Python自学笔记——基础篇
本笔记参考视频为:https://www.bilibili.com/video/BV1ex411x7Em?p=101,有兴趣的可以直接移步B站
Python编程
- Sec.1 第一个Python程序
-
- 1 第一个HelloPython程序
-
- 1.1 Python源程序的基本概念
- 1.2 演练步骤
- 1.3 演练扩展——认识错误(BUG)
- 2 Python 2.x 与 3.x 版本简介
- 3 执行Python程序的三种方式
-
- 3.1 解释器python/python3
- 3.2 交互式运行Python程序
- 3.3 IDE运行Python程序——Pycharm
- 4 注释
- Sec.2 算数运算符
-
- 1 算数运算符
- 2 算数运算符的优先级
- Sec.3 程序执行原理(科普)
-
- 1 计算机中的三大件
- 2 程序的执行原理
-
- 2.1 Python的执行原理
- Sec.4 变量的基本使用
-
- 1 变量定义及使用
- 2 变量的类型
-
- 2.1 变量类型演练——个人信息
- 2.2 变量的类型
- 2.3 不同类型变量之间的计算
- 2.4 变量的输入
-
- 2.4.1 input函数实现键盘输入
- 2.4.2 类型转换函数
- 2.4.3 变量输入演练——买苹果增强版
- 2.5 变量的格式化输出
- 3 变量的命名
-
- 3.1 标识符和关键字
-
- 3.1.1 标识符
- 3.1.2 关键字
- 3.2 变量的命名规则
- Sec.5 判断(if)语句
-
- 1 开发中的应用场景
- 2 if 语句体验
-
- 2.1 if 判断语句基本语法
- 2.2 判断语句训练——判断年龄
- 2.3 else 处理条件不满足的情况
- 2.4 判断语句演练——判断年龄改进
- 3 逻辑运算
-
- 3.1 逻辑运算符:and
- 3.2 逻辑运算符:or
- 3.3 逻辑运算符:not
- 3.4 逻辑运算演练
-
- 3.4.1 判断年龄
- 3.4.2 考试成绩
- 3.4.3 判断是否是本公司员工
- 4 if 语句进阶
-
- 4.1 elif
- 4.2 if 的嵌套
- 5 综合应用——石头剪刀布
-
- 5.1 基础代码实现
- 5.2 随机数的处理
- Sec. 6 循环
-
- 1 程序的三大流程
- 2 while循环基本使用
-
- 2.1 while语句基本语法
- 2.2 Python中的赋值运算符
- 2.3 Python中的计数方法
- 2.4 循环计算
- 3 break 和 continue
- 4 while 循环嵌套
-
- 4.1 循环嵌套
- 4.2 循环嵌套演练
-
- 4.2.1 用嵌套打印小星星 + print换行与不换行
- 4.2.2 用嵌套打印九九乘法表+转义字符
- Sec. 7 函数基础
-
- 1 函数的快速体验
- 2 函数基本使用
-
- 2.1 函数的定义
- 2.2 函数调用
- 2.3 第一个函数演练
- 2.4 函数的文档注释(一)
- 3 函数的参数
-
- 3.1 函数参数的使用
- 3.2 形参和实参
- 4 函数的返回值
- 5 函数的嵌套调用
-
- 5.1 函数嵌套演练
- 5.2 函数的文档注释(二)
- 6 使用模块中的函数
-
- 6.1 第一个模块体验
- 6.2 模块名也是一个标识符
- 6.3 Pyc 文件
- Sec. 8 高级变量类型
-
- 1 列表
-
- 1.1 列表的定义
- 1.2 列表的常用操作
- 1.3 循环遍历
- 2 元组
-
- 2.1 元组的定义
- 2.2 元组的常用操作
- 2.3 循环遍历
- 2.4 应用场景
- 2.5 元组和列表之间的转换
- 3 字典
-
- 3.1 字典的定义
- 3.2 字典的基本操作
- 3.3 字典常用操作
- 3.4 循环遍历
- 3.5 字典和列表组合的应用场景
- 4 字符串
-
- 4.1 字符串的定义
- 4.2 字符串的常用操作
-
- 4.2.1 字符串判断类型方法 - 9个
- 4.2.2 字符串查找和替换方法 - 7个
- 4.2.3 字符串文本对齐方法 - 3个
- 4.2.4 字符串去除空白字符方法 - 3个
- 4.2.5 字符串拆分和连接方法 - 5个
- 4.3 字符串的切片
- 5 公共方法
-
- 5.1 Python内置函数
- 5.2 切片
- 5.3 运算符
- 5.4 完整的for循环语法
- Sec. 9 综合应用 —— 名片管理系统
- Sec. 10 变量进阶
-
- 1 变量的引用
-
- 1.1 引用的概念
- 1.2 函数的参数和返回值的传递
- 2 可变和不可变类型
- 3 局部变量和全局变量
-
- 3.1 局部变量
- 3.2 全局变量
-
- 3.2.1 函数不能直接修改全局变量的引用
- 3.2.2 在函数内部修改全局变量的方法
- 3.2.3 全局变量定义的位置
- 3.2.4 全局变量命名的建议
- Sec. 11 函数进阶
-
- 1. 函数参数和返回值的作用
- 2. 函数的返回值 进阶
-
- 2.1 面试题——交换两个数字
- 3. 函数的参数 进阶
-
- 3.1 不可变和可变参数
- 3.2 面试题 —— +=
- 3.3 缺省参数
-
- 3.3.1 指定函数的缺省参数
- 3.3.2 缺省函数的注意事项
- 3.4 多值参数
-
- 3.4.1 多值参数案例——计算任意多个数字的和
- 3.4.2 元组和字典的拆包
- 4 函数的递归
-
- 4.1 函数递归的特点
- 4.2 递归程序代码执行流程图
- 4.3 递归案例——计算数字累加
Sec.1 第一个Python程序
1 第一个HelloPython程序
1.1 Python源程序的基本概念
- 本质是一个特殊格式的文本文件,可以使用任意文本编辑软件进行开发
- 文件扩展名通常都是.py
1.2 演练步骤
print("hello python")
print("hello world")
结果:

1.3 演练扩展——认识错误(BUG)
常见错误
-
函数的名字写错
报错:NameError: name ‘XXX’ is not defined
-
将多条
print写在一行报错:SyntaxError: invalid syntax。错误位置下有^标识
注意:Python中每行代码只负责完成一个动作 -
缩进错误
报错:IdentationError: unexpected indent
注意:Python是一个格式非常严格的程序设计语言
要求:每行代码前面都不要增加空格 -
python2.x默认不支持中文
2 Python 2.x 与 3.x 版本简介
3 执行Python程序的三种方式
3.1 解释器python/python3
除了上述解释器,还有其他解释器
- CPython——官方版本的C语言实现
- Jython——可以运行在Java平台
- ItonPython——可以运行在.NET和Mono平台
- PyPy——Python实现的,支持JIT的即时编译
3.2 交互式运行Python程序
- 所谓交互式,就是在终端中直接运行解释器,而不输入要执行的文件名
- 在Python的shell中直接输入Python的代码,会立即看到程序执行结果
1)ubuntu原生的bash或者是windows的cmd
- 打开方式:直接输入
python - 退出(Linux):输入
exit()或者热键ctrl+D
2)运行交互式代码时比较常用的shell:IPython
特点:
- 支持自动补全
- 自动缩进
- 支持
bash shell命令(输入linux终端命令) - 内置很多有用的功能和函数
打开方式:在ubuntu系统中,终端中输入ipython
退出方式:输入exit或者热键ctrl+D
3.3 IDE运行Python程序——Pycharm
1)集成开发环境 (Integrated Development Environment, IDE)——集成了软件开发需要的所有工具,一般包括:
- 图形用户界面
- 代码编辑器(支持代码补全/自动缩进)
- 编译器/解释器
- 调试器(断点/单步执行)
- ……
2)Pycharm介绍
4 注释
- 单行注释:某一行前面加
#
为了保证代码的优雅,#后面应该加一个空格,再写注释信息 - 多行注释:将需要注释的段落,开始和结束各用三个引号引起来
"""
关于代码规范
Python官方提供一系列PEP文档,其中第8篇针对代码格式给出的建议,也就是俗称的PEP8
官方有英文版,谷歌有对应的中文文档
Sec.2 算数运算符
1 算数运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 10+20=30 |
| - | 减 | 10-29=10 |
| * | 乘 | 1*20=200 |
| / | 除 | 10/20=0.5 |
| // | 取整数 | 返回除法的整数部分 例:9//2=4 |
| % | 取余数 | 返回除法的余数 例:9%4=1 |
| ** | 幂 | 次方、乘方 例:2**3=8 |
- 在Python中,
*运算符还能用于字符串中,计算结果就是字符串重复指定次数的结果
2 算数运算符的优先级
和数学中保持一致
幂运算>乘除取整取余>加减
Sec.3 程序执行原理(科普)
1 计算机中的三大件
计算机中包含较多的硬件,但是一个程序要运行,有三个核心的硬件,分别是:
- CPU
中央处理器,是一块超大规模的集成电路
负责处理数据/计算 - 内存
临时存储数据(断电之后,数据会消失)
速度快
空间小
价格高 - 硬盘
永久存储数据
速度慢
空间大
价格便宜
2 程序的执行原理
- 程序运行之前,程序是保存在硬盘中的
- 当运行一个程序时
操作系统会首先让CPU把程序复制到内存中
CPU执行内存中的代码

2.1 Python的执行原理

- 操作系统让CPU把Python解释器的程序复制到内存中
- CPU再把Python程序复制到内存中
- Python解释器根据规则,从上向下让CPU翻译Python程序
- CPU执行翻译完成的代码
Sec.4 变量的基本使用
1 变量定义及使用
a=1
示例:超市买苹果
# 苹果单价
price = 8.5
# 苹果数量
weight = 7.5
# 苹果价格
money = price * weight
print(money)
2 变量的类型
在内存中创建一个变量,会包括:
- 变量的名称
- 变量保存的数据
- 变量存储数据的类型
- 变量的地址(标示)
2.1 变量类型演练——个人信息
需求
- 定义变量保存小明的个人信息
- 姓名:小明
- 年龄:18岁
- 性别:男
- 身高:1.75
- 体重:75.0公斤
代码
name = "小明"
age = 18
gender = True
height = 1.75
weight = 75.0
在Pycharm中,启用调试会显示出中间变量的类型(在VScode里面好像不行),上面的各个变量对应的类型分别是:
str:字符串
int:整型
bool:布尔类型(True/False)
float:浮点型(小数)
总结: 在Python中,定义变量是不需要指定变量的类型的,在运行的时候,Python解释器会根据赋值语句等号右侧的数据自动推导出变量中保存的数据的准确类型
2.2 变量的类型
数据类型可以分为数字型和非数字型
- 数字型
- 整形
int - 浮点型
float - 布尔型
bool - 复数型
complex- 主要用于科学计算,例如:平面场问题,波动问题,电容电感问题
- 整形
- 非数字型
- 字符串
- 列表
- 元组
- 字典
使用type()函数可以查看一个变量中保存的数据类型(在ipython中使用)
在Python2.x中,整型可以分为
int和long(长整型),但是在Python3.x中不再区分
2.3 不同类型变量之间的计算
1)数字型变量之间可以直接计算
- 如果变量是
bool型,True为1,False为0
示例
i = 10
f = 10.5
b = True
print(i+f+b)
结果:
![]()
2)字符串变量之间使用+拼接字符串
示例:
firstname = "三"
lastname = "张"
name =lastname + firstname
print(name)
结果:
![]()
3)字符串变量可以和整数使用*重复拼接相同的字符串
示例:
firstname = "三"
lastname = "张"
name =lastname + firstname
print(name*10)
结果:

4)数字型变量 和 字符串 之间,不能进行其他计算
2.4 变量的输入
Python中获取用户在键盘上的输入信息,用到input()函数
2.4.1 input函数实现键盘输入
示例:
password = input("请输入银行密码:")
print(password)
print(type(password))
结果:
首先会出现:
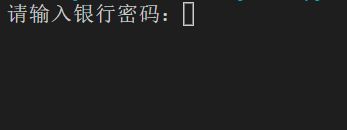
输入密码后,会出现:
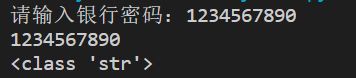
由此可见,输入的数据类型默认为字符串型
2.4.2 类型转换函数
上述input函数得到的输入默认都是字符串类型,但是用户也有需求输入整数或者小鼠类型
| 函数 | 说明 |
|---|---|
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
2.4.3 变量输入演练——买苹果增强版
需求
- 收银员输入 苹果的单价
- 收银员输入 购买苹果的重量
- 计算并输出付款金额
示例
# 苹果的单价
price = float(input("输入苹果的单价:"))
# 苹果的重量
weight = float(input("输入苹果的重量:"))
# 输出应该的价格
money = price * weight
print(money)
结果
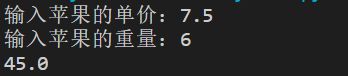
2.5 变量的格式化输出
如果希望输出文字信息的同时,一起输出数据,就需要使用到格式化操作符
%被成为格式化操作符,专门用于处理字符串中的格式
- 包含
%的字符串,被称为格式化字符串 %和不同的字符连用,不同类型的数据需要使用不同的格式化字符
| 格式化字符 | 含义 |
|---|---|
| %s | 字符串 |
| %d | 有符号十进制整数,%06d表示输出的整数显示位数,不足的地方使用0补全 |
| %f | 浮点数,%.02f表示小数点后只显示两位 |
| %% | 输出% |
语法格式
print("格式化字符串" % 变量1)
print("格式化字符串" % (变量1,变量2,变量3,……))
注意 :跟C++区分,Python用
%分开占位符和和变量,而不是,
格式化输出演练——基本练习
示例:
# 定义字符串变量name,输出 我的名字叫小明,请多多关照
name = "小明"
print("我的名字叫%s,请多多关照!" % name)
# 定义整数变量student_no,输出 我的学号是000001
num = 1
print("我的学号是:%06d" % num)
# 定义小数price、weight、money,输出 苹果单价9.00元/斤,购买了5.00斤,需要支付45.00元
price = 9.00
weight = 5.00
money = price * weight
print("苹果单价 %.02f 元 / 斤,购买了 %.02f 斤,需要支付 %.02f 元" % (price, weight, money))
# 定义一个小数scale,输出 数据比例是10.00%
scale = 0.1
print("数据比例是 %.02f%%" % (scale * 100))
结果:

3 变量的命名
3.1 标识符和关键字
3.1.1 标识符
标识符就是程序员定义的变量名、函数名
名字需要有见名知义的效果
- 标识符可以由字母、下划线和数字组成
- 不能以数字开头
- 不能与关键字重名
3.1.2 关键字
- 关键字就是在Python内部就已经使用的标识符
- 关键字具有特殊功能和含义
- 开发者不允许定义和关键字相同的名字的标识符
可以使用下图方法查看关键字

3.2 变量的命名规则
- 在定义变量时,为了保证代码格式,
=的左右应该各保留一个空格 - 在Python中,如果变量名需要两个或多个单词组成时,可以(Python开发者建议)
1.每个单词都使用小写字母
2. 单词与单词之间使用_下划线连接
驼峰命名法
- 小驼峰命名法
- 如:
firstName、lastName
- 如:
- 大驼峰命名法
- 如:
FirstName、LastName
- 如:
Sec.5 判断(if)语句
1 开发中的应用场景
判断语句又被称为“分支语句”
2 if 语句体验
2.1 if 判断语句基本语法
if 要判断的条件:
条件成立时,要做的事情
……
注意1 :if条件后面要跟
:冒号
注意2 :执行语句前面要有缩进
注意3 :Python中,缩进为一个Tab,或者四个Space
注意4 :Python中,Tab和空格不要混用
2.2 判断语句训练——判断年龄
示例
# 定义一个年龄
age = 18
#判断
if age >= 18:
print("可以进网吧嗨皮φ(゜▽゜*)♪")
注意 :if 语句及下方缩进的部分应该看成一个完整的代码块
2.3 else 处理条件不满足的情况
语法:
if 要判断的条件:
条件成立时,要做的事情
……
else:
条件不成立时,要做的事情
……
2.4 判断语句演练——判断年龄改进
示例:
# 定义一个年龄
age = 18
#判断
if age >= 18:
print("可以进网吧嗨皮φ(゜▽゜*)♪")
else:
print("回家呆着去吧您内(╯▔皿▔)╯")
3 逻辑运算
Python中的逻辑运算符包括: 与and / 或or / 非not 三种
3.1 逻辑运算符:and
条件1 and 条件2
- 两个条件都满足,返回
True - 只要有一个条件不满足,返回
False
3.2 逻辑运算符:or
条件1 or 条件2
- 两个条件只要有一个满足,返回
True - 两个条件都不满足,返回
False
3.3 逻辑运算符:not
not 条件
- 取反操作
3.4 逻辑运算演练
3.4.1 判断年龄
示例
# 定义一个年龄
age = 121
#判断
if age >= 0 and age <= 120:
print("是个人")
else:
print("不是人")
3.4.2 考试成绩
需求:只要有一门成绩>60分就合格
示例
# 输入两个成绩
score_python = 59
score_cpp = 59
#判断
if score_python > 60 or score_cpp > 60:
print("恭喜你,你通过考试了!")
else:
print("奶奶滴,你挂了!")
3.4.3 判断是否是本公司员工
示例
# 输入bool值
is_employee = True
#判断
if not is_employee:
print("不是本公司愿员工,不让进")
else:
print("加油加油加油!努力努力努力!")
4 if 语句进阶
4.1 elif
语法:
if 条件1:
条件1成立时,要做的事情
……
elif 条件2:
条件2成立时,要做的事情
……
elif 条件3:
条件3成立时,要做的事情
……
else:
条件不成立时,要做的事情
……
4.2 if 的嵌套
if嵌套的应用场景就是,在之前条件满足的前提下,再增加额外的判断
if嵌套的语法格式,除了缩进之外 和之前没有区别
if 嵌套演练——火车站安检
需求:
- 定义布尔型变量
has_ticket表示是否有车票 - 定义整型变量
knife_length表示刀的长度,单位:厘米 - 首先检查是否有车票,如果有,才允许进行安检
- 安检时,需要检查刀的长度,判断是否超过20厘米
4.1 如果超过20厘米,提示刀的长度,不允许上车
4.2 如果不超过20厘米,安检通过 - 如果没有车票,不允许进门
示例:
has_ticket = False
knief_length = 20
if has_ticket == True:
if knief_length > 20:
print("您的刀的长度是:%d cm" % knief_length)
print("您的刀太长了,没收!")
else:
print("祝您旅途愉快!")
else:
print("没票你还想坐车!?")
5 综合应用——石头剪刀布
目标
1.强化多个条件的逻辑运算
2.体会import导入模块(“工具包")的使用
需求
1.从控制台输入要出的拳–石头(1)/剪刀(2)/布(3)
2.电脑随机出拳——先假定电脑只会出石头,完成整体代码功能
3.比较胜负
5.1 基础代码实现
示例:
# 输入玩家的出拳信息:
player = int(input("请选择要出的拳 石头(1)/剪刀(2)/布(3):"))
# 电脑暂时默认出某个拳
computer = 1
# 进行判断
# 玩家胜利的条件
if (player == 1 and computer == 2) or (player == 2 and computer == 3) or (player == 3 and computer ==1):
print("电脑真是个小辣鸡,连你都玩不过")
# 平局
elif player == computer:
print("你也就跟电脑水平差不多吧,平了")
# 其他情况,算电脑赢
else:
print("你可真是一个小辣鸡,连电脑都玩不过")
注意:上面第一个 if 的判断条件过长,可以在
or处添加回车,但是需要在整 if 条件上再加一对小括号,如下图
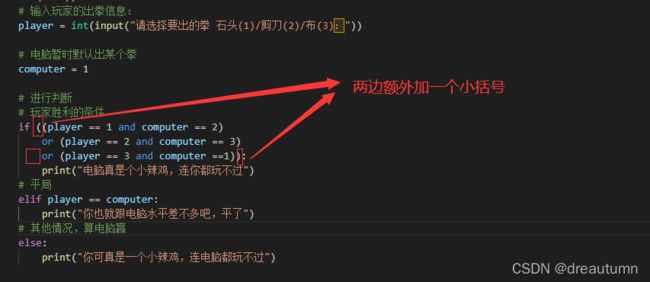
5.2 随机数的处理
-
在Python中,要使用随机数,首先需要导入 随机数 的 模块 ——工具包
import random -
导入模块后,可以直接在 模块名称 后面敲一个
.然后按Tab键,会提示该模块包含的所有函数 -
random.randint(a,b),返回[a,b]之间的整数,包含a和b
注意: 导入工具包的语句应该放在文件的顶部
改造上面的石头剪刀布代码,让电脑能够做到随机出拳:
示例:
import random
# 输入玩家的出拳信息:
player = int(input("请选择要出的拳 石头(1)/剪刀(2)/布(3):"))
# 电脑随机出拳
computer = random.randint(1,3)
# 进行判断
# 玩家胜利的条件
if ((player == 1 and computer == 2)
or (player == 2 and computer == 3)
or (player == 3 and computer ==1)):
print("电脑真是个小辣鸡,连你都玩不过")
# 平局
elif player == computer:
print("你也就跟电脑水平差不多吧,平了")
# 其他情况,算电脑赢
else:
print("你可真是一个小辣鸡,连电脑都玩不过")
Sec. 6 循环
1 程序的三大流程
- 顺序
- 分支
- 循环
2 while循环基本使用
2.1 while语句基本语法
初始条件设置——通常是重复执行的计数器
while 条件(判断计数器是否达到目标次数):
条件满足时,做的事情1
条件满足时,做的事情2
……
处理条件(计数器 + 1)
注意:while的条件语句后面也要跟一个
:冒号
示例:打印5遍hello python
i = 1
while i <= 5:
print("hello python!")
i= i + 1
2.2 Python中的赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c=a+b将a+b的结果赋值为c |
| += | 加法赋值运算符 | c+=a等效于c=c+a |
| -= | 减法赋值运算符 | c-=a等效于c=c-a |
| *= | 乘法赋值运算符 | c*=a等效于c=c*a |
| /= | 除法赋值运算符 | c/=a等效于c=c/a |
| //= | 取整除赋值运算符 | c//=a等效于c=c//a |
| %= | 取模(余数)赋值运算符 | c%a等效于c=c%a |
| **= | 幂赋值运算符 | c**a等效于c=c**a |
2.3 Python中的计数方法
常见的技术方法有两种,分别是:
- 自然计数法(从1开始)
- 程序计数法(从0开始)
除非特殊的需求,否则循环的计数都从0开始
2.4 循环计算
示例1:计算0~100之间所有数字的累计求和
# 计算0—100所有数字之和
sum = 0
i = 0
while i <= 100:
sum += i
i += 1
print("0~100的求和结果为: %d" % sum)
结果
![]()
示例2:计算0~100之间所有偶数的累计求和结果
# 计算0—100所有偶数之和
sum = 0
i = 0
while i <= 100:
if i % 2 == 0:
sum += i
i += 1
print("0~100的偶数求和结果为: %d" % sum)
结果
![]()
3 break 和 continue
break:某一条件满足时,退出循环,不再执行后续重复的代码——跳出循环continue:某一条件满足时,不执行后续重复的代码——跳过本次循环
注意:在循环中,如果使用
continue这个关键字,需要确认循环的计数是否修改,否则可能会导致死循环(C++用while也需要注意这个问题,但是用for就不需要了)
4 while 循环嵌套
4.1 循环嵌套
所谓的循环嵌套,就是while里面有while
4.2 循环嵌套演练
4.2.1 用嵌套打印小星星 + print换行与不换行
要求连续输出5行*,每一行星号的数量依次递增
方法1:可以通过字符串乘法实现:
row = 1
while row <= 5:
print("*" * row)
row += 1
结果:

方法2:使用循环嵌套
知识点
-
在默认情况下,
print函数输出内容之后,会自动在内容末尾增加换行 -
如果不希望末尾增加换行,可以在
print函数输出内容的后面增加, end="" -
其中
""中间可以指定print函数输出内容之后,继续希望显示的内容 -
语法格式:
# 输出内容结束之后,不会换行 print("*", end="") # 单纯的换行 print("")
打印小星星的程序
row = 1
while row <= 5:
col = 1
while col <= row:
print("*", end="")
col += 1
print("")
row += 1
结果跟上面用字符串连接的一样
4.2.2 用嵌套打印九九乘法表+转义字符
字符串中的转义字符
\t在控制台输出一个制表符,协助在输出文本时 垂直方向 保持对齐
\n在控制台输出一个换行符
| 转义字符 | 描述 |
|---|---|
| \\ | 反斜杠符号 |
| \’ | 单引号 |
| \" | 双引号 |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |
乘法表代码:
# 九九乘法表
row = 1
while row <= 9:
col = 1
while col <= row:
print("%d * %d = %d" % (col, row, col * row), end="\t")
col += 1
print("")
row += 1
结果:

Sec. 7 函数基础
1 函数的快速体验
- 所谓函数,就是把具有独立功能的代码块组织为一个小模块,在需要的时候调用
- 函数的使用包含两个步骤
- 定义函数
- 调用函数
- 函数的作用:在开发程序时,使用函数可以提高编写的效率以及代码的重用
2 函数基本使用
2.1 函数的定义
函数的定义格式:
def 函数名():
函数封装的代码
……
def是英文define的缩写- 函数名称应该能够表达函数封装代码的功能,方便后续调用
- 函数名称的命名应该符合标识符的命名规则
2.2 函数调用
通过函数名()即可完成对函数的调用
2.3 第一个函数演练
注意1:函数不调用不执行
注意2:函数调用只能在函数定义下使用
示例:
# 函数定义
def SayHello():
print("hello 1")
print("hello 2")
print("hello 3")
# 函数调用
SayHello()
结果:

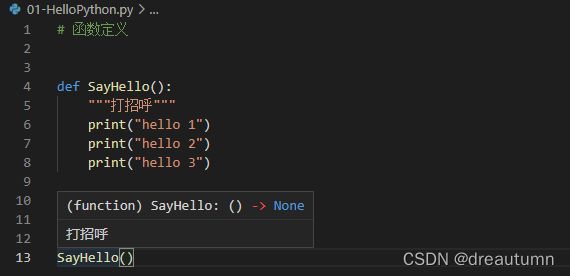
2.4 函数的文档注释(一)
- 根据PEP8的要求,在函数定义的上方,应该和其他代码(包括注释)保留两个空行
- 如果希望给函数添加注释,应该在定义函数的下方,使用连续的三对引号
- 在连续的三对引号之间编写对函数的说明文字
- 把光标放在函数调用处,就会显示出相应的注释
3 函数的参数
3.1 函数参数的使用
- 在函数名后面的小括号内部填写 参数
- 多个参数之间使用
,分隔
示例:两个数相加
def Add(num1, num2):
"""
两个数字相加
"""
sum = num1 + num2
print("%d + %d = %d" % (num1, num2, sum))
# 函数调用
Add(10, 20)
结果:
![]()
3.2 形参和实参
- 形参:定义函数时,小括号中的参数,是用来接受参数用的,在函数内部作为变量使用
- 实参:调用函数时,小括号中的参数,是用来把数据传递到函数内部用的
4 函数的返回值
- 返回值是函数完成工作后,最后给调用者的一个结果
- 在函数中使用
return关键字可以返回结果 - 调用函数一方,可以使用变量来接收函数的返回结果
注意:
return表示返回,后续的代码都不会被执行
示例:上面的求和函数使用返回值
def Add(num1, num2):
"""
两个数字相加
"""
sum = num1 + num2
return sum
# 函数调用
result = Add(10, 20)
print("求和的结果是: %d" % result)
结果:
![]()
5 函数的嵌套调用
- 一个函数里面又调用了另外一个函数,这就是函数嵌套调用
5.1 函数嵌套演练
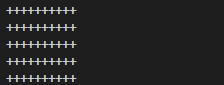
函数的嵌套演练——打印分割线
需求:可以打印指定行数的分割线,分割线的分隔符样式、长度可以自定义
示例:
def PrintLine(char, times):
print(char * times)
def PrintLines(rows, char, times):
row = 0
while row < rows:
PrintLine(char, times)
row += 1
# 测试代码
PrintLines(5, "+", 10)
结果:
5.2 函数的文档注释(二)
出了上面提到的给函数做注释,也可以对函数的各参数做注释,在VScode中可使用插件
见https://blog.csdn.net/qq_42951560/article/details/118146713
6 使用模块中的函数
模块是Python程序架构的一个核心概念
- 模块就好比是工具包,想要使用这个工具包中的工具,就需要导入import这个模块
- 每一个以拓展名
py结尾的Python源码文件都是一个模块 - 在模块中定义的全局变量、函数都是模块能够提供给外界直接使用的工具
6.1 第一个模块体验
-
将刚才写的“打印多行分隔线”的文件,删掉执行部分保存为
Practice.pydef PrintLine(char, times): print(char * times) def PrintLines(rows, char, times): row = 0 while row < rows: PrintLine(char, times) row += 1 -
新建
Practice2.py,添加如下内容:import Practice Practice.PrintLines(5, "#", 10) -
执行效果如下:

注意事项:
- 想要添加模块,在代码的最上方,输入
import + 模块名/文件名- 想要使用模块里的函数,调用时
模块名/文件名+.+函数名(参数列表)- 结合C语言的include理解,
import相当于include,因为C语言要求一个项目只能有一个main函数,所以转换到Python可理解成只有一个文件里面有调用和执行代码,其余文件只能进行函数的定义- 如果其他文件里也有执行代码,经实验,如,Practice.py文件中包含执行代码:打印5行+号,Practice2.py中
import了Practice.py,并且调用了函数:打印5行#号,程序会先执行模块中的语句,再执行主程序中的语句

6.2 模块名也是一个标识符
- 标识符可以由 字母、下划线 和 数字 组成
- 不能以数字开头
- 不能与关键字重名
注意:如果再给Python文件起名时,以数字开头是无法作为模块导入的
6.3 Pyc 文件
当使用import之后,打开程序存储目录,会发现多了一个__pycache__文件夹
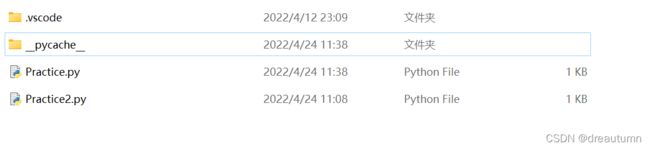
点开该文件夹:

其中,.pyc的c表示“Complied编译过”,.cpython前面的是被编译文件的文件名,-310表示pyhthon的版本。
出现这个文件夹的原因是,为了提高程序的执行速度,当import一个python文件时,解释器会先将这个被import的文件编译成一个二进制文件,提高执行速度
Sec. 8 高级变量类型
目标
- 列表
- 元组
- 字典
- 字符串
- 公共方法
- 变量高级
在Python中,所有非数字型变量都支持以下特点(公共方法):
- 都是一个序列sequnce,也可以理解为容器
- 取值用
[] - 遍历用
for in - 计算长度、最大/最小值、比较、删除
- 链接
+和重复* - 切片
1 列表
1.1 列表的定义
List(列表)是Python中使用最频繁的数据类型,在其他语言中通常叫做数组- 专门用于存储一串信息
- 列表用
[]定义,数据之间使用,分隔 - 列表的索引从0开始
- 取数据的时候格式:
列表名[索引值]
注意:从列表中取值是,如果超出索引范围,程序会报错
1.2 列表的常用操作
| 序号 | 分类 | 关键字/函数/方法 | 说明 |
|---|---|---|---|
| 1 | 增加 | list_name.insert(index,data) | 在指定位置插入数据 |
| - | - | list_name.append(data) | 在末尾追加数据 |
| - | - | list_name.extend(list_name2) | 将列表2的数据追加到列表 |
| 2 | 修改 | list_name[index]=data | 修改指定索引的数据 |
| 3 | 查找 | n=list_name.index(data) | n为返回的相应数据的索引值 |
| 4 | 删除 | del list_name[index] | 删除指定索引的数据 |
| - | - | list_name.remove[data] | 删除第一个出现的指定数据 |
| - | - | list_name.pop() | 删除末尾数据 |
| - | - | list_name.pop(index) | 删除指定索引数据 |
| - | - | list_name.clear() | 清空列表 |
| 5 | 统计 | len(list_name) | 列表长度 |
| - | - | list_name.count(data) | 数据在列表中出现的次数 |
| 6 | 排序 | list_name.sort() | 升序排序 |
| - | - | list_name.sort(reverse=True) | 降序排序 |
| - | - | list_name.reverse() | 逆序、反转 |
关键字、函数和方法(科普)
- 关键字是Python内置的,具有特殊意义的标识符
- 函数封装了独立功能,可以直接调用
- 方法和函数类似,同样是封装了独立的功能,但是需要对象来调用
1.3 循环遍历
- 遍历就是从头到尾依次从列表中获取数据
- 在Python中为了提高列表的遍历效率,专门提供的迭代iteration遍历
- 使用
for就能够实现迭代遍历
语法
for name in name_list:
print(name)
说明:上面的
name是自定义的一个变量,可以理解成for(int i = 0; i < ; i++)中的i
示例:
name_list = ["A", "B", "C","D"]
for name in name_list:
print("我的名字叫:%s" % name)
结果:

应用场景:
- 尽管Python的列表中可以存储不同类型的数据
- 但是在开发中,更多的应用场景是
- 列表存储相同类型的数据
- 通过迭代遍历,在循环体内部,针对列表中的每一项元素,执行相同的操作
2 元组
2.1 元组的定义
Tuple(元组)与列表类似,不同之处在于元组的元素不能修改- 元组表示多个元素组成的序列
- 元组在Python开发中,有特定的应用场景(主要用元组来保存不同类型的数据)
- 元组的数据之间用
,分隔 - 元组用
()定义 - 元组的索引从
0开始 - 从元组中获取数据时要使用
[]
定义一个元组
info_tuple = ("zhangsan",18,1.75)
创建空元组
info_tuple = ()
元组中只包含一个元素时,需要在元素后面添加逗号
info_tuple = (50, )
解释:如果元组中只有一个数据,如
tuple = (1),python解释器会忽略这个括号,从而把tuple认为是一个整型变量,所以要加,
2.2 元组的常用操作
在Python中,对元组的操作只有以下两种方法:
- tuple.count(数据值)
- 记录数据在列表中出现的次数
- tuple.index(数据值)
- 返回数据在元组中的索引值
其他的对于列表的函数,对元组也适用,如:
- len(元组名)
- 返回元组元素的个数
2.3 循环遍历
语法
for item in info:
print(item)
- 在Python中,可以使用
for循环遍历所有非数字型类型的变量:列表、元组、字典以及字符串- 提示:在实际开发中,除非能够确认元组中的数据类型,否则针对元组的循环遍历需求不是很多(因为元素保存的数据类型通常是不一样的,所以针对不同的数据类型操作起来也很有难度)
2.4 应用场景
- 函数的参数和返回值:一个函数可以接受任意多个参数,或者一次返回多个数据
- 格式字符串,格式化字符串后面的
()本质上就是一个元组- 比如原来的
print("名字: %s,成绩:%f" % (name, score)),后面(name,score)就是一个元组
- 比如原来的
- 让列表不可以被修改,以保护数据安全
示例:针对 格式化字符串 的应用
# 定义一个元组,存储print要打印的信息
info_tuple = ("小明", 20, 1.75)
print("%s 年龄是 %d 身高是 %.2f" % info_tuple)
# 还可以把上面整个print()里面的内容,作为一个字符串,直接打印
info_str = "%s 年龄是 %d 身高是 %.2f" % info_tuple
print(info_str)
结果:

2.5 元组和列表之间的转换
-
使用
list()函数可以把元组转换成列表list(元组) -
使用
tuple()函数可以把列表转换成元组tuple(列表)
3 字典
3.1 字典的定义
dictionary(字典)是除列表以外,Python中最灵活的数据类型- 字典同样可以用来存储多个数据
- 通常用于存储描述一个
物体的相关信息
- 通常用于存储描述一个
- 和列表的区别
- 列表是有序的对象集合
- 字典是无序的对象集合
- 字典用
{}定义 - 字典使用键值对存储数据,键值对之间使用
,分隔(跟json有点像)- 键
key是索引 - 值
value是数据 - 键 和 值 之间使用
:分隔 - 键必须是唯一的
- 值可以取任何数据类型,但键只能使用字符串、数字、或元组
- 键
语法:
xiaoming = {"name": "小明",
"age": 18,
"gender": True,
"height": 1.75}
注意:字典是一个无序的数据集合,使用print函数输出字典时,通常输出的顺序和定义的顺序事不一致的

3.2 字典的基本操作
-
取值
字典名["键名"] -
增加
字典名["新增的key"] = value -
修改
字典名["要修改key"] = 新value -
删除
字典名.pop("要删除的key")
示例:
# 定义一个字典
xiaoming_dict = {"name" : "小明"}
# 取值
print(xiaoming_dict["name"])
# 增加
xiaoming_dict["age"] = 18
print(xiaoming_dict)
# 修改
xiaoming_dict["name"] = "小小明"
print(xiaoming_dict)
#删除
xiaoming_dict.pop("name")
print(xiaoming_dict)
结果:

3.3 字典常用操作
-
统计键值对数量:
len(字典名) -
合并字典:
字典名.updata(要合并的字典)
注意:如果被合并的字典中包含已经存在的键值对,会覆盖原有的键值对 -
清空字典:
字典.clear()
3.4 循环遍历
语法:
for k in dict:
print(dict[k])
注意:在实际开发中,由于字典中每一个键值对保存数据的类型是不同的,所以针对字典的循环遍历需求并不是很多
3.5 字典和列表组合的应用场景
- 尽管可以使用
for in遍历字典 - 但是在开发中,更多的应用场景是:
- 使用多个键值时,存储描述一个物体的相关信息
- 将多个字典放在一个列表中,再进行遍历,再循环体内部针对每一个字典进行相同的处理
card_list=[{"name":"张三",
"qq": "12345",
"phone": "110"},
{"name": "李四",
"qq": "54321",
"phone": "10086"}
]
4 字符串
4.1 字符串的定义
- 字符串 就是一串字符,是编程语言中表示文本的数据类型
- 在Python中可以使用一对双引号
"或者一对单引号'定义一个字符串- 虽然可以使用
\"或者\做字符串的转移,但是在实际开发中:- 如果字符串内部需要使用
",可以使用'定义字符串 - 如果字符串内部需要使用
',可以使用"定义字符串
- 如果字符串内部需要使用
- 虽然可以使用
- 可以使用 索引 获取一个字符串中 指定位置的字符,索引计数从0开始
- 也可以使用
for循环遍历字符串中每一个字符
大多数变成语言都是采用
"来定义字符串
str1 = "Hello Python"
for char in str1:
print(char)
4.2 字符串的常用操作
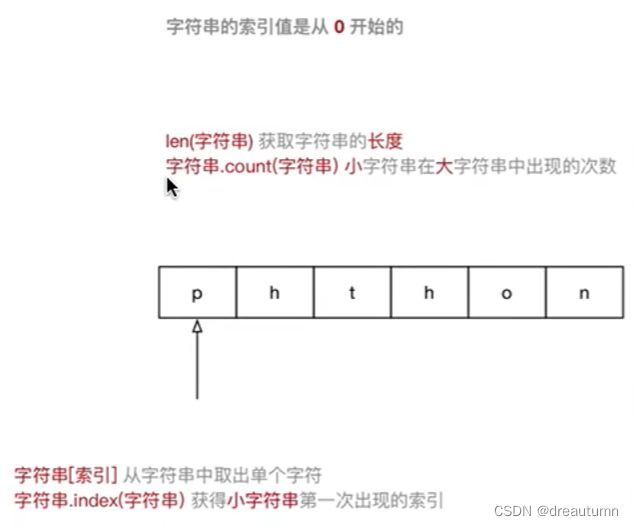
小字符串:子字符串
- 统计字符串的长度
len(字符串名称)
- 统计某一个子字符串出现的次数
字符串名称.count("子字符串")
- 某一个子字符串出现的位置
字符串名称.index(子字符串)- 注意:如果使用index方法传递的子字符串不存在,程序会报错
关于字符串还有很多具体的方法,详见视频

4.2.1 字符串判断类型方法 - 9个
| 方法 | 说明 |
|---|---|
| string.isspace() | 如果string中只包含空格,则返回True(除了判断空格,还能判断\t, \n这种空白字符) |
| string.isdecimal() | 如果string只包含数字则返回True,全角数字(只能判断阿拉伯数字整数) |
| string.isdigit() | 如果string只包含数字则返回True,全角数字、(1)、\u00b2(不能判断小数)(可以判断unicode字符串) |
| string.isnumeric | 如果string只包含数字则返回True,全角数字,汉字数字(不能判断小数)(可以判断unicode字符串)(可以判断中文数字) |
| 其余待补充 |
4.2.2 字符串查找和替换方法 - 7个
| 方法 | 说明 |
|---|---|
| string.startwith(str) | 检查字符串是否以str开头,是则返回True |
| string.endwith(str) | 检查字符串是否以str结束,是则返回True |
| string.find(str, start=0, end=len(string)) | 检测str是否包含在string中,如果start和end指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.replace(old_str, new_str, num=string,count(old)) | 把string中的old_str替换成new_str,如果num指定,则替换不超过num次(replace方法执行完成后会返回一个新的字符串,而不会改变原有字符串) |
| 其余待补充 |
4.2.3 字符串文本对齐方法 - 3个
| 方法 | 说明 |
|---|---|
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度width的新字符串 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度width的新字符串 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度width的新字符串 |
| 其余待补充 |

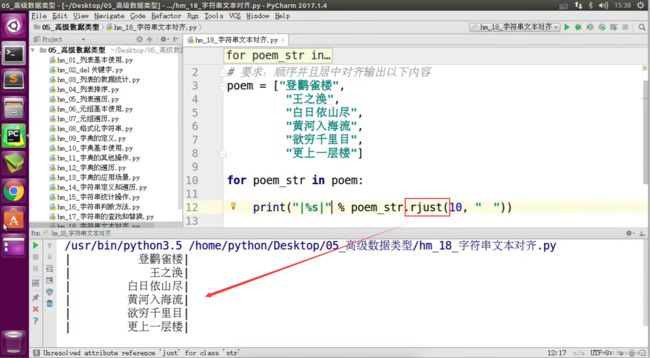
4.2.4 字符串去除空白字符方法 - 3个
| 方法 | 说明 |
|---|---|
| string.lstrip() | 截掉string左边(开始)的空白字符 |
| string.rstrip() | 截掉string右边(末尾)的空白字符 |
| string.strip() | 截掉string左右两边的空白字符 |
| 其余待补充 |

4.2.5 字符串拆分和连接方法 - 5个
| 方法 | 说明 |
|---|---|
| string.split(str=“”,num) | 以str为分隔符拆分string,如果num有指定值,则进分隔num+1个字符串,str默认包含\r,\t,\n和空格(使用指定的分隔符,把一个打的字符串拆分成字符串列表) |
| string.join(seq) | 以string作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串(把列表、字典、元组中的内容拼接成大的字符串) |
| 其余待补充 |
4.3 字符串的切片
- 切片方法适用于字符串、列表、元组
- 切片使用索引值来限定范围,从一个大的字符串中切出小的字符串
- 列表和元组都是有序的集合,都能够通过索引值获取到对应的数据
- 字典是一个无序的集合,是使用键值对保存数据
语法:
字符串[开始索引:结束索引:步长]
注意:结束索引对应的字符不包含在切片范围内;步长就是指定切片的间隔,如步长为2即是各隔一个字符取一个值
- 顺序索引:第一个字符对应的索引值为0,往后递增
- 倒序索引:最后一个字符对应的索引值为-1,倒数第二个为-2,以此类推
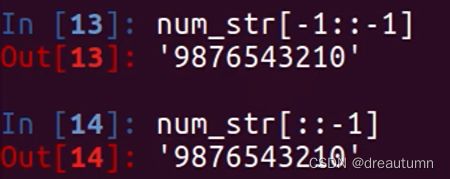
示例:字符串逆序
num_str = “0123456789”
5 公共方法
公共方法是列表、元组、字典、字符串都能够使用的方法
5.1 Python内置函数
内置函数是指不需要import导入任何模块就能直接使用的函数
python包含了以下内置函数
| 函数 | 描述 | 备注 |
|---|---|---|
| len(item) | 计算容器中元素个数 | |
| del(item) | 删除变量 | del有两种方式 |
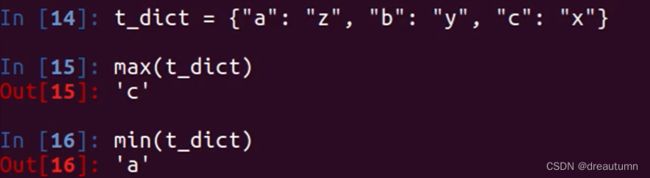
| max(item) | 返回容器中元素最大值 | 如果是字典,只针对key比较 |
| min(item) | 返回容器中元素最小值 | 如果是字典,只针对key比较 |
| cmp(item1,item2) | 比较两个值,返回:-1小于/0相等/1大于 | Python3.x取消了cmp函数 |
字典的max和min示例:
5.2 切片
内容与4.3相同,列表和元组的用法与字符串一样
5.3 运算符
| 运算符 | Python表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1,2]+[3,4] | [1,2,3,4] | 合并 | 字符串、列表、元组 |
| * | [“Hi”]*4 | [“Hi”,“Hi”,“Hi”,“Hi”] | 重复 | 字符串、列表、元组 |
| in | 3 in (1,2,3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1,2,3) | True | 元素是否不存在 | 字符串、列表、元组字典 |
| > >= == < <= | (1,2,3)<(2,2,3) | True | 元素比较 | 字符串、列表、元组 |
注意:关于列表合并的使用

注意:乘员运算符in和not in的使用:
1.in在对字典进行操作时,判断的是字典的键
5.4 完整的for循环语法
在Python中完整的for循环的语法如下:
for 变量 in 集合:
循环体代码
else:
没有通过break退出循环,循环结束后,会执行的代码
如果循环体内部使用break退出了循环,else下方的代码就不会被执行
应用场景
- 在迭代遍历嵌套的数据类型时,例如一个列表包含了多个字典
- 需求:要判断某一个字典中,是否存在指定的值
- 如果存在,提示并退出循环
- 如果不存在,在循环整体结束后,希望得到一个统一的提示
Sec. 9 综合应用 —— 名片管理系统
暂略
Sec. 10 变量进阶
目标
- 变量的引用
- 可变和不可变类型
- 局部变量和全局变量
1 变量的引用
- 变量和数据都是保存在内存中的
- 在Python中函数的参数传递以及返回值都是靠引用传递的
1.1 引用的概念
在Python中
- 变量和数据是分开存储的
- 数据保存在内存中的一个位置
- 变量中保存着数据在内存中的地址
- 变量中记录数据的地址,就叫做引用
- 使用
id()函数可以查看变量中保存数据所在的内存地址
注意:如果变量已经被定义,则给一个变量赋值的时候,本质上是修改了数据的引用
- 变量不在对之前的数据引用
- 变量改为对新赋值的数据引用
1.2 函数的参数和返回值的传递
在Python中,函数的实参/返回值都是靠引用来传递的
注意:与C++不同,Python中函数参数和返回值传递的时候,传递传递的都是地址(即是数据的引用)
但是也跟C++不同,这个不能在函数内部对外部的变量进行修改,如下swap示例
def swap(a,b):
temp = a
a = b
b = temp
print("a: %d" % a)
print("b: %d" % b)
A = 10
B = 20
swap(A,B)
print("A: %d" % A)
print("B: %d" % B)
结果:

2 可变和不可变类型
- 不可变类型,内存中的数据不允许被修改:
- 数字类型
int,bool,float,complex,long(2,x) - 字符串
str - 元组
tuple
- 数字类型
- 可变类型,内存中的数据可以被修改:
- 列表
list - 字典
dict
- 列表
注意:对于可变类型,对其内存数据进行修改的时候需要用到方法,比如
list.append(),list.clear()等,直接对list重新赋值相当于改变引用,即开辟了新的内存空间
注意:字典的
key只能使用不可变的数据类型
3 局部变量和全局变量
- 局部变量:在函数内部定义的变量,只能在函数内部使用
- 全局变量:在函数外部定义的变量(没有定义在某一个函数内),所有函数内部都可以使用这个变量
提示:在其他的开发语言中,大多不推荐使用全局变量——可变范围太大,导致程序不好维护!但是在python中对全局变量有一些特殊的设置,使用的还是比较广泛的
3.1 局部变量
- 局部变量是在函数内部定义的变量,只能在函数内部使用
- 函数执行结束后,函数内部的局部变量,会被系统回收
- 不同的函数,可以定义相同的名字的局部变量,但是各用个的不会产生影响
局部变量的生命周期
- 所谓生命周期就是变量从被创建到被系统回收的过程
- 局部变量在函数执行时才会被创建
- 函数执行结束后局部变量被系统回收
- 局部变量在生命周期内,可以用来存储函数内部临时使用到的数据
3.2 全局变量
- 全局变量是在函数外部定义的变量,所有函数内部都可以使用这个变量
示例:
#全局变量
num = 10
def demo1():
print("demo1--> %d" % num)
def demo2():
print("demo2--> %d" % num)
demo1()
demo2()
结果:

注意:要跟C++的全局变量与局部变量区分
3.2.1 函数不能直接修改全局变量的引用
在函数内部,可以用过全局变量的引用获取对应的数据
但是,不允许直接修改全局变量的引用——即不允许使用赋值语句修改全局变量的值
#全局变量
num = 10
def demo1():
# 希望修改全局变量的值
# 在python中,是不允许直接全局变量的值
# 如果使用赋值语句,会得到一个同名的局部变量
num = 99
print("demo1--> %d" % num)
def demo2():
print("demo2--> %d" % num)
demo1()
demo2()
结果:

3.2.2 在函数内部修改全局变量的方法
如果在函数中需要修改全局变量,需要使用global进行访问
#全局变量
num = 10
def demo1():
# 希望修改全局变量的值 - 使用global声明一下变量即可
# global 关键字会告诉解释器后面的变量是一个全局变量
# 再使用赋值语句时,就不会创建局部变量
global num
num = 99
print("demo1--> %d" % num)
def demo2():
print("demo2--> %d" % num)
demo1()
demo2()
结果:
![]()
3.2.3 全局变量定义的位置
为了保证所有的函数都能够正确使用到全局变量,应该将全局变量定义在其他函数上方
代码结构示意图

3.2.4 全局变量命名的建议
- 为了避免局部变量和全局变量出现混淆,在定义全局变量时,有些公司会有一些开发要求,例如:
- 全局变量名前应该增加
g_或者gl_的前缀
Sec. 11 函数进阶
1. 函数参数和返回值的作用
函数根据有没有参数以及有没有返回值,可以相互组合,一共有4种组合方式
- 无参数,无返回值
- 无参数,有返回值
- 有参数,无返回值
- 有参数,有返回值
2. 函数的返回值 进阶
问题:一个函数执行后能否返回多个结果
示例1:返回测量的温度和湿度
# 测量温度和湿度并返回
def measure():
print("测量开始...")
temp = 29
witness = 50
print("测量结束...")
# 元组可以包含多个数据,因此可以使用元组让函数一次返回多个值
# 如果函数的返回类型是元组,小括号可以省略
return temp, witness
result = measure()
print(result)
结果:

注意: 如果函数的返回类型是元组,小括号可以省略
示例2:接受返回值是元组的方式
接上一个示例,由于返回的是一个元组,接受数据之后需要把元组里面的数据提取出来
# 测量温度和湿度并返回
def measure():
print("测量开始...")
temp = 29
wetness = 50
print("测量结束...")
# 元组可以包含多个数据,因此可以使用元组让函数一次返回多个值
# 如果函数的返回类型是元素,小括号可以省略
return temp, wetness
result = measure()
print(result)
# 需要单独处理湿度或温度 - 方法1
print(result[0])
print(result[1])
# 方法2
# 如果函数返回的类型是元组,同时希望单独处理元组中的元素
# 可以使用多个变量,一次接受函数的返回结果
gl_temp, gl_wetness = measure()
print(gl_temp)
print(gl_wetness)
结果:

注意:使用多个变量接受结果时,变量的个数应该和元组中元素的个数保持一致
2.1 面试题——交换两个数字
题目要求
- 有两个整数变量
a=6,b=100 - 不适用其他变量,交换两个变量的值
-
解法1——使用临时变量
c = b b = a a =c -
解法2——不使用临时变量
a = a + b b = a - b a = a - b -
解法3——Python专有,利用元组
a, b = (b, a)注意:等号右边时元组时,可以把小括号省略,所以解法3也可以写成
a, b = b, a
3. 函数的参数 进阶
3.1 不可变和可变参数
在函数内部,针对参数使用赋值语句,不会影响调用函数时传递的实参变量
- 无论传递的参数时可变还是不可变,只要针对参数使用赋值语句,会在函数内部修改局部变量的引用,不会影响到外部变量的引用
示例1:
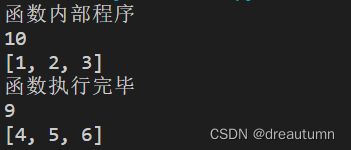
def demo(num, num_list):
print("函数内部程序")
num = 10
num_list = [1,2,3]
print(num)
print(num_list)
print("函数执行完毕")
gl_num = 9
gl_num_list = [4,5,6]
demo(gl_num, gl_num_list)
print(gl_num)
print(gl_num_list)
结果:
如果传递的参数时可变类型,在函数内部,使用方法修改了数据的内容,同样会影响到外部的数据
示例2
def demo(num_list):
print("函数内部程序")
# 使用方法对列表进行操作
num_list.append(9)
print(num_list)
print("函数执行完毕")
gl_num_list = [1,2,3]
demo(gl_num_list)
print(gl_num_list)

3.2 面试题 —— +=
在python中,列表变量调用+=本质上是在执行列表变量的extend方法,不会修改变量的引用
示例:
def demo(num, num_list):
print("函数内部程序")
num += num
num_list += num_list
print(num)
print(num_list)
print("函数执行完毕")
gl_num = 9
gl_num_list = [1,2,3]
demo(gl_num, gl_num_list)
print(gl_num)
print(gl_num_list)
结果:
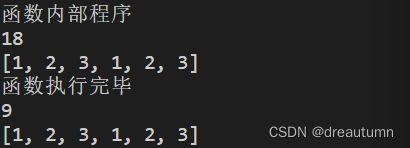
上面的例子同时给出了一个对数字使用
+=的方法,可以看出,对于数字+=相当于是在赋值,而对于列表来说就是调用extend
3.3 缺省参数
- 定义函数时,可以给某个参数指定一个默认值,具有默认值的参数就叫做缺省参数
- 调用函数时,如果没有传入缺省参数的值,则在函数内部使用定义函数时指定的参数默认值
- 函数的缺省参数,将常见的值设置为参数的缺省值,从而简化函数的调用
3.3.1 指定函数的缺省参数
- 在参数后使用赋值语句,可以指定参数的缺省值
示例:
def print_info(name, gender = True):
if gender == True:
gender_text = "男生"
else:
gender_text = "女生"
print("%s 是 %s" % (name, gender_text))
print_info("小明", True)
print_info("老王")
print_info("小美", False)
结果:

3.3.2 缺省函数的注意事项
注意1:缺省参数的定义位置
必须保证带有默认值的缺省参数在参数列表末尾
以下为错误示例
错误:def print_info(name, gender = True, title):
注意2:
在调用具有多个缺省值的函数时,如果只想给某个具体的缺省参数传递数据,在调用函数时,应该先写参数的名字,跟一个等号,后面加需要的值
在上面示例的基础上,进行如下修改:
def print_info(name, title = "", gender = True):
if gender == True:
gender_text = "男生"
else:
gender_text = "女生"
print("[%s] %s 是 %s" % (title, name, gender_text))
print_info("小明")
print_info("老王")
print_info("小美", gender = False)
结果:

分析:
在调用函数的时候,如果还保持上一个示例中的不变,print_info("小美", False),按照顺序,第一个变量"小美"赋给name,第二个变量False付给title,不是我们的本意,所以要进行如新示例所示修改
3.4 多值参数
-
有时可能需要一个函数能够处理的参数个数是不确定的,这个时候,就可以使用多值参数
-
Python中有两种多汁参数:
- 参数名前增加一个
*可以接收元组 - 参数名前增加两个
**可以接收字典
- 参数名前增加一个
-
一般在给多值参数命名时,喜欢使用以下两个名字
*args——存放元组参数,前面有一个***kwargs——存放字典参数,前面有两个*
-
args是arguments的缩写,有变量的含义 -
kw是keyword的缩写,keyword可以记忆键值对参数
示例:
def demo(num, *args, **kwargs):
print(num)
print(args)
print(kwargs)
demo(1,2,3,4,name = "小明",age = "18")
结果:

记住这个格式,以后用的时候知道就行了
3.4.1 多值参数案例——计算任意多个数字的和
需求:一定一个函数,可以接受任意多个整数并返回这些整数的累加结果
示例:
def sum_numbers(*args):
sum = 0
for n in args:
sum += n
return sum
print(sum_numbers(1,2,3,4,5,6))
3.4.2 元组和字典的拆包
- 在调用带有多值参数的函数时,如果希望:
- 将一个元组变量,直接传递给
args - 将一个字典变量,直接传递给
kwargs
- 将一个元组变量,直接传递给
- 就可以使用拆包,简化参数的传递,拆包的方式:
- 在元组变量前,增加一个
* - 在字典变量前,增加两个
*
- 在元组变量前,增加一个
示例:
def demo(*args, **kwargs):
print(args)
print(kwargs)
gl_nums = (1,2,3)
gl_dict = {"name": "小明", "age": 18}
demo(*gl_nums, **gl_dict)
结果:

总结:有点类似C++的指针解引用
4 函数的递归
函数调用自身的编程技巧成为递归
4.1 函数递归的特点
特点:一个函数内部调用自己
代码特点:
1.函数内部的代码是相同的,只是针对参数不同,处理的结果不同
2.当参数满足一个条件时,函数不在执行:这个非常重要,通常被称为递归的出口,否则会出现死循环!
示例:
def sum_number(num):
print(num)
# 递归的出口,当参数满足某个条件时,不再执行函数
if num == 1:
return
# 自己调用自己
sum_number(num - 1) # 参数不一样
sum_number(3)
结果:

4.2 递归程序代码执行流程图
接上一个示例,为了更加清晰,添加一行函数结束的代码:
def sum_number(num):
print(num)
# 递归的出口,当参数满足某个条件时,不再执行函数
if num == 1:
return
# 自己调用自己
sum_number(num - 1) # 参数不一样
print("完成--> %d" % num)
sum_number(3)
结果:

流程图:

4.3 递归案例——计算数字累加
需求:
1.定义一个函数sum_numbers
2.能够接受一个num的整数参数
3.计算1+2+…+num的结果
示例:
def sum_number(num):
# 递归的出口,当参数满足某个条件时,不再执行函数
if num == 1:
return 1
# 根据递推公式写表达式
temp = sum_number(num - 1)
return num + temp
print(sum_number(3))
运用递归可以先把递推关系理清楚,本例中f(x) = f(x-1) + x
数字累加程序执行流程图:
