性能测试实战(四):Jmeter的使用
一、初识Jmeter
1、Jmeter的文件结构:
(1)bin
jmeter的启动文件以及配置文件。jmeter的默认保存文件路径,也是在jmeter的bin文件夹里;读取文件,默认也是该文件夹。
(2)docs
文档,开发人员看的接口api文档,如果你要对jmeter进行二次开发,需要阅读此文档。
(3)printable_docs
文档,这是Jmeter的使用帮助文档(离线帮助)。
(4)lib
library库,存放jmeter源码打成的jar包,以及第三方人员开发的扩展功能jar
ext文件夹,放第三方人员开发扩展功能jar
场景设计时,也会涉及到jar
(5)extras
在jmeter性能测试持续集成的时候,而外生成的文件夹
2、jmeter运行模式
(1)GUI图形界面:学习时使用该方式运行
(2)CLI无图形界面:实战中使用该方式运行
3、面试问题
(1)你用Jmeter做性能测试,你的机器配置需要什么样的配置?
jmeter默认启动时,只会占用1g的内存资源
修改jmeter以及系统的相关配置,才能支持比较大的并发用户数
需要单独的性能测试机器,测试机器的配置由被测服务器决定。如果被测服务器支持几千上万的并发用户数,那么一台无法满足被测服务器的并发用户数,则需要多台测试机器;如果被测服务器,只能支持几十小几百的并发用户数,则测试机器的配置,需要中等偏上的硬件配置。
一般一台测试机器能支持上千的并发
4、性能测试相关
(1)性能测试时,如果写代码,不要使用beanshell,因为性能低
(2)写性能测试脚本时,jmeter不仅支持java,也支持python2.7、groovy、jython、js
二、jmeter工具的简单使用
1、使用时,需要改变2个习惯
(1)使用工具时,容易在菜单中找功能,但jmeter的菜单中只有很少部分的功能
(2)jmeter的重点功能,都在右键
2、界面基本功能介绍
(1)快捷工具栏
00:00:00 表示jmeter的运行时间
0 0/0
▲可以打开日志面板,后面的第一个数值,在工具报错时会有红色数字
0/0 前面的数值,是当前有多少个正在运行的线程,后面的数值,表示预计要开启多少个线程数
3、写脚本
(1)理解接口文档
① http请求:请求行 请求头 请求体
请求行:请求方法,请求URI
请求头:Content-Type、UserAgent
当你的请求体为json格式时,请求头中必须有Content-Type:application/json
②请求头:Content-Type:application/json;charset=utf-8
意思是:请求体格式为json格式,可通过jmeter的配置元件消息头管理器配置
Accept: application/json 是表示响应格式为json格式,非必传
③http响应:响应行 响应头 响应体
响应行:响应码
2xx 响应成功
3xx 成功,但是有重定向
4xx 资源找不到,请求地址可能有问题(功能测试时),发起机器、脚本、服务器可能有问题(性能测试时)
5xx 服务器异常
响应头:Accept(非必传)
④json格式:
{
"key0":"value",
"key1":2,
"key2":"[{\"key0\":\"v1\",\"key1\":2}]"
}
(2)根据接口文档写脚本
①存在注册接口文档如下:

②上面有个字段code验证码,这个在企业测试环境中,可以采取以下两种方式解决:
开发人员暂时注释掉该部分代码
使用万能验证码
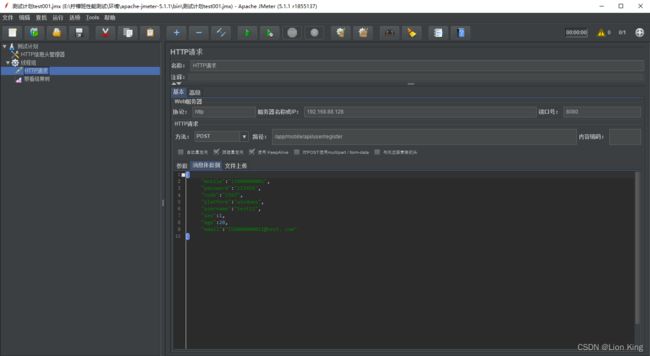
③http请求注意事项
⚪协议输入项里,如果协议是http可以不写,但https一定要写
⚪服务器的名称或IP:千万不要写带任何 / 的信息
⚪端口根据项目端口填写
⚪请求方法一定要根据文档描述来填写
⚪路径必须使用 / 开头
注意路径的前后空格,空格在url-encode编码后会显示 %20
⚪请求体的内容编码:将非英文字母或数字的值,进行utf8编码
控制请求体的三个地方
▲内容编码:utf-8
▲消息头:Content-Type 加 ;charset=utf8
application/json ------Content-Type添加该字段,代表的请求体为json格式
application/x-www-form-urlencoded ------ 不写时,默认为此表单格式,当请求体不是json的时候,不写application/x-www-form-urlencoded也会默认此格式
此时,请求体,需要写在http的参数里面
▲在参数中写内容时,勾选“编码”,那么参数值就会进行url-encode编码,需要注意当你的请求体为参数(表单格式)时,你的参数值,如果有中文或特殊符号,请务必勾选“编码”,不然,你的请求可能报错,或进入服务器内部后乱码。所以,不管你的值是什么数据,建议都勾选“编码”。而消息体数据,可以写json、xml;文件上传时,可以写文件路径来传文件。
④响应体的编码控制
⚪在jmeter请求之后,在查看结果树中,看到response-body中,出现中文乱码
出现乱码的原因:jmeter.bat文件启动,去读取了我们的配置文件,然后再启动jmeter,jmeter的编码,使用了系统的中文编码,系统window中文版,编码gbk,所以,我们jmeter中,所有的中文,都是gbk编码,当你的请求响应体中的编码,不是gbk,或者是gbk但无法编码时,就会出现乱码。
解决方式:先把jmeter的编码改为utf8,如果不行,再修改为响应体的编码(修改方式:bin文件夹下面修改jmeter.proper...的配置文件)
⑤自动重定向和跟随重定向
自动重定向,也会重定向,但不会记录中间过程,因此不能提取中间数据
跟随重定向,默认勾选,请求会自动进行跳转到新的地址上,而且会显示重定向的过程,我们也可以提取出重定向过程中的数据(可以通过后置处理器提取数据)。
如果发生了重定向,在查看结果树中,会有一个折叠的加号可以展开。如果你的请求方法错误,也可能在查看结果树这边,看到这种带有加号的折叠现象。(红色时,表示方法错误)
使用keepalive,与性能相关,现在接口协议http版本是1.1版本,默认就是长连接,勾选keepalive就是长连接,可进行长时间的数据传输,不需要再次握手。注意:长连接建立起来之后,会占用发起方的端口,被测服务器要使用1个连接通道,所以端口数量可能会成为性能瓶颈,因为端口数量有限,大概是6.3万左右(1024~65534之间),我们服务器的通道也可能成为性能瓶颈(有资源才能创建,不可能无限大)。解决办法:不勾选keepalive(有可能解决问题,延缓出错时间,不能从根本上解决问题);去修改系统的端口访问相关配置(操作系统修改,如果不修改,30个并发用户数可能就出错了)
⑥jmeter的元件的作用域与优先级
⚪配置元件的优先级:优先级最高的元件
典型的元件:csv数据文件设置、消息头管理器、请求默认值、用户定义变量
优先级最高:最先被执行
都是配置文件:优先级顺序从上往下
用户定义变量:
⚪作用域:测试计划>线程组>取样器(如果这三者都有相同元件,执行顺序由左到右,最终以最后的元件配置为准)
⚪发起请求的元件:取样器
要有取样器,必须先有线程组(这个是用来进行性能场景设计的)
要有线程组,必须先有测试计划(脚本的根路径)
取样器:是真正发起请求的元件,也就是真正干活的
根据不同的协议,会有不同的取样器
⚪逻辑控制器: 控制取样器的逻辑 ------- 肯定在取样器之前被执行,逻辑控制下面会有取样器
作用域:只会作用在它下面的取样器
⚪前置处理器:在取样器被执行前被执行,是在请求前做准备
作用域:放在测试计划下,则作用于整个测试计划,都可以使用;放在线程组,则作用在线程组,而不作用域其他线程组;放在取样器,则作用域取样器,而不作用于同级的其他取样器(可作用于下一级取样器)。
用户参数:
⚪后置处理器:对取样器的执行结果进行,是在请求后才执行
json提取器、正则提取器
作用域:放在测试计划下面,因为没有请求结果,相当于没有作用域;放在线程组下面,如果有多个请求结果,则结果不可预知;因此,后置处理器应正确放在某个取样器下面。
⚪定时器
定时器放在线程组下面,作用域整个线程组
定时器放在取样器下面,只作用于该取样器
⚪小结
| 元件 | 作用 | 作用域 |
| 取样器 | 只作用于自身 | 无作用域 |
| 逻辑控制器 | 控制子节点 | 作用于子节点 |
| 前置处理器 | 在取样器执行前,影响所有取样器 | 整个测试计划 |
| 后置处理器 | 在取样器之后执行,影响在此之后的取样器 | 后续取样器 |
| 断言 | 取样器之后执行 | 当前取样器 |
| 定时器 | 影响同级及子集取样器 | 同级及子级 |
| 配置元件 | 影响同级及子级元件 | 同级及子级 |
| 监听器 | 手机取样器执行数据 | 同级 |
⑦实战展示: