别以端口号命名的文件夹7001,7002,7003
# 进入redis的按照目录
cd /usr/local/bin
# 创建目录
mkdir -p 7001 7002 7003
ll
如图:
- 修改配置文件
修改redis.conf的配置文件,将其中的持久化模式改为开启rdb,关闭aof,并指定ip,端口。
其中如果想要用redis的可视化连接工具链接,还需要关闭保护模式
protected-mode no
# 关闭aof
appendonly no
思考:为什么要开启rdb模式,关闭aof呢❓
- 拷贝配置文件到7001,7002,7003
#方式一:逐个拷贝
cp /opt/redis-5/redis.conf ./7001/
cp /opt/redis-5/redis.conf ./7002/
cp /opt/redis-5/redis.conf ./7003/
#方式二:管道操作
echo 7001 7002 7003 | xargs -t -n 1 cp redis-5/redis.conf
- 修改端口,数据保存目录
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/usr\/local\/bin\/7001\//g' ./7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/usr\/local\/bin\/7002\//g' ./7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/usr\/local\/bin\/7003\//g' ./7003/redis.conf
daemonize no:表示不后台启动,实际生产需要修改为yes,这里为了方便观察日志,暂时关闭
- 修改每个实例的声明IP
虚拟机本身存在多个ip,为了避免混淆,我们需要在配置文件的第一行,声明每个实例的IP
sed -i '1a replica-announce-ip 192.168.152.133' ./7001/redis.conf
sed -i '1a replica-announce-ip 192.168.152.133' ./7002/redis.conf
sed -i '1a replica-announce-ip 192.168.152.133' ./7003/redis.conf
第二步:启动redis实例
执行如下命令
redis-server ./7001/redis.conf
redis-server ./7002/redis.conf
redis-server ./7003/redis.conf
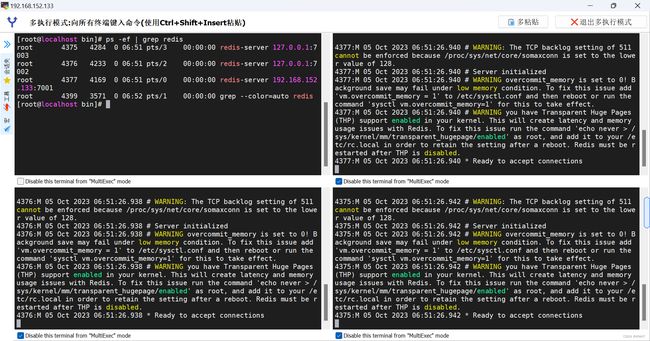
第三步:构建主从关系
完成上面的操作之后,其实还没有完成主从的搭建,因为这样只是启动三个单独的redis实例,这三个redis实例之间没有任何的联系。需要在从节点下执行如下命令:
# 方式一:永久修改
在redis.conf文件里添加slaveof masterIp masterPort
只要添加了这行命令的redis实例就会成为被添加的masterIp的从节点
# 方式二,临时修改,重启后将失效
# 进入redis-cli客户端,执行slaveof
slaveof 主节点IP 主节点端口

观察日志变化:
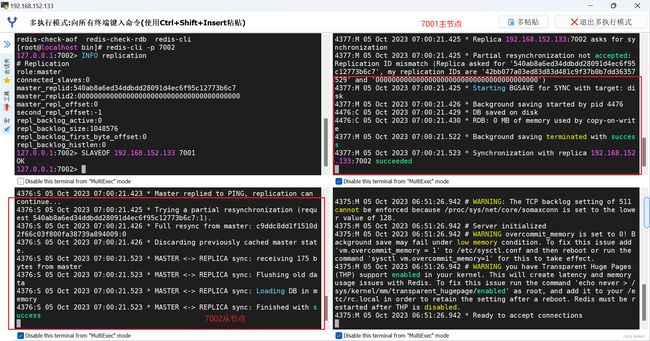
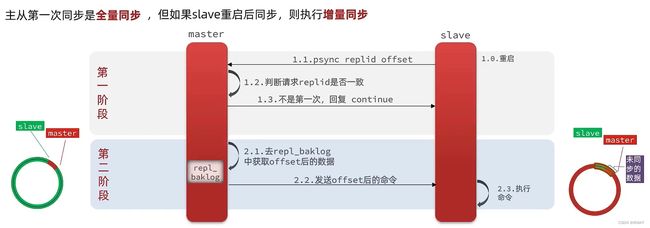
1.2、主从同步原理
全量同步
数据同步图解
数据同步原理
Redis主从的第一次数据同步是全量同步:

如何判断是否是第一次
那么由上图我们可以知道master必须要对发来的slave节点进行判断,看是不是第一次,如果是第一次,需要做全量同步数据,那么问题来了?master怎么知道是不是第一次呢???
这里就涉及到了两个概念:
-
Replication Id: 简称replid,是数据集的标记,id一致则说明是同一个数据集,每一个master都有唯一的replid,slave则会继承master的replid。
-
**offset:**随着repl_back_log中地数据量的增大而增加,slave完成同步时也会记录当前地offset,所以slave地offset偏移量一定是小于等于,master地offset。

答案是Replid,因为slave在成成为master地从节点之前,自己也是master,也有自己的replid,故replid是唯一的。
日志分析
接下来我们看下日志进行进一步的分析:
【步骤一】:

【步骤二】:
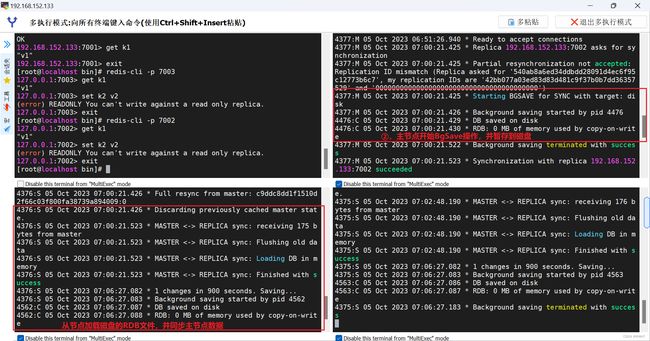
【步骤三】:
由于是第一次,所以没有offset,故没有日志,但是redis后台会监控
增量同步
增量同步图解
增量同步地关键就是repl_baklog,上面讲过一个概念offset,他记录的是主从节点同步的节点信息,也就是说假如slave宕机了,但是这个时候master还持续地往里面写数据,这个时候slave地offset一直没有增加,而master地offset一直在增加。当我们地slave重新恢复的时候,slave地offset与master地offset的差值,就是slave需要做增量同步的数据。
那么repl_baklog是怎么实现记录的操作呢?
原理就如上图左下角所示:
repl_baklog数据结构实际上就是一个环形数组,绿色的部分代表slave的offset,而红色的部分代表需要同步的数据,也就是master的offset与slave的offset的差值,我们实际要关注的也就是这部分。
什么时候无法增量同步

由于是一个环形的数据结构,所以一旦master的offset覆盖掉slave宕机前的offset位置,那么此时就无法实现增量同步。
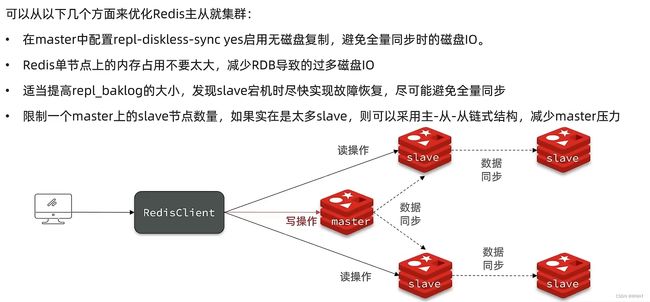
如何优化主从集群
二、Redis哨兵
思考:
- slave节点宕机恢复后可以找master节点数据同步,
- 那master节点宕机了呢,怎么办?
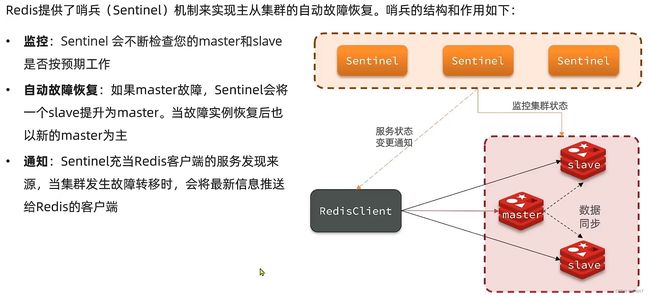
2.1、哨兵的作用与原理
哨兵的作用
Redis提供了哨兵模式(Sentinel),其主要的作用就是监控主从集群,用于自动的故障检测与恢复,以及通知。
服务状态监控
选举新的Master

