- Linux安装Anaconda和Jupyter
硬水果糖
人工智能Linuxlinuxjupyter运维
一、了解Anaconda和Jupyter引言:Anaconda是一个流行的开源数据科学平台,广泛用于数据分析、机器学习、人工智能等领域。它是一个集成了大量科学计算和数据科学工具的Python和R编程语言环境。Anaconda的主要目标是简化数据科学和机器学习的开发流程,提供一个易于安装和管理的环境。而预装了大量常用的Python和R库,这些库涵盖了数据科学的各个方面,包括:数据分析:Pandas、
- python pandas 读取excel单元门公式值_Python pandas对excel的操作实现示例
weixin_39585761
pythonpandas读取excel单元门公式值
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程。本篇介绍pandas的DataFrame对列(Column)的处理方法。示例数据请通过明哥的gitee进行下载。增加计算列pandas的DataFrame,每一行或每一列都是一个序列(Series)。比如:importpandasaspddf1=pd.read_e
- pandas整表写入excel指定位置_pandas操作Excel的常用场景及问题
那个吴小明
很多场景下使用pandas就能够胜任手上的excel处理任务,之前写的用python操作具体到excel单元格的方法参考:贺霆:python操作Excel实现自动化报表zhuanlan.zhihu.com现在主要介绍使用pandas读取excel的几种常用场景:一、常规读取importpandasaspdfrompandasimportDataFrame,Seriesimportosos.chdi
- pandas 读取某一单元格的值_07-Pandas Excel新建/读取/填充(一)
扇贝编程
pandas读取某一单元格的值
Excel是微软的经典之作,几乎可以满足我们日常工作的所有需求,但是在处理海量数据时,Excel在效率及性能方面就显得很吃力。正因为Pandas在数据处理方面有着独特的优势,所有掌握pandas库处理excel格式的数据就显得十分必要。目录excel文档新建读取excel文档行列操作空值自动填充行列函数运算excel数据排序excel数据按条件筛选#1.创建excel文件在jupyter中导入pa
- 如何用Python批量将CSV文件编码转换为UTF-8并转为Excel格式?
字节王德发
pythonpythonexcel开发语言
在处理数据时,CSV文件格式常常用作数据的交换格式。不过,很多情况下我们会遇到编码问题,特别是当文件不是UTF-8编码时。为了更好地处理这些文件,可能需要将它们转换为UTF-8编码,并且将其转换为Excel格式,这样可以方便后续的数据分析和使用。今天就来聊聊如何用Python实现这一过程。准备工作:安装必要的库我们需要确保安装了所需的Python库。主要用到的库有pandas和openpyxl。p
- Pandas完全指南:数据处理与分析从入门到实战
xiaoyu❅
pythonpythonpandas开发语言
目录引言一、Pandas环境配置与核心概念1.1安装Pandas1.2导入惯例1.3核心数据结构二、数据结构详解2.1Series创建与操作2.2DataFrame创建三、数据查看与基本操作3.1数据预览3.2索引与选择3.3数据排序四、数据清洗实战4.1处理缺失值4.2处理重复值4.3数据类型转换4.4字符串处理五、数据处理进阶5.1数据筛选5.2列操作5.3应用函数六、数据分组与聚合6.1基础
- 焊接性能分析代码(Python)
骑蜗牛上月亮
python开发语言
welding_performance_data.xls数据文件。welding_strengthtoughness5001052012480855015490953013510115401447075601690018600121500139111578115importpandasaspdimportmatplotlib.pyplotaspltimporttkinterastkfrommatp
- Python常用的库讲解(易懂版)
不辉放弃
python开发语言
NumPy:用于科学计算的基础库,提供多维数组对象、各种派生对象和对数组执行操作的工具。importnumpyasnp#创建一个numpy数组arr=np.array([1,2,3,4,5])print(arr)Pandas:数据处理库,提供数据结构和数据分析工具,特别适合处理结构化数据。importpandasaspd#创建一个Pandas数据帧df=pd.DataFrame({'A':[1,2
- 基于Geopandas的地理空间数据可视化与分析方法研究
一键难忘
信息可视化Geopandaspython
地理空间数据可视化是数据科学中重要的应用之一。通过有效地展示地理信息,我们能够深入理解空间数据的分布和模式。Python的Geopandas库为地理空间数据处理和可视化提供了强大的支持,它基于pandas并集成了shapely、fiona等多个库,能够方便地进行地理数据的读取、处理和展示。本文将介绍如何使用Geopandas进行地理空间数据可视化,示范数据处理的基本流程,并通过具体的代码实例,深入
- 如何用python做一个小程序进行炒股?
