Centos7-部署基于cri-o的K8S集群
- 环境资源:
| 操作系统 | 主机名称 | IP地址 |
|---|---|---|
| centos7 | crio-master | 10.0.2.120 |
| centos7 | crio-node1 | 10.0.2.121 |
- 初始配置:(master和node都得执行)
1) 关闭swap ,关闭selinux,关闭firewalld:
swapoff -a
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
2 ) 在 Github 中下载 CRI-O 的二进制压缩包:https://storage.googleapis.com/k8s-conform-cri-o/artifacts/crio-v1.19.0.tar.gz
3) cri-o安装部署:
tar -xf crio-v1.19.0.tar.gz
mkdir -p /opt/cni/bin
mkdir -p /usr/local/share/oci-umount/oci-umount.d
mkdir /etc/crio
mkdir -p /usr/local/lib/systemd/system
yum install make -y
make install
执行过程如下:
install -Z -d -m 755 /etc/cni/net.d
install -Z -D -m 755 -t /opt/cni/bin cni-plugins/*
install -Z -D -m 644 -t /etc/cni/net.d contrib/10-crio-bridge.conf
install -Z -D -m 755 -t /usr/local/bin bin/conmon
install -Z -d -m 755 /usr/local/share/bash-completion/completions
install -Z -d -m 755 /usr/local/share/fish/completions
install -Z -d -m 755 /usr/local/share/zsh/site-functions
install -Z -d -m 755 /etc/containers
install -Z -D -m 755 -t /usr/local/bin bin/crio-status
install -Z -D -m 755 -t /usr/local/bin bin/crio
install -Z -D -m 644 -t /etc etc/crictl.yaml
install -Z -D -m 644 -t /usr/local/share/oci-umount/oci-umount.d etc/crio-umount.conf
install -Z -D -m 644 -t /etc/crio etc/crio.conf
install -Z -D -m 644 -t /usr/local/share/man/man5 man/crio.conf.5
install -Z -D -m 644 -t /usr/local/share/man/man5 man/crio.conf.d.5
install -Z -D -m 644 -t /usr/local/share/man/man8 man/crio.8
install -Z -D -m 644 -t /usr/local/share/bash-completion/completions completions/bash/crio
install -Z -D -m 644 -t /usr/local/share/fish/completions completions/fish/crio.fish
install -Z -D -m 644 -t /usr/local/share/zsh/site-functions completions/zsh/_crio
install -Z -D -m 644 -t /etc/containers contrib/policy.json
install -Z -D -m 644 -t /usr/local/lib/systemd/system contrib/crio.service
install -Z -D -m 755 -t /usr/local/bin bin/crictl
install -Z -D -m 755 -t /usr/local/bin bin/pinns
install -Z -D -m 755 -t /usr/local/bin bin/runc
install -Z -D -m 755 -t /usr/local/bin bin/crun
4 ) cri-o的 镜像源配置:
修改:/etc/crio/crio.conf
设置为
pause_image = "registry.aliyuncs.com/google_containers/pause:3.2"
设置为:
registries = ['4v2510z7.mirror.aliyuncs.com:443/library']
5)设置启动服务:
systemctl daemon-reload
systemctl enable --now crio
systemctl start --now crio
systemctl status crio
6 ) cri-o的卸载方法,在解压目录下面执行:
make uninstall
- k8s相关的配置搭建:
1)配置k8s的yum源:(master和node都得执行)
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
2 ) 安装 kubeadm kubelet kubectl组件,版本和cri-o的版本保持一致(master和node都得执行)
yum install kubectl-1.19.0-0.x86_64 -y
yum install -y kubelet-1.19.0-0.x86_64 -y
yum install -y kubeadm-1.19.0-0.x86_64 -y
3)配置文件配置:(master和node都得执行)
systemctl enable kubelet
修改/etc/sysconfig/kubelet的参数配置,指定kubelet通过cri-o来进行启动,非常重要(master和node都得执行)
