Elasticsearch专栏-3.es基本用法-基础api
es基本用法-基础api
-
- 索引index增删改查
-
- 增
- 删
- 改
- 查
- 文档doc增删改查
-
- 增
-
- 方式1:PUT
- 方式2:POST
- 删
- 改
-
- 方式1:_doc
- 方式2:_update
- 查
- 批量操作bulk
-
- 同一索引
- 不同索引
- 官网数据导入
索引index增删改查
在es7以后,已经不存在type,所以直接创建索引即可。以es_index_test举例。演示用kibana,左侧为api,右侧为结果。
增
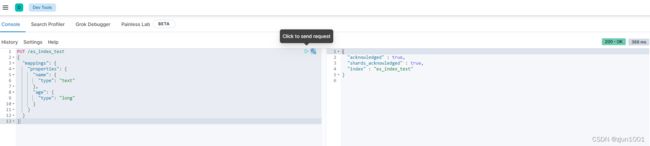
PUT /es_index_test
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
}
}
}
}
删
DELETE /es_index_test

改
mappings一旦创建,其字段类型就不能再被修改。对于需要修改字段的场景,一般都是新建新的mapping,把原有数据拷贝过来。
字段虽然不能再被修改,但可以新增新的字段。
查
GET /es_index_test

基于第一篇讲过的es数据类型,这里贴上一份字段类型更为丰富的index,仅供参考。
这里面涉及到的类型有keyword、text、long、float、date、子对象。其中address字段有两种数据类型,orders包含子对象。
PUT /es_index_complex
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "long"
},
"content": {
"type": "text"
},
"address": {
"type": "text",
"fields": {
"keyw": {
"type": "keyword"
}
}
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"orders": {
"properties": {
"id": {
"type": "keyword"
},
"money": {
"type": "float"
}
}
}
}
}
}
文档doc增删改查
增
文档doc的新增有put和post两种方式,它们各自又有_create和_doc两种方式,相当于有两大类,四小类的新增方式。不同方式使用方法,体现在要不要带上id以及数据状态。如下分别举例:
方式1:PUT
(1) _create、不带id。创建失败。
PUT /es_index_test/_create
{
"name": "zhangsan",
"age": 20
}

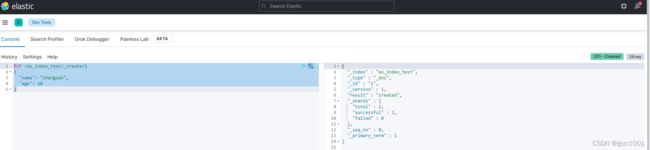
(2) _create、带id。创建成功,返回结果是create。
PUT /es_index_test/_create/1
{
"name": "zhangsan",
"age": 20
}
(3) _create、带相同id。创建失败。

(4) _doc、不带id。创建失败。
PUT /es_index_test/_doc/
{
"name": "lisi",
"age": 30
}

(5) _doc、带id。创建成功,返回结果是create。
PUT /es_index_test/_doc/2
{
"name": "lisi",
"age": 30
}

(6) _doc、带相同id。创建成功,返回结果是update。

总结:
1.在put模式下,无论使用_create还是_doc,都必须带上id。否则创建失败。
2.使用_create方法时,如果id相同,创建失败。
3.使用_doc方法时,如果id相同,创建不会失败,此时是对数据做了update。
4.虽然上述创建过程很绕人和繁琐,但本质还是一样,即:不会存在两份数据拥有相同id。这就是mysql唯一索引概念。
方式2:POST
(1) _create、不带id。创建失败。
POST /es_index_test/_create
{
"name": "zhangsan",
"age": 40
}

(2) _create、带id。创建成功,返回结果是create。
POST /es_index_test/_create/3
{
"name": "zhangsan",
"age": 40
}

(3) _create、带相同id。创建失败。

(4) _doc、不带id。创建成功,返回结果是create,id自动生成。
POST /es_index_test/_doc/
{
"name": "zhangsan",
"age": 40
}

(5) _doc、带id。创建成功,返回结果是create。
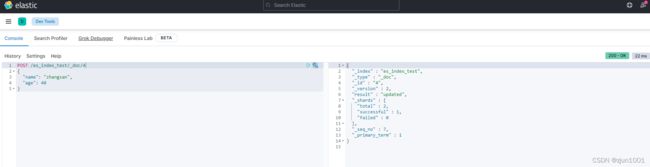
POST /es_index_test/_doc/4
{
"name": "zhangsan",
"age": 40
}