大懒猫软件
python小程序开发语言
使用Python分析股票的完整程序以下是一个完整的Python程序,展示如何获取股票数据、进行数据清洗、计算技术指标、并进行简单的价格走势分析。1.安装必要的库首先,确保安装了必要的库:bash复制pipinstallrequestspandasmatplotlibyfinance2.获取股票数据使用yfinance库获取股票数据。yfinance是一个流行的库,可以方便地从雅虎财经获取股票数据。
- 批量将将xlsx转为csv,将csv转为csv utf-8
Znnjcidmslz
数据pythonpandas
csv转换为csvutf-8将csv格式文件批量转换为csvutf-8格式文件,以下为使用Python处理的代码:importosimportpandasaspd#存有文件的路径current_path=os.getcwd()#current_path=os.path.dirname('G:/weather_output2')#转换之后存放的路径为“UTF8”,会检查当前路径是否有,没有就创建ut
- csv转为utf8编码_中文的csv文件的编码改成utf8的方法
John Sheppard
csv转为utf8编码
直奔主题:把包含中文的csv文件的编码改成utf-8的方法:啰嗦几句:在用pandas读取hive导出的csv文件时,经常会遇到类似UnicodeDecodeError:'gbk'codeccan'tdecodebyte0xa3inposition12这样的问题,这种问题是因为导出的csv文件包含中文,且这些中文的编码不是gbk,直接用excel打开这些文件还会出现乱码,但用记事本打开这些csv则
- 1.4使用pandas读取和写入Excel文件的基本操作
林伽一
python处理excelpandasexcelpython
读取和写入Excel文件是使用Python处理Excel的基本操作。在Python中,可以使用不同的库来实现这些操作,例如pandas、openpyxl等。以下是读取和写入Excel文件的基本操作示例:读取Excel文件使用pandas库读取Excel文件非常方便。下面的示例演示了如何使用pandas读取Excel文件:importpandasaspd#读取Excel文件df=pd.read_ex
- 【Python】爬取高校数据(名字,院校特色,所在地,性质)。可用于判断高校是否为双一流,本科/专科等分析
llzcxdb
Pythonpython开发语言爬虫
源网站:http://college.gaokao.com/schlist/p1利用Python的lxml库进行html解析,源代码:importrequestsfromlxmlimportetreeimportpandasaspdimportcsv#请求URLurl='http://college.gaokao.com/schlist/p'#构建请求头headers={'User-Agent':
- 机器学习Pandas_learn4
XW-ABAP
机器学习机器学习pandas人工智能
importpandasaspddefcalculate_goods_covariance():#定义商品销售数据字典goods_sales_data={"时期":["一期","二期","三期","四期"],"苹果":[15,16,3,2],"橘子":[12,14,16,18],"石榴":[11,8,7,1]}#将字典转换为DataFrame对象goods_dataframe=pd.DataFra
- 如何使用Python对Excel、CSV文件完成数据清洗与预处理?
