【linux】CentOS8 Hadoop伪分布式环境搭建(三台节点机)
文章目录
- 前言
- 一、伪分布式集群分别是什么?
- 二、安装Hadoop
- 三、伪分布式环境搭建
- 四、添加两个节点机
- 五、启动hadoop
前言
1.本篇文章主要参考博客:点击进入,整合了伪分布的环境搭建和一些踩坑事项。
2.环境搭建的节点机一共三台:pc1,pc2,pc3 ,其中pc1为管理机,三台节点机都使用用户Sillyhumans,如果你三台机器的用户名不一样,下面配置地址的时候可能要略作修改。
3.关闭防火墙后操作。
4.让管理机可以ssh免密登录到其他的节点机(包括他自己)。
5.保证管理机可以ping外网
一、伪分布式集群分别是什么?
简单来说就是一台机器上模拟多台机器的集成分布(假装自己有多台服务器)
二、安装Hadoop
首先下载Hadoop:点击进入下载
我下的版本是3.3
上传到l用户目录下进行解压
tar -zxvf hadoop-3.3.0.tar.gz
解压完成后修改文件名字为hadoop
mv hadoop-3.3.0 hadoop
接着配置环境变量,进入.bashrc文件,再文件末尾添加如下代码
export HADOOP_HOME=/home/Sillyhumans/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后保存退出,执行命令使配置生效
source .bashrc
验证:输入hadoop version,若出现版本信息,说明配置成功

三、伪分布式环境搭建
配置hosts文件中的映射
su root
输入密码
vi /etc/hosts
在末尾添加如下:
192.168.100.1 pc1
192.168.100.2 pc2
192.168.100.3 pc3
然后把hosts文件发送到pc2和pc3的root目录下
scp /etc/hosts root@pc2:/etc/
scp /etc/hosts root@pc3:/etc/
进入hadoop目录下的etc/hadoop文件
编辑如下几个文件,根据自己的主机名做修改(若权限不够可先切为root用户)
vi core-site.xml
修改为如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/Sillyhumans/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://pc1:9000
</property>
</configuration>
vi hdfs-site.xml
修改为如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/Sillyhumans/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/Sillyhumans/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>dfs://pc1:9870
</property>
</configuration>
vi hadoop-env.sh
在其中添加jdk路径:export JAVA_HOME=/home/Sillyhumans/java
vi mapred-site.xml
修改为如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
</configuration>
vi yarn-site.xml
修改为如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
四、添加两个节点机
可能会出现的问题:查看ip地址,输入
ip addr
观察ens33出现的ip地址,此时可能会出现两个ip,如图:

其中一个是自己设置的地址,另一个为动态地址,在配置hadoop时会使用服务器的动态地址导致管理界面不会显示其他节点机的信息,需要编辑ifconfig-ens33
vi /etc/sysconfig/network-scripts/ifcfg-ens33
将其中的BOOTPROTO的值改为static,重启服务器。
接着编辑hadoop的workers文件
vi ~/hadoop/etc/hadoop/workers
添加节点机
Sillyhumans@pc1
Sillyhumans@pc2
Sillyhumans@pc3
保存后将hadoop和.bashrc发送到pc2和pc3
su Sillyhumans
scp -r hadoop Sillyhumans@pc2:~/
scp -r hadoop Sillyhumans@pc3:~/
scp .bashrc Sillyhumans@pc2:~/
scp .bashrc Sillyhumans@pc3:~/
在pc2和pc3分别使.bashrc生效
到pc2上
source .bashrc
验证 hadoop version
pc3
source .bashrc
验证 hadoop version
保存
五、启动hadoop
第一次启动需要格式化,首先进入到sbin中,输入如下
cd ~/hadoop/sbin
hdfs namenode -format
其中出现选择项选择y
开启hadoop
start-all.sh
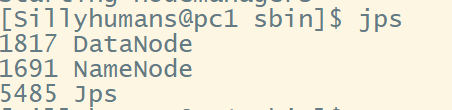
验证:在各个节点机上输入jps
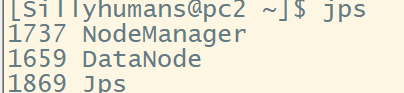
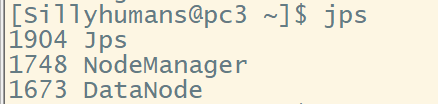
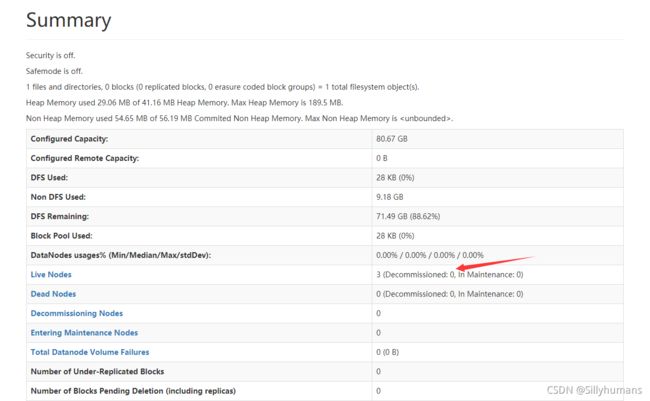
进入浏览器,地址栏输入192.168.100.1:9870 进入管理界面,此时有三个节点机表示成功