【Spring笔记04】Spring中Bean的生命周期及Bean的后置处理器
这篇文章主要介绍的是Spring框架中Bean的生命周期,Bean的后置处理器、以及多个后置处理器的先后执行顺序。
目录
一、生命周期介绍
1.1、什么是Bean的生命周期
1.2、Bean生命周期的过程
(1)实例化阶段
(2)依赖注入阶段
(3)初始化阶段
(4)使用阶段
(5)销毁阶段
二、Bean的后置处理器
2.1、如何使用Bean的后置处理器
2.2、后置处理器执行顺序
一、生命周期介绍
1.1、什么是Bean的生命周期
生命周期,指的是:Spring框架中一个Bean对象从实例化到被垃圾回收器回收的这么一个过程,我们通常把这个过程称作:Bean的生命周期。
简单理解,就是一个Bean对象从创建到销毁的这么一个过程,就好比一个人从出生到死亡的这么一个阶段一样。
Spring中Bean的生命周期大致可以分为五个阶段,分别是:实例化、依赖注入、初始化、使用阶段、销毁阶段。下面详细的介绍一下Bean的生命周期过程。
1.2、Bean生命周期的过程
Bean的生命周期大致可以分为下面五个过程,如下所示:
实例化:这个阶段就是Spring加载XML配置文件,然后通过反射机制创建Bean对象的过程。
依赖注入:实例化完成之后,Spring就会调用Bean对应的setXxx()方法、或者构造方法给相应的属性赋值。
初始化:在Bean实例化完成并且依赖注入之后,就会调用Bean的初始化方法,进行一些额外的处理操作,默认初始化方法我们习惯叫做【init()】。
使用阶段:处于这个阶段的Bean对象,就可以真正的被使用啦。
销毁阶段:当某个Bean对象不再被使用时候,此时会首先调用销毁方法(默认销毁方法我们习惯叫做【destory()】),用于释放一些系统资源,然后将Bean对象进行垃圾回收。

(1)实例化阶段
当我们启动Spring工程的时候,此时Spring会加载XML配配置文件,读取里面的bean标签相关配置信息,查找需要被实例化的Bean信息,然后通过Java中的反射机制,创建相应的Bean实例对象。
到此,bean的实例化就结束了。Spring框架中Bean的实例化过程采用了工厂模式,通过统一的Bean工厂创建对应的Bean对象。
(2)依赖注入阶段
通过前几篇文章,我们知道了什么是依赖注入,当我们在XML配置文件里面,通过【property】标签或者【constructor-arg】标签,判断是否需要进行依赖注入。
如果有配置依赖注入,则Spring框架会调用对应的【setXxx()】或者【构造方法】进行属性赋值操作,这个过程我们叫做:依赖注入阶段。
下面看个测试案例:
创建【User】测试类
public class User {
private Integer uid;
private String username;
public User() {
System.out.println("1、实例化阶段");
}
public Integer getUid() {
return uid;
}
public void setUid(Integer uid) {
this.uid = uid;
System.out.println("2、依赖注入阶段,uid赋值");
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
System.out.println("2、依赖注入阶段,username赋值");
}
}添加XML配置
编写测试类
public class Test {
public static void main(String[] args) {
// 1、获取 ApplicationContext 容器
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("spring.xml");
// 2、获取 Bean 对象
User user = context.getBean("user", User.class);
System.out.println("4、Bean使用阶段");
}
}运行测试程序,可以在控制台看到如下输出结果。

为什么没有步骤3呢???因为步骤3是初始化阶段,我们没有显式指定【init()】方法,所以没有输出语句。下面介绍初始化阶段。
(3)初始化阶段
初始化阶段,这个阶段可以额外的对Bean做一些处理,例如:加载一些资源,初始化需要使用的数据等等。一般情况下,Bean的初始化方法是【init()】方法,我们只需要在对应的Bean里面声明一个【init()】方法,然后在XML配置文件里面指定初始化方法名称。
声明初始化【init()】方法
在前面的【User】类里面,新增一个【init()】方法,如下所示:
public void init() {
System.out.println("3、执行初始化操作");
}
XML配置文件中指定【init-method】属性值
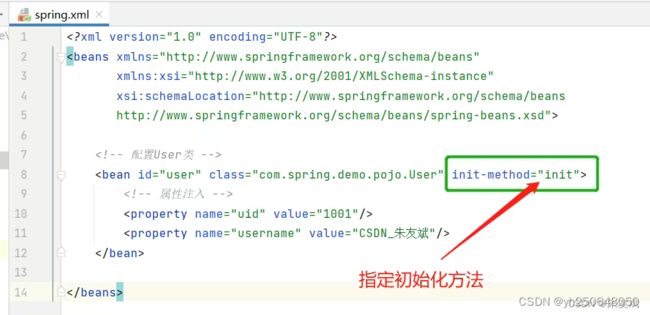
再次运行测试程序,查看控制台结果

以上,就是初始化方法的定义,我们习惯上将初始化方法叫做【init()】,当然你也可以随便起个方法名称,只需要通过【init-method】属性指定。
(4)使用阶段
处于使用阶段的Bean对象,就能够真正的用于处理一些业务逻辑,完成特定的业务需求,这个阶段没有什么可以介绍的。
(5)销毁阶段
当我们的Bean对象不再需要使用后,垃圾回收器就会开始回收Bean对象,再回收之前就会调用Bean对象的销毁方法,一般情况下,销毁方法名称叫做【destory()】,在销毁方法里面,可以用于释放一些资源。通过在XML配置文件里面指定【destory-method】属性声明销毁方法。
定义销毁【destory()】方法
在【User】类里面定义一个【destory()】方法。
public void destory() {
System.out.println("5、执行销毁操作");
}XML配置【destory-method】属性