Python 集中营
python数据分析应用pythonexcel开发语言
在数据分析和机器学习项目中,数据清洗与预处理是不可或缺的重要环节。现实世界中的数据往往是不完整、不一致且含有噪声的,这些问题会严重影响数据分析的质量和机器学习模型的性能。Python作为一门强大的编程语言,提供了多种库和工具来帮助我们高效地完成数据清洗与预处理任务,其中最常用的库包括Pandas、NumPy、SciPy等。本文将详细介绍如何使用Python对Excel和CSV格式的数据文件进行清洗
- Pandas与PySpark混合计算实战:突破单机极限的智能数据处理方案
Eqwaak00
Pandaspandas学习python科技开发语言
引言:大数据时代的混合计算革命当数据规模突破十亿级时,传统单机Pandas面临内存溢出、计算缓慢等瓶颈。PySpark虽能处理PB级数据,但在开发效率和局部计算灵活性上存在不足。本文将揭示如何构建Pandas+PySpark混合计算管道,在保留Pandas便捷性的同时,借助Spark分布式引擎实现百倍性能提升,并通过真实电商用户画像案例演示全流程实现。一、混合架构设计原理1.1技术栈优势分析维度P
- pandas 根据给定的条件动态筛选
Aa123456789_55
pandaspandaspython
defdynamic_filter(df,conditions):"""根据给定的条件动态筛选DataFrame。:paramdf:pandasDataFrame:paramconditions:字典,键为列名,值为筛选条件(单个值、列表或其他布尔表达式):return:筛选后的DataFrame"""mask=pd.Series(True,index=df.index)#初始化全True的mas
- 机器学习Pandas_learn3
XW-ABAP
机器学习pandas
frompandasimportDataFrameimportnumpypaints={"车名":["奥迪Q5L","哈弗H6","奔驰GLC"],"最低报价":[numpy.nan,9.80,numpy.nan],"最高报价":[49.80,23.10,58.78]}goods_in=DataFrame(paints,index=[1,2,3])print(goods_in)goods_in_n
- python绘制密度散点图
龟速前进
anaconda可视化python
头大,外行人做个图咋这么难,趋势线还没有研究出来怎么加上去,哎importmatplotlib.pyplotaspltfromscipy.statsimportgaussian_kdefrommpl_toolkits.axes_grid1importmake_axes_locatableimportnumpyasnpimportpandasaspdfromdbfreadimportDBFdata=
- pandas 读写excel
jimox_ai
pandas
在Python中,使用Pandas库读写Excel文件是一个常见的操作。Pandas提供了`read_excel`和`to_excel`方法来分别实现读取和写入Excel文件的功能。以下是一些基本的示例:###读取Excel文件```pythonimportpandasaspd#读取Excel文件df=pd.read_excel('path_to_your_excel_file.xlsx')#显示
- 大话 Python:python 操作 excel 系列 -- pandas 读取、分析、保存
2401_84140734
程序员pythonexcelpandas
read_excel()直接读取excel文件df=pd.read_excel(‘C:/test.xlsx’)4,读取当前字段计算后生成新字段获取原有字段paymount值paymount=df[‘paymount’]业务计算(金额-10)paymount_new=paymount-10添加新字段paymount_newdf[‘paymount_new’]=paymount_new这个步骤可以加入
- pandas寻找四分位数及判断离群点
SXxtyz
python
importpandasaspdtrain_df=pd.read_csv("train.csv")q1,q3=train_df['price'].quantile([0.25,0.75])iqr=q3-
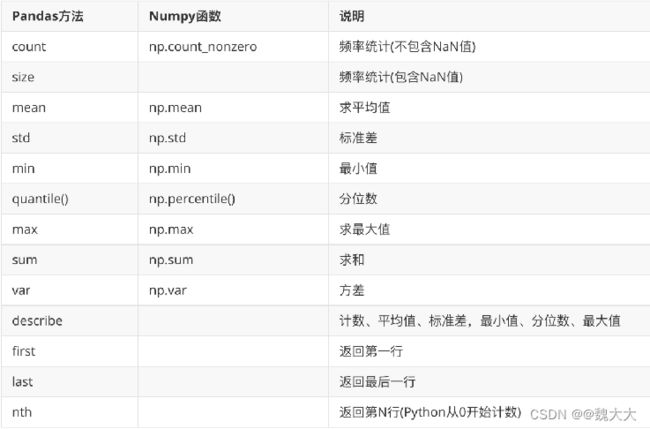
- Python----数据分析(Pandas四:一维数组Series的统计计算,分组和聚合)
