大模型上车:先打广告,再看疗效

来源 |远川汽车评论
作者 | 熊宇翔
在今年ChatGPT火爆全球后,大模型成为AI显学,一度号称“所有行业都值得用大模型重做一遍”。
汽车行业热烈响应号召,李想也在微博热情布道,“大模型的研发和训练是智能电动车企业的必要能力。”
一场大模型(口头)军备竞赛迅速席卷行业。前脚某华东车企发布了“全球首个汽车行业全场景大模型”,后脚某华南车企就推出“汽车行业首创大模型平台”。智驾领域更甚,CEO与项目Leader们言必称“大模型”,不管这个模型有多大, 到底用在哪。
大模型尤其是自动驾驶大模型概念的无序扩张,引发了一些技术大佬的警惕。
图森未来CTO王乃岩日前呛声“自动驾驶大模型是伪命题”,他认为大模型最重要的特点是能摆脱场景限制的强泛化能力,但“任何所谓的自动驾驶大模型都还没达成这样的能力”[1]。
拿下今年计算机视觉顶会CVPR最佳论文奖的UniAD论文作者、上海人工智能实验室科学家李弘扬也认为,“现在这个行业没有自动驾驶大模型。我们给UniAD工作的定义也是‘自动驾驶通用模型’,而不是大模型。[2]”
略显喜感的是,与UniAD相关的几家机构在宣传口径上都将之称为大模型。
在汽车与AI交汇更深入的2023年,一边是工程师沦陷在如何把大模型嫁接到车上的工程地狱里,另一边,则是吃瓜群众快要迷失在“车企喜迎大模型上车”的漫天广告里。
自动驾驶“大模型”,不是真的大模型
一个不那么众所周知的事实是,如今自动驾驶的大模型,虽然和ChatGPT一样使用Transformer作为底层技术,但两者并不是一种大模型。
甚至于,跟AIGC大模型比起来,自动驾驶大模型的“大模型”户籍,都显得有些可疑。
AI行业习惯用参数规模来定义大模型。AIGC大模型的参数量大多在数百亿到数千亿量级,ChatGPT是1750亿;自动驾驶模型的参数规模,则还在十亿量级努力。一般认为,让这一轮AI表现惊艳的“涌现”能力,在参数量百亿以上的模型中才会出现。
由于自动驾驶对实时性、可靠性更严苛的要求,ChatGPT们那套依靠云端海量算力进行推理的架构行不通,智能驾驶汽车能依仗的,只有车载智驾芯片。由于成本、功耗限制,车载芯片的性能与云端相差甚远,难以承载千亿级参数的大模型。
以特斯拉去年的FSD V11版本为例,它有基础感知网络、车道线网络(Lanes Network)、占用网络(OccpuancyNetwork)、混合规划网络等几个较小的神经网络接合,参数规模在10亿量级,运行在算力144T的FSD芯片上。
自动驾驶模型是有变大的诉求,但主要矛盾在于车端芯片性能不足——不足不仅仅在算力,更在存储与带宽。为了给更大的模型做好准备,特斯拉在HW4.0上不仅提升了FSD芯片的算力,也为其配置了GDDRX6内存,带宽提升至HW3.0的3倍+[3]。
当然,在帮助自动驾驶模型变大、能力进化的过程中,云端算力依然至关重要。
当前,在云端预训练一个大模型,利用它来进行数据自动标注、场景挖掘是头部车企与智驾供应商的主流做法。此外,大模型能够生成更高质量的仿真效果,长城AI大模型负责人杨继峰的观点是,“高精度的三维重建仿真,是当下自动驾驶开发中大模型在云端能做的最确切工作”。
