高效的ProtoBuf
一、背景
Google ProtoBuf介绍 这篇文章我们讲了怎么使用ProtoBuf进行序列化,但ProtoBuf怎么做到最高效的,它的数据又是如何压缩的,下面先看一个例子,然后再讲ProtoBuf压缩机制。
二、案例
网上有各种序列化方式性能对比,我们这里仅对比一下JSON序列化和ProtoBuf序列化。
原始数据如下
{
"id":1,
"name":"qingcai18036",
"email":"[email protected]"
}序列化后十六进值如下

可以看出使用ProtoBuf序列化后的十六进值长度要小很多。
三、基础概念
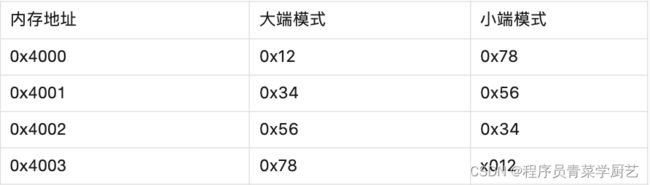
1、大小端模式
大端模式:数据的高字节保存在内存低地址中,数据的低字节保存在内存高地址中。
小端模式:数据的高字节保存在内存高地址中,数据的低字节保存在内存的低地址中。
这里记住小端模式的存储是 高高低低,小端模式也是ProtoBuf协议中使用的模式。
十六进制数据 0x12345678,大小端模式在内存的存放如下
2、ZigZag编码
ZigZag是一种对负数友好的压缩算法,可以压缩掉多余为0的比特位。
正数:byte a = 11; 存储用原码表示二进制值:0000 1011
ZigZag对正数进行编码
整体数据左移1位: 0001 0110
符号位移到最低位 :0001 0110
负数:byte a =-11; 存储用补码表示二进值 :11110101
原码:10001011-> 反码:11110100-> 补码:11110101
ZigZag对负数进行编码
(1)、左移1位:11101010
(2)、符号位移到最低位:11101011
(3)、除最后一位外全部取反:00010101
ZigZag 对负数-11增加了前导三个0,可以压缩掉
3、 Varint编码
Varint是一种使用一个或多个字节序列化整数的办法,对于32位的整数用Varint编码后为1~5个字节,小的数字使用1个byte,大的数字使用5个byte。但实际场景中小数字使用率大于大数字,这样就达到压缩效果,而Java序列化Int需要用4个byte。
Varint每个字节中每一比特位定义
![]()
第8位(最高位):1:表示后续的字节也是该数字的一部分 0:表示该数字结束。
第1~7位:表示具体数字值
Varint编码例子
小于128的数字用一个字节就可以表示,大于128的数比如1234,需要用到2个字节表示。
1234 二进制值 10011010010
在Java中Int类型占用4个字节,如果直接使用Java序列化存储如下
00000000 00000000 00000100 11010010
前面有21个0造成空间的浪费,可以对空位(0)进行压缩,节省空间。
Varint编码:从右往左每隔7位取一片段并补上标识位,再将若干片段从左往右排序。
(1)、从右往左取7位 1010010,并补上标记位(1表示后续还有数据) 11010010
(2)、再续继取7位 000100 1,并补上标记位(0表示后续没有数据)00001001
(3)、再往左已经全部是0了,就不管了。
(4)、然后将上面形成的两个片段从左往右排列(小端模式) 11010010 00001001
最终整数1234做Varint编码后二进制为 11010010 00001001
四、ProtoBuf协议
1、ProtoBuf序列结构
![]()
2、Key定义: (field_number << 3) | wire_type
field_number 是 定义在proto文件中字段的序号
3、wire_type

-
Type=1 :如果是 int32采用Varints编码编码,如果是sint32采用ZigZag编码(因为要对负数进行有效压缩)。
-
Type=1:分配64位大小空间,采用小端模式
-
Type=5:分配32位大小空间,采用小端模式
-
Type=2:string是一个指定长度的编码,key+length+content,key编码采用统一的方式,length(内容长度)采用varints编码,content就是由length指定长度的byte。所以其对字符串本身的内容并不压缩?
五、总结
ProtoBuf采用了Varint、ZigZa压缩算法,二制制的数据就非常紧凑,并且比JSON少了{}符号、字段名、所以用ProtoBuf序列化后整体体积会更小,这样网络传输更快,更高效。