ElasticSearch总结
文章目录
- 一、ElasticSearch概述
-
- 1、基本介绍
- 2、Elasticsearch 是如何诞生的?
- 3、哪些公司在用ElasticSearch?
- 二、ElasticSearch和Solr的区别
- 三、ES安装及head插件安装
-
- 1、windows下安装
- 2、安装可视化界面es head的插件
- 四、安装Kibana
- 五、ES核心概念
-
- 1、索引
- 六、IK分词器
- 七、基本的操作
-
- 1、Rest风格说明
- 2、索引的基本操作
- 3、文档的基本操作
- 八、集成SpringBoot
-
- 1、初始化SpringBoot项目
- 2、编写索引API
- 3、编写文档API
- 九、仿京东搜索

一、ElasticSearch概述
1、基本介绍
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
2、Elasticsearch 是如何诞生的?
2004 年,Shay Banon 开发了 Compass,这是一个基于 Lucene 技术的应用。回忆起 Compass 的诞生,他的脸上总会挂满微笑。某种意义上,Shay Banon、Compass 与 Lucene 的关系是一种偶然。
那时,他刚结婚。为支持妻子成为厨师的梦想,他们搬到伦敦。Shay Banon 正值失业状态,急需一份工作,所以他决定试试一些新技术,让自己的技能更符合当前时代的需求。因为只有真正尝试构建一些东西时,新技术才能发挥作用,所以他决定构建一个烹饪 App,让妻子可以用来搜索她在烹饪课程中收集的烹饪信息。
为开发这款 App,他认真比较了很多不同技术的优缺点。在他眼里,这款 App 的核心是一个搜索框。只要你在这个搜索框中输入一个概念、一个想法或者一种配料,它就可以开始搜索可能相关的烹饪知识。很快,他接触到 Lucene,它当时是 Java 上可用的搜索库。他说:“我沉浸其中,尝试在典型的 Java 应用中简化 Lucene 的使用。这个过程中诞生了 Compass。”
Shay Banon 被这个项目深深吸引,把更多的时间和精力转向这个项目,而非烹饪 App 本身。几个月后,他决定把它开源,而 Compass 很快流行起来。Compass 允许用户轻松地将他们的领域模型(在典型程序中映射应用程序或业务概念的代码)映射到 Lucene,方便地索引,然后轻松地搜索它们。这种自由让越来越多的人开始使用 Compass 和 Lucene,但是他从未预料到这种情况。
假设在你的金融应用程序中有一个交易模型,你可以轻松地使用 Compass 将该交易索引到 Lucene 中,然后搜索它,并自由地搜索交易的任何方面信息,并允许用户将这种自由传递给他们的用户,这被证明是一个功能非常强大的概念。
“实际上,这让我可以与实际用户交谈和工作,他们和我一样,发现了搜索在向用户提供业务价值方面所具有的惊人能力。”Shay Banon 说。
10 年后的今天,它就是 Elasticsearch 的基础!
3、哪些公司在用ElasticSearch?
在国内,阿里巴巴、腾讯、滴滴、今日头条、饿了么、360安全、小米,vivo 等诸多知名公司都在使用Elasticsearch,多到不能穷举,主要用于日志搜集分析、用于APP综合搜索、订单系统搜索、企业级网站搜索等方面…
二、ElasticSearch和Solr的区别
1、solr: Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果,【特点】是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
2、ElasticSearch:ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
ElasticSearch和Solr的比较
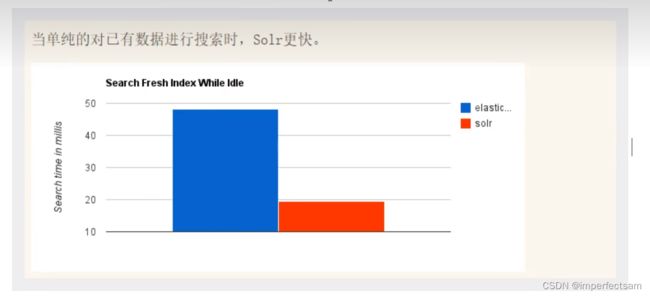


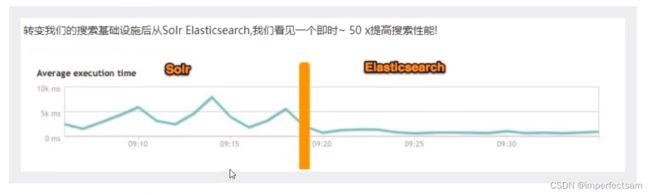
ElasticSearch vs Solr 总结
1、es基本就是开箱使用,非常简单,Solr安装比较复杂一点。
2、Solr支持更多格式的数据,比如json,xml,csv,而ElasticSearch仅支持json文件格式。
3、Solr利用Zookeeper进行分布式管理,而ElasticSearch自身带有分布式协调管理功能。
4、Solr官方提供的功能更多,而ElasticSearch本身更注重与核心功能,高级功能多有第三方插件提供,例如图形化页面需要kibana友好支撑。
5、Solr查询快,但更新索引满,用于电商等查询多的应用。
6、ElasticSearch建立索引快(查询慢),实时性查询快,用于facebook新浪等搜索。
7、Solr是传统搜索应用的有力解决方案,但ElasticSearch更适用新兴的实时搜索应用。
8、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而ElasticSearch相对开发维护者较少,更新太快,学习使用成本较高。
三、ES安装及head插件安装
1、windows下安装
官网下载地址
我这里下载的是7.6.2,这里下载需要梯子,不然会很慢

下载完了以后,我们直接解压就好了。
然后我们来熟悉一下目录
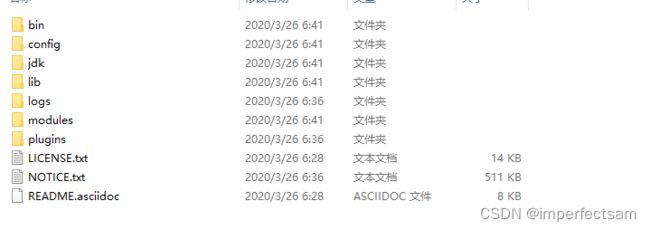
bin 启动文件
conf 配置文件
log4j2 日志配置文件
jvm.options java 虚拟机相关的配置
elasticsearch.yml elasticsearch 的配置文件 默认为9200端口
lib 相关jar包
logs 日志
modules 功能模块
plugins 插件
然后我们来启动一下
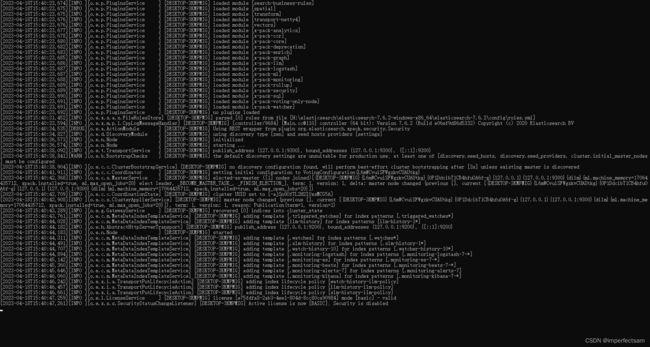
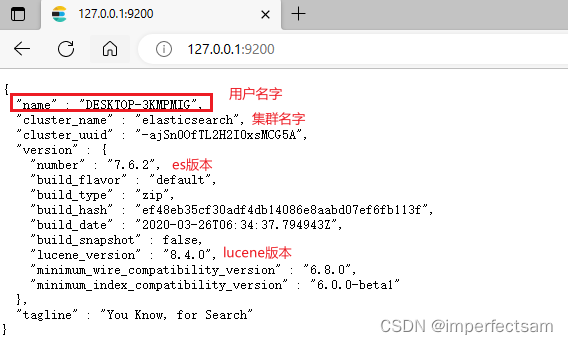
启动成功后我们来访问一下http://127.0.0.1:9200/
2、安装可视化界面es head的插件
没有nodejs和npm是不可以进行安装的
下载地址
在解压文件完的目录下进行安装。
npm install
如果存在报错
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! [email protected] install: `node install.js`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] install script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
可以执行
npm install [email protected] --ignore-scripts
来进行安装
然后我们来启动一下
npm run start


哦嚯,这里我们发现了跨域的问题❌
接下来我们就来解决一下跨域的问题
首先我们找到es.yml文件
http.cors.enabled: true
http.cors.allow-origin: "*"
加上这两行配置允许所有人进行访问
然后我们重启一下es

我们就解决了跨域问题啦啦啦啦啦啦啦啦
四、安装Kibana
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash和Kibana这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
Kibana官网
这里选择的版本号需要跟es对应上7.6.2

我们解压到指定的文件夹就可以了。

我们打开kibana.yml
因为默认的kibana是英文的,我们可以汉化一下。在yml最下面一行加上
i18n.locale: "zh-CN"

在已经启动了es服务的前提下,我们就可以开开心心的启动kibana啦啦啦啦啦啦

访问http://localhost:5601/我们就可以看到启动kibana的可视化界面了。
五、ES核心概念
1、索引
ElasticSearch最关键的就是提供了强大的索引能力。一切的设计都是为了提高搜索的性能。
ElasticSearch为每一个field都建立了一个倒排索引。
例如文档中有以下的数据:
| id | name | age | sex |
|---|---|---|---|
| 1 | sam | 18 | male |
| 2 | imperfect | 26 | male |
| 3 | tom | 18 | female |
| 4 | cindy | 26 | female |
那么就会为每一个field都建立一个倒排索引
这是name字段的倒排索引
| term | posting list |
|---|---|
| sam | [1] |
| imperfect | [2] |
| tom | [3] |
| cindy | [26] |
这是age字段的倒排索引
| term | posting list |
|---|---|
| 18 | [1,3] |
| 26 | [2,4] |
这是sex字段的倒排索引
| term | posting list |
|---|---|
| male | [1,2] |
| female | [3,4] |
term就相当于每一个关键字keyword,而Posting list就是一个int的数组,存储了所有符合某个term的文档id。
倒排索引很多地方都有介绍,但是其比关系型数据库的 b-tree 索引快在哪里?到底为什么快呢?
我们先来看一下这张图
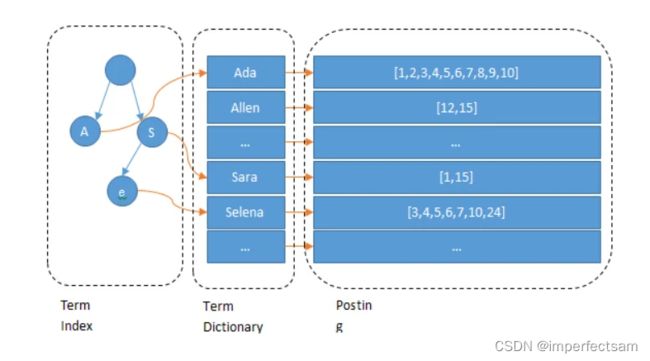
假设我们有很多个 term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的 term 一定很慢,因为 term 没有排序,需要全部过滤一遍才能找出特定的 term。排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的 term。这个就是 term dictionary。有了 term dictionary 之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次 random access 大概需要 10ms 的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 term dictionary 本身又太大了,无法完整地放到内存里。于是就有了 term index。term index 有点像一本字典的大的章节表。比如:
A 开头的 term ……………. Xxx 页
C 开头的 term ……………. Xxx 页
E 开头的 term ……………. Xxx 页
如果所有的 term 都是英文字符的话,可能这个 term index 就真的是 26 个英文字符表构成的了。但是实际的情况是,term 未必都是英文字符,term 可以是任意的 byte 数组。而且 26 个英文字符也未必是每一个字符都有均等的 term,比如 x 字符开头的 term 可能一个都没有,而 s 开头的 term 又特别多。实际的 term index 是一棵 trie 树:
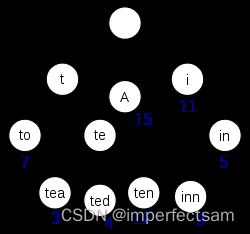
例子是一个包含 “A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 的 trie 树。这棵树不会包含所有的 term,它包含的是 term 的一些前缀。通过 term index 可以快速地定位到 term dictionary 的某个 offset(偏移量),然后从这个位置再往后顺序查找。再加上一些压缩技术(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有 term 的尺寸的几十分之一,使得用内存缓存整个 term index 变成可能。整体上来说就是这样的效果。
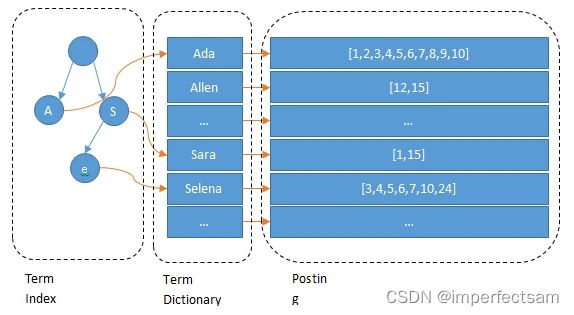
现在我们可以回答“为什么 Elasticsearch/Lucene 检索可以比 mysql 快了。Mysql 只有 term dictionary 这一层,是以 b-tree 排序的方式存储在磁盘上的。检索一个 term 需要若干次的 random access 的磁盘操作。而 Lucene 在 term dictionary 的基础上添加了 term index 来加速检索,term index 以树的形式缓存在内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的 random access 次数。
额外值得一提的两点是:term index 在内存中是以 FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary 在磁盘上是以分 block 的方式保存的,一个 block 内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去。这样 term dictionary 可以比 b-tree 更节约磁盘空间。
六、IK分词器
IK分词器下载地址
在当前目录下进行解压


