基于YOLOv8的安全帽检测系统(4):EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA,助力行为检测 | ICASSP2023
目录
1.Yolov8介绍
2.安全帽数据集介绍
3.EMA介绍
4.训练结果分析
5.系列篇
1.Yolov8介绍
Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO成功基础上,并引入了新功能和改进,以进一步提升性能和灵活性。它可以在大型数据集上进行训练,并且能够在各种硬件平台上运行,从CPU到GPU。
具体改进如下:
-
Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
-
PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
-
Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
-
Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
-
损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
-
样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式

框架图提供见链接:Brief summary of YOLOv8 model structure · Issue #189 · ultralytics/ultralytics · GitHub
2.安全帽数据集介绍
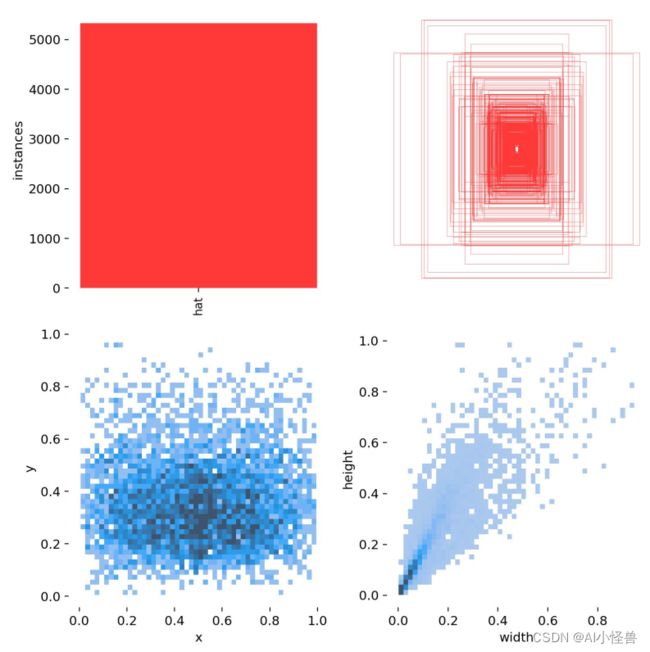
数据集大小3241张,train:val:test 随机分配为7:2:1,类别:hat

3.EMA介绍

论文:https://arxiv.org/abs/2305.13563v1
录用:ICASSP2023

通过通道降维来建模跨通道关系可能会给提取深度视觉表示带来副作用。本文提出了一种新的高效的多尺度注意力(EMA)模块。以保留每个通道上的信息和降低计算开销为目标,将部分通道重塑为批量维度,并将通道维度分组为多个子特征,使空间语义特征在每个特征组中均匀分布。

提出了一种新的无需降维的高效多尺度注意力(efficient multi-scale attention, EMA)。请注意,这里只有两个卷积核将分别放置在并行子网络中。其中一个并行子网络是一个1x1卷积核,以与CA相同的方式处理,另一个是一个3x3卷积核。为了证明所提出的EMA的通用性,详细的实验在第4节中给出,包括在CIFAR-100、ImageNet-1k、COCO和VisDrone2019基准上的结果。图1给出了图像分类和目标检测任务的实验结果。我们的主要贡献如下:
本文提出了一种新的跨空间学习方法,并设计了一个多尺度并行子网络来建立短和长依赖关系。
1)我们考虑一种通用方法,将部分通道维度重塑为批量维度,以避免通过通用卷积进行某种形式的降维。
2)除了在不进行通道降维的情况下在每个并行子网络中构建局部的跨通道交互外,我们还通过跨空间学习方法融合两个并行子网络的输出特征图。
3)与CBAM、NAM[16]、SA、ECA和CA相比,EMA不仅取得了更好的结果,而且在所需参数方面效率更高。

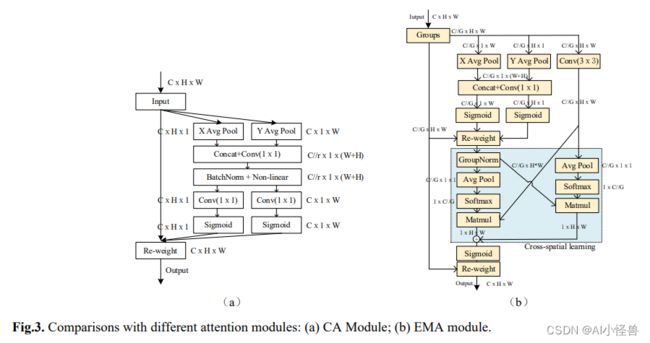
CA块首先可以被视为与SE注意力模块类似的方法,其中利用全局平均池化操作对跨通道信息进行建模。通常,可以通过使用全局平均池化来生成信道统计信息,其中全局空间位置信息被压缩到信道描述符中。与SE微妙不同的是,CA将空间位置信息嵌入通道注意图以增强特征聚合。
并行子结构帮助网络避免更多的顺序处理和大深度。给定上述并行处理策略,我们在EMA模块中采用它。EMA的整体结构如图3 (b)所示。在本节中,我们将讨论EMA如何在卷积操作中不进行通道降维的情况下学习有效的通道描述,并为高级特征图产生更好的像素级注意力。具体来说,我们只从CA模块中挑选出1x1卷积的共享组件,在我们的EMA中将其命名为1x1分支。为了聚合多尺度空间结构信息,将3x3内核与1x1分支并行放置以实现快速响应,我们将其命名为3x3分支。考虑到特征分组和多尺度结构,有效地建立短期和长程依赖有利于获得更好的性能。
源码详见:
Yolov8改进---注意力机制:ICASSP2023 EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA | 小目标涨点明显_AI小怪兽的博客-CSDN博客
4.训练结果分析
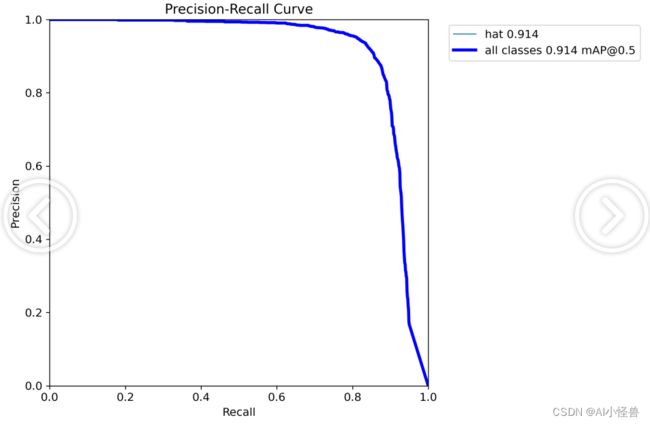
训练结果如下:
[email protected] 0.897提升至0.914
5.系列篇
1)基于YOLOv8的安全帽检测系统-CSDN博客
2)基于YOLOv8的安全帽检测系统(2):Gold-YOLO,遥遥领先,助力行为检测 | 华为诺亚NeurIPS23-CSDN博客
3) 基于YOLOv8的安全帽检测系统(3):DCNv3可形变卷积,基于DCNv2优化,助力行为检测 | CVPR2023 InternImage_AI小怪兽的博客-CSDN博客
4) 基于YOLOv8的安全帽检测系统(4):EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA,助力行为检测 | ICASSP2023_AI小怪兽的博客-CSDN博客