测试程序,关闭Spring容器来模拟Bean被销毁的情况
public class Test {
public static void main(String[] args) {
// 1、获取 ApplicationContext 容器
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("spring.xml");
// 2、获取 Bean 对象
User user = context.getBean("user", User.class);
System.out.println("4、Bean使用阶段");
// 关闭容器: 这里通过关闭容器来模拟Bean被销毁的操作
context.close();
}
}运行测试程序,查看控制台输出情况。

以上,就是Bean的生命周期基本的五个过程,其实在Bean的初始化前后我们还可以通过Bean的后置处理器,添加一些额外的功能,下面介绍以下Bean的后置处理器。
二、Bean的后置处理器
2.1、如何使用Bean的后置处理器
后置处理器,是指:我们可以在Bean调用初始化【init()】方法之前或者之后,执行我们指定的一些代码逻辑。
Spring框架中给我们提供了后置处理器接口【BeanPostProcessor】,这个接口中定义两个方法,分别是:
postProcessBeforeInitialization:这个方法在调用【init()】方法之前执行。
postProcessAfterInitialization:这个方法在调用【init()】方法之后执行。
我们可以自定义一个类,然后实现后置处理器接口,重写其中两个方法,然后可以在对应的方法里面进行一些额外的逻辑处理。下面看个案例:
创建【CustomProcess】后置处理器
public class CustomProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("在init()之前,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("在init()之后,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
}XML配置后置处理器
运行测试程序,查看控制台输出结果

以上就是Bean的后置处理器最基础的使用,这个后置处理器是会对所有的Bean的生命周期有效的,也就是说,定义了一个后置处理器,那么所有的Bean在初始化前后都会执行后置处理器。
后置处理器也可以定义多个,这里就有一个问题了,多个后置处理器它们的执行顺序是怎样的呢???下面介绍一下多个后置处理器的执行顺序。
2.2、后置处理器执行顺序
当我们在程序中定义了多个后置处理器时,它们的执行顺序可以分为两种情况,分别如下:
第一种情况:不指定执行顺序,按照配置的先后顺序执行。
第二种情况:手动指定先后执行顺序。
(1)第一种情况:采用默认配置顺序
如果我们有多个后置处理器,那么默认情况下,这些后置处理器是按照在XML配置文件里面的
举个栗子看看默认的执行顺序:
创建【CustomProcessor1】后置处理器
public class CustomProcessor1 implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessor1: 在init()之前,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessor1: 在init()之后,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
}创建【CustomProcessor2】后置处理器
public class CustomProcessor2 implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessor2: 在init()之前,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessor2: 在init()之后,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
}创建【CustomProcessor3】后置处理器
public class CustomProcessor3 implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessor3: 在init()之前,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessor3: 在init()之后,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
}XML配置三个后置处理器
上面是按照【1,2,3】的顺序配置的,那么程序执行时候,也是按照【1,2,3】顺序执行的后置处理器,运行测试程序【Test02】,查看控制台输出结果。

这个时候,为了验证默认情况下,后置处理器是按照XML配置顺序执行的,我们可以调整一下XML配置的先后顺序,这里我将顺序调整为【1,3,2】,然后再次运行测试程序,查看结果。

有时候,我们不想按照默认的配置顺序,而是需要自己指定哪个后置处理器先执行,哪个后执行,这个时候就需要手动设置执行顺序,下面介绍如何手动设置先后执行顺序。
(2)第二种情况:手动指定顺序
要实现后置处理器按照指定顺序执行,那么每个后置处理器需要实现【Ordered】接口,然后重写其中的【getOrder()】方法,这个【getOrder()】方法有什么作用呢???
【getOrder()】作用】:
这个方法返回一个【int】类型数字,这个数字就是表示后置处理器的先后执行顺序。
默认返回值是【0】。
返回的数字越大,那么优先级越低,也就是执行顺序越低。
创建【CustomProcessorOrder01】后置处理器
public class CustomProcessorOrder01 implements BeanPostProcessor, Ordered {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessorOrder01: 在init()之前,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessorOrder01: 在init()之后,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
@Override
public int getOrder() {
return 10; // 这里设置为10
}
}创建【CustomProcessorOrder02】后置处理器
public class CustomProcessorOrder02 implements BeanPostProcessor, Ordered {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessorOrder02: 在init()之前,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("CustomProcessorOrder02: 在init()之后,执行Bean的后置处理器, 当前bean的名称: " + beanName);
return bean;
}
@Override
public int getOrder() {
return 5; // 这里设置为5
}
}XML配置两个后置处理器
运行测试程序【Test03】,查看控制台输出结果。

从控制台的输出结果,我们可以看到,虽然我们在XML配置文件里面是按照【01,02】两个顺序配置的,但是测试程序输出结果是按照【02,01】执行的,这是因为我们重写了【getOrder()】方法,然后【CustomProcessorOrder01】类中返回是【10】,【CustomProcessorOrder02】类中返回是【5】,返回值越小,越先执行,所以最终结果按照【02,01】执行。