然后我们重启一下es
避坑:
1、注意当前目录下只允许存在一个文件,不允许存在压缩文件
2、如果重启es出现强退,请检查properties文件中的版本信息
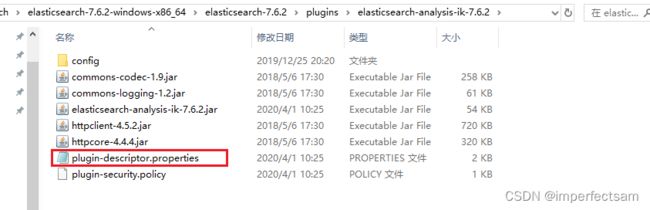
启动成功,我们可以看到这里加载了ik插件
我们启动一下kibana来玩一下这个ik分词器
ik提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分
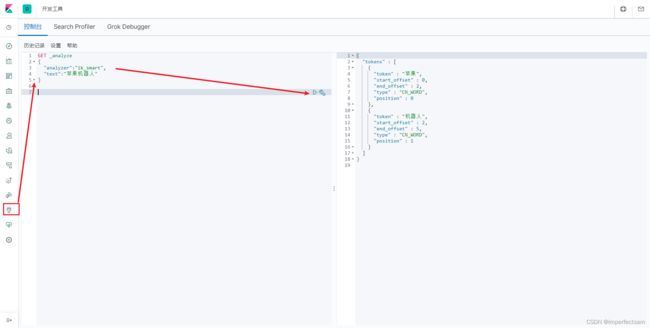
ik_smart
GET _analyze
{
"analyzer":"ik_smart",
"text":"苹果机器人"
}
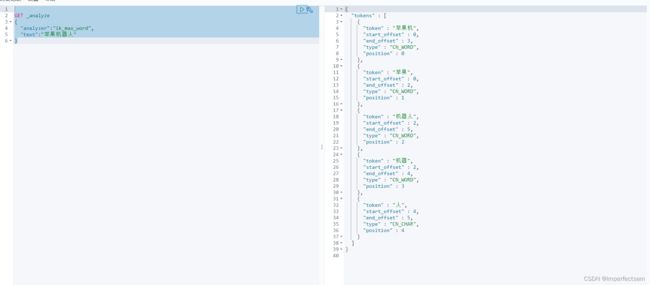
ik_max_word
GET _analyze
{
"analyzer":"ik_max_word",
"text":"苹果机器人"
}
除此之外,我们还可以自定义分词器的字典
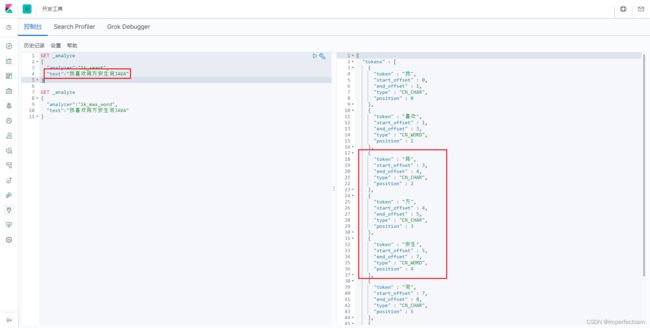
例如这里陈方安生是一个人

例如我们在这里加上imperfect.dic

避坑:
这里的dic注意要保存为UTF-8编码。
然后我们重启一下es和kibana

我们就可以看到这里成功把陈方安生这个词分出来啦
七、基本的操作
1、Rest风格说明
Rest风格是一种架构风格,而不是标准,只是提供了一组设计原则和约束条件,它主要用于客户端和服务端交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有的数据 |
2、索引的基本操作
创建一条索引
#PUT /索引名/类型名/文档id
#{请求体}
PUT /test1/type/1
{
"name":"imperfect",
"age":18
}
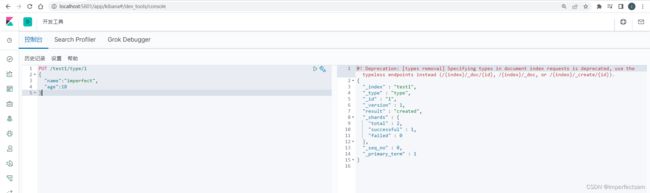
然后我们来分析一下返回的结果
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "test1", #创建了一个索引叫test1
"_type" : "type", #类型
"_id" : "1", #id
"_version" : 1, #版本号
"result" : "created", #当前状态
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}

