【LeetCode高频SQL50题-基础版】打卡第1天:第1~10题
文章目录
- 【LeetCode高频SQL50题-基础版】打卡第1天:第1~10题
-
- ⛅前言
- 可回收且低脂的产品
-
- 题目
- 题解
- 寻找用户推荐人
-
- 题目
- 题解
- 大的国家
-
- 题目
- 题解
- 文章浏览I
-
- 题目
- 题解
- 无效的推文
-
- 题目
- 题解
- 使用唯一标识码替代员工ID
-
- 题目
- 题解
- 产品销售分析I
-
- 题目
- 题解
- 进店却未进行交易的顾客
-
- 题目
- 题解
- 上升的温度
-
- 题目
- 题解
- 每台机器的进程平均运行时间
-
- 题目
- 题解
【LeetCode高频SQL50题-基础版】打卡第1天:第1~10题
⛅前言
在这个博客专栏中,我将为大家提供关于 LeetCode 高频 SQL 题目的基础版解析。LeetCode 是一个非常受欢迎的编程练习平台,其中的 SQL 题目涵盖了各种常见的数据库操作和查询任务。对于计算机科班出身的同学来说,SQL 是一个基础而又重要的技能。不仅在面试过程中经常会遇到 SQL 相关的考题,而且在日常的开发工作中,掌握 SQL 的能力也是必备的。
本专栏的目的是帮助读者掌握 LeetCode 上的高频 SQL 题目,并提供对每个题目的解析和解决方案。我们将重点关注那些经常出现在面试中的题目,并提供一个基础版的解法,让读者更好地理解问题的本质和解题思路。无论你是准备找工作还是提升自己的技能,在这个专栏中,你可以学习到很多关于 SQL 的实践经验和技巧,从而更加深入地理解数据库的操作和优化。
我希望通过这个专栏的分享,能够帮助读者在 SQL 的领域里取得更好的成绩和进步。如果你对这个话题感兴趣,那么就跟随我一起,开始我们的 LeetCode 高频 SQL 之旅吧!
- 博客主页:知识汲取者的博客
- LeetCode高频SQL100题专栏:LeetCode高频SQL100题_知识汲取者的博客-CSDN博客
- Gitee地址:知识汲取者 (aghp) - Gitee.com
- 题目来源:高频 SQL 50 题(基础版) - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台
可回收且低脂的产品
题目
题目来源:1757.可回收且低脂的产品

题解
select product_id from products where low_fats='Y' and recyclable='Y';
寻找用户推荐人
题目
题目来源:584.寻找用户推荐人

题解
select name from customer where referee_id is null or referee_id!=2;
注意:null不参与比较运算,所以直接这样写select name from customer where referee_id!=2会直接忽略空字段,从而得到错误的答案,所以切勿踩坑
大的国家
题目
题目来源:595.大的国家

题解
select name, population, area from world where area >= 3000000 or population >= 25000000;
使用 or 会使索引会失效,在数据量较大的时候查找效率较低,通常建议使用 union 代替 or
select name, population, area from world where area >= 3000000
union
select name, population, area from world where population >= 25000000;
UNION 和 OR 之间的比较:
对于单列来说,用 or 是没有任何问题的,但是 or 涉及到多个列的时候,每次 select 只能选取一个index,如果选择了area,population就需要进行table-scan,即全部扫描一遍,但是使用union就可以解决这个问题,分别使用area和 population上面的index进行查询。 但是这里还会有一个问题就是,UNION会对结果进行排序去重,可能会降低一些 performance (这有可能是方法一比方法二快的原因),所以最佳的选择应该是两种方法都进行尝试比较
文章浏览I
题目
题目来源:1148.文章浏览I

