漫谈C语言内存管理
更多博文,请看音视频系统学习的浪漫马车之总目录
C内存与指针:
漫谈C语言内存管理
漫谈C语言指针(一)
漫谈C语言指针(二)
漫谈C语言指针(三)
C语言简介
要学习音视频开发,首先C、C++是必备的编程语言,因为很多知名的音视频库,比如FFMPEG、X264等都是用C语言编写的,而我们要使用这些库就必须用C、C++去开发程序。
C语言是一门怎样的语言呢?C语言是一门面向过程的编译型语言,它的运行速度极快,仅次于汇编语言。C语言是计算机产业的核心语言,操作系统、硬件驱动、关键组件、数据库等都离不开C语言;不学习C语言,就不能了解计算机底层。后来的很多语言(C++、Java等)都参考了C语言,说C语言是现代编程语言的开山鼻祖毫不夸张,它改变了编程世界。
以下是C语言几个特性:
1.高效性:c语言是一种高效的语言。c表现出通常只有汇编语言才具有的精细的控制能力(汇编语言是特定cpu设计所采用的一组内部制定的助记符。不同的cpu类型使用不同的汇编语言)。如果愿意,您可以细调程序以获得最大的速度或最大的内存使用率。
2.可移植性:c语言是一种可移植的语言。意味着,在一个系统上编写的c程序经过很少改动或不经过修改就可以在其他的系统上运行。
3.强大的功能和灵活性:c强大而又灵活。比如强大灵活的UNIX操作系统便是用c编写的。其他的语言(Perl、Python、BASIC、Pascal)的许多编译器和解释器也都是用c编写的,包括大家熟悉的JVM也是C语言写的。
当然C语言的内容非常庞大,博文是讲不完的,也没必要全面去讲,毕竟该系列是讲音视频的,而且读者应该是有C语言基础(至少其他语言基础),所以这里只会讲到C语言的一些重点难点,一些比较本质的东西。
变量的本质
相信变量大家都很熟悉了,但是关于变量本质是什么,可能不一定每个人都仔细思考过。
首先谈下执行程序的本质是什么。程序就是通过一系列的算法和数据结构,对数据进行的操作处理,那被操作的数据在哪里呢,在内存里,那么写程序的时候就要指定我现在要操作那一块内存的数据,那这块数据要怎么在程序中表示呢?直接用它的内存地址?那实在太不方便了吧,于是程序设计者就用变量名去指代内存中的某个数据,具体来讲,变量就是一段连续内存空间的别名,程序通过变量来申请和命名内存空间, 通过变量名访问内存空间。不是向变量名读写数据,而是向变量所代表的内存空间中读写数据
大家都知道定义变量一定有数据类型的,那么变量的类型是什么呢?
刚才说到变量就是一段连续内存空间的别名,那么具体给一个变量分配多大的空间呢?就比如给动物造窝,造小了动物住不下,造大了浪费空间,狗窝不能给大象住,象窝给小狗住实在是浪费,而且,不指定内存大小,计算机读取数据的时候就不知道要读取的范围有多大。所以,需要通过数据类型来指定分配的内存大小,也可以说,数据类型是固定大小内存的别名。
当然只是指定内存大小是不够的,还需要指定放在内存中的数据是表示什么样的东西,具体是表示猫还是狗还是大象,仅仅知道身高和尺寸并不知道具体的动物,因为数据在内存中都是以2进制存储的,所以需要用不同的表示方式(类似协议)表示不同的数据类型,顾名思义数据类型还区分了数据的类型,比如数据是字符还是整数还是小数。所以通过数据类型,让 计算机知道以什么方式去读取变量的值。
内存管理
程序是在内存中运行的,因为c语言的特性,所以它比任何一门编程语言都贴近内存,而掌握了它的内存管理机制,也是学习好C语言的重中之重,很多其他问题也可以通过内存分析推导使其得到迎刃而解。
内存模型
我们知道应用程序启动后就会加载到内存中取执行,这时候cpu从内存中取出数据和指令去执行,我们将程序内存在地址空间中的分布情况称为内存模型(Memory Model),那C语言的程序在内存模型是怎样的呢?内存模型由操作系统决定,以下以C语言程序在Linux32位系统的内存模型为例:
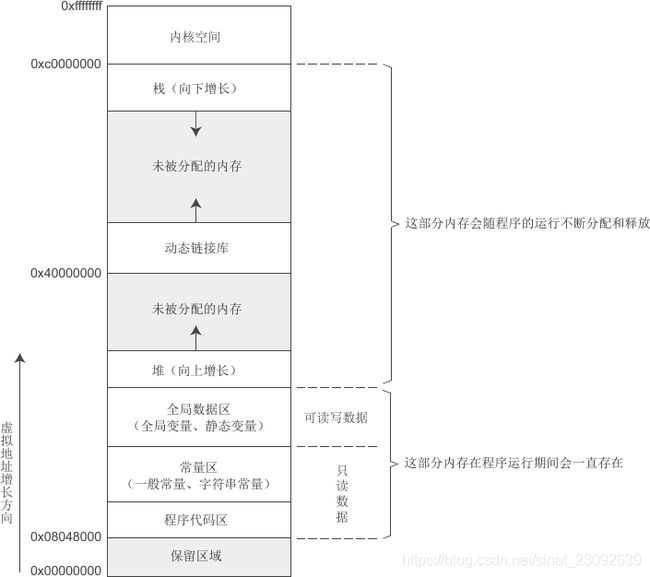
上图已经清晰地将内存模型从地地址到高地址各个分区表示出来了,下面看下各个主要分区的描述:

总体来讲说,程序源代码被编译之后主要分成两种段:程序指令和程序数据。代码区属于存放程序指令,常量区、全局数据区、堆区、栈区属于存放程序数据。程序代码区、常量区、全局数据区在程序加载到内存后就分配好了,并且在程序运行期间一直存在,大小固定,只能等到程序运行结束后由操作系统收回。栈区、堆区在程序运行时动态开辟。
那为什么把程序的指令和程序数据分开呢?