然后我们看到这边成功创建一条索引。
数据类型
对于文档中的字段我们也可以设置类型
●字符串类型
text,keyword
●数值类型
long,integer,short,byte,double,float,half_float,scaled_float
●日期类型
date
●布尔值类型
boolean
●二进制类型
binary
等等
更多详情看下面的文章
官方文档
指定字段的类型
##这里我们只创建了索引并且指定里面的数据类型,并没有往里面插入数据。(创建索引规则)
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type":"text"
},
"age":{
"type":"long"
},
"birthday":{
"type":"date"
}
}
}
}
GET /test2
我们也可以获得当前索引的规则信息

获取当前索引状态信息
GET _cat/indices?v

同样地,这里我们输入的时候kibana也会有所提示的
使用PUT来修改文档
PUT /test1/type/1
{
"name":"imperfect123",
"age":18
}
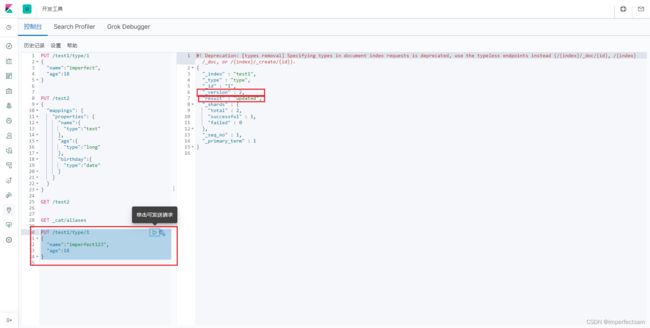
我们可以看到之前我们已经有一条数据了,这里修改完以后,这里显示的状态是update并且版本号增加为2了。
这里的PUT方法有个弊端就是如果我只传需要修改的字段的数据,那么其他没有传的字段的数据都会置空了。
PUT /test1/type/1
{
"name":"imperfect123"
}

我们可以看到这里的age就不见了。
使用POST来修改文档
POST /test1/_doc/1/_update
{
"doc":{
"name":"法外狂徒张三"
}
}

你看这样子就只更新了文档中的name字段了。
删除索引
DELETE test2
然后我们来看一下test2这个索引就被删除了。
通过DELETE命令可以实现删除的是索引还是删除文档记录。
所以ES推荐我们使用RESTFUL风格。
3、文档的基本操作
添加一条数据
PUT /imperfect/user/1
{
"name":"sam",
"age":"26",
"desc":"一顿操作猛如虎,一看工资2500",
"tags":["技术宅","温暖","直男"]
}

我们再新建一些初始化数据以供后面测试使用
PUT /imperfect/user/2
{
"name":"张三",
"age":"3",
"desc":"法外狂徒",
"tags":["交友","旅游","渣男"]
}
PUT /imperfect/user/3
{
"name":"李四",
"age":"23",
"desc":"随便",
"tags":["靓女","美丽"]
}

获取数据
获取目标索引中的具体一条数据
GET /imperfect/user/1
PUT更新数据
PUT如果不传递值的话,其他数据会被覆盖置空
PUT /imperfect/user/3
{
"name":"李四",
"age":"23",
"desc":"随便",
"tags":["靓女","美丽"]
}
POST更新数据(推荐使用这种更新方式)
只修改有传递的参数,注意这里最后有个_update
POST /imperfect/user/1/_update
{
"doc":{
"name":"imperfect123"
}
}
简单的通过条件查询
GET /imperfect/user/_search?q=name:imperfect123
含义:查询imperfect表中字段name=imperfect123的数据
注意这里_search?q的q是query的意思
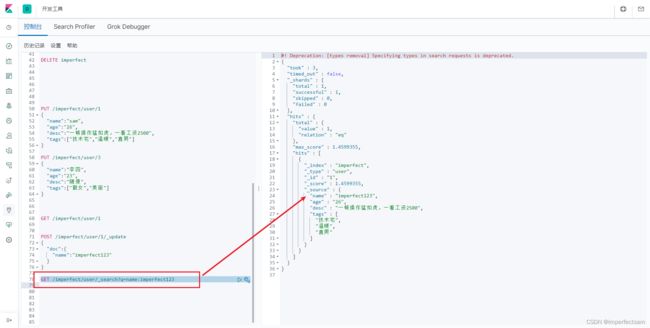
模糊查询
GET /imperfect/user/_search
{
"query": {
"match": {
"name": "张"
}
}
}

从右边的返回参数我们可以看到hits这个字段里面包括索引和文档的信息,查询结果的总数以及查询出来具体的文档。
查询结果过滤
GET /imperfect/user/_search
{
"query": {
"match": {
"name": "张"
}
},
"_source": ["name"]
}