理论上,企业也可以在云端训练一个参数量较大的模型,然后通过蒸馏、剪枝、量化等操作,缩小模型的规模,再把它塞到车内。
比如毫末智行的DriveGPT,采用了类GPT的结构,在云端拥有1200亿参数。不过,要将1200亿参数的模型压缩到能塞进车内,显然当下的芯片性能还不足以支持。而如何实现模型的轻量化但又不影响精度,也将是各家秘而不宣的核心know-how。
总之,因为大模型的概念本身在不断变动、泛化,当一家公司说在做自动驾驶大模型时,实际上可能包含(但不限于)三种含义:
-
他们基于Transformer搭建BEV(鸟瞰视角)感知模型,做出了一个参数量比原本基于CNN更大的智驾模型(但很可能参数还不到亿);
-
他们从AIGC大模型的工程实践中获得了启发,开发了弱监督学习方法、引入了HFRL人类反馈强化学习(但实际上ChatGPT彻底带火大模型之前,自动驾驶行业已经在推进这些工作);
-
他们在云端做了参数量很大的模型,能够将其作为基础设施,加速、优化自动驾驶的开发(但并不能直接部署在车端,也不能指望车辆的自动驾驶能力在短时间内突飞猛进)。
无论哪一种,都与“大模型即将带来自动驾驶的iPhone时刻”这类狂热判断有不小差距。
但很大程度上,智驾行业是一个格外符合“因为相信,所以看见”的前沿行业,无论是想吸引投资人的真金白银,还是让消费者慷慨解囊,又或者是出于吸纳人才的目的,其中的企业多少都有“先把广告打响,再把牛X圆上”的冲动。
个中翘楚,自然是令人又爱又恨的画饼惯犯,特斯拉。
端到端模型:更强、更贵、更难管
当一批企业仍在模模糊糊地高举大模型大旗时,特斯拉已然更新了版本,开启对消费者心智的新一轮占领。
两周前,马斯克以“找小扎1V1男人大战”为由,亲自驾车直播了尚在开发中的特斯拉智能驾驶功能FSD V12版本,超过1100万人在推特上观看。回想马斯克的行为,他在推特上的漫长预热,更像是假约架,为FSD V12真引流——直播中,马斯克根本没有让车在柔道蓝带选手扎克伯格的家附近停留。
相较于目前的FSD V11.4,V12最大的特性是基本实现了“神经网络吞噬一切”。在马斯克口中,FSD V11.4还有30万行人类手写的代码,但FSD V12几乎完全是神经网络,构筑了一套端到端自动驾驶技术。

和参数规模庞大一样,端到端也是ChatGPT等大模型的重要特征:用户输入Prompt提示词,ChatGPT直接输出结果,而不会把它的每一步“思考”过程都展现出来。尽管模型是一个黑箱,没人知道里面到底发生了什么,但最后呈现的结果是,ChatGPT的回答表现得很像人。
端到端同样是自动驾驶试图追逐的方向,但行业主流的自动驾驶算法由多个分立的上下游模块拼接而成,每个模块的成分不同(比如目前感知模块主要是深度神经网络,规划模块主要是人工设定的规则),目标不一致,各个模块自身的局限将不断累加并传递到下游,最终导致难以获得理想的效果。
这很像经典的传话游戏。同样的话,在经过多人传递后,往往会出现信息失真。