蹦蹦跳跳真可爱589
数据分析Pythonpandaspython数据分析
一、统计计算1.1、count用于计算Series中非NaN(非空)值的数量。importpandasaspds=pd.Series([1,2,None,4,None])count_non_na=s.count()print(count_non_na)1.2、sumsum()函数会计算所有值的总和。Series.sum(axis=None,skipna=True,numeric_only=None
- Python----数据分析(Pandas三:一维数组Series的数据操作:数据清洗,数据转换,数据排序,数据筛选,数据拼接)
蹦蹦跳跳真可爱589
数据分析Pythonpython数据分析pandas
一、数据清洗1.1、dropna()删除包含NaN值的行。series.dropna(axis=0,inplace=False)描述说明axis可选参数,用于指定按哪个轴删除缺失值。对于Series对象,因为它是一维数据结构,只有一个轴,所以此参数默认值为0,且一般不需要修改这个参数(在处理DataFrame时该参数才有更多实际意义,如除,axis=1表示按列删除)。inplace可选参数,用于指
- 房产租赁数据分析与可视化
学习只是用户态
数据分析信息可视化数据挖掘
【实训目的】 通过本次实训,要求了解Python用于数据可视化的常用包:matplotlib、seaborn、pyecharts等基本使用,及各种图形的使用。【实训环境】 Jupyter环境、Pandas、NumPy、Matplotlib。【实训内容】 1.数据统计与分析方面的可视化; 2.数据分析与预测方面的可视化; 3.数据多类型的可视化。 本次实验以温州市三区房屋租赁数据(res
- selenium+pyquery爬取《鱿鱼游戏》评论2000+条
铁憨憨0304
python爬虫seleniumpython测试工具
IMDB网址爬取《鱿鱼游戏》的全部评论评论排名评论标题id评论时间评论内容导入所需要的包selenium:模拟浏览器,这里使用的是Edge浏览器,需要安装Edge浏览器驱动解析库:PyQuery保存数据:pandas,保存为csv文件fromseleniumimportwebdriverfromselenium.webdriver.support.uiimportWebDriverWaitfrom
- Python——文件读取
一颗小松松
python开发语言
Python可以读取不同格式的文件,下面简单来介绍一下:1、使用read_excel或read_csv读取文件,若在路径前加r,使用“\”importpandasaspd#在路径前加r,使用“\”df=pd.read_excel(r'C:\Users\merit\Desktop\测试.xlsx')#导入.csv文件,以“,”为分隔符data=pd.read_csv(r'C:\Users\merit
- Python处理CSV文件的12个高效技巧
宇宙大豹发
python开发语言
今天,我们的Python之旅,目标是那片由逗号分隔的宝藏——CSV文件。别看它简单,掌握这些技巧,你的数据处理能力将直线上升,轻松驾驭千行万列的数据海洋。让我们一起,用Python的魔力,让CSV舞动起来吧!1.初次见面,你好,CSV!安装pandas,是这场冒险的起点。它,是Python数据分析的瑞士军刀。pipinstallpandas导入我们的英雄——pandas,并亲切地叫它pd。impo
- Python中三种表示NA的方式
风语者666
python
Python中三种表示NA的方式#-*-coding:utf-8-*-importnumpyasnpimportpandasaspd#data_frame=np.load('a.npy',allow_pickle=True)#print(data_frame.columns)df=pd.DataFrame({'one':[1,2,3,pd.NA]})df=pd.DataFrame({'one':[
- 安装数据库首次应用
Array_06
javaoraclesql
可是为什么再一次失败之后就变成直接跳过那个要求
enter full pathname of java.exe的界面
这个java.exe是你的Oracle 11g安装目录中例如:【F:\app\chen\product\11.2.0\dbhome_1\jdk\jre\bin】下的java.exe 。不是你的电脑安装的java jdk下的java.exe!