我们可以看到这里有个_source其实就是筛选出来你想查询的字段。
排序
这里为了构建排序的场景,我们先重新构建一下环境
PUT /imperfect/user/1
{
"name":"sam",
"age":26,
"desc":"一顿操作猛如虎,一看工资2500",
"tags":["技术宅","温暖","直男"]
}
PUT /imperfect/user/2
{
"name":"张三",
"age":32,
"desc":"一顿操作猛如虎,一看工资35455",
"tags":["冷酷","温暖","直男"]
}
PUT /imperfect/user/3
{
"name":"李四",
"age":23,
"desc":"随便",
"tags":["靓女","美丽"]
}
PUT /imperfect/user/4
{
"name":"李五",
"age":32,
"desc":"随便",
"tags":["靓女","美丽"]
}
注意我们这里的age类型是long类型
GET /imperfect/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"sort": [
{
"age":{
"order": "desc"
}
}
]
}
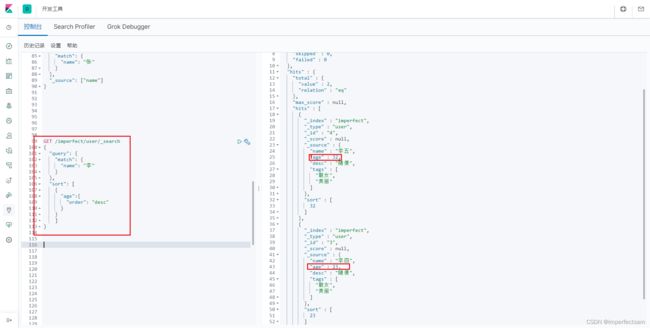
分页查询
GET /imperfect/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"sort": [
{
"age":{
"order": "desc"
}
}
],
"from":0,
"size":1
}
这里的from可以这样理解:
from:从哪里开始
size:返回多少条数据
多条件符合查询
GET /imperfect/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "李四"
}
},
{
"match": {
"age": 32
}
}
]
}
}
}
这里must指定了必须满足这两个条件来进行查询
多条件不符合查询
#这里我们来查询出imperfect索引中age不等于26的文档
GET imperfect/user/_search
{
"query":{
"bool":{
"must_not":[
{
"match": {
"age": "26"
}
}
]
}
}
}
filter筛选器
#filter,查询出来name为李的,并且年龄大于10且小于30的
#gt:大于等于
#lte:小于等于
GET imperfect/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "李"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
}
}
}
匹配多条件进行查询
GET imperfect/user/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
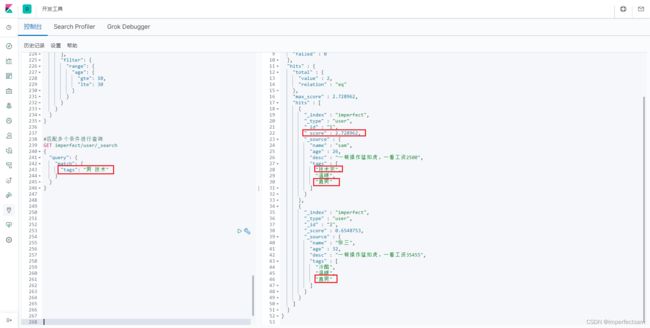
这里我们可以通过空格隔开,相当于or,有一个可以注意到的点就是这里查询出来的两条数据的score即权重有所不同,我们这里可以看出查询出来的第一条数据技术和男这两个词都匹配了所以权重更加高,而第二条数据只匹配到男,所以权重较低。
keyword类型和text类型
首先我们来构建一个索引来进行测试
构建这条索引的数据类型规则
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
然后我们来创建一些测试的数据
PUT testdb/_doc/1
{
"name":"李方安生说JAVA name",
"desc":"李方安生说JAVA desc"
}
PUT testdb/_doc/2
{
"name":"李方安生说JAVA name2",
"desc":"李方安生说JAVA desc2"
}
然后我们analyze解析看一下
GET _analyze
{
"analyzer": "keyword",
"text": "李方安生说JAVA"
}
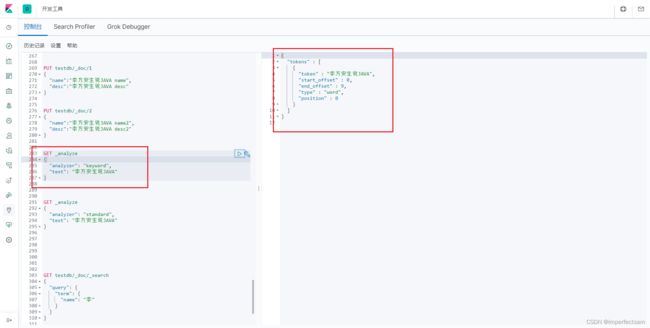
如果我们使用keyword去解析,可以看出来是不会被拆分的
试验:
GET _analyze
{
"analyzer": "standard",
"text": "李方安生说JAVA"
}
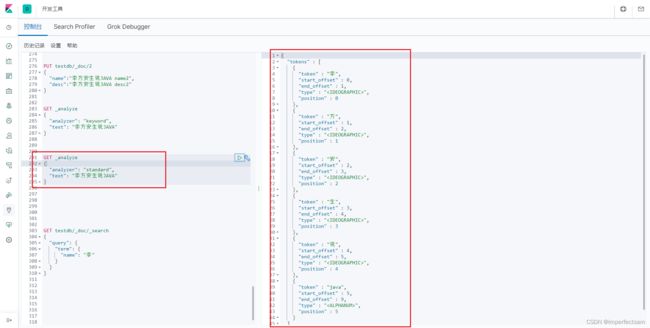
正常的解析是可以拆分出来的
GET testdb/_doc/_search
试验:
{
"query": {
"match": {
"name": "李方安生说JAVA"
}
}
}
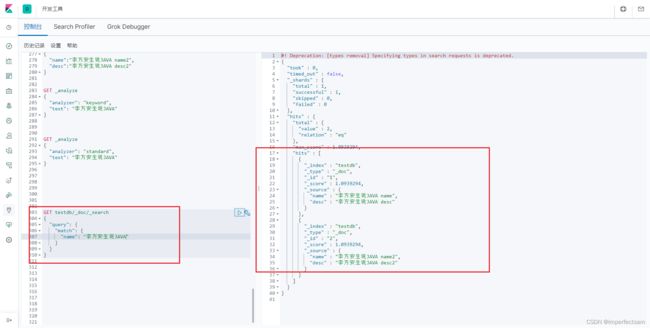
这里我们使用match即模糊查询进行测试,其中name的类型为text类型,即每一个字都可以拆分出来,这里我们查询‘李方安生说JAVA’的时候,可以见到第一条数据和第二条数据都满足这个条件。
试验:
GET testdb/_doc/_search
{
"query": {
"match": {
"desc": "李方安生说JAVA"
}
}
}