程序被load到内存中之后,可以将数据和代码分别映射到两个内存区域。由于数据区域对进程来说是可读可写的,而指令区域对程序来讲说是只读的,所以分区之后呢,可以将程序指令区域和数据区域分别设置成可读可写或只读。这样可以防止程序的指令有意或者无意被修改。
当系统中运行着多个同样的程序的时候,这些程序执行的指令都是一样的,所以只需要内存中保存一份程序的指令就可以了,然后这些程序就可以共享这一份代码指令了,只是每一个程序运行中数据不一样而已,这样可以节省大量的内存。
以下详细分析这几个主要的分区:
全局数据区
存储定义在函数外部的变量,可以被全局(其他文件)访问到。
常量区
存储字符串常量和const修饰的变量。
栈
栈由系统进行内存的管,数据结构就是我们熟悉的栈结构(先进后出)。主要存放函数的参数以及局部变量。在函数完成执行,系统自行释放栈区内存,不需要编程人员管理。函数被调用时,会将参数、局部变量、返回地址、保存的上下文等与函数相关的信息压入栈中,函数执行结束后,这些信息都将被销毁。所以局部变量、参数只在当前函数中有效(函数中使用参数本质也是在函数栈中创建一块内存把参数拷贝过来),不能传递到函数外部,因为它们的内存不在了。另外栈属于线程私有。
从上图“C语言程序在Linux32位系统的内存模型”可以看出,栈是从高地址往下增长的。
函数调用时栈内存的分布情况如下图,可见函数本身开辟一个栈,函数栈之间也是通过类似栈的结构组织的。图中ebp指针指向当前调用函数的栈底,esp指针指向调用函数的栈顶,当前函数栈增加内存空间只要移动esp即可。这里每个函数栈都会保存自己的栈底指针,以在下一个函数栈被回收之后,ebp可以指到自己函数栈的栈底,以便恢复现场。(同编译器在不同编译模式下所产生的函数栈并不完全相同)

实际上,程序启动时会为栈区分配一块大小适当的内存,对于一般的函数调用这已经足够了,函数进栈出栈只是 ebp、esp 寄存器指向的变换,或者是向已有的内存中写入数据,不涉及内存的分配和释放。我们经常听说“栈内存的分配效率要高于堆”就是这个道理,因为大部分情况下并没有真的分配栈内存,仅仅是对已有内存的操作。
堆
堆由编程人员手动申请,手动释放,若不手动释放,程序结束后由系统回收,生命周期是整个程序运行期间。更重要的是堆是一个大容器,它的容量要远远大于栈,这可以解决内存溢出困难。使用malloc或者new进行堆的申请。堆完全由程序员掌控(也是唯一由程序员完全控制的内存区域),想分配多少就分配多少,想什么时候释放就什么时候释放,非常灵活,但是也引入了内存泄漏问题。堆虽说操作灵活,但是分配效率比栈要低。
具体代码实例说明
#include 代码说明函数栈分配的内存会在函数执行后释放:
char* testStack(){
char p[] = "hello world!"; //字符串在栈区存储
printf("in testStack %s\n", p);
return p;
}
int main() {
char* p = NULL;
p = testStack();
printf("out of testStack %s\n",p); //返回的是函数中的字符串的地址
return 0;
}
运行结果:
in testStack hello world!
out of testStack (null)
null说明指向的内存已经在函数执行完之后释放了。
但是将字符串用指针指向:
char* testStack(){
char *p = "hello world!"; //在常量区存储
printf("in testStack %s\n", p);
return p;
}
运行结果:
in testStack hello world!
out of testStack hello world!
可见函数执行结果后内存并没有释放,印证了字符指针指向的字符串创是存储在常量区。
证明栈的增长是往下(低地址方向):
void testStack1(){
int a = 10;
int b = 20;
int c = 30;
int d = 40;
printf("a = %d\n", &a);
printf("b = %d\n", &b);
printf("c = %d\n", &c);
printf("d = %d\n", &d);
}
运行结果:
a = 6421996
b = 6421992
c = 6421988
d = 6421984
可以看到地址逐步减少,即栈的增长是从高往低地址方向走的。
证明堆的变量在没有手动释放前不会被释放:
int *get()
{
int *p = (int *)malloc(sizeof(int));//申请了一个堆空间
*p = 10;
return p;
}
int main(){
int *x = get();
printf("x: %d\n", *x);
}
运行结果:
x: 10
get函数执行返回的值为里面指针p的值,即malloc开辟的内存空间,函数执行完毕之后,对指针x取值依然可以拿到正确的值,说明函数调用之后,那块内存没有被回收。
如果在p返回之前free:
int *get()
{
int *p = (int *)malloc(sizeof(int));//申请了一个堆空间
*p = 10;
free(p);
return p;
}
运行结果:
x: 38870160
此时返回的指针成了野指针,指向的内存已经被释放,变成了随机值。
证明static变量是全局的:
全局static就不需要证明了,看下static局部变量的情况:
int testStatic() {
static int s = 0;
s = s + 1;
return s;
}
int main() {
for (int i = 0;i<=10;i++){
int a = testStatic();
printf("a = %d\n", a);
}
}
运行结果:
a = 1
a = 2
a = 3
a = 4
a = 5
a = 6
a = 7
a = 8
a = 9
a = 10
a = 11
说明s是有叠加的,说明testStatic函数执行完后,里面的static变量s并没有被释放,所以即使是局部变量,static变量也是存储在全局变量区的。
内存对齐
CPU 通过地址总线来访问内存,一般多少位cpu一次能取到的数据就是多少位的,所以32位cpu一次可以处理4个字节的数据,那么每次就从内存读取4个字节的数据,而单位时间内读取的次数叫做主频。为了做到最快的寻址,即一次获取的数据尽量多,并且不要重复,cpu寻址采用了步长进行寻址,并且只对编号为一定数据量的倍数的内存寻址(不一定严格为4倍数,假如最起始的地址不是0)。比如32位cpu的寻址步长为4个字节,即每次只对编号为 4 的倍数的内存开始进行寻址,例如只对0、4、8、12…1000的地址为开始进行寻址 :

所以对于程序来说,一个变量最好位于一个寻址步长的范围内,这样一次就可以读取到变量的值;如果跨步长存储,就需要读取两次,然后再拼接数据,效率显然降低了。
将一个数据尽量放在一个步长之内,避免跨步长存储,这称为内存对齐。
比如一个int类型数据(以4个字节为例),如果首地址为0,则32位cpu一次读取4个字节就可以读完该数据。但如果首地址为6,则32位cpu需要第一次从内存地址4开始读取4个字节,第二次从内存地址8读取4个字节,然后分别取第一次读取的后2个字节和第二次读取的前2个字节进行拼接。这就很明显看出跨步长存储对读取效率的影响了。
所以**编译器会自动将一个数据尽量放在一个步长之内,避免跨步长存储,这称为内存对齐。**对齐位数取决于编译模式,在32位编译模式下,默认以4字节对齐;在64位编译模式下,默认以8字节对齐。
以下用代码证明内存对齐(用结构体证明最好不过):
(注:sizeof返回的占用空间大小是为这个变量开辟的大小,而不只是它用到的空间。所以会包含对齐的内存部分)
struct {
int a;
char b;
double c;
} t = {10, 'C', 20.1};
int main() {
//先打印出当前环境每种类型的大小
printf("int length: %d\n", sizeof(int));
printf("char length: %d\n", sizeof(char));
printf("double length: %d\n", sizeof(double));
//打印出结构体的大小
printf("struct length: %d\n", sizeof(t));
printf("&a: %X\n&b: %X\n&c: %X\n", &t.a, &t.b, &t.c);
return 0;
}
运行结果:
int length: 4
char length: 1
double length: 8
struct length: 16
&a: 408010
&b: 408014
&c: 408018
从前三行可以看出当前是32位编译模式,所以寻址步长为4。所以如果结构体t中的a、b、c属性是没有内存对齐的话,则t的占用空间大小应该为4+1+8=13,但是打印出来的是16,再看下结构体t中的a、b、c的起始地址,然后注意到c是从地址408018开始存储的,而b是从408014开始存储的,而b为char类型本来是1个字节,如果没有对齐的话c的起始地址应该是408015,因为当前的步长内已经容不下c了,所以b的后面做了内存对齐,补上了3个字节,让c从下一个步长开始存储。
假如把结构体改为:
struct {
char a;
short b;
int c;
} t = {'C', 10, 20};
运行结果:
char length: 1
short length: 2
int length: 4
struct length: 8
&a: 408010
&b: 408012
&c: 408014
注意到因为在存储了a之后,当前步长还能容纳下b,所以b还在当前的步长中,不过这里因为存储了b之后,当前步长只剩下一个字节,所以放不下c,所以补了一个字节(看地址输出,是补在a后面了)
而如果结构体改为以下,则不需要内存对齐,因为2个short类型属性刚好满一个步长,而后面的int也刚好满一个步长:
struct {
short a;
short b;
int c;
} t = {1, 10, 20};
运行结果:
short length: 2
int length: 4
struct length: 8
&a: 408010
&b: 408012
&c: 408014
结果也印证了上面的说法。
下一篇:漫谈C语言指针(一)