端到端自动驾驶,则是将算法悉数神经网络化,并用一个统一的大模型替代分立模块,感知数据被输入进统一的神经网络后,将直接输出对车辆的控制信号。由于没有“中间人”卡信息,端到端的自动驾驶相比于传统的多模块算法有更高的理论上限,更容易获得全局最优解。
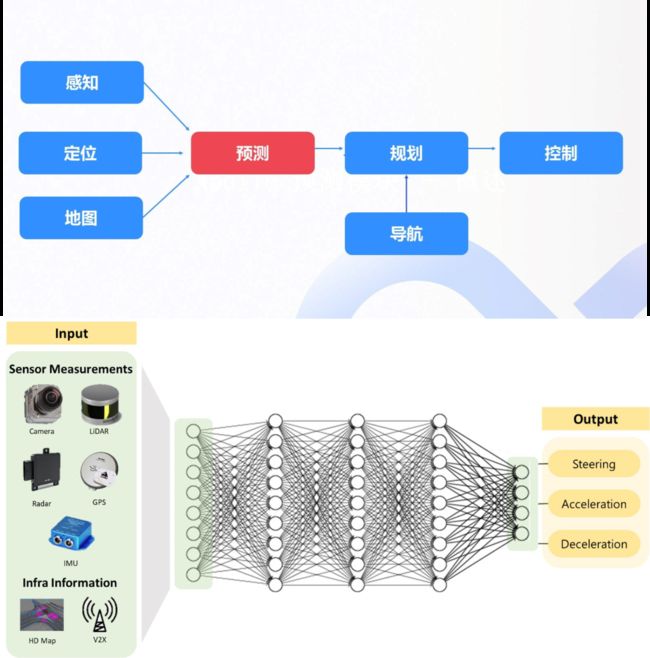
多任务模块自动驾驶VS端到端自动驾驶,图片来自百度Apollo,AVE Lab
这在马斯克的直播中有一个具体的体现:在一个十字路口观察到前方拥堵后,即使是绿灯亮起,马斯克乘坐的特斯拉仍放弃了通行,从而避免了堵在十字路口挡路的尴尬。这是一个很类人的操作。
不过,更高上限的代价是更高昂的成本。马斯克预计特斯拉采用端到端自动驾驶技术栈,今年仅用于训练的成本就将达到20亿美元,让这份作业格外难抄。
从公开的信息来看,蔚小理、华为的高阶智驾算法框架仍是多模块式,包含基于Transformer的BEV,Ocuupancy Network(或者功能相似的网络模块),以及同时基于深度学习与规则的混合规划决策模型等[4],大致相当于FSD在去年AI Day之后的阶段。
其实,特斯拉的新作业,国内新势力也未必想抄。因为在实际驾乘体验中,端到端自动驾驶算法在当下的表现并不一定就比模块式的自动驾驶表现更强。
在FSD V12的直播进行到第19分钟时,直行等待红灯转绿的特斯拉,在左转灯变绿时擅自冲了出去,被马斯克紧急接管,一脚刹停。在被问及解决方案时,马斯克的回应是“继续向神经网络投喂大量带有左转交通灯的驾驶视频。”
这也是端到端自动驾驶被诟病的固有缺陷:缺乏可解释性。由于算法的运作是隐式且一体化的,智驾团队很难对问题精确溯源,从而作出针对性的优化,只能依靠喂养更多数据,大力出奇迹。
类似的问题在大语言模型上也存在,比如ChatGPT至今没能改掉胡编乱造的“幻觉”问题。为了让ChatGPT的输出符合现实、符合人类的价值观,OpenAI花了大力气来进行“对齐”。而端到端自动驾驶,错误输出的后果显然比ChatGPT更加严重。
端到端自动驾驶运作方式的不可知与出错后果更严重的特征,将比生成式大模型更加挑战监管部门敏感的神经。同济大学教授、汽车安全专家朱西产在一场行业活动上吐槽,“光是感知使用神经网络,就产生了预期功能安全问题,端到端自动驾驶全部使用神经网络,那就没法测试、认证了”。
前文提到的UniAD自动驾驶通用模型试图解决这一问题,UniAD虽然是端到端模型,但也会同时输出人类能够理解的中间结果,使得溯源、优化与监管能够可视化。不过,这类方法的落地还处在早期阶段。
而特斯拉的FSD V12,目前也还仅仅是马斯克测试特供版。在FSD V12正式推送之前,人们大概还要看很多次马斯克的直播。
真·大模型上车,从语音助手开始
在2023年,汽车行业与AI的主要矛盾,正在逐渐靠向车企日益增长的大模型赋能需求与大模型能力发展不平衡不充分之间的矛盾。
好在,汽车的智能化不仅是智能驾驶,也包含智能座舱,这为车企们找到了另一条追逐大模型的道路:将生成式大模型用在汽车座舱中,让座舱变得更加智能。