(6) _doc、带相同id。创建成功,返回结果是update。
总结:
1._create方式下,和put处理方式一模一样。id必须带上,且相同id添加会报错。
2._doc方式下,id可以带也可以不带。区别是,带id,以后提交都是更新。不带id,每次提交都是新增。
3.post和put创建文档的本质是一样的,即id的唯一性。可以存在两份同样数据,但不会存在id相同的两份数据。
补充:以上4种方式那种合适,看你喜欢。
删
DELETE /es_index_test/_doc/4

改
也有两种方法,_doc和_update。直接带上要修改的数据即可。
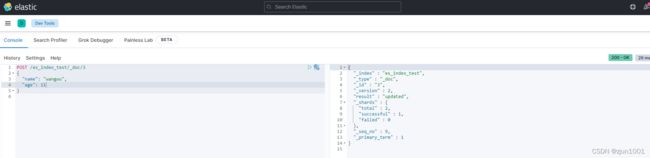
方式1:_doc
POST /es_index_test/_doc/3
{
"name": "wangwu",
"age": 11
}
方式2:_update
POST /es_index_test/_update/3
{
"doc": {
"name":"lisi001"
}
}

查
(1)查询单个文档
GET /es_index_test/_doc/2

(2)查看所有文档
GET /es_index_test/_search
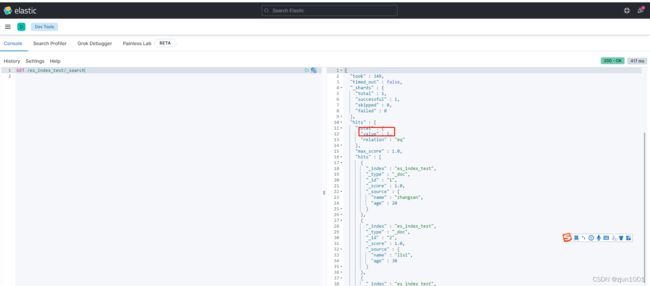
批量操作bulk
在mysql中,批量操作通常指的是批量插入。而es的批量操作适用性更宽,可以对同一个索引进行批量插入、修改等,也可以对不同索引同时进行不同的批量操作。批量操作涉及的方法有:create、index、update、delete。相关说明如下:
| 方法 | 说明 |
|---|---|
| create | 如果文档不存在就创建,但如果文档存在就返回错误 |
| index | 如果文档不存在就创建,如果文档存在就更新 |
| update | 更新一个文档,如果文档不存在就返回错误 |
| delete | 删除一个文档,如果要删除的文档id不存在,就返回错误 |
另外,在批量操作过程中,某一个操作失败,是不会影响其他文档的操作的。而bulk对JSON串的有着严格的要求。每个JSON串不能换行,只能放在同一行。
同一索引
- 批量新增
POST /es_index_test/_bulk
{"index":{"_id":"10"}}
{"name":"lisi001","age":30}
{"index":{"_id":"11"}}
{"name":"lisi002","age":31}

- 批量修改、删除
POST /es_index_test/_bulk
{"update":{"_id":"10"}}
{"doc": {"name": "admin-02", "age":30}}
{"delete":{"_id":"11"}}

不同索引
POST /_bulk
{"index": {"_index": "es_index_test", "_id": "10"}}
{"name":"lisi002","age":30}
{"index": {"_index": "es_index_test_02", "_id": "123"}}
{"name":"lisi002","age":30}

官网数据导入
为了学习和测试es,官网提供了一批数据。现在我们将其导入,供后面查询使用。
数据地址:https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
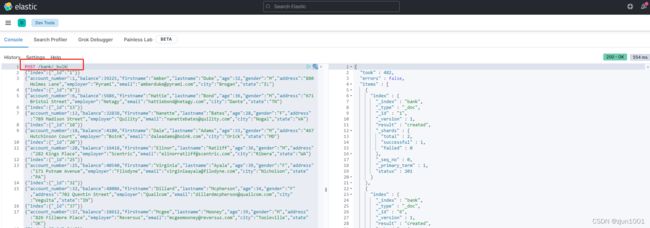
打开后,数据格式如下,我们可以看到这些数据就是批量导入使用的格式。

之后,我们将数据拷贝到kibana中,执行即可。这里我指定创建索引为bank。
插入完成后,我们来看下索引bank的信息

从这里我们可以看到,没有提前创建索引情况下,在插入数据时,es会自动帮我们创建好索引。在第一章中说过,文本是有text和keyword两种数据类型。这里也可以看出,默认情况下,es会为文本字段同时创建text和keyword两种类型。后续该字段就支持分词和不分词查询了。
另外,setting字段包含了索引的分片信息。我们创建索引时候,也可以自己指定。
最后,我们在查询下这次导入数据的总量。

数据总量显示1000,和原始数据总量一致。