注意第一次,使用SQL D
- Weblogic Server Console密码修改和遗忘解决方法
bijian1013
Welogic
在工作中一同事将Weblogic的console的密码忘记了,通过网上查询资料解决,实践整理了一下。
一.修改Console密码
打开weblogic控制台,安全领域 --> myrealm -->&n
- IllegalStateException: Cannot forward a response that is already committed
Cwind
javaServlets
对于初学者来说,一个常见的误解是:当调用 forward() 或者 sendRedirect() 时控制流将会自动跳出原函数。标题所示错误通常是基于此误解而引起的。 示例代码:
protected void doPost() {
if (someCondition) {
sendRedirect();
}
forward(); // Thi
- 基于流的装饰设计模式
木zi_鸣
设计模式
当想要对已有类的对象进行功能增强时,可以定义一个类,将已有对象传入,基于已有的功能,并提供加强功能。
自定义的类成为装饰类
模仿BufferedReader,对Reader进行包装,体现装饰设计模式
装饰类通常会通过构造方法接受被装饰的对象,并基于被装饰的对象功能,提供更强的功能。
装饰模式比继承灵活,避免继承臃肿,降低了类与类之间的关系
装饰类因为增强已有对象,具备的功能该
- Linux中的uniq命令
被触发
linux
Linux命令uniq的作用是过滤重复部分显示文件内容,这个命令读取输入文件,并比较相邻的行。在正常情 况下,第二个及以后更多个重复行将被删去,行比较是根据所用字符集的排序序列进行的。该命令加工后的结果写到输出文件中。输入文件和输出文件必须不同。如 果输入文件用“- ”表示,则从标准输入读取。
AD:
uniq [选项] 文件
说明:这个命令读取输入文件,并比较相邻的行。在正常情况下,第二个
- 正则表达式Pattern
肆无忌惮_
Pattern
正则表达式是符合一定规则的表达式,用来专门操作字符串,对字符创进行匹配,切割,替换,获取。
例如,我们需要对QQ号码格式进行检验
规则是长度6~12位 不能0开头 只能是数字,我们可以一位一位进行比较,利用parseLong进行判断,或者是用正则表达式来匹配[1-9][0-9]{4,14} 或者 [1-9]\d{4,14}
&nbs
- Oracle高级查询之OVER (PARTITION BY ..)
知了ing
oraclesql
一、rank()/dense_rank() over(partition by ...order by ...)
现在客户有这样一个需求,查询每个部门工资最高的雇员的信息,相信有一定oracle应用知识的同学都能写出下面的SQL语句:
select e.ename, e.job, e.sal, e.deptno
from scott.emp e,
(se
- Python调试
矮蛋蛋
pythonpdb
原文地址:
http://blog.csdn.net/xuyuefei1988/article/details/19399137
1、下面网上收罗的资料初学者应该够用了,但对比IBM的Python 代码调试技巧:
IBM:包括 pdb 模块、利用 PyDev 和 Eclipse 集成进行调试、PyCharm 以及 Debug 日志进行调试:
http://www.ibm.com/d
- webservice传递自定义对象时函数为空,以及boolean不对应的问题
alleni123
webservice
今天在客户端调用方法
NodeStatus status=iservice.getNodeStatus().