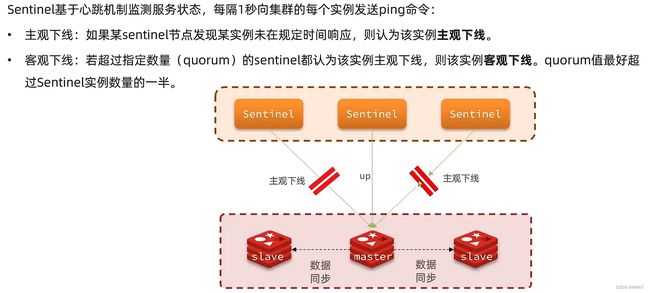
故障转移原理

⚓️注意:
当原master宕机后,sentinel会选举出新的master,同时会强制修改master节点的redis.conf配置文件,添加一行:
slaveof <新的masterip> <新的master端口>故,如果重新使用原理的redis.conf启动主从,就无法实现主从的搭建。
2.2、搭建哨兵集群
| 节点 | PORT | 角色 |
|---|---|---|
| sentinel1 | 27001 | master |
| sentinel2 | 27002 | slave/replica |
| sentinel3 | 27003 | slave/replica |
第一步:准备实例和配置
必须要准备三分不同的sentinel.conf的配置文件,为了方便管理,这里创建三个文件夹,存放不同的配置文件:sentinel27001 sentinel27002 sentinel27003
- 创建目录
创建出三个分别以端口号命名的文件夹7001,7002,7003
# 进入redis的按照目录
cd /usr/local/bin
# 创建目录
mkdir -p sentinel27001 sentinel27002 sentinel27003
ll
如图:
- 修改配置文件
sentinel.conf的配置文件,
vim ./sentinel27001/sentinel.conf
port 27001
sentinel announce-ip 192.168.152.133
# 客观下线数目 2台sentinel都认为下线则认为主管下线
# mymaster 为sentinel的名字,随意,但是前后须保持一致
# 192.168.152.133 7001 为master主节点的ip,端口
sentinel monitor mymaster 192.168.152.133 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/usr/local/bin/sentinel27001"
- 拷贝配置文件到sentinel27002,sentinel27003
#方式二:管道操作
echo sentinel27002 sentinel27003 | xargs -t -n 1 cp ./sentinel27001/sentinel.conf
- 修改端口,数据保存目录
sed -i -e 's/27001/27002/g' -e 's/sentinel27001/sentinel27002/g' ./sentinel27002/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/sentinel27001/sentinel27003/g' ./sentinel27003/sentinel.conf
daemonize no:表示不后台启动,实际生产需要修改为yes,这里为了方便观察日志,暂时关闭
- 修改每个实例的声明IP
虚拟机本身存在多个ip,为了避免混淆,我们需要在配置文件的第一行,声明每个实例的IP
sed -i '1a replica-announce-ip 192.168.152.133' ./7001/redis.conf
sed -i '1a replica-announce-ip 192.168.152.133' ./7002/redis.conf
sed -i '1a replica-announce-ip 192.168.152.133' ./7003/redis.conf
第二步:启动sentinel实例
执行如下命令
redis-sentinel ./sentinel27001/sentinel.conf
redis-sentinel ./sentinel27002/sentinel.conf
redis-sentinel ./sentinel27003/sentinel.conf

第三步:模拟master宕机

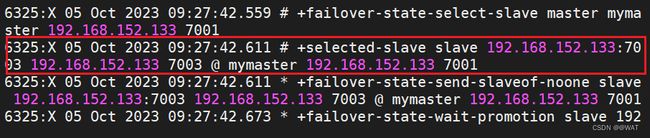
哨兵服务监控7001状态,并完成新的sentinel-leader的选举,并最终由选举出来的sentinel-leader完成故障恢复

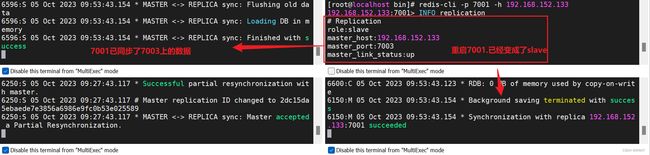
由选举出来的27001哨兵选举出7003节点,成为新的master,并向7003发送了一个slaveof-noone的命令【起来,不愿做奴隶的人】,使得7003成为新的master
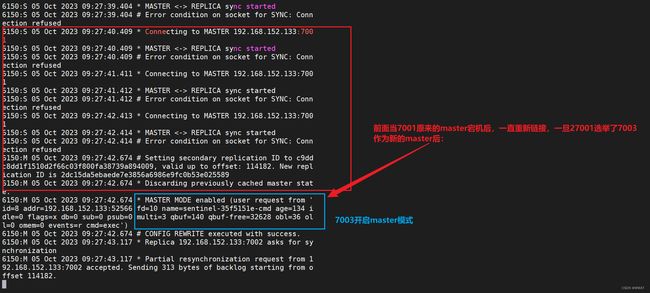
向7001发起reconf命令
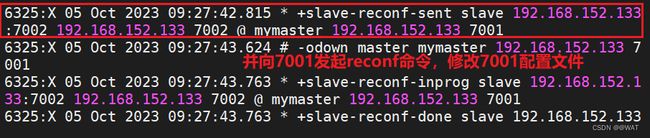
恢复7001节点后,地位变成了slave,并实现了一次全量同步数据7003
2.3、RedisTemplate的哨兵模式
SpringBoot为访问Redis,提供了一个RedisTemplate的包,集成了Lettuce和Jedis两种Java访问Redis的客户端,接下来,让我们来使用一下:
【引入依赖】
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.73version>
dependency>
application.yml
server:
port: 9088
# 开启redis的日志
logging:
level:
'[io.lettuce.core]': debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
# redis配置信息
spring:
redis:
sentinel:
master: mymaster
nodes:
- 192.168.152.133:27001
- 192.168.152.133:27002
- 192.168.152.133:27003
【redisConfig配置类】
import org.springframework.boot.autoconfigure.AutoConfigureBefore;
import org.springframework.boot.autoconfigure.data.redis.LettuceClientConfigurationBuilderCustomizer;
import org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import io.lettuce.core.ReadFrom;
/**
* @ClassName: RedisConfig
* @Description: Redis配置类
* @author weiyongpeng
* @date 2023年10月5日 下午12:37:19
*/
@Configuration
@AutoConfigureBefore(RedisAutoConfiguration.class)
public class RedisConfig {
/**
* 方法描述: 初始化redis连接
* @param factory redis连接工厂
* @return {@link RedisTemplate}
*/
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory factory) {
// 新建redisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置工厂
template.setConnectionFactory(factory);
//序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//1,用StringRedisSerializer进行序列化的值,在Java和Redis中保存的内容是一样的
//2,用Jackson2JsonRedisSerializer进行序列化的值,在Redis中保存的内容,比Java中多了一对双引号。
//3,用JdkSerializationRedisSerializer进行序列化的值,对于Key-Value的Value来说,是在Redis中是不可读的。对于Hash的Value来说,比Java的内容多了一些字符。
//如果Key的Serializer也用和Value相同的Serializer的话,在Redis中保存的内容和上面Value的差异是一样的,所以我们保存时,只用StringRedisSerializer进行序列化
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(stringRedisSerializer);
// 返回redisTemplate对象
return template;
}
/**
* 描述:配置读写分离
* @Title: configurationBuilderCustomizer
* @return
* @author weiyongpeng
* @date 2023年10月5日 上午10:20:57
*/
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {
// REPLICA_PERFERED:表示优先从从节点读取数据,当从节点都挂掉,才去读master
return configurate -> configurate.readFrom(ReadFrom.REPLICA_PREFERRED);
}
}
三、Redis分片集群
3.1、搭建分片集群
首先在搭建Redis分片集群之前,先了解下分片集群可以解决哨兵和主从无法解决的那些问题,以及分片式集群的特征:

**注意:**在使用RedisTemplate访问分片集群的时候,就不需要指定主从关系,可以访问任意一台节点,redis会实现自动的路由转发机制
共包含六个实例,由于资源有限,所以在一台虚拟机上,开启多个redis的实例,端口不同,下面是具体的配置
| IP | PORT | 角色 |
|---|---|---|
| 192.168.152.133 | 7001 | master |
| 192.168.152.133 | 7002 | master |
| 192.168.152.133 | 7003 | master |
| 192.168.152.133 | 8001 | slave |
| 192.168.152.133 | 8002 | slave |
| 192.168.152.133 | 8003 | slave |
第一步:准备实例和配置
为了完成3主3从的redis分片集群的搭建,必须要准备六份不同的redis.conf的配置文件,为了方便管理,这里创建六个文件夹,存放不同的配置文件:cluster7001 cluster7002 cluster7003 cluster8001 cluster8002 cluster8003
- 创建目录
创建出三个分别以端口号命名的文件夹cluster7001 cluster7002 cluster7003 cluster8001 cluster8002 cluster8003
# 进入redis的按照目录
cd /usr/local/bin
# 创建目录
mkdir -p cluster7001 cluster7002 cluster7003 cluster8001 cluster8002 cluster8003
ll
如图:

- 修改配置文件
重新生成redis.conf的配置文件,
vim ./cluster7001/redis.conf
port 7001
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,需要redis自己维护
cluster-config-file /usr/local/bin/cluster7001/nodes.conf
# 节点心跳超时链接时间
cluster-node-timeout 5000
# 持久化数据文件存放路径
dir "/usr/local/bin/cluster7001"
# 绑定地址
bind 192.168.152.133
# 开启后台运行
daemonize yes
# 声明IP
replica-announce-ip 192.168.152.133
# 保护模式关闭
protected-mode no
# 日志文件路径
logfile "/usr/local/bin/cluster7001/cluster.log"
- 拷贝配置文件到cluster7002 cluster7003 cluster8001,cluster8002 cluster8003
#方式二:管道操作
echo cluster7002 cluster7003 cluster8001 cluster8002 cluster8003 | xargs -t -n 1 cp ./cluster7001/redis.conf
- 修改端口,数据保存目录
printf '%s\n' cluster7002 cluster7003 cluster8001 cluster8002 cluster8003 | xargs -I{} -t sed -i 's/cluster7001/{}/g' {}/redis.conf
daemonize no:表示不后台启动,实际生产需要修改为yes,这里为了方便观察日志,暂时关闭
第二步:启动
执行如下命令
cd /usr/local/bin
printf '%s\n' cluster7001 cluster7002 cluster7003 cluster8001 cluster8002 cluster8003 | xargs -I{} -t redis-server ./{}/redis.conf
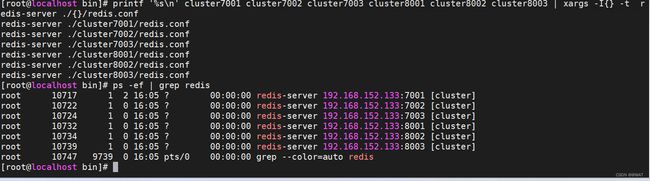
注意,此时还没有完成集群的配置,因为这个时候6台redis实例话没有形成任何的关联关系。
第三步:创建集群
针对redis5.x之后的把版本,执行下述命令:
redis-cli --cluster create --cluster-replicas 1 192.168.152.133:7001 192.168.152.133:7002 192.168.152.133:7003 192.168.152.133:8001 192.168.152.133:8002 192.168.152.133:8003
命令说明
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表创建集群--replicas 1或者--cluster-replicas 1:代表集群中每个master的副本个数为1,master+slave的比例就是2,那么总节点数➗(master+salve的比例)就是当前master个数,那么其余的就是salve
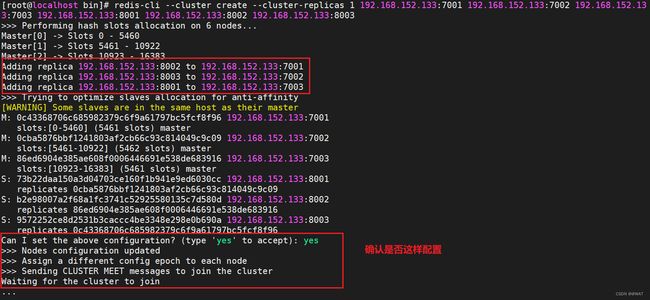

