redis进阶
redis.conf
启动的时候就通过配置文件来启动的!
# 这个不是配置的,就是在这儿说明一下
# 当配置中需要配置内存大小时,可以使用 1k, 5GB, 4M 等类似的格式,其转换方式如下(不区分大小写)
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# 内存配置大小写是一样的.比如 1gb 1Gb 1GB 1gB
# 包含,可以把其他的配置导入进来
# include /path/to/local.conf
# include /path/to/other.conf
# 绑定的ip,允许哪个可以访问,默认只能本地访问
# 如果需要所有访问 *
# bind 192.168.1.100 10.0.0.1
# bind 127.0.0.1 ::1
# 保护模式
# protected-mode yes
port 6379
# 以守护(后台)进程的方式运行,默认是no,
daemonize yes
# 如果以后台的方式运行,我们就需要指定一个 pid 文件
pidfile /var/run/redis_6379.pid
# 日志
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably) 生产环境
# warning (only very important / critical messages are logged)
loglevel notice
logfile "" # 日志的文件位置名
databases 16 # 数据库的数量,默认是16 个数据库
always-show-logo yes # 是否显示 开启redis 时的logo
# 快照
# 持久化,在规定的时间内,执行了多少次操作,则会持久化到文件, .rdb .aof
# redis是内存数据库,如果没有持久化,那么数据断电即失
# 900s内如果有一个key进行了修改,我们就进行持久化操作
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes # 持久化如果出错,是否还需要继续工作
rdbcompression yes # 是否压缩rdb文件,需要消耗一些cpu资源!
rdbchecksum yes # 保存rdb文件的时候,进行错误的检查校验!
dir ./ # rdb文件保存的目录
# 密码,redis默认没有密码
requirepass 123456
##########################扩展###########################
# 限制clients
maxclients 10000 # 默认限制最大1w个客户端连接
# redis 配置最大的内存容量
maxmemory <bytes>
# 内存到达上限之后的处理策略
# 移除一些过期的key
# 报错。。。
maxmemory-policy noeviction
# aof 默认不开启
# 默认是使用rdb持久化的
# 在大部分的情况下,rdb完全够用
appendonly no
# 持久化文件的名字
appendfilename "appendonly.aof"
#
# appendfsync always # 每次修改都会同步,消耗性能
appendfsync everysec # 每s执行一次,如果这1s redis宕机了,这1s的数据就没了
# appendfsync no # 不执行sync,这个时候操作系统自己同步数据,速度最快!
使用命令设置redis密码

maxmemory-policy 内存满了的处理策略

reids持久化
面试和工作,持久化都是重点!
redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以redis提供了持久化功能!
rdb

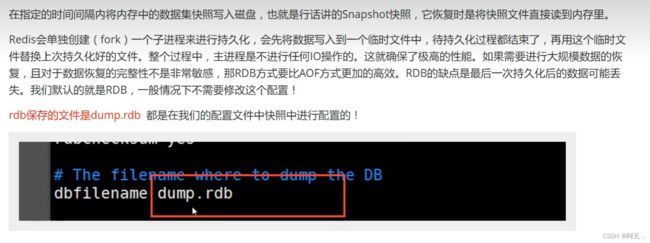
触发机制

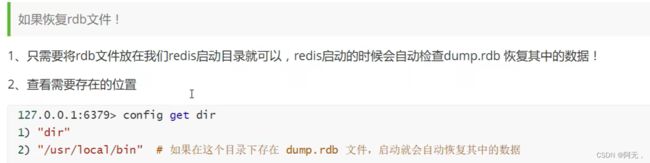
如何恢复rdb文件中的数据
有时候在生产环境,我们会将rdb文件备份!
优缺点

aof
将我们所有的写命令都记录下来,history,恢复的时候就把这个文件的命令全部执行一遍!
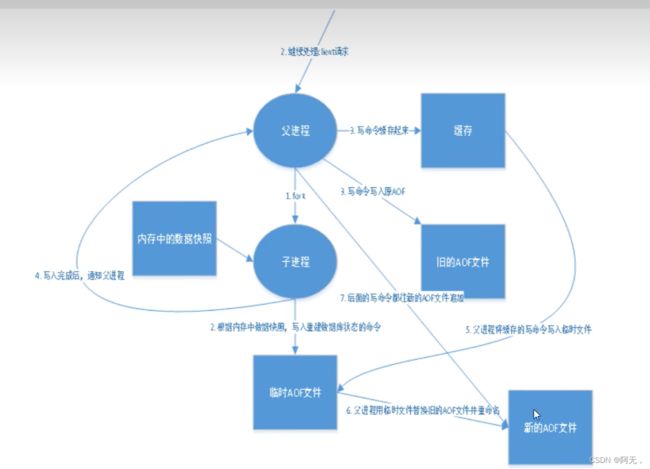