结果NodeStatus的属性都是null。
进行debug之后,发现服务器端返回的确实是有值的对象。
后来发现原来是因为在客户端,NodeStatus的setter全部被我删除了。
本来是因为逻辑上不需要在客户端使用setter, 结果改了之后竟然不能获取带属性值的
- java如何干掉指针,又如何巧妙的通过引用来操作指针————>说的就是java指针
百合不是茶
C语言的强大在于可以直接操作指针的地址,通过改变指针的地址指向来达到更改地址的目的,又是由于c语言的指针过于强大,初学者很难掌握, java的出现解决了c,c++中指针的问题 java将指针封装在底层,开发人员是不能够去操作指针的地址,但是可以通过引用来间接的操作:
定义一个指针p来指向a的地址(&是地址符号):
- Eclipse打不开,提示“An error has occurred.See the log file ***/.log”
bijian1013
eclipse
打开eclipse工作目录的\.metadata\.log文件,发现如下错误:
!ENTRY org.eclipse.osgi 4 0 2012-09-10 09:28:57.139
!MESSAGE Application error
!STACK 1
java.lang.NoClassDefFoundError: org/eclipse/core/resources/IContai
- spring aop实例annotation方法实现
bijian1013
javaspringAOPannotation
在spring aop实例中我们通过配置xml文件来实现AOP,这里学习使用annotation来实现,使用annotation其实就是指明具体的aspect,pointcut和advice。1.申明一个切面(用一个类来实现)在这个切面里,包括了advice和pointcut
AdviceMethods.jav
- [Velocity一]Velocity语法基础入门
bit1129
velocity
用户和开发人员参考文档
http://velocity.apache.org/engine/releases/velocity-1.7/developer-guide.html
注释
1.行级注释##
2.多行注释#* *#
变量定义
使用$开头的字符串是变量定义,例如$var1, $var2,
赋值
使用#set为变量赋值,例
- 【Kafka十一】关于Kafka的副本管理
bit1129
kafka
1. 关于request.required.acks
request.required.acks控制者Producer写请求的什么时候可以确认写成功,默认是0,
0表示即不进行确认即返回。
1表示Leader写成功即返回,此时还没有进行写数据同步到其它Follower Partition中
-1表示根据指定的最少Partition确认后才返回,这个在
Th
- lua统计nginx内部变量数据
ronin47
lua nginx 统计
server {
listen 80;
server_name photo.domain.com;
location /{set $str $uri;
content_by_lua '
local url = ngx.var.uri
local res = ngx.location.capture(
- java-11.二叉树中节点的最大距离
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
public class MaxLenInBinTree {
/*
a. 1
/ \
2 3
/ \ / \
4 5 6 7
max=4 pass "root"
- Netty源码学习-ReadTimeoutHandler
bylijinnan
javanetty
ReadTimeoutHandler的实现思路:
开启一个定时任务,如果在指定时间内没有接收到消息,则抛出ReadTimeoutException
这个异常的捕获,在开发中,交给跟在ReadTimeoutHandler后面的ChannelHandler,例如
private final ChannelHandler timeoutHandler =
new ReadTim
- jquery验证上传文件样式及大小(好用)
cngolon
文件上传jquery验证
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="jquery1.8/jquery-1.8.0.
- 浏览器兼容【转】
cuishikuan
css浏览器IE
浏览器兼容问题一:不同浏览器的标签默认的外补丁和内补丁不同
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
碰到频率:100%
解决方案:CSS里 *{margin:0;padding:0;}
备注:这个是最常见的也是最易解决的一个浏览器兼容性问题,几乎所有的CSS文件开头都会用通配符*来设
- Shell特殊变量:Shell $0, $#, $*, $@, $?, $$和命令行参数
daizj
shell$#$?特殊变量
前面已经讲到,变量名只能包含数字、字母和下划线,因为某些包含其他字符的变量有特殊含义,这样的变量被称为特殊变量。例如,$ 表示当前Shell进程的ID,即pid,看下面的代码:
$echo $$
运行结果
29949
特殊变量列表 变量 含义 $0 当前脚本的文件名 $n 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个
- 程序设计KISS 原则-------KEEP IT SIMPLE, STUPID!