自此集群创建完毕,那么我们如何查看集群的状态呢?
redis-cli -p 7001 -h 192.168.152.133 cluster nodes

3.2、散列插槽原理
Redis会把每一个Master节点映射到0-16383之间共16384个插槽(hash solt)上,查看集群信息时就能看到:

这些的solts总和正好是16384。
为什么要使用插槽呢?原因很简单:
**因为redis的节点时有可能宕机的,所以redis的key并不是与节点所绑定的,而是与插槽绑定。**redis会根据key的有效部分计算插槽,分两种情况:
- key中包含{},且{}中至少有一个字符,{}中的部分就是有效部分
- key中不包含{},整个key作为有效部分
![]()
**注意:在集群模式下,必须使用
-c**参数链接redis-cli


所以这就是为什么我们说,访问集群的任意一个节点,都可以,因为他们是通过槽的值自动切换。
总结
- 如何将同一类的数据固定保存在同一个Redis实例中?
这一类数据使用同样的key有效部分,例如key都以{typeid}作为前缀
3.3、集群伸缩
添加一个节点到集群

[root@localhost bin]# mkdir -p cluster7004
[root@localhost bin]# cp ./cluster7001/redis.conf ./cluster7004/
[root@localhost bin]# sed -i 's/7001/7004/g' ./cluster7004/redis.conf
[root@localhost bin]# redis-server ./cluster7004/redis.conf
[root@localhost bin]# ps -ef | grep redis
root 10717 1 0 16:05 ? 00:00:04 redis-server 192.168.152.133:7001 [cluster]
root 10722 1 0 16:05 ? 00:00:04 redis-server 192.168.152.133:7002 [cluster]
root 10724 1 0 16:05 ? 00:00:04 redis-server 192.168.152.133:7003 [cluster]
root 10732 1 0 16:05 ? 00:00:04 redis-server 192.168.152.133:8001 [cluster]
root 10734 1 0 16:05 ? 00:00:04 redis-server 192.168.152.133:8002 [cluster]
root 10739 1 0 16:05 ? 00:00:04 redis-server 192.168.152.133:8003 [cluster]
root 11285 1 0 16:48 ? 00:00:00 redis-server 192.168.152.133:7004 [cluster]
root 11290 9739 0 16:48 pts/0 00:00:00 grep --color=auto redis
[root@localhost bin]#
启动完后,查看此时的7004的集群信息

接下来,我们就要使用add-node添加到集群中
redis-cli --cluster add-node 192.168.152.133:7004 192.168.152.133:7001

但是,我们这个时候查看一下redis7004的集群信息发现,新增的7004没有插槽分配

使用reshard实现插槽的重新分配
redis-cli --cluster reshard 192.168.152.133:7001 # 表示重新分配7001的插槽

分配完后查看7004的集群状态,发现已经实现类分配


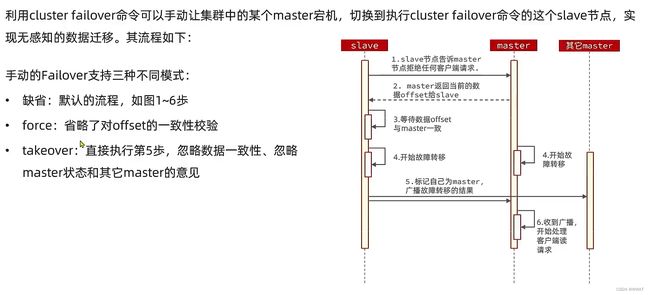
3.4、故障转移
自动故障转移

手动故障转移
3.5、RedisTemplate访问分片集群
spring:
redis:
cluster:
# 集群节点
nodes:
- 192.168.152.133:7001
- 192.168.152.133:7002
- 192.168.152.133:7003
- 192.168.152.133:8001
- 192.168.152.133:8002
- 192.168.152.133:8003
# 最大重定向次数
max-redirects: 5
其余配置和哨兵一致,只需要修改application.yml文件即可