redis.conf
# 默认是不开启的,改为yes就开启了,需要重启redis
appendonly no
# appendfsync always # 每次修改都会同步,消耗性能
appendfsync everysec # 每s执行一次,如果这1s redis宕机了,这1s的数据就没了
# appendfsync no # 不执行sync,这个时候操作系统自己同步数据,速度最快!就相当于没开启aof了应该是
# 在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行fsync会造成阻塞过长时间,
# no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。
# 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes。Linux的默认fsync策略是30秒。可能丢失30秒数据。默认值为no。
no-appendfsync-on-rewrite no
# aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。
# 当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。
auto-aof-rewrite-percentage 100
# 设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写。
auto-aof-rewrite-min-size 64mb
redis-check-aof 修复aof文件
rdb也有类似文件
aof文件出现错误的话,redis是启动不起来的。
# 例如我们在里面随便敲一些,它就把它不认识的全部删掉了
redis-check-aof --fix appendonly.aof
优缺点

扩展


redis发布订阅



# 订阅端
# 订阅一个频道
127.0.0.1:6379> SUBSCRIBE mychannel
Reading messages... (press Ctrl-C to quit)
# 初始化消息
1) "subscribe"
2) "mychannel"
3) (integer) 1
# 收到发送端的消息
1) "message"
2) "mychannel"
3) "mychannelmessage"
# 发送端
# 发布一个消息
127.0.0.1:6379> PUBLISH mychannel mychannelmessage
(integer) 1
127.0.0.1:6379>

使用场景
- 实时消息系统
例如注册了csdn,就假设订阅了官方频道,官方频道就会每天给用户发送消息。
稍微复杂的场景我们就会使用消息中间件来做(mq)
主从复制

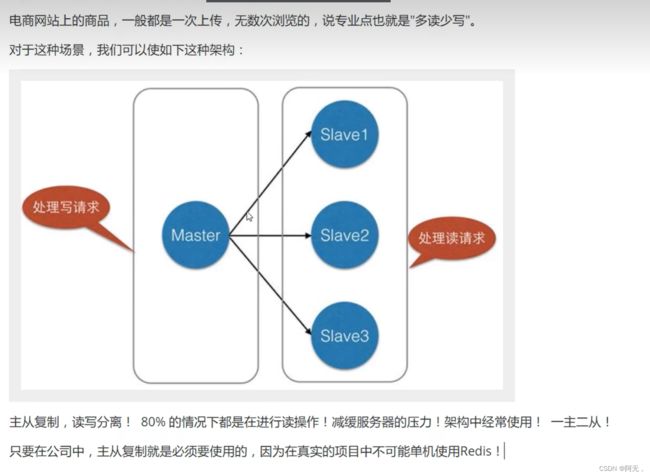
一主二从
# 查看当前服务器的信息
127.0.0.1:6379> info replication
# Replication
# redis默认角色为 主机
role:master
# 没有从机
connected_slaves:0
master_replid:2f0aa2c3a49ce3875a377a01511ff0e93787c756
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
这个是使用redis服务启动的进程,我用的是docker。


默认情况下,每台redis服务器都是主节点。我们一般情况下只配置从机就行!
# 从机配置
127.0.0.1:6379> SLAVEOF 172.17.0.4 6379
OK
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:172.17.0.4
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:14
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:0e3e3fe78d3d503e91cf345439ba6699e5ac6f4b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14
# 主机查看信息
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.17.0.5,port=6379,state=online,offset=70,lag=1
slave1:ip=172.17.0.6,port=6379,state=online,offset=70,lag=0
master_replid:0e3e3fe78d3d503e91cf345439ba6699e5ac6f4b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:70
# 命令是暂时生效,配置文件才是永久生效。
# redis.conf
replicaof <masterip> <masterport>
细节
-
主机可以写(当然也可以读),
从机不能写(写的话会报错)只能读!主机中的所有信息和数据,都会自动被从机保存。 -
主机宕机,从机依然是连接到主机的,但是没有写操作。如果主机恢复,从机依旧可以连接到主机。
-
从机宕机,在此期间主机依然在写入数据,等从机恢复,还能获取到主机这段时间的数据。
复制原理