请注意,这里我们查询的是desc这个字段,这个字段是keyword类型的,对于字段整体不可拆分,所以就算我们这里进行模糊查询的时候,也是不能够找到任何一条数据。
试验:
GET testdb/_doc/_search
{
"query": {
"match": {
"desc": "李方安生说JAVA desc2"
}
}
}
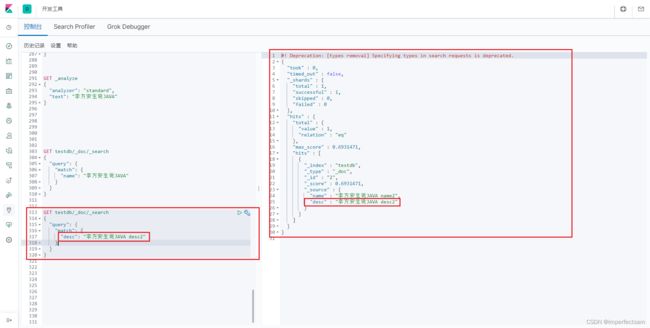
当我们字段整体都匹配的时候,才能够查询到出来
term精确查询
同样地我们先来构建一下基础的环境
PUT /member/info/1
{
"name":"郭飞",
"age":"20"
}
PUT /member/info/2
{
"name":"郭锦泳",
"age":"35"
}
PUT /member/info/3
{
"name":"郭碧婷",
"age":"55"
}
PUT /member/info/4
{
"name":"李碧婷",
"age":"34"
}

GET /member/
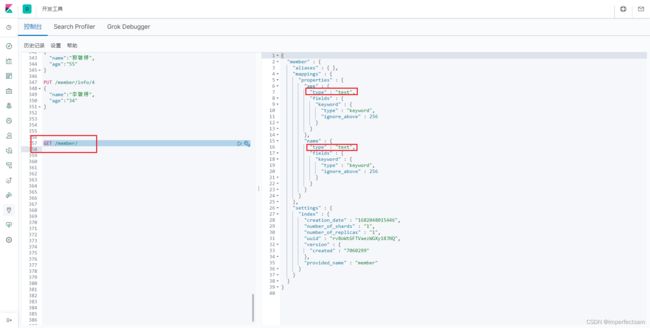
这里我们插入了数据后,默认的类型两个都是text。
试验:
通过term单个字来进行精确查询
GET /member/info/_search
{
"query": {
"term": {
"name": "郭"
}
}
}

我们可以看到凡是有郭字的三条数据都能够查询出来。
试验:
通过多个字进行term查询
GET /member/info/_search
{
"query": {
"term": {
"name": "郭飞"
}
}
}

我们会发现查询出来没有数据,从概念上说,term属于精确查询,只能查单个词。
如果需要通过term来匹配多个词,可以使用terms实现
试验
GET /member/info/_search
{
"query": {
"terms": {
"name": ["郭","飞"]
}
}
}

咦,从这里的查询结果我们可以看出,这里居然能查出三条数据出来。因为terms里的[ ] 多个搜索词之间是or(或者)关系,只要满足其中一个词即可。
如果我们想要同时满足两个词精确匹配的话,就得使用bool的must来做。
试验:
GET /member/info/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": "郭"
}
},
{
"term": {
"name": "飞"
}
}
]
}
}
}

高亮查询
试验:
GET imperfect/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"highlight": {
"fields": {
"name":{}
}
}
}

