机器学习---RBM、KL散度、DBN
1. RBM
1.1 BM
BM是由Hinton和Sejnowski提出的一种随机递归神经网络,可以看做是一种随机生成的
Hopfield网络,是能够通过学习数据的固有内在表示解决困难学习问题的最早的人工神经网络之
一,因样本分布遵循玻尔兹曼分布而命名为BM。BM由二值神经元构成,每个神经元只取1或0这两
种状态,状态1代表该神经元处于接通状态,状态0代表该神经元处于断开状态。在下面的讨论中单
元和节点的意思相同,均表示神经元。

上图为一个玻尔兹曼机(BM),其蓝色节点为隐层,白色节点为输入层。玻尔兹曼机和递归神经
网络相比,区别体现在以下几点:
①递归神经网络(RNN)本质是学习一个映射关系,因此有输入和输出层的概念,而玻尔兹曼机
的用处在于学习一组数据的“内在表示”,因此其没有输出层的概念。
②递归神经网络各节点链接为有向环,而玻尔兹曼机各节点连接成无向完全图。
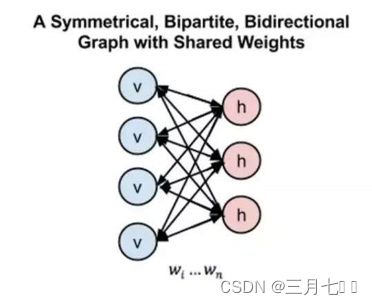
1.2 RBM
限制玻尔兹曼机中,所谓的限制就是:将完全图变成了二分图。如图所示,限制玻尔兹曼机
由三个显层节点和四个隐层节点组成。

RBM中,所有可见单元和隐单元之间存在连接,而隐单元两两之间和可见单元两两之间不存
在连接,也就是层间全连接,层内无连接(这也是和玻尔兹曼机BM模型的区别,BM是层间、层内
全连接)。其中,每一个节点(无论是Hidden Unit还是Visible Unit)都有两种状态:处于激活状
态时值为1,未被激活状态值为0。
这里的0和1状态的意义是代表了模型会选取哪些节点来使用,处于激活状态的节点被使用,未
处于激活状态的节点未被使用。节点的激活概率由可见层和隐藏层节点的分布函数计算。
RBM本质是无监督学习(Unsupervised Learning)的利器(Hinton和吴恩达都认为:将来的
机器学习任务慢慢都会转变为无监督学习的),因为,它可以用于降维(隐层少一点),学习特征
(隐层输出就是特征),自编码器(AutoEncoder)以及深度信念网络(多个RBM堆叠而成)等。
RBM是两层神经网络,这些浅层神经网络是DBN(深度信念网络)的构建块,RBM的第一层
被称为可见层或输入层,他的第二层被称为输出层。

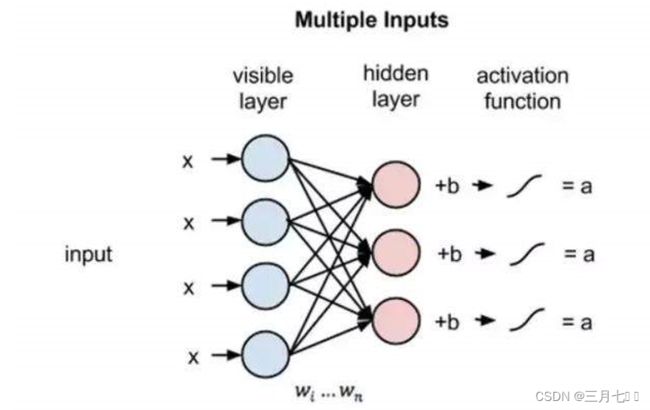
上图的每一个圆圈代表一个类似的神经元节点, 这个节点通常是产生计算的地方,相邻层的
节点是连接的,但是同层的节点是不连接的。
每个输入单元以数据集样本中的低级特征作为输入。例如,对于一个由灰度图组成的数据集,
每个输入节点都会接收图像中的一个像素值。MNIST 数据集有784个像素点,所以处理它们的神经
网络必须有784个输入节点。
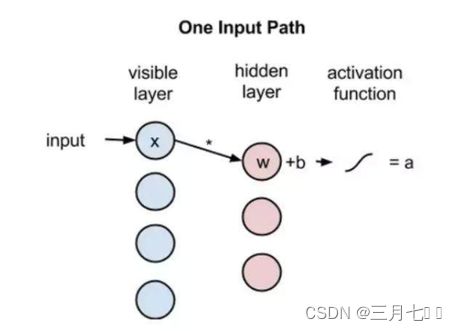
现在让我们跟随单像素穿过这两层网络。在隐藏层的节点1,x和一个权重相乘,然后再加上一
个偏置项。这两个运算的结果可作为非线性激活函数的输入,在给定输入x时激活函数能给出这个
节点的输出,或者信号通过它之后的强度。这里其实和我们常见的神经网络是一样的过程。
activation f((weight w*input x)+bias b)=output a
如果这两层是更深网络的一部分,那么第一个隐藏层的输出会被传入到第二个人隐藏层作为
输入,从这里开始就可以有很多隐藏层,直到他们增加到最终的分类层,对于简单的前馈网络,
RBM起着自编码器的作用,除此之外,别无其它。

1.3 重建(Reconstruction)
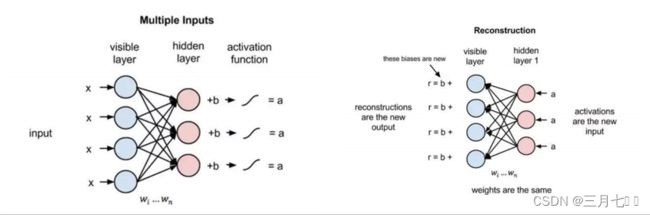
但是在本文关于RBM的介绍中,我们会集中讨论它们如何以一种无监督的方式通过自身来重
建数据,这使得在不涉及更深层网络的情况下,可见层和第一个隐藏层之间会存在数次前向和反向
传播。
在重建阶段,第一个隐藏层的激活状态变成了反向传递过程中的输入。它们与每个连接边相
同的权重相乘,就像x在前向传递的过程中随着权重调节一样。这些乘积的和在每个可见节点处又
与可见层的偏置项相加,这些运算的输出就是一次重建,也就是对原始输入的一个逼近。这可以通
过下图表达:

因为RBM的权重是随机初始化的,所以,重建结果和原始输入的差距通常会比较大。你可以
将r和输入值之间的差值看做重建误差,然后这个误差会沿着 RBM的权重反向传播,以一个迭代学
习的过程不断反向传播,直到达到某个误差最小值。
在前向传递过程中,给定权重的情况下 RBM 会使用输入来预测节点的激活值,或者输出的概
率 x:p(a|x; w)。
但是在反向传播的过程中,当激活值作为输入并输出原始数据的重建或者预测时,RBM 尝试
在给定激活值a的情况下估计输入x的概率,它具有与前向传递过程中相同的权重参数。这第二个阶
段可以被表达为p(x|a;w)
这两个概率估计将共同得到关于输入x和激活值a的联合概率分布,或者p(x,a)。重建与回
归有所不同,也不同于分类。回归基于很多输入来估计一个连续值,分类预测出离散的标签以应用
在给定的输入样本上,而重建是在预测原始输入的概率分布。
这种重建被称之为生成学习,它必须跟由分类器执行的判别学习区分开来。判别学习将输入
映射到标签上,有效地在数据点与样本之间绘制条件概率。若假设 RBM的输入数据和重建结果是
不同形状的正态曲线,它们只有部分重叠。
在RBM中,任意两个相连的神经元之间有一个权值w表示其连接强度,每个神经元都有一个偏
置系数b(对显层神经元)和c(对隐层神经元)来表示自身权重。
这样,就可以用一个函数来表示一个RBM的能量:
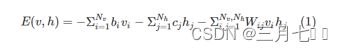
在一个RBM中,一个隐藏神经元 hj 被激活的概率:
![]()
由于是双向连接,显层神经元也可以被隐层神经元激活:
![]()
其中,σ代表代表sigmoid函数,也可以设定其他函数。
为了衡量输入数据的预测概率分布和真实分布之间的距离,RBM使用KL散度来度量两个分布
的相似性。KL散度测量的是两条曲线的非重叠区域或者说发散区域,RBM的优化算法尝试最小化
这些区域,所以当共享权重与第一个隐藏层的激活值相乘时就可以得出原始输入的近似。图的左边
是一组输入的概率分布p及其重构分布q,图的右侧是它们的差的积分。

迭代的根据它们产生的误差来调节权重,RBM学会了逼近原始数据,你可以说权重在慢慢地
反应输入数据的结构,并通过隐藏层的激活值进行编码学习过程就像两个概率分布在逐渐重合。

2. KL散度
2.1 例子
假设我们是一群太空科学家,经过遥远的旅行,来到了一颗新发现的星球。在这个星球上,生
存着一种长有牙齿的蠕虫,引起了我们的研究兴趣。我们发现这种蠕虫生有10颗牙齿,但是因为不
注意口腔卫生,又喜欢嚼东西,许多蠕虫会掉牙。收集大量样本之后,我们得到关于蠕虫牙齿数量
的经验分布:
显然我们的原始数据并非均分布的,但也不是我们已知的分布,至少不是常见的分布。作为备
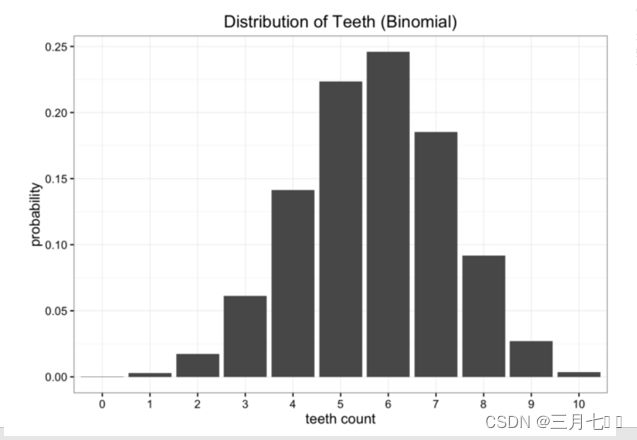
选,我们想到的另一种简单模型是二项式分布(binomlal distribution)。蠕虫嘴里面共有n=10个牙
槽,每个牙槽出现牙齿与否为独立事件,且概率均为p。则蠕虫牙齿数量即为期望值E[x]=np,真实
期望值即为观察数据的平均值,比如说5.7,则p=0.57,得到如下图所示的二项式分布:

KL散度源于信息论。信息论主要研究如何量化数据中的信息。最重要的信息度量单位是熵
(Entropy),一般用H表示。分布的熵的公式如下:
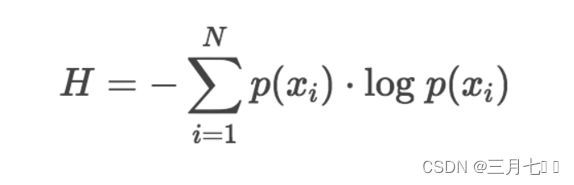
上面对数没有确定底数,可以是2、e或10,等等。如果我们使用以2为底的对数计算H值的
话,可以把这个值看作是编码信息所需要的最少二进制位个数(bits)。上面空间蠕虫的例子中,信
息指的是根据观察所得的经验分布给出的蠕虫牙齿数量。计算可以得到原始数据概率分布的熵值为
3.12 bits。这个值只是告诉我们编码蠕虫牙齿数量概率的信息需要的二进制位bit的位数。
2.2 KL散度度量信息损失
只需要稍微修改熵H的计算公式就能得到KL散度的计算公式,设p为观察得到的概率分布,q为
另一分布来近似p,则p、q的KL散度为:

显然,根据上面的公式,KL散度其实为数据的原始分布p与近似分布q之间的对数差值的期
望,如果继续用2为底的对数计算,用KL散度值表示信息损失的二进制位数,下面用公式以期望表
达KL散度:
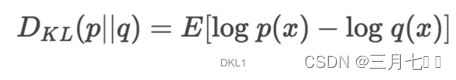
一般,KL散度以下面的书写更常见:

对比两种分布:
首先是均匀分布来近似原始分布的KL散度:

接下来计算用二项分布 :

通过上面的计算可以看出,通过均匀分布近似原始分布的信息损失要比二项分布的值小,因
此,在这个例子中,均匀分布更好一些。
3 DBN
3.1 多层受限玻尔兹曼机
一旦 RBM 学到了与第一隐藏层激活值有关的输入数据的结构,那么数据就会沿着网络向下传
递一层。你的第一个隐藏层就成为了新的可见层或输入层。这一层的激活值会和第二个隐藏层的权
重相乘,以产生另一组的激活。
这种通过特征分组创建激活值集合序列,并对特征组进行分组的过程是特征层次结构的基础,
通过这个过程,神经网络学到了更复杂的、更抽象的数据表征。
它们是一种无向图模型,也被称作马尔科夫随机场。
了解工作原理之后就可以看看RBM是如何通过数据学习的了:
RBM共有五个参数:h、v、b、c、W,其中b、c、W,也就是相应的权重和偏置值,是通过
学习得到的。(v是输入向量,h是输出向量)
对于一条样本数据x,采用对比散度算法对其进行训练:
将x赋给显层的,利用(2)式计算出隐层中每个神经元被激活的概率P(h1|v1);
从计算的概率分布中采取Gibbs抽样抽取一个样本:
![]()
用h1重构显层,即通过隐层反推显层,利用(3)式计算显层中每个神经元被激活的概率P
(v2|h1);
同样地,从计算得到的概率分布中采取Gibbs抽样抽取一个样本:
![]()
通过v2再次计算隐层中每个神经元被激活的概率,得到概率分布P(h2|v2)
更新权重:

若干次训练后,隐层不仅能较为精准地显示显层的特征,同时还能够还原显层,当隐层神经元
数量小于显层时,则会产生一种“数据压缩”的效果,也就类似于自动编码器。
3.2 多层置信网络结构
首先,你需要用原始输入x(k)训练第一个RBM,它能够学习得到原始输入的一阶特征表
示 h^{(1)(k)}。
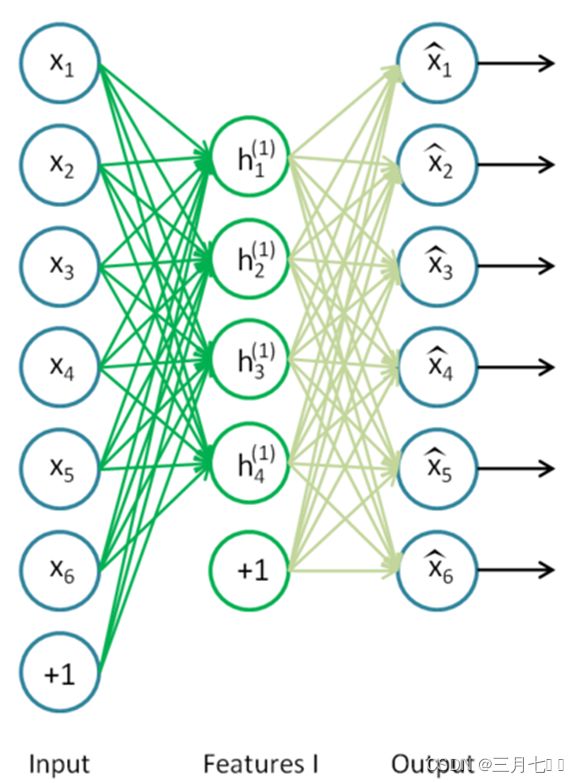
接着,你需要把原始数据输入到上述训练好的稀疏自编码器中,对于每一个输入 x(k),都可以
得到它对应的一阶特征表示 h^{(1)(k)}。然后你再用这些一阶特征作为另一个稀疏自编码器的输
入,使用它们来学习二阶特征 h^{(2)(k)}。

再把一阶特征输入到刚训练好的第二层稀疏自编码器中,得到每个h^{(1)(k)} 对应的二阶特征
激活值 h^{(2)(k)}。接下来,你可以把这些二阶特征作为softmax分类器的输入,训练得到一个能
将二阶特征映射到数字标签的模型。
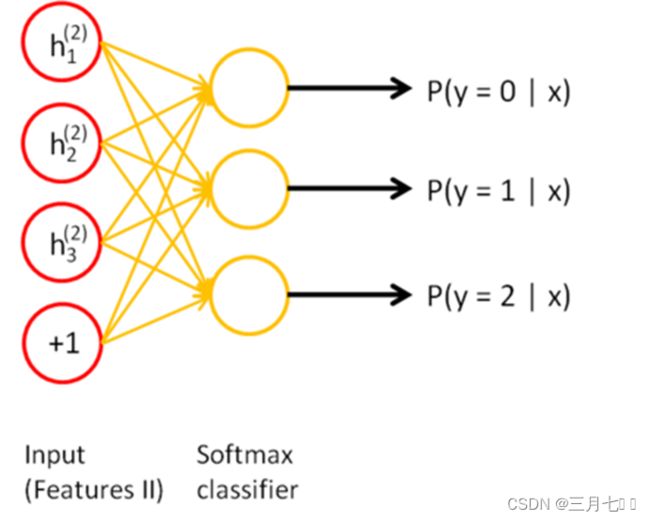
最终,你可以将这三层结合起来构建一个包含两个隐藏层和一个最终softmax分类器层的栈式
自编码网络,这个网络能够如你所愿地对MNIST数字进行分类。

DBNs由多个限制玻尔兹曼机(Restricted Boltzmann Machines)层组成,一个典型的神经网
络类型如图所示。

最终在构筑好整个网络后,相当于进行了一次完整的无监督学习。在确定了网络的权值后,再
次根据样本,以BP神经网络的算法,进行一次有监督的学习过程。这一过程被称为多层置信网络
的微调。