题解
可以选择直接使用 distinct 对 author_id 进行去重
select distinct author_id as id
from views
where author_id = viewer_id
order by id;
SQL优化:使用 group by 对 author_id 进行去重
select author_id as id
from views
where author_id = viewer_id
group by author_id
order by id;
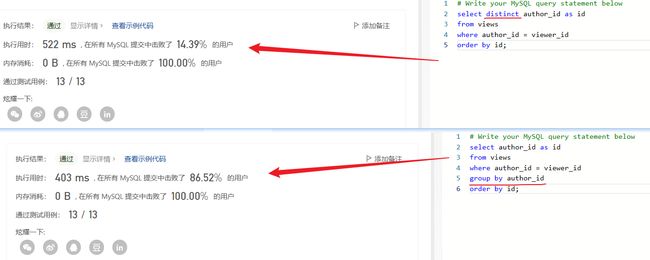
虽然它们都可以达到去重的效果,但在某些情况下,使用 GROUP BY 可能比使用 DISTINCT 更高效。
这主要是因为 GROUP BY 在进行聚合时,可以利用索引来提高查询性能。在 GROUP BY 操作中,数据库会将相同的值分组,并对每个组进行聚合计算。而在执行到 GROUP BY 时,数据库会使用索引来排序和分组数据。如果有适当的索引可用,那么数据库可以直接使用该索引而不需要完全扫描整个表。
另一方面,使用 DISTINCT 时,数据库需要扫描整个表来查找重复的数据并消除它们。虽然在一些情况下 DISTINCT可以利用索引优化,但它通常需要完全扫描数据,因此在数据量较大时可能会导致性能下降。
总的来说,当需要去重时,如果已经存在适当的索引,并且可以在 GROUP BY 条件下进行聚合操作,那么使用 GROUP BY 可能会更高效。但是在其他情况下,使用 DISTINCT 或者其他优化手段可能更合适。
注意:性能的比较也受到具体数据库实现、查询条件、数据量和索引等因素的影响,因此在实际应用中最好进行测试和评估以确定最佳的方法。
温馨提示:8.0之前的版本distinct的效率要比group by的去重效率高,因为group by会有隐式排序,8.0之后group by移除了隐式排序,所以8.0之后的版本,这两个效率近乎相当
无效的推文
题目
题目来源:1638.无效的推文

题解
这里主要考察对length函数的使用
select tweet_id from tweets where length(content) > 15;
使用唯一标识码替代员工ID
题目
题目来源:1638.无效的推文

题解
直接使用左接连,so easy
select tb2.unique_id, tb1.name
from Employees tb1 left join EmployeeUNI tb2 on tb1.id = tb2.id;
产品销售分析I
题目
题目来源:1068.产品销售分析I

题解
-
解法一:使用左(外)连接(
left outer join,简写left join)这里直接使用左连接,但是需要注意左连接的顺序,题目中要求是查询Sales表中所有的产品,所以要最先写Sales,这样才能保障查询的结果包含Sales表中所有的产品
select p.product_name, s.price, s.year from Sales s left join Product p on s.product_id = p.product_id; -
解法二:使用内连接(
inner join,简写join)如果使用内连接,就不需要关注是先写Sales还是先写Product了。但是使用内连接
select p.product_name, s.year, s.price from Sales s join Product p on s.product_id = p.product_id备注:在一般情况下,内连接(INNER JOIN)比左连接(LEFT JOIN)的性能更高。这是因为内连接只返回两个表中匹配的行,而左连接返回匹配的行以及左边表中不匹配的行。
进店却未进行交易的顾客
题目
题目来源:1581.进店却未进行交易的顾客

题解
-
解法一:使用左连接
select v.customer_id, count(v.customer_id) count_no_trans from visits v left join transactions t on v.visit_id = t.visit_id where t.amount is null group by v.customer_id; -
解法二:使用
not in子查询select customer_id, count(customer_id ) count_no_trans from visits where visit_id not in( select visit_id from transactions ) group by customer_id;
上升的温度
题目
题目来源:197.上升的温度

题解
-
解法一:使用
jonin+datediffdatediff(date1, date2):计算 date1 与 date2 两个日期的间隔,结果为date1-date2select a.id from weather a join weather b where datediff(b.recordDate, a.recordDate) = 1 and b.Temperature > a.Temperature; -
解法二:使用
jonin+adddateadddate(date1, interval n day):在 date1 的基础上添加 n天,这里的单位可以是 second、minute、hour、weekselect a.id from weather a join weather b on(a.recordDate = adddate(b.recordDate, interval 1 day)) where a.temperature > b.temperature;
每台机器的进程平均运行时间
题目
题目来源:1661.每台机器的进程平均运行时间

题解
这里涉及到三个知识点:rount、avg、if
rount(value, n):保留指定数值(value)的小数点后 n 位(四舍五入,不够补0)
avg(value):计算value的平均值
if(condition,exp1,exp2):条件成立执行epx1,条件不成立执行exp2,作用等价于三元算符
select machine_id, round(
avg(if(activity_type='start', -timestamp, timestamp))*2, 3
) processing_time
from Activity
group by machine_id;
备注:由于 avg 计算的是所有行的平均值,而两行(start和end)才构成一个进程,因此 avg 计算得到的值乘 2 才是每个进程的平均值