这里我们指定了name这个字段,他都给我们高亮了
同样地,我们也可以自定义高亮条件
GET imperfect/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "p>",
"fields": {
"name":{}
}
}
}
八、集成SpringBoot
官方文档
1、初始化SpringBoot项目
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.2.5.RELEASEversion>
<relativePath/>
parent>
<groupId>com.imperfectgroupId>
<artifactId>imperfect-es-apiartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>imperfect-es-apiname>
<description>Demo project for Spring Bootdescription>
<properties>
<java.version>1.8java.version>
//注意这里我们需要指定一下elasticsearch的版本号,因为在SpringBoot2.2.5的版本当中,elasticsearch的版本相对比较旧。以免后续出现不必要错误。
<elasticsearch.version>7.6.2elasticsearch.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
exclude>
excludes>
configuration>
plugin>
plugins>
build>
project>
然后根据官方文档的介绍,这里我们初始化的时候需要构建一个config配置类
com/imperfect/imperfectesapi/config
package com.imperfect.imperfectesapi.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author : Imperfect(lxm)
* @Des:
* @date : 2023/4/24 17:28
*/
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")));
return client;
}
}
源码分析
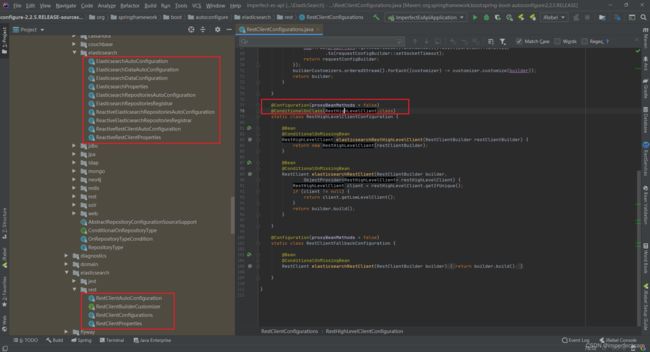 @ConditionalOnClass注解的作用是当项目中存在某个类时才会使标有该注解的类或方法生效。
@ConditionalOnClass注解的作用是当项目中存在某个类时才会使标有该注解的类或方法生效。
2、编写索引API
(1)创建索引
创建索引
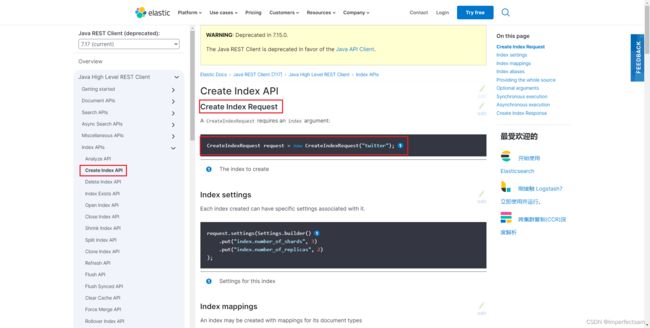
发送请求
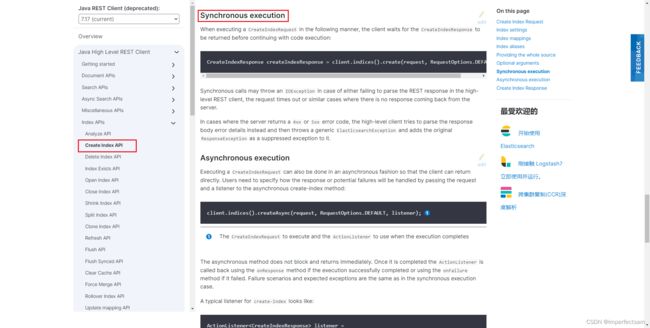
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("twitter");
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
测试结果:
(2)判断索引是否存在
其实这里对于索引api的操作,我们都可以通过参考官方api说明文档。
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 10:42
* @Des 判断索引是否存在
* @Param []
* @Return void
*/
@Test
void testGetIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("twitter");
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
(3)删除索引
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 10:50
* @Des 测试删除索引
* @Param []
* @Return void
*/
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("twitter");
AcknowledgedResponse deleteIndexResponse = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(deleteIndexResponse.isAcknowledged());
}
3、编写文档API
(1)构建编写文档需要用到的环境
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.62version>
dependency>
这里我们因为涉及到对象与json之间的转换,所以需要用到alibaba的fastjson插件。
(2)编写API
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 11:16
* @Des 新增文档
* @Param []
* @Return void
*/
@Test
void testAddDocument() throws IOException {
//创建对象
User user = new User("imperfect", 3);
//创建请求
IndexRequest request = new IndexRequest("document_index");
//规则 put/document_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
//将我们的数据放入请求 json
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求
IndexResponse index = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(index.toString());
System.out.println(index.status());
}
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 14:45
* @Des 判断文档是否存在
* @Param []
* @Return void
*/
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("document_index", "1");
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 14:45
* @Des 获取某一列文档
* @Param []
* @Return void
*/
@Test
void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("document_index", "1");
GetResponse documentFields = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//打印文档的内容
System.out.println(documentFields.getSourceAsString());
}
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 14:44
* @Des 更新文档
* @Param []
* @Return void
*/
@Test
void testUpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("document_index", "1");
updateRequest.timeout("1s");
User user = new User("imperfect", 18);
updateRequest.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 14:44
* @Des 删除文档
* @Param []
* @Return void
*/
@Test
void testDeleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("document_index", "1");
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 14:44
* @Des 批量新建文档
* @Param []
* @Return void
*/
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
User user = new User("imperfect" + i, i);
userList.add(user);
}
for (int i = 0; i < 10; i++) {
bulkRequest.add(
new IndexRequest("document_index")
.id("" + (i + 1))
.source(JSON.toJSONString(userList.get(i)), XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures());
}
/**
* @Author Imperfect(lxm)
* @Date 2023/4/25 14:43
* @Des 根据指定的条件查询文档
* @Param []
* @Return void
*/
@Test
public void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("document_index");
//构建搜索条件
SearchSourceBuilder sourceBuilde = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "imperfect0");
sourceBuilde.query(termQueryBuilder);
sourceBuilde.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.sourjce(sourceBuilde);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits().getHits()));
}
九、仿京东搜索
最终的效果:
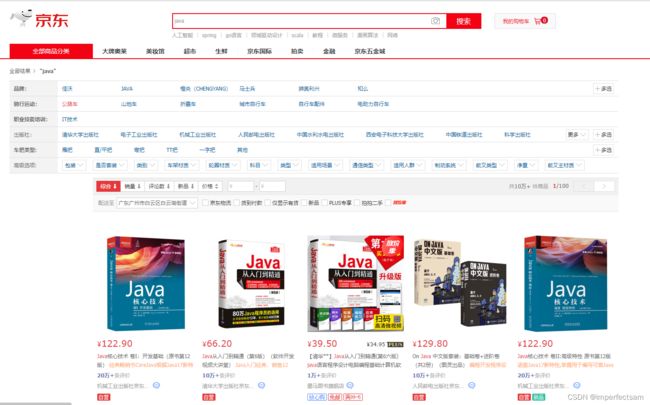
模仿京东商城
整体项目结构
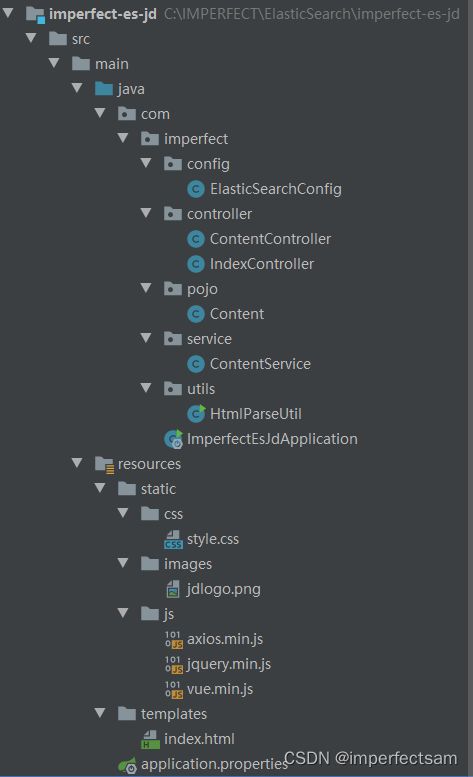
application.properties
server.port=6188
#关闭thymeleaf的缓存
spring.thymeleaf.cache=false
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.5.5version>
<relativePath/>
parent>
<groupId>com.imperfectgroupId>
<artifactId>imperfect-es-jdartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>imperfect-es-jdname>
<description>Demo project for Spring Bootdescription>
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.6.2elasticsearch.version>
properties>