宕机后手动配置主机
如果主机断开连接,我们可以使用slaveof no one让自己变成主机!其他的节点就可以手动连接到最新的这个主节点。
如果主机恢复,那就重新手动指定!
哨兵模式

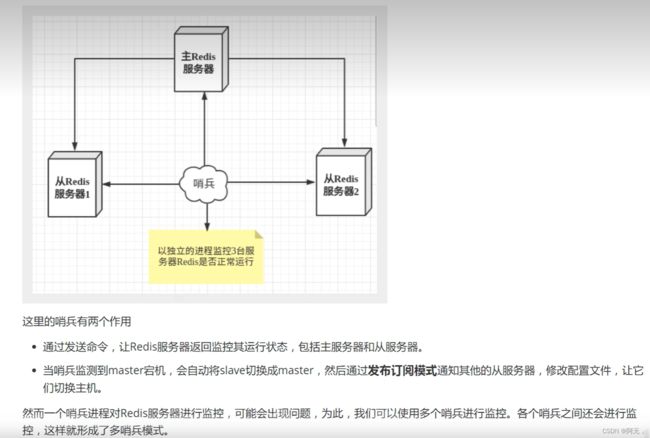
哨兵工作流程(了解)
在配置文件中通过 sentinel monitor 来定位master的IP、端口,一个哨兵可以监控多个master数据库,只需要提供多个该配置项即可。哨兵启动后,会与要监控的master建立两条连接:
- 一条连接用来订阅master的_sentinel_:hello频道与获取其他监控该master的哨兵节点信息
- 另一条连接定期向master发送INFO等命令获取master本身的信息
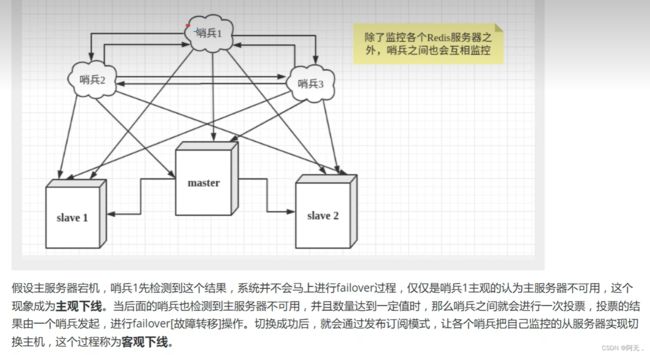
哨兵认为master客观下线后,故障恢复的操作需要由选举的领头哨兵来执行,选举采用Raft算法:
- 发现master下线的哨兵节点(我们称他为A)向每个哨兵发送命令,要求对方选自己为领头哨兵
- 如果目标哨兵节点没有选过其他人,则会同意选举A为领头哨兵
- 如果有超过一半的哨兵同意选举A为领头,则A当选
- 如果有多个哨兵节点同时参选领头,此时有可能存在一轮投票无竞选者胜出,此时每个参选的节点等待一个随机时间后再次发起参选请求,进行下一轮投票竞选,直至选举出领头哨兵
关于主节点故障选举流程(了解)
哨兵节点选出领头哨兵后,领头者开始对系统进行故障恢复,从出现故障的master的从数据库中挑选一个来当选新的master
规则如下
- 所有在线的slave中选择优先级最高的,优先级可以通过slave-priority配置
- 如果有多个最高优先级的slave,则选取复制偏移量最大(即复制越完整)的当选
- 如果以上条件都一样,选取id最小的slave
挑选出需要继任的slave后,领头哨兵向该数据库发送命令使其升格为master,然后再向其他slave发送命令接受新的master,最后更新数据。将已经停止的旧的master更新为新的master的从数据库,使其恢复服务后以slave的身份继续运行。
