Linux工具(三)
继Linux工具(一)和Linux工具(二),下面我们就来讲解Linux最后的两个工具,分别是代码托管的版本控制器git和代码调试器gdb。
目录
1.git-版本控制器
从0到1的实现git代码托管
检测并安装git
新建git仓库
将远程仓库克隆到本地
提交代码三板斧-add、commit和push
git log 查看日志信息
仓库开源代表着仓库可以被别人随意篡改吗?
多人协作中如何保证代码同步?(git pull同步远端和本地仓库)
.gitignore-文件过滤器
2.Linux调试器-gdb使用
gcc/g++编译模式
如何证明gcc/g++ 编译的程序是release版本?
如何让Linux以debug模式编译代码?
gdb的使用命令
程序显示与运行
断点
单句执行与监视
行动是打败焦虑最好的办法
1.git-版本控制器
git 是一种分布式版本控制系统,广泛用于软件开发和版本管理。它可以追踪文件和目录的变化,记录每个版本的修改历史,并支持多人协作开发。
从0到1的实现git代码托管
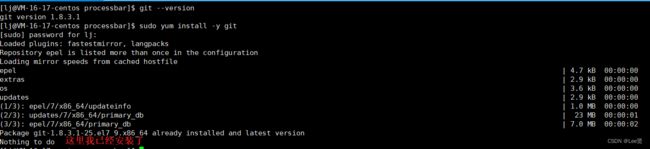
检测并安装git
首先,我们需要检查自己的环境下是否有git工具,我们可以通过命令 git --version 来查看我们的git的版本,只要能找到就说明我们有git工具,如果没有找到,我们就要安装git工具,安装我们之前也已经讲过,执行命令 sudo yum install -y git ,然后按提示操作即可。
新建git仓库
我们需要有一个自己的git账户 ,网址:Gitee - 企业级 DevOps 研发效能平台
![]()
接着,我们点击上方的加号新建仓库,然后按照需求填写仓库名称等,
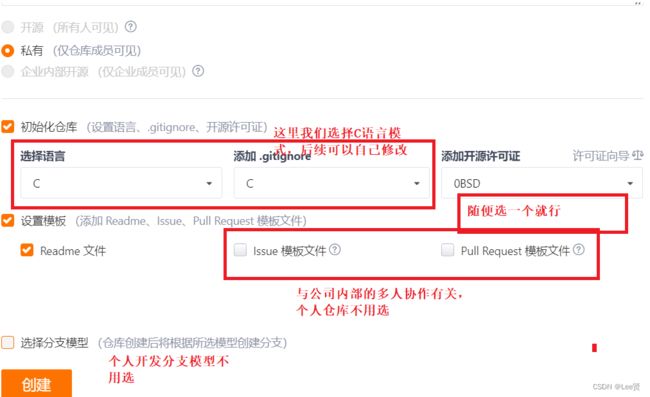
这样就可以生成我们的一个空仓库,
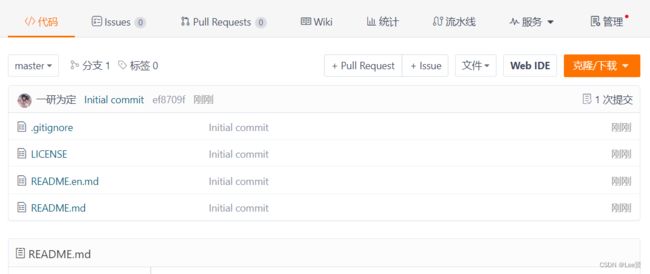
接着,我们可以将这个仓库设置为开源,让所有人都可以看到,我们在仓库页面点击管理-> 基本信息->点击开源(注意,空仓库首次开源时必须要更新代码后方可生效)即可,但是还是强烈建议在更新过代码之后再更改为私有。

将远程仓库克隆到本地
进入仓库主页,点击克隆/下载 ,我们直接用默认的http模式即可,我们复制这个网址,
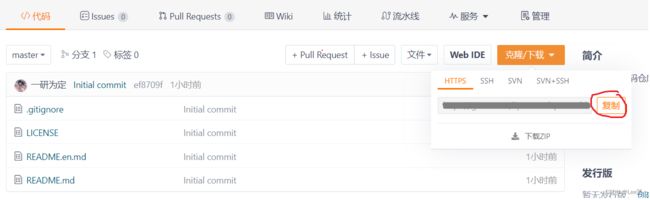
接着,我们打开XShell并进入我们对应的普通用户下,输入命令git clone +[复制的网址] ,然后,如果是第一次克隆,就会提示我们输入gitee的账户名和密码,我们就按照注册时用的账户名和密码输入即可(下面的图片没有给出输入账号和密码部分),如果你在上面的操作中就提前将你的仓库开源了,就没有有输入用户名和密码这一个环节了,但是对后续会产生什么影响,这里笔者也不太清楚~~~
这里,我首先建立了一个git目录,然后我想在git目录下将远端的仓库克隆到我们的git目录下,方便以后查找,这里也可以选择不建。
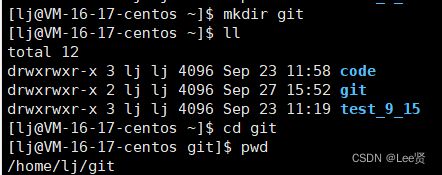
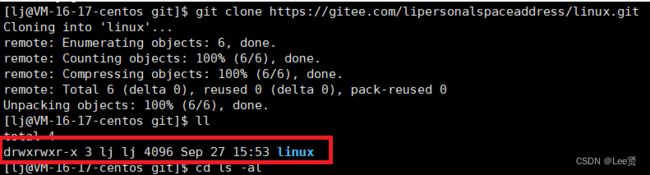
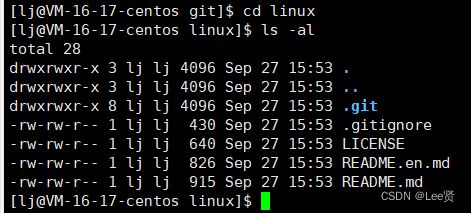
这里可以看到我们远端的仓库已经被克隆到本地目录里面来了,其实,当我们进入仓库目录,输入命令ls -al 查看所有的文件时。我们发现一个叫做 .git的文件,这个文件才是我们真正的本地仓库,在上传代码时,也是将代码传入到 .git,再由 .git将上传的代码同步到远端。
注意,这个 .git文件我们一定不要对其做任何的操作,否则仓库可能会出现问题。
提交代码三板斧-add、commit和push
如何将我们平时所写的代码提交到远程的仓库中呢?首先,我们需要找到我们对应的需要被提交的代码所在的目录,我们可以直接将保存的代码的目录拷贝到我们的仓库下,

首先,我们需要将代码提交到我们本地的仓库,也就是上面我们说的那个 .git目录,我们需要用到add和commit命令:
git add . //提交当前目录下所有能够提交的文件
//git add processbar //提交当前目录中特定的某个文件
git commit -m "对该代码的命名,一般不要乱写,因为我们在这里写的日志可以被溯源查看,这个稍后会提到" //commit命令必须要带这个命名环节,也就是日志
输入命令后,我们可能会遇到一下情况:
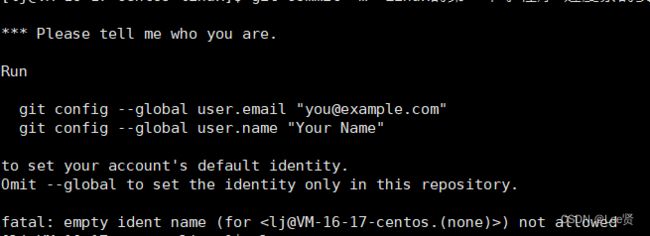
这种情况,说明我们没有配置对应的邮箱和用户名,也可能是我们第一次登录验证时使用的不是邮箱登录,或者说我们当时注册gitee账号时不是我们之前输入的登录方式注册的,具体笔者没有尝试过,不过这里我们验证就行,根据上面给我们提示的命令行,我们的邮箱就是gitee账号绑定的主邮箱,而用户名就是个人主页的“@”后面的字符串:

我们接着输入下面的两行命令,即可完成配置:
git config --global user.email "添加自己的邮箱"
git config --global user.name "个人用户名"
接着,我们就可以继续提交代码到本地仓库了,
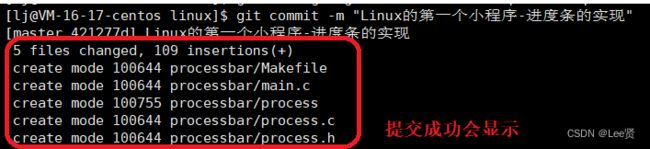
上面的操作,我们只是将我们的代码提交到了本地仓库,在远端仓库是看不到的,我们需要将我们提交的本地的代码同步到远端仓库,也就是我们的最后一个命令:push
git push然后会提示我们需要再次输入gitee的用户名和密码,我们接着输入一遍即可,这也是阻止他人恶意修改远端仓库代码的途径之一
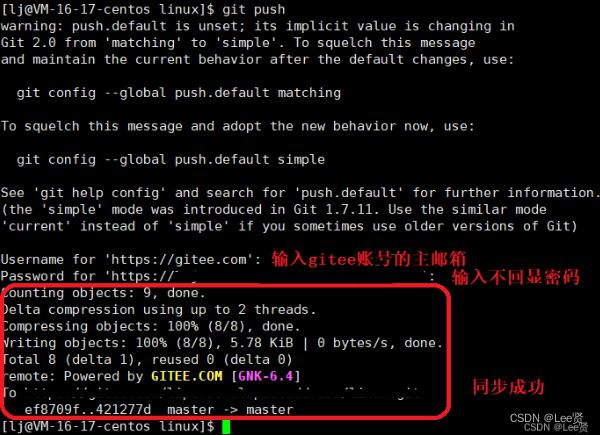
接着,我们回到我们的gitee对应的仓库页面,刷新页面,就会显示我们新上传的代码了,这里需要注意,如果你想要好看的小绿点的话,那么我们就需要在确认邮箱时保证这个邮箱使我们gitee账户绑定的邮箱才行。
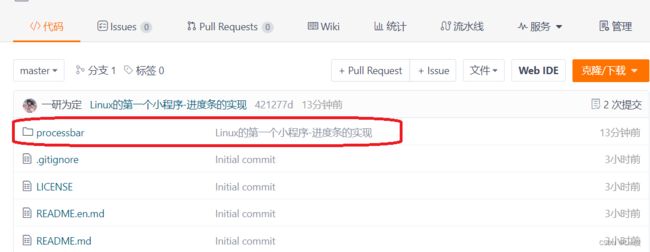
然后,为了可以让别人看到,我们可以在这里设置开源了。
git log 查看日志信息
在我们的仓库开源之后,也就一位置任何人都能访问我们的仓库了,其他人只需要将我们的仓库克隆到他的本地,就能够查看我们的代码提交信息了,比如git log就可以查看仓库主人的代码提交日志,
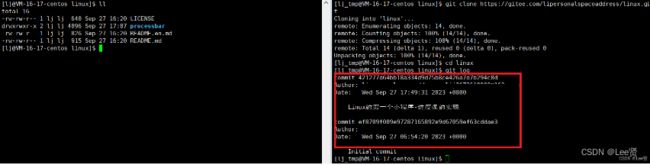
现在其实是有三个身份,分别是本地仓库,远端仓库和其他访问人员(比如面试官等)
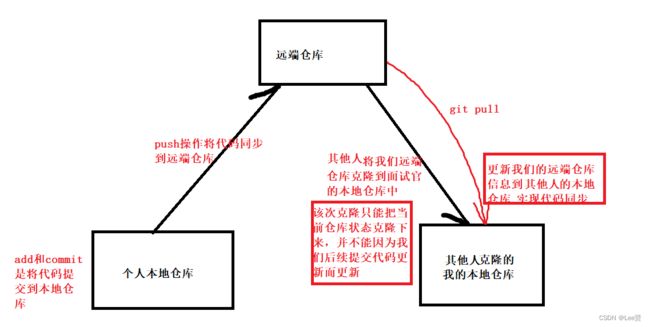
仓库开源代表着仓库可以被别人随意篡改吗?