dcj3sjt126com
unix
翻到一本书,讲到编程一般原则是kiss:Keep It Simple, Stupid.对这个原则深有体会,其实不仅编程如此,而且系统架构也是如此。
KEEP IT SIMPLE, STUPID! 编写只做一件事情,并且要做好的程序;编写可以在一起工作的程序,编写处理文本流的程序,因为这是通用的接口。这就是UNIX哲学.所有的哲学真 正的浓缩为一个铁一样的定律,高明的工程师的神圣的“KISS 原
- android Activity间List传值
dcj3sjt126com
Activity
第一个Activity:
import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import android.app.Activity;import android.content.Intent;import android.os.Bundle;import a
- tomcat 设置java虚拟机内存
eksliang
tomcat 内存设置
转载请出自出处:http://eksliang.iteye.com/blog/2117772
http://eksliang.iteye.com/
常见的内存溢出有以下两种:
java.lang.OutOfMemoryError: PermGen space
java.lang.OutOfMemoryError: Java heap space
------------
- Android 数据库事务处理
gqdy365
android
使用SQLiteDatabase的beginTransaction()方法可以开启一个事务,程序执行到endTransaction() 方法时会检查事务的标志是否为成功,如果程序执行到endTransaction()之前调用了setTransactionSuccessful() 方法设置事务的标志为成功则提交事务,如果没有调用setTransactionSuccessful() 方法则回滚事务。事
- Java 打开浏览器
hw1287789687
打开网址open浏览器open browser打开url打开浏览器
使用java 语言如何打开浏览器呢?
我们先研究下在cmd窗口中,如何打开网址
使用IE 打开
D:\software\bin>cmd /c start iexplore http://hw1287789687.iteye.com/blog/2153709
使用火狐打开
D:\software\bin>cmd /c start firefox http://hw1287789
- ReplaceGoogleCDN:将 Google CDN 替换为国内的 Chrome 插件
justjavac
chromeGooglegoogle apichrome插件
Chrome Web Store 安装地址: https://chrome.google.com/webstore/detail/replace-google-cdn/kpampjmfiopfpkkepbllemkibefkiice
由于众所周知的原因,只需替换一个域名就可以继续使用Google提供的前端公共库了。 同样,通过script标记引用这些资源,让网站访问速度瞬间提速吧
- 进程VS.线程
m635674608
线程
资料来源:
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001397567993007df355a3394da48f0bf14960f0c78753f000 1、Apache最早就是采用多进程模式 2、IIS服务器默认采用多线程模式 3、多进程优缺点 优点:
多进程模式最大
- Linux下安装MemCached
字符串
memcached
前提准备:1. MemCached目前最新版本为:1.4.22,可以从官网下载到。2. MemCached依赖libevent,因此在安装MemCached之前需要先安装libevent。2.1 运行下面命令,查看系统是否已安装libevent。[root@SecurityCheck ~]# rpm -qa|grep libevent libevent-headers-1.4.13-4.el6.n
- java设计模式之--jdk动态代理(实现aop编程)
Supanccy2013
javaDAO设计模式AOP
与静态代理类对照的是动态代理类,动态代理类的字节码在程序运行时由Java反射机制动态生成,无需程序员手工编写它的源代码。动态代理类不仅简化了编程工作,而且提高了软件系统的可扩展性,因为Java 反射机制可以生成任意类型的动态代理类。java.lang.reflect 包中的Proxy类和InvocationHandler 接口提供了生成动态代理类的能力。
&
- Spring 4.2新特性-对java8默认方法(default method)定义Bean的支持
wiselyman
spring 4
2.1 默认方法(default method)
java8引入了一个default medthod;
用来扩展已有的接口,在对已有接口的使用不产生任何影响的情况下,添加扩展
使用default关键字
Spring 4.2支持加载在默认方法里声明的bean
2.2
将要被声明成bean的类
public class DemoService {