Redisson—分布式服务
一、 分布式远程服务(Remote Service)
基于Redis的Java分布式远程服务,可以用来通过共享接口执行存在于另一个Redisson实例里的对象方法。换句话说就是通过Redis实现了Java的远程过程调用(RPC)。分布式远程服务基于可以用POJO对象,方法的参数和返回类不受限制,可以是任何类型。
分布式远程服务(Remote Service)提供了两种类型的RRemoteService实例:
- 服务端(远端)实例 - 用来执行远程方法(工作者实例即worker instance). 例如:
RRemoteService remoteService = redisson.getRemoteService();
SomeServiceImpl someServiceImpl = new SomeServiceImpl();
// 在调用远程方法以前,应该首先注册远程服务
// 只注册了一个服务端工作者实例,只能同时执行一个并发调用
remoteService.register(SomeServiceInterface.class, someServiceImpl);
// 注册了12个服务端工作者实例,可以同时执行12个并发调用
remoteService.register(SomeServiceInterface.class, someServiceImpl, 12);- 客户端(本地)实例 - 用来请求远程方法. 例如:
RRemoteService remoteService = redisson.getRemoteService();
SomeServiceInterface service = remoteService.get(SomeServiceInterface.class);
String result = service.doSomeStuff(1L, "secondParam", new AnyParam());客户端和服务端必须使用一样的共享接口,生成两者的Redisson实例必须采用相同的连接配置。客户端和服务端实例可以运行在同一个JVM里,也可以是不同的。客户端和服务端的数量不收限制。(注意:尽管Redisson不做任何限制,但是Redis的限制仍然有效。)
在服务端工作者可用实例数量 大于1 的时候,将并行执行并发调用的远程方法。
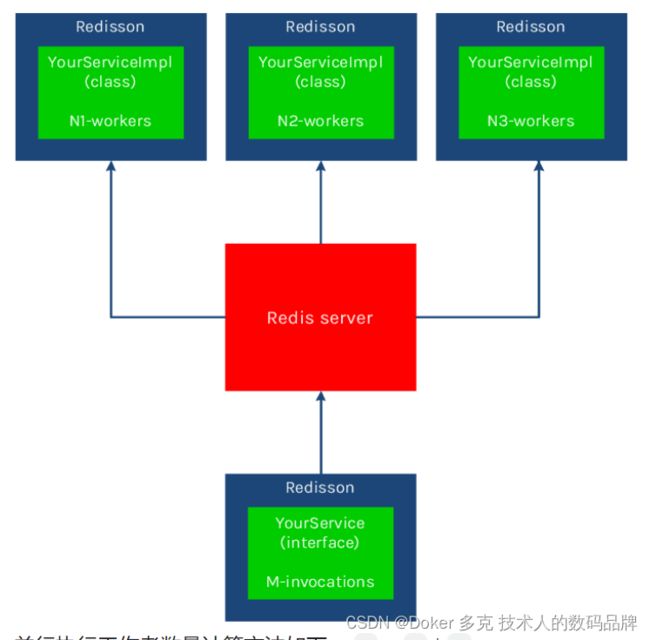
并行执行工作者数量计算方法如下: T = R * N
T - 并行执行工作者总数 R - Redisson服务端数量 N - 注册服务端时指定的执行工作者数量
超过该数量的并发请求将在列队中等候执行。
在服务端工作者实例可用数量为 1 时,远程过程调用将会按 顺序执行。这种情况下,每次只有一个请求将会被执行,其他请求将在列队中等候执行。

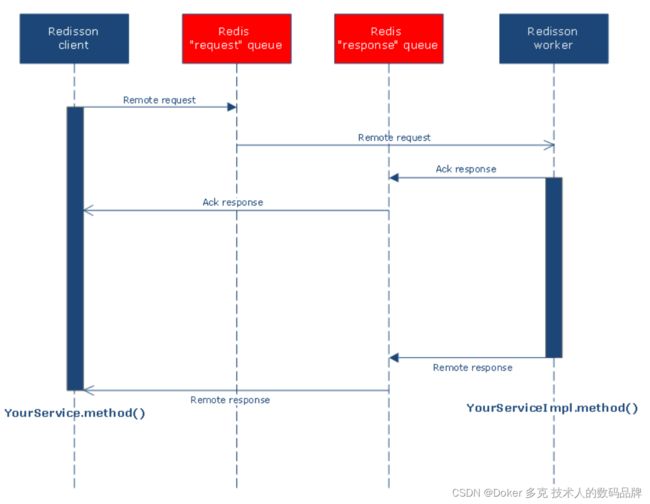
1. 分布式远程服务工作流程
分布式远程服务为每个注册接口建立了两个列队。一个列队用于请求,由服务端监听,另一个列队用于应答回执和结果回复,由客户端监听。应答回执用于判定该请求是否已经被接受。如果在指定的超时时间内没有被执行工作者执行将会抛出RemoteServiceAckTimeoutException错误。
下图描述了每次发起远程过程调用请求的工作流程。
2. 发送即不管(Fire-and-Forget)模式和应答回执(Ack-Response)模式
分布式远程服务通过org.redisson.core.RemoteInvocationOptions类,为每个远程过程调用提供了一些可配置选项。这些选项可以用来指定和修改请求超时和选择跳过应答回执或结果的发送模式。例如:
// 应答回执超时1秒钟,远程执行超时30秒钟
RemoteInvocationOptions options = RemoteInvocationOptions.defaults();
// 无需应答回执,远程执行超时30秒钟
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noAck();
// 应答回执超时1秒钟,不等待执行结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noResult();
// 应答回执超时1分钟,不等待执行结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().expectAckWithin(1, TimeUnit.MINUTES).noResult();
// 发送即不管(Fire-and-Forget)模式,无需应答回执,不等待结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noAck().noResult();
RRemoteService remoteService = redisson.getRemoteService();
YourService service = remoteService.get(YourService.class, options);3. 异步调用
远程过程调用也可以采用异步的方式执行。异步调用需要单独提交一个带有@RRemoteAsync注解(annotation)的异步接口类。异步接口方法签名必须与远程接口的方法签名相符。异步接口的返回类必须是org.redisson.api.RFuture对象或其子对象。在调用RRemoteService.get方法时将对异步接口的方法进行验证。异步接口无须包含所有的远程接口里的方法,只需要包含要求异步执行的方法即可。
// 远程接口
public interface RemoteInterface {
Long someMethod1(Long param1, String param2);
void someMethod2(MyObject param);
MyObject someMethod3();
}
// 匹配远程接口的异步接口
@RRemoteAsync(RemoteInterface.class)
public interface RemoteInterfaceAsync {
RFuture someMethod1(Long param1, String param2);
RFuture someMethod2(MyObject param);
}
RRemoteService remoteService = redisson.getRemoteService();
RemoteInterfaceAsync asyncService = remoteService.get(RemoteInterfaceAsync.class); 4. 取消异步调用
通过调用Future.cancel()方法可以非常方便的取消一个异步调用。分布式远程服务允许在三个阶段中任何一个阶段取消异步调用:
- 远程调用请求在列队中排队阶段
- 远程调用请求已经被分布式远程服务接受,还未发送应答回执,执行尚未开始。
- 远程调用请求已经在执行阶段
想要正确的处理第三个阶段,在服务端代码里应该检查Thread.currentThread().isInterrupted()的返回状态。范例如下:
// 远程接口
public interface MyRemoteInterface {
Long myBusyMethod(Long param1, String param2);
}
// 匹配远程接口的异步接口
@RRemoteAsync(MyRemoteInterface.class)
public interface MyRemoteInterfaceAsync {
RFuture myBusyMethod(Long param1, String param2);
}
// 远程接口的实现
public class MyRemoteServiceImpl implements MyRemoteInterface {
public Long myBusyMethod(Long param1, String param2) {
for (long i = 0; i < Long.MAX_VALUE; i++) {
iterations.incrementAndGet();
if (Thread.currentThread().isInterrupted()) {
System.out.println("interrupted! " + i);
return;
}
}
}
}
RRemoteService remoteService = redisson.getRemoteService();
ExecutorService executor = Executors.newFixedThreadPool(5);
// 注册远程服务的服务端的同时,通过单独指定的ExecutorService来配置执行线程池
MyRemoteInterface serviceImpl = new MyRemoteServiceImpl();
remoteService.register(MyRemoteInterface.class, serviceImpl, 5, executor);
// 异步调用方法
MyRemoteInterfaceAsync asyncService = remoteService.get(MyRemoteInterfaceAsync.class);
RFuture future = asyncService.myBusyMethod(1L, "someparam");
// 取消异步调用
future.cancel(true); 二、分布式实时对象(Live Object)服务
1. 介绍
一个 分布式实时对象(Live Object) 可以被理解为一个功能强化后的Java对象。该对象不仅可以被一个JVM里的各个线程相引用,还可以被多个位于不同JVM里的线程同时引用。Wikipedia对这种特殊对象的概述是:
Live distributed object (also abbreviated as live object) refers to a running instance of a distributed multi-party (or peer-to-peer) protocol, viewed from the object-oriented perspective, as an entity that has a distinct identity, may encapsulate internal state and threads of execution, and that exhibits a well-defined externally visible behavior.
Redisson分布式实时对象(Redisson Live Object,简称RLO)运用即时生成的代理类(Proxy),将一个指定的普通Java类里的所有字段,以及针对这些字段的操作全部映射到一个Redis Hash的数据结构,实现这种理念。每个字段的get和set方法最终被转译为针对同一个Redis Hash的hget和hset命令,从而使所有连接到同一个Redis节点的所有可以客户端同时对一个指定的对象进行操作。众所周知,一个对象的状态是由其内部的字段所赋的值来体现的,通过将这些值保存在一个像Redis这样的远程共享的空间的过程,把这个对象强化成了一个分布式对象。这个分布式对象就叫做Redisson分布式实时对象(Redisson Live Object,简称RLO)。
通过使用RLO,运行在不同服务器里的多个程序之间,共享一个对象实例变得和在单机程序里共享一个对象实例一样了。同时还避免了针对任何一个字段操作都需要将整个对象序列化和反序列化的繁琐,进而降低了程序开发的复杂性和其数据模型的复杂性:从任何一个客户端修改一个字段的值,处在其他服务器上的客户端(几乎^)即刻便能查看到。而且实现代码与单机程序代码无异。(^连接到从节点的客户端仍然受Redis的最终一致性的特性限制)
鉴于Redis是一个单线程的程序,针对实时对象的所有的字段操作可以理解为全部是原子性操作,也就是说在读取一个字段的过程不会担心被其他线程所修改。
通过使用RLO,可以把Redis当作一个允许被多个JVM同时操作且不受GC影响的共享堆(Heap Space)。
2. 使用方法
Redisson为分布式实时对象提供了一系列不同功能的注解,其中@REntity和@RId两个注解是分布式实时对象的必要条件。
@REntity
public class MyObject {
@RId
private String id;
@RIndex
private String value;
private MyObject parent;
public MyObject(String id) {
this.id = id;
}
public MyObject() {
}
// getters and setters
}在开始使用分布式实时对象以前,需要先通过Redisson服务将指定的对象连接(attach),合并(merge)或持久化(persist)到Redis里。
RLiveObjectService service = redisson.getLiveObjectService();
MyLiveObject myObject = new MyLiveObject();
myObject.setId("1");
// 将myObject对象当前的状态持久化到Redis里并与之保持同步。
myObject = service.persist(myObject);
MyLiveObject myObject = new MyLiveObject("1");
// 抛弃myObject对象当前的状态,并与Redis里的数据建立连接并保持同步。
myObject = service.attach(myObject);
MyLiveObject myObject = new MyLiveObject();
myObject.setId("1");
// 将myObject对象当前的状态与Redis里的数据合并之后与之保持同步。
myObject = service.merge(myObject);
myObject.setValue("somevalue");
// 通过ID获取分布式实时对象
MyLiveObject myObject = service.get(MyLiveObject.class, "1");
// 通过索引查找分布式实时对象
Collection myObjects = service.find(MyLiveObject.class, Conditions.in("value", "somevalue", "somevalue2"));
Collection myObjects = service.find(MyLiveObject.class, Conditions.and(Conditions.in("value", "somevalue", "somevalue2"), Conditions.eq("secondfield", "test"))); “parent”字段中包含了指向到另一个分布式实时对象的引用,它可以与包含类是同一类型也可以不同。Redisson内部采用了与Java的引用类似的方式保存这个关系,而非将全部对象序列化,可视为与普通的引用同等效果。
//RLO对象:
MyObject myObject = service.get(MyObject.class, "1");
MyObject myParentObject = service.get(MyObject.class, "2");
myObject.setValue(myParentObject);RLO的字段类型基本上无限制,可以是任何类型。比如Java util包里的集合类,Map类等,也可以是自定义的对象。只要指定的编码解码器能够对其进行编码和解码操作便可。关于编码解码器的详细信息请查阅高级使用方法章节。
尽管RLO的字段类型基本上无限制,个别类型还是受限。注解了RId的字段类型不能是数组类(Array),比如int[],long[],double[],byte[]等等。更多关于限制有关的介绍和原理解释请查阅使用限制 章节。
为了保证RLO的用法和普通Java对象的用法尽可能一直,Redisson分布式实时对象服务自动将以下普通Java对象转换成与之匹配的Redisson分布式对象RObject。
| 普通Java类 |
转换后的Redisson类 |
| SortedSet.class |
RedissonSortedSet.class |
| Set.class |
RedissonSet.class |
| ConcurrentMap.class |
RedissonMap.class |
| Map.class |
RedissonMap.class |
| BlockingDeque.class |
RedissonBlockingDeque.class |
| Deque.class |
RedissonDeque.class |
| BlockingQueue.class |
RedissonBlockingQueue.class |
| Queue.class |
RedissonQueue.class |
| List.class |
RedissonList.class |
类型转换将按照从上至下的顺序匹配类型,例如LinkedList类同时实现了Deque,List和Queue,由于Deque排在靠上的位置,因此它将会被转换成一个RedissonDeque类型。
Redisson的分布式对象也采用类似的方式,将自身的状态储存于Redis当中,(几乎^)所有的状态改变都直接映射到Redis里,不在本地JVM中保留任何赋值。(^本地缓存对象除外,比如RLocalCachedMap)
3. 高级使用方法
正如上述介绍,RLO类其实都是按需实时生成的代理(Proxy)类。生成的代理类和原类都一同缓存Redisson实例里。这个过程会消耗一些时间,在对耗时比较敏感的情况下,建议通过RedissonLiveObjectService提前注册所有的RLO类。这个服务也可以用来注销不再需要的RLO类,也可以用来查询一个类是否已经注册了。
RLiveObjectService service = redisson.getLiveObjectService();
service.registerClass(MyClass.class);
service.unregisterClass(MyClass.class);
Boolean registered = service.isClassRegistered(MyClass.class);4. 注解(Annotation)使用方法
@REntity
仅适用于类。通过指定@REntity的各个参数,可以详细的对每个RLO类实现特殊定制,以达到改变RLO对象的行为。
- namingScheme - 命名方案。命名方案规定了每个实例在Redis中对应key的名称。它不仅被用来与已存在的RLO建立关联,还被用来储存新建的RLO实例。默认采用Redisson自带的DefaultNamingScheme对象。
- codec - 编码解码器。在运行当中,Redisson用编码解码器来对RLO中的每个字段进行编码解码。Redisson内部采用了实例池管理不同类型的编码解码器实例。Redisson提供了多种不同的编码解码器,默认使用JsonJacksonCodec。
- fieldTransformation - 字段转换模式。如上所述,为了尽可能的保证RLO的用法和普通Java对象一致,Redisson会自动将常用的普通Java对象转换成与其匹配的Redisson分布式对象。这是由于字段转换模式的默认值是ANNOTATION_BASED,修改为IMPLEMENTATION_BASED就可以不转换。
@RId
仅适用于字段。@RId注解只能用在具备区分实例的字段上,这类字段可以理解为一个类的id字段或主键字段。这个字段的值将被命名方案namingScheme用来与事先存在的RLO建立引用。加了该注解的字段是唯一在本地JVM里同时保存赋值的字段。一个类只能有一个字段包含@RId注解。
可以通过指定一个生成器generator策略来实现自动生成这个字段的值。默认不提供生成器。
@RIndex
仅适用于字段。用来指定可用于搜索的字段。可以通过RLiveObjectService.find方法来根据条件精细查找分布式实时对象。查询条件可以是含(IN),或(OR),和(AND)或相等(EQ)以及它们的任意组合。
使用范例如下:
public class MyObject {
@RIndex
String field1;
@RIndex
String field2;
@RIndex
String field3;
}
Collection objects = RLiveObjectService.find(MyObject.class, Conditions.or(Conditions.and(Conditions.eq("field1", "value"), Conditions.eq("field2", "value")), Conditions.in("field3", "value1", "value2")); @RObjectField
仅适用于字段。允许通过该注解中的namingScheme或codec来改变该字段的命名或编码方式,用来区别于@REntity中指定的预设方式。
@RCascade
仅适用于字段。用来指定包含于分布式实时对象字段内其它对象的级联操作方式。
可选的级联操作方式为如下:
RCascadeType.ALL - 执行所有级联操作
RCascadeType.PERSIST - 仅在执行RLiveObjectService.persist()方法时进行级联操作 RCascadeType.DETACH - 仅在执行RLiveObjectService.detach()方法时进行级联操作 RCascadeType.MERGE - 仅在执行RLiveObjectService.merge()方法时进行级联操作 RCascadeType.DELETE - 仅在执行RLiveObjectService.delete()方法时进行级联操作
5. 使用限制
如上所述,带有RId注解字段的类型不能使数组类,这是因为目前默认的命名方案类DefaultNamingScheme还不能正确地将数组类序列化和反序列化。在改善了DefaultNamingScheme类的不足以后会考虑取消这个限制。另外由于带有RId注解的字段是用来指定Redis中映射的key的名称,因此组建一个只含有唯一一个字段的RLO类是毫无意义的。选用RBucket会更适合这样的场景。
三、分布式执行服务(Executor Service)
1. 分布式执行服务概述
Redisson的分布式执行服务实现了java.util.concurrent.ExecutorService接口,支持在不同的独立节点里执行基于java.util.concurrent.Callable接口或java.lang.Runnable接口或Lambda的任务。这样的任务也可以通过使用Redisson实例,实现对储存在Redis里的数据进行操作。Redisson分布式执行服务是最快速和有效执行分布式运算的方法。
2. 任务
Redisson独立节点不要求任务的类在类路径里。他们会自动被Redisson独立节点的ClassLoader加载。因此每次执行一个新任务时,不需要重启Redisson独立节点。
采用Callable任务的范例:
public class CallableTask implements Callable {
@RInject
private RedissonClient redissonClient;
@Override
public Long call() throws Exception {
RMap map = redissonClient.getMap("myMap");
Long result = 0;
for (Integer value : map.values()) {
result += value;
}
return result;
}
} 采用Runnable任务的范例:
public class RunnableTask implements Runnable {
@RInject
private RedissonClient redissonClient;
private long param;
public RunnableTask() {
}
public RunnableTask(long param) {
this.param = param;
}
@Override
public void run() {
RAtomicLong atomic = redissonClient.getAtomicLong("myAtomic");
atomic.addAndGet(param);
}
}在创建ExecutorService时可以配置以下参数:
ExecutorOptions options = ExecutorOptions.defaults()
// 指定重新尝试执行任务的时间间隔。
// ExecutorService的工作节点将等待10分钟后重新尝试执行任务
//
// 设定为0则不进行重试
//
// 默认值为5分钟
options.taskRetryInterval(10, TimeUnit.MINUTES);RExecutorService executorService = redisson.getExecutorService("myExecutor", options);
executorService.submit(new RunnableTask(123));
RExecutorService executorService = redisson.getExecutorService("myExecutor", options);
Future future = executorService.submit(new CallableTask());
Long result = future.get(); 使用Lambda任务的范例:
RExecutorService executorService = redisson.getExecutorService("myExecutor", options);
Future future = executorService.submit((Callable & Serializable)() -> {
System.out.println("task has been executed!");
});
Long result = future.get(); 可以通过@RInject注解来为任务实时注入Redisson实例依赖。
3. 取消任务
通过Future.cancel()方法可以很方便的取消所有已提交的任务。通过对Thread.currentThread().isInterrupted()方法的调用可以在已经处于运行状态的任务里实现任务中断:
public class CallableTask implements Callable {
@RInject
private RedissonClient redissonClient;
@Override
public Long call() throws Exception {
RMap map = redissonClient.getMap("myMap");
Long result = 0;
// map里包含了许多的元素
for (Integer value : map.values()) {
if (Thread.currentThread().isInterrupted()) {
// 任务被取消了
return null;
}
result += value;
}
return result;
}
}
RExecutorService executorService = redisson.getExecutorService("myExecutor");
Future future = executorService.submit(new CallableTask());
// 或
RFuture future = executorService.submitAsync(new CallableTask());
// ...
future.cancel(true); 四、 分布式调度任务服务(Scheduler Service)
1. 分布式调度任务服务概述
Redisson的分布式调度任务服务实现了java.util.concurrent.ScheduledExecutorService接口,支持在不同的独立节点里执行基于java.util.concurrent.Callable接口或java.lang.Runnable接口的任务。Redisson独立节点按顺序运行Redis列队里的任务。调度任务是一种需要在未来某个指定时间运行一次或多次的特殊任务。
2. 设定任务计划
Redisson独立节点不要求任务的类在类路径里。他们会自动被Redisson独立节点的ClassLoader加载。因此每次执行一个新任务时,不需要重启Redisson独立节点。
采用Callable任务的范例:
public class CallableTask implements Callable {
@RInject
private RedissonClient redissonClient;
@Override
public Long call() throws Exception {
RMap map = redissonClient.getMap("myMap");
Long result = 0;
for (Integer value : map.values()) {
result += value;
}
return result;
}
} 在创建ExecutorService时可以配置以下参数:
ExecutorOptions options = ExecutorOptions.defaults()
// 指定重新尝试执行任务的时间间隔。
// ExecutorService的工作节点将等待10分钟后重新尝试执行任务
//
// 设定为0则不进行重试
//
// 默认值为5分钟
options.taskRetryInterval(10, TimeUnit.MINUTES);RScheduledExecutorService executorService = redisson.getExecutorService("myExecutor");
ScheduledFuture future = executorService.schedule(new CallableTask(), 10, TimeUnit.MINUTES);
Long result = future.get(); 使用Lambda任务的范例:
RExecutorService executorService = redisson.getExecutorService("myExecutor", options);
ScheduledFuture future = executorService.schedule((Callable & Serializable)() -> {
System.out.println("task has been executed!");
}, 10, TimeUnit.MINUTES);
Long result = future.get(); 采用Runnable任务的范例:
public class RunnableTask implements Runnable {
@RInject
private RedissonClient redissonClient;
private long param;
public RunnableTask() {
}
public RunnableTask(long param) {
this.param= param;
}
@Override
public void run() {
RAtomicLong atomic = redissonClient.getAtomicLong("myAtomic");
atomic.addAndGet(param);
}
}
RScheduledExecutorService executorService = redisson.getExecutorService("myExecutor");
ScheduledFuture future1 = executorService.schedule(new RunnableTask(123), 10, TimeUnit.HOURS);
// ...
ScheduledFuture future2 = executorService.scheduleAtFixedRate(new RunnableTask(123), 10, 25, TimeUnit.HOURS);
// ...
ScheduledFuture future3 = executorService.scheduleWithFixedDelay(new RunnableTask(123), 5, 10, TimeUnit.HOURS);3. 通过CRON表达式设定任务计划
在分布式调度任务中,可以通过CRON表达式来为任务设定一个更复杂的计划。表达式与Quartz的CRON格式完全兼容。
例如:
RScheduledExecutorService executorService = redisson.getExecutorService("myExecutor");
executorService.schedule(new RunnableTask(), CronSchedule.of("10 0/5 * * * ?"));
// ...
executorService.schedule(new RunnableTask(), CronSchedule.dailyAtHourAndMinute(10, 5));
// ...
executorService.schedule(new RunnableTask(), CronSchedule.weeklyOnDayAndHourAndMinute(12, 4, Calendar.MONDAY, Calendar.FRIDAY));4. 取消计划任务
分布式调度任务服务提供了两张取消任务的方式:通过调用ScheduledFuture.cancel()方法或调用RScheduledExecutorService.cancelScheduledTask方法。通过对Thread.currentThread().isInterrupted()方法的调用可以在已经处于运行状态的任务里实现任务中断:
public class RunnableTask implements Callable {
@RInject
private RedissonClient redissonClient;
@Override
public Long call() throws Exception {
RMap map = redissonClient.getMap("myMap");
Long result = 0;
// map里包含了许多的元素
for (Integer value : map.values()) {
if (Thread.currentThread().isInterrupted()) {
// 任务被取消了
return null;
}
result += value;
}
return result;
}
}
RScheduledExecutorService executorService = redisson.getExecutorService("myExecutor");
RScheduledFuture future = executorService.scheduleAsync(new RunnableTask(), CronSchedule.dailyAtHourAndMinute(10, 5));
// ...
future.cancel(true);
// 或
String taskId = future.getTaskId();
// ...
executorService.cancelScheduledTask(taskId); 五、分布式映射归纳服务(MapReduce)
1. 介绍
Redisson提供了通过映射归纳(MapReduce)编程模式来处理储存在Redis环境里的大量数据的服务。这个想法来至于其他的类似实现方式和谷歌发表的研究。所有 映射(Map) 和 归纳(Reduce) 阶段中的任务都是被分配到各个独立节点(Redisson Node)里并行执行的。以下所有接口均支持映射归纳(MapReduce)功能: RMap、 RMapCache、 RLocalCachedMap、 RSet、 RSetCache、 RList、 RSortedSet、 RScoredSortedSet、 RQueue、 RBlockingQueue、 RDeque、 RBlockingDeque、 RPriorityQueue 和 RPriorityDeque
映射归纳(MapReduce)的功能是通过RMapper、 RCollectionMapper、 RReducer 和 RCollator 这几个接口实现的。
1.RMapper映射器接口适用于映射(Map)类,它用来把映射(Map)中的每个元素转换为另一个作为归纳(Reduce)处理用的键值对。
public interface RMapper extends Serializable {
void map(KIn key, VIn value, RCollector collector);
} 2.RCollectionMapper 映射器接口仅适用于集合(Collection)类型的对象,它用来把集合(Collection)中的元素转换成一组作为归纳(Reduce)处理用的键值对。
public interface RCollectionMapper extends Serializable {
void map(VIn value, RCollector collector);
} 3.RReducer归纳器接口用来将上面这些,由映射器生成的键值对列表进行归纳整理。
public interface RReducer extends Serializable {
V reduce(K reducedKey, Iterator values);
} 4.RCollator收集器接口用来把归纳整理以后的结果化简为单一一个对象。
public interface RCollator extends Serializable {
R collate(Map resultMap);
} 以上每个阶段的任务都可以用@RInject注解的方式来获取RedissonClient实例:
public class WordMapper implements RMapper {
@RInject
private RedissonClient redissonClient;
@Override
public void map(String key, String value, RCollector collector) {
// ...
redissonClient.getAtomicLong("mapInvocations").incrementAndGet();
}
} 2. 映射(Map)类型的使用范例
Redisson提供的RMap、 RMapCache和RLocalCachedMap这三种映射(Map)类型的对象均可以使用这种分布式映射归纳(MapReduce)服务。
以下是在映射(Map)类型的基础上采用映射归纳(MapReduce)来实现字数统计的范例:
- Mapper对象将每个映射的值用空格且分开。
public class WordMapper implements RMapper {
@Override
public void map(String key, String value, RCollector collector) {
String[] words = value.split("[^a-zA-Z]");
for (String word : words) {
collector.emit(word, 1);
}
}
} - Reducer对象计算统计所有单词的使用情况。
public class WordReducer implements RReducer {
@Override
public Integer reduce(String reducedKey, Iterator iter) {
int sum = 0;
while (iter.hasNext()) {
Integer i = (Integer) iter.next();
sum += i;
}
return sum;
}
} - Collator对象统计所有单词的使用情况。
public class WordCollator implements RCollator {
@Override
public Integer collate(Map resultMap) {
int result = 0;
for (Integer count : resultMap.values()) {
result += count;
}
return result;
}
} - 把上面的各个对象串起来使用:
RMap map = redisson.getMap("wordsMap");
map.put("line1", "Alice was beginning to get very tired");
map.put("line2", "of sitting by her sister on the bank and");
map.put("line3", "of having nothing to do once or twice she");
map.put("line4", "had peeped into the book her sister was reading");
map.put("line5", "but it had no pictures or conversations in it");
map.put("line6", "and what is the use of a book");
map.put("line7", "thought Alice without pictures or conversation");
RMapReduce mapReduce
= map.mapReduce()
.mapper(new WordMapper())
.reducer(new WordReducer());
// 统计词频
Map mapToNumber = mapReduce.execute();
// 统计字数
Integer totalWordsAmount = mapReduce.execute(new WordCollator()); 3. 集合(Collection)类型的使用范例
Redisson提供的RSet、 RSetCache、 RList、 RSortedSet、 RScoredSortedSet、 RQueue、 RBlockingQueue、 RDeque、 RBlockingDeque、 RPriorityQueue和RPriorityDeque这几种集合(Collection)类型的对象均可以使用这种分布式映射归纳(MapReduce)服务。
以下是在集合(Collection)类型的基础上采用映射归纳(MapReduce)来实现字数统计的范例:
public class WordMapper implements RCollectionMapper {
@Override
public void map(String value, RCollector collector) {
String[] words = value.split("[^a-zA-Z]");
for (String word : words) {
collector.emit(word, 1);
}
}
} public class WordReducer implements RReducer {
@Override
public Integer reduce(String reducedKey, Iterator iter) {
int sum = 0;
while (iter.hasNext()) {
Integer i = (Integer) iter.next();
sum += i;
}
return sum;
}
} public class WordCollator implements RCollator {
@Override
public Integer collate(Map resultMap) {
int result = 0;
for (Integer count : resultMap.values()) {
result += count;
}
return result;
}
} RList list = redisson.getList("myList");
list.add("Alice was beginning to get very tired");
list.add("of sitting by her sister on the bank and");
list.add("of having nothing to do once or twice she");
list.add("had peeped into the book her sister was reading");
list.add("but it had no pictures or conversations in it");
list.add("and what is the use of a book");
list.add("thought Alice without pictures or conversation");
RCollectionMapReduce mapReduce
= list.mapReduce()
.mapper(new WordMapper())
.reducer(new WordReducer());
// 统计词频
Map mapToNumber = mapReduce.execute();
// 统计字数
Integer totalWordsAmount = mapReduce.execute(new WordCollator());