有些人可能会好奇,我把仓库开源了,是不是任何人只要克隆了我的仓库到本地,就一定能修改我自己的代码呢?这个是不一定的,对于开源的仓库,虽然任何人都有了克隆仓库到自己本地的权利,但是其他人将自己修改的代码想要更新同步到我的仓库就必须要有仓库主人的允许,比如,其他人在push阶段会出现验证仓库主任的账号和密码行为,只要其他人不能push,他们再怎么玩都只能在自己的本地仓库上玩,永远影响不到远端仓库。
多人协作中如何保证代码同步?(git pull同步远端和本地仓库)
多人协作的本质是其他人将同一个人的仓库克隆到各自的本地仓库中,每个人都在这个本地仓库中贡献自己的代码,但是,如何保证多人开发中的代码仓库的内容时同步的呢?比如,张三刚克隆了李四的代码仓库到本地,紧接着李四又在自己的代码仓库中更新提交了一份代码并push同步到了远程仓库,而此时张三并不知情,他此时也想向这个仓库中贡献自己的代码,但是,当张三写完代码并且尝试着push到这个仓库时,就会出现问题,提示我们出现了错误,这是我们就能意识到张三这小子背着我又偷偷更新了代码了,然后我们就需要再次pull将我们本地的仓库再次和朱咱三的远端仓库进行同步之后再进行我们的协作,这样一来,就能够保证团队中的每个人都能实时同步代码到他们的本地仓库中。
.gitignore-文件过滤器
在我们的本地仓库中有一个 .ignore文件,这个文件在本地起一个类似于“过滤器”的作用,可以拦截特定后缀的文件,在我们上传代码时,就会拦截对应后缀的文件,使其不会被提交到远端仓库,我们也可以打开这个文件看一下,
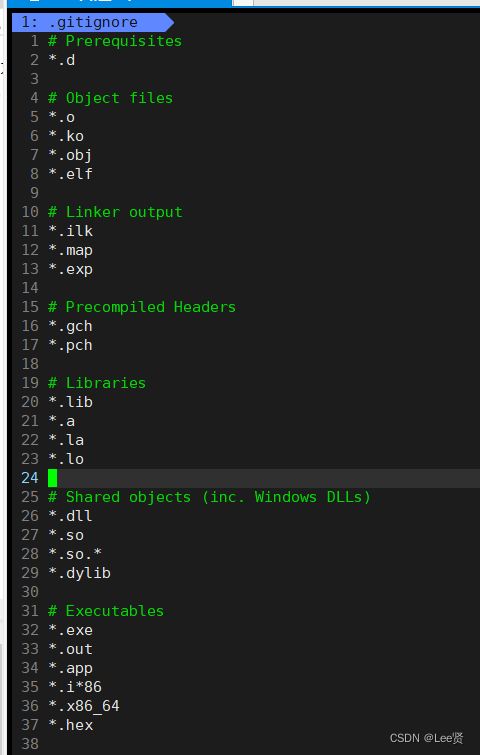
像这个文件里面含有的特定后缀的文件,均不会被提交到远端仓库中,我们也可以随意的自己定义,对远端提交仓库的文件类型进行限制,日常我们自己提交代码基本不需要修改该文件,需要修改时,我们可以直接将需要拦截的文件后缀添加到 .gitignore 中即可。
2.Linux调试器-gdb使用
gcc/g++编译模式
程序的发布方式有两种,debug模式和release模式,Linux下gcc/g++出来的二进制程序,默认是release模式,一份代码如果希望被调试,那么这份代码的发布模式必须是debug模式,在开模式下,我们一般都是采用debug版本,方便我们测试程序,完成开发后,我们将程序设置为release版本,交给后续的测试人员再次进行测试,release版本是对debug版本的各种优化,release版本一般就会是用户使用的版本,而测试人员就需要对用户测试人员的版本进行测试,所以,测试人员测试的都是release版本,测试完毕就会将程序以release版本发布到公司对应的服务器上供其他人下载使用,这里一般都会分批上线,也就是先选择一小批用户进行下载,没有发现问题,再逐步开放至全体用户,这就是所谓的灰度上线,和我们日常的听说的游戏内测的概念差不多。
如何证明gcc/g++ 编译的程序是release版本?