<dependencies>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.10.2version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.62version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
exclude>
excludes>
configuration>
plugin>
plugins>
build>
project>
com/imperfect/config/ElasticSearchConfig.java
package com.imperfect.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author : Imperfect(lxm)
* @Des:
* @date : 2023/4/26 16:15
*/
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")));
return client;
}
}
com/imperfect/utils/HtmlParseUtil.java
```java
package com.imperfect.utils;
import com.imperfect.pojo.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
/**
* @author : Imperfect(lxm)
* @Des:
* @date : 2023/4/26 15:11
*/
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
new HtmlParseUtil().parseJD("心理学").forEach(System.out::println);
}
public List<Content> parseJD(String keywords) throws IOException {
//获取请求
String url="https://search.jd.com/Search?keyword="+keywords;
//解析网页 (Jsoup返回Document就是浏览器Document对象)
Document document = Jsoup.parse(new URL(url), 30000);
//所有你在js中可以使用的方法,这里都能用
Element element = document.getElementById("J_goodsList");
//拿到标签后,获取所有的li元素
Elements elements = element.getElementsByTag("li");
ArrayList arrayList=new ArrayList<Content>();
for (Element element1 : elements) {
Content content=new Content();
//关于这种图片特别多的网站都是延迟加载的
String img = element1.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price=element1.getElementsByClass("p-price").eq(0).text();
String title=element1.getElementsByClass("p-name").eq(0).text();
content.setImg(img);
content.setPrice(price);
content.setTitle(title);
arrayList.add(content);
}
return arrayList;
}
}
com/imperfect/pojo/Content.java
package com.imperfect.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author : Imperfect(lxm)
* @Des:
* @date : 2023/4/26 16:06
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Content {
private String title;
private String img;
private String price;
}
com/imperfect/service/ContentService.java
package com.imperfect.service;
import com.alibaba.fastjson.JSON;
import com.imperfect.pojo.Content;
import com.imperfect.utils.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.naming.directory.SearchResult;
import java.awt.font.TextMeasurer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* @author : Imperfect(lxm)
* @Des:
* @date : 2023/4/26 16:16
*/
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
//把解析出来的数据放入到es数据库当中
public Boolean parseContent(String keywords) throws IOException {
List<Content> contents = new HtmlParseUtil().parseJD(keywords);
//把查询到的数据插入到es当中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
bulkRequest.add(new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
//2、获取这些数据
public List<Map<String, Object>> searchPage(String keyword, int pageNo, int pageSize) throws IOException {
if (pageNo <= 1) {
pageNo = 1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
list.add(documentFields.getSourceAsMap());
}
return list;
}
//2、条件搜索高亮
public List<Map<String, Object>> searchhighLightPage(String keyword, int pageNo, int pageSize) throws IOException {
if (pageNo <= 1) {
pageNo = 1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮配置
HighlightBuilder highlightBuilder=new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.preTags("");
highlightBuilder.postTags("");
highlightBuilder.requireFieldMatch(false);
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
//解析高亮的字段
Map<String, HighlightField> highlightFields = documentFields.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String, Object> sourceAsMap = documentFields.getSourceAsMap();
if(title!=null){
Text[] fragments = title.fragments();
String newTitle="";
for (Text text : fragments) {
newTitle+=text;
}
sourceAsMap.put("title",newTitle);//高亮字段替换原来的内容即可
}
list.add(documentFields.getSourceAsMap());
}
return list;
}
}
com/imperfect/controller/ContentController.java
package com.imperfect.controller;
import com.imperfect.service.ContentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
/**
* @author : Imperfect(lxm)
* @Des:
* @date : 2023/4/26 16:27
*/
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyword}")
public Boolean parse(@PathVariable("keyword") String keyword) throws IOException {
return contentService.parseContent(keyword);
}
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String, Object>> search(
@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
return contentService.searchhighLightPage(keyword, pageNo, pageSize);
}
}
com/imperfect/controller/IndexController.java
package com.imperfect.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
/**
* @author : Imperfect(lxm)
* @Des:
* @date : 2023/4/26 15:03
*/
@Controller
public class IndexController {
@GetMapping({"/","/index"})
public String index(){
return "index";
}
}
com/imperfect/ImperfectEsJdApplication.java
package com.imperfect;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ImperfectEsJdApplication {
public static void main(String[] args) {
SpringApplication.run(ImperfectEsJdApplication.class, args);
}
}
前端文件:
链接: https://pan.baidu.com/s/1amgEZeh3bgDRVCWmZjKRHA?pwd=2255 提取码: 2255 复制这段内容后打开百度网盘手机App,操作更方便哦
接下来我们启动一下服务
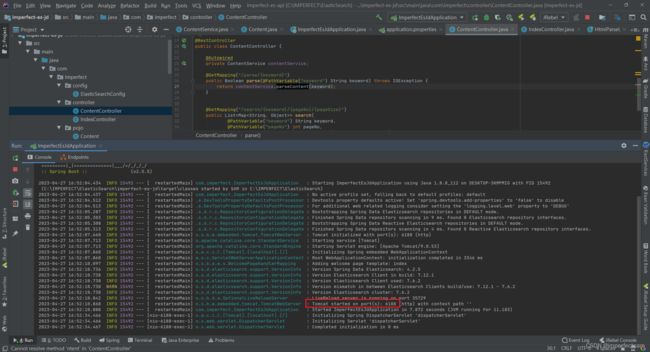
然后我们来玩耍一下吧♀️ ♂️♀️ ♂️

演示效果:
道谢文献:时间序列数据库的秘密 (2)——索引