今年2月,尚在内测阶段中的文心一言,即收获了吉利、长城、红旗、东风日产、岚图等车企合作伙伴。6月,奔驰宣布将为90万辆车的车载语音助手接入ChatGPT的能力——在智能座舱体验屡遭吐槽后,德国人终于抢跑了一个回合[4]。
而在上周,11家通过《生成式人工智能服务管理暂行办法》备案的大模型获批上线,也打通了国产AIGC大模型上车的道路。加上尚未上线的、车企自研的,一场汽车智能座舱里的大模型征战,即将在今年第四季度打响。
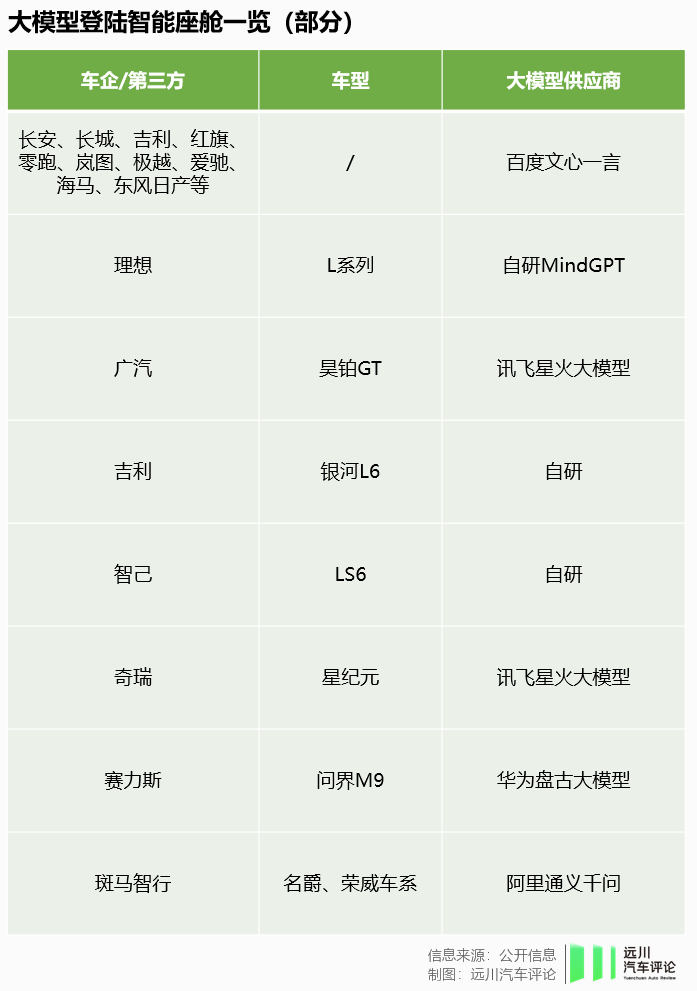
由于车企对AIGC类大模型所需的数据掌握较少,且算力储备不够,因而大多选择与大模型提供方合作,自研派较少。
指望在智能座舱市场掘金的大模型公司,也充分放飞想象力,不仅为车企提供聊天机器人,还试图将大模型的文图互生、健康监测、文档解读等能力搬上车。恍然间,车上托儿、车上看诊、车上办公指日可待,一些急需卖点的车企也甘之如饴。
实际上,座舱能否因大模型加持变得更智能,不仅要看大模型的能力,车企自身的能力同样重要。
这是因为,原生的大模型在车载场景往往还不够好用或者不能满足车企的差异化需求,需要车企自行喂养数据对大模型进行微调,对功能二次开发。即使使用同一个大模型,不同车企由于积累的数据与对场景的理解不同,以及具体车型电子电气架构不同,最终呈现出的效果也会有明显差别。
平心而论,大模型进驻智能座舱,当前最显著的作用还是提升智能汽车语音交互的能力,让它能更好地胜任交互中枢的角色。
目前绝大部分汽车都配置了智能语音助手,但即使是能力较强的那一批,仍然存在几个主要问题:
-
人和语音助手的交互依然略显机械,不是人类最习惯的自然语言交互形式;
-
聊闲天强,干实事(技能)弱;
-
技能局限于对车辆自身硬件与元素的调用。
而在大语言模型加持下,语音助手可以更精确地听懂人类对话的含义,拉起链路更复杂的任务,更准确地执行人类希望的操作。目前来看,这是国产智能汽车对特斯拉胜率最大的战场。
在此基础上,车企与大模型供应商在竭力推动的另一项工作是,将多模态感知大模型(注:实际上这个模型不算大)与大语言模型整合起来,让汽车的智能座舱同时建立起感知与认知能力,看懂车内人员的表情、手势,进而更深层次地理解人类更日常或者隐晦的表达。
比如,当司机用手抹了抹额头上的汗珠,喃喃自语好热时,语音助手会适时蹦出来,问一句是否要为你调低空调。
车联网公司与车企们讲了十余年的“让车更懂你”,也终于在大模型加持下,即将看到阶段性胜利的曙光——当然,这一切的前提仍然是,在汽车智能座舱中,工程学跑赢了广告学。
参考资料:
[1] 图森中国CTO王乃岩:长尾问题只是庸人自扰,首席智行官
[2] 青年科学家李弘扬:行业大模型会推动自动驾驶更快更好迈向L4,首席智行官
[3] 二代FSD也有算力焦虑?特斯拉不惜血本用上GDDR6,机器之心
[4] 奔驰联手微软,率先将ChatGPT接入车载语音助手,福布斯中国
来源:https://m.huxiu.com/article/2026442.html?type=text&visit_source=share_from_app&f=app_android_friends