我们尝试编写如下的代码并运行生成可执行程序,
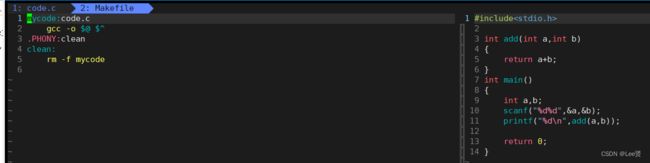
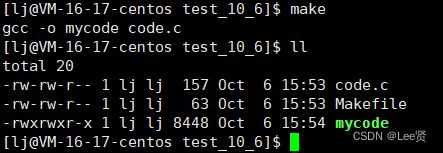
输入命令 gdb mycode ,
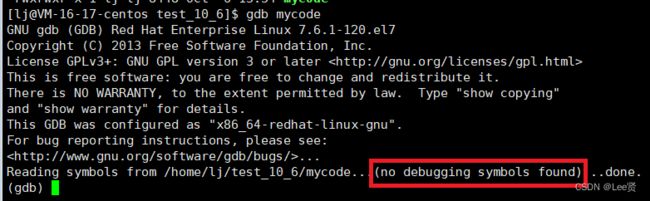
我们可以发现,gdb 没有找到可以进行调试的debug标志,也就代表这份代码不能被调试,间接证明了Linux默认情况下生成的代码是release版本的。
当然,我们还有一些更加直接的方式来证明,比如,按我们正常的理解,debug模式下的程序大小一般都会比release模式下大,因为debug模式会给程序某些调试信息,我们可以利用同一份代码,同时编译出debug和release版本的两个不同的可执行程序来比较其大小,这一点比较简单,这里就只给出对应的结果。
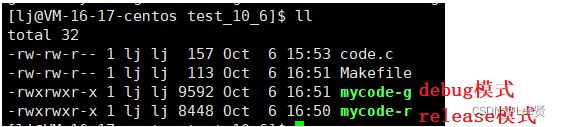
在Linux中,形成的可执行程序有一个确定的格式,ELF格式,里面包含了这个可执行程序的信息,我们可以通过浏览不同编译模式下,其形成的可执行程序的二进制信息,来查看对应的可执行程序中是否有debug信息。
//查看release模式编译的代码的信息中是否含有debug标志,grep管道过滤 ,-i表示忽略大小写
readelf -S mycode-r | grep -i debug
//查看debug模式编译的代码的信息中是否含有debug标志
readelf -S mycode-g | grep -i debug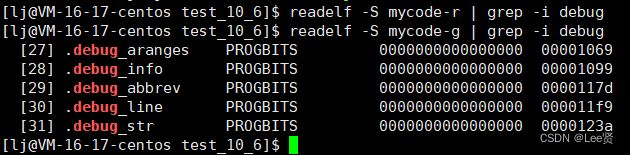
如何让Linux以debug模式编译代码?
我们可以通过在编译指令后面加 -g ,来表示我们想要以debug模式编译代码,像上面的代码,我们可以直接修改makefile文件即可,
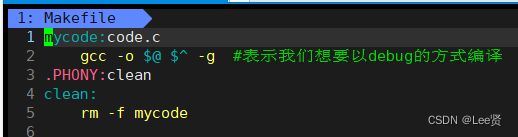
下面,我们再次使用gdb来尝试调试新的可执行程序mycode,此时代码就不再显示找不到debug标志了,说明此时代码是debug版本。
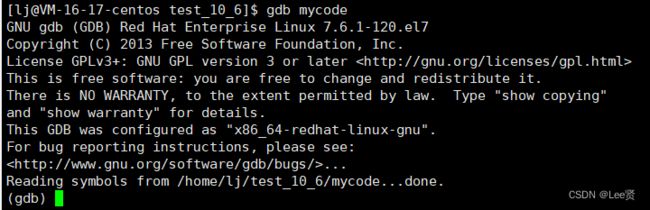
gdb的使用命令
程序显示与运行
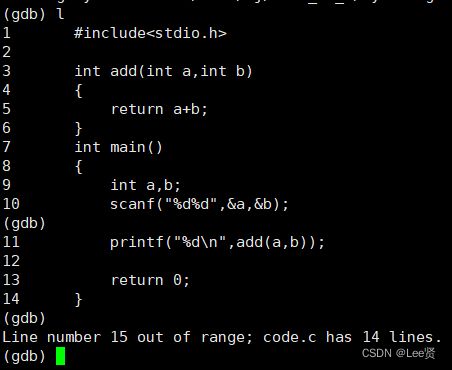
list(l) (行号):显示当前输入行号(不输入时默认从0开始),接着上次的位置往下列,每次列10行,这里有一个细节,gdb具有自动记录上一次命令和结果的功能,如果我们的程序大于十行,而我们又想让它一次显示完我们的程序,我们可以在第一次输入list命令后直接一直按回车就可以打印完全部程序。
r或run:运行程序。 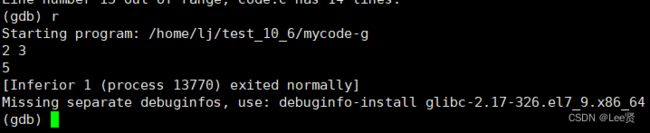
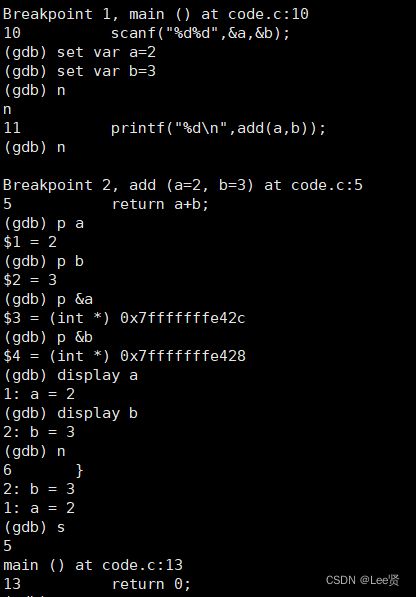
断点
在vs中,在调试时我们经常会以打断点然后按F5直接将程序运行到断点处停下来供我们调试,那么在gcc/g++中如何利用断点的呢?
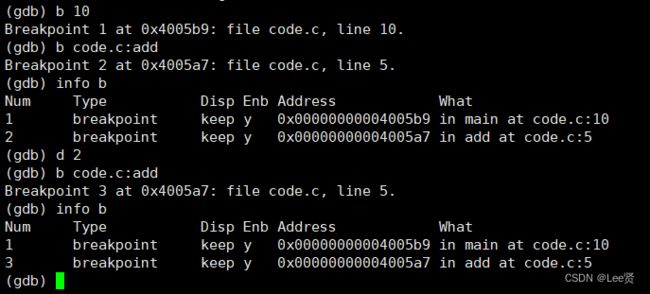
break(b) 行号:在某一行设置断点
break(b) 函数名:在某个函数开头设置断点
info break(b):查看断点信息。
这里的打断点命令还可以分文件进行,也就是说,我们可以通过指定文件来给特定的文件里的某一行打断点,这一点正是适用于多文件编译模式。
delete(d) breakpoints:删除所有断点
delete(d) n:删除序号为n的断点(注意,这里删除断点要根据断点的编号来删除,不能像我们打断点一样删除)
注:断点的序号在一个调试周期内会一直递增,换句话说,断点编号会一直维持递增状态,不论某个断点是否已经被删除,举个例子,比如我们在一个gdb调试周期内,删除了序号为3的断点,那么此后我们打的断点编号将会是大于3的,这个状态在整个gdb调试周期内都有效,一个gdb调试周期内设置的断点,也会随着该gdb调试周期的结束而自动销毁。
disable :禁用断点
enable :启用断点
单句执行与监视
n 或 next:单条执行,相当于vs中的逐过程,相当于F10
s或step:进入函数调用,相当于vs中的逐语句,也就是F11
p 变量(&变量):打印变量值或者变量的地址
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
undisplay:取消对先前设置的那些变量的跟踪,注意这个命令和删除断点命令相似,需要我们输入对应的变量名对应的编号,该命令才能生效,
until 行号:跳至X行,通常用来跳出一个循环或者函数
finish:执行到当前函数返回,然后停下来等待命令
continue(或c):从当前位置开始一直执行到下一个断点处
bt:查看调用堆栈,函数栈帧信息
set var :修改变量的值
quit(或ctrl+d):退出gdb
由于调试的场景过多,这里不可能一一介绍完全,所以想要深入学习的话,可以自行去网上搜一下条件断点之类的拓展命令。
Linux工具篇到这里就暂时告一段落了,后序随着更加深入的学习,我们还会更加深入的学习Linux相关的工具并进行拓展,希望本系列文章可以真正帮助到大家。
行动是打败焦虑最好的办法
买了一堆书没读,报了一堆课程没上,心中有无数欲望的人,这样的人几乎没有主动做成过一件事,比如养成早起、跑步、阅读的习惯,练就一些技能,或者考个好成绩,有高收入等等。
行动,是打败焦虑的最好的方法。当你不知道该怎么办的时候,就把手头的每件小事做好,当你不知道怎么开始时,就把离你最近的那件事情做好。
有时候,坚持了你不想干的事之后,便会得到你想要的东西,自律的苦轻于鸿毛,后悔的痛重于泰山。像每天早睡早起,坚持锻炼,你就已经战胜了大多数的人。你退缩的越多,能让你喘息的空间就越有限,“再见少年拉满弓,不惧岁月不惧风”,你的未来是什么样取决于你现在做什么样的选择。