KUBELET_EXTRA_ARGS="--container-runtime=remote --cgroup-driver=systemd --container-runtime-endpoint='unix:///var/run/crio/crio.sock' --runtime-request-timeout=5m"
加载内核模块
modprobe br_netfilter
在/etc/sysctl.conf文件中进行配置
net.ipv4.ip_forward = 1
vm.swappiness = 0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
执行sysctl -p,让配置文件生效
4) 在master上生成配置文件:
kubeadm config print init-defaults > kubeadm-config.yaml
配置文件修改后内容如下:
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.0.2.120
bindPort: 6443
nodeRegistration:
# criSocket: /var/run/dockershim.sock
criSocket: /var/run/crio/crio.sock
name: cri-2.120
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
#imageRepository: k8s.gcr.io
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.19.0
networking:
dnsDomain: cluster.local
podSubnet: 10.85.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
5) 初始化k8s集群
查看所需镜像列表
kubeadm config images list --config kubeadm.yml
拉取镜像
kubeadm config images pull --config kubeadm.yml
根据配置文件启动kubeadm拉起k8s
--v=6 查看日志级别,一个节点可以忽略该参数 --upload-certs
kubeadm init --config=./kubeadm.yml --upload-certs --v=6
执行完毕后的打印内容:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.0.2.120:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:3db371d75d6029e5527233b9ec8400cdc6826a4cb88d626216432f0943232eba
6 ) 在master执行如下命令,使kubectl命令可用:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
- 查看集群状态(kubectl get node):
[root@cri-2 crio-v1.19.0]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
cri-2.120 Ready master 9m59s v1.19.0
查看kubectl get cs状态(k8s的19版本存在问题,修改配置文件,重启kubelet进行恢复)
[root@cri-2 crio-v1.19.0]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
原因是kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口是0,只需在文件中注释掉即可。
在每个主节点上执行
vim /etc/kubernetes/manifests/kube-scheduler.yaml
# and then comment this line
# - --port=0
重启kubelet
执行完毕后,查看状态:
[root@cri-2 crio-v1.19.0]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
8)将node加入到集群,执行:
kubeadm join 10.0.2.120:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:3db371d75d6029e5527233b9ec8400cdc6826a4cb88d626216432f0943232eba
9)部署flannel网络插件:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
10)部署完毕后的情况查看如下:
[root@cri-2-120 mwt]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
cri-2-121 Ready 4h42m v1.19.0 10.0.2.121 CentOS Linux 7 (Core) 3.10.0-1160.45.1.el7.x86_64 cri-o://1.19.0
cri-2.120 Ready master 4h43m v1.19.0 10.0.2.120 CentOS Linux 7 (Core) 3.10.0-1160.45.1.el7.x86_64 cri-o://1.19.0
[root@cri-2-120 mwt]# kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-6d56c8448f-2pmwz 0/1 CrashLoopBackOff 63 4h43m 10.85.0.2 cri-2.120
coredns-6d56c8448f-45q9w 0/1 CrashLoopBackOff 64 4h43m 10.85.0.3 cri-2.120
etcd-cri-2.120 1/1 Running 0 4h43m 10.0.2.120 cri-2.120
kube-apiserver-cri-2.120 1/1 Running 0 4h43m 10.0.2.120 cri-2.120
kube-controller-manager-cri-2.120 1/1 Running 7 4h42m 10.0.2.120 cri-2.120
kube-flannel-ds-jj9n7 0/1 CrashLoopBackOff 64 4h35m 10.0.2.121 cri-2-121
kube-flannel-ds-xjbnt 0/1 CrashLoopBackOff 58 4h35m 10.0.2.120 cri-2.120
kube-proxy-b2d5b 1/1 Running 0 4h43m 10.0.2.121 cri-2-121
kube-proxy-zb9cc 1/1 Running 0 4h43m 10.0.2.120 cri-2.120
kube-scheduler-cri-2.120 1/1 Running 7 4h42m 10.0.2.120 cri-2.120
[root@cri-2-120 mwt]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql-4qhrw 1/1 Running 0 4h5m 10.85.0.9 cri-2-121
mysql-8hgsf 1/1 Running 0 4h5m 10.85.0.10 cri-2-121
myweb-cr6rd 1/1 Running 0 4h9m 10.85.0.7 cri-2-121
myweb-mb6sg 1/1 Running 0 4h9m 10.85.0.8 cri-2-121
11) flannel 插件报错原因:大概的意思就是说,我pod的ip未进行配置,但是我在部署的时候已经在yml文件指定pod的ip地址,为啥还是说没有地址
[root@cri-2-120 mwt]# kubectl logs kube-flannel-ds-jj9n7 -n kube-system
I1123 13:23:19.362621 1 main.go:520] Determining IP address of default interface
I1123 13:23:19.457117 1 main.go:533] Using interface with name ens192 and address 10.0.2.121
I1123 13:23:19.457155 1 main.go:550] Defaulting external address to interface address (10.0.2.121)
W1123 13:23:19.457188 1 client_config.go:608] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I1123 13:23:19.559039 1 kube.go:116] Waiting 10m0s for node controller to sync
I1123 13:23:19.559097 1 kube.go:299] Starting kube subnet manager
I1123 13:23:20.559212 1 kube.go:123] Node controller sync successful
I1123 13:23:20.559239 1 main.go:254] Created subnet manager: Kubernetes Subnet Manager - cri-2-121
I1123 13:23:20.559264 1 main.go:257] Installing signal handlers
I1123 13:23:20.559400 1 main.go:392] Found network config - Backend type: vxlan
I1123 13:23:20.559490 1 vxlan.go:123] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
E1123 13:23:20.559858 1 main.go:293] Error registering network: failed to acquire lease: node "cri-2-121" pod cidr not assigned
I1123 13:23:20.559984 1 main.go:372] Stopping shutdownHandler...
20211123
按照该方法部署,会存在问题,因为我flannel插件没有部署成功,我不知道原因是什么,但是pod部署后可以正常启动,但是分配的地址为/etc/cni/net.d/10-crio-bridge.conf中配置的地址,这方面的资料真心感觉太少了,也可能是我太菜了,总感觉搜索到的文章都没有一个实际可以使用的,来来回回折腾了快一周,搭建环境,实在是太痛苦了。
20211124 在不断尝试中,我终于找到原因了:
原来所有一切还得从原理上面去进行分析:
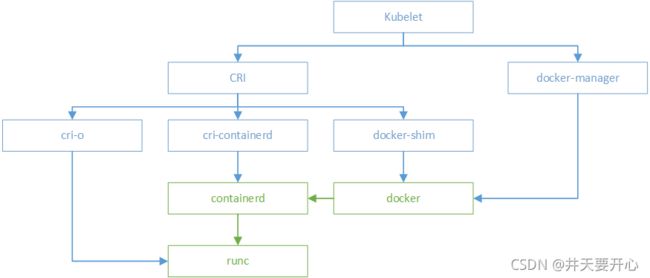
/etc/cni/net.d 这里面的配置文件是指定要使用什么的网络插件来启动网卡,分配哪个网段的ip地址,pod的路由等等信息。
/opt/cni/bin/ 这个存放的是网络插件,比如brige,flannel等
当启动kublet时,会读取/etc/cni/net.d的文件,调用/opt/cni/bin/ 的插件创建相关的网络,并且为启动的pod分配ip地址来进行通信。
我配置flannel失败的原因为:
1. /etc/cni/net.d 中有多个文件有干扰。最后移除所有只留 10-flannel.conflist
2. /opt/cni/bin/目录中,不存在flannel二进制文件,从docker的环境下拷贝过来。
3. 配置的kubeadm-config文件 podSubnet: 10.85.0.0/16 字段名称写错了。
搭建环境查看的文章链接:
https://xujiyou.work/%E4%BA%91%E5%8E%9F%E7%94%9F/CRI-O/%E4%BD%BF%E7%94%A8CRI-O%E5%92%8CKubeadm%E6%90%AD%E5%BB%BA%E9%AB%98%E5%8F%AF%E7%94%A8%20Kubernetes%20%E9%9B%86%E7%BE%A4.html (主要参照,但是存在一些问题)
https://blog.csdn.net/u014230612/article/details/112647016 (重点参照)
https://stdworkflow.com/695/get-http-127-0-0-1-10252-healthz-dial-tcp-127-0-0-1-10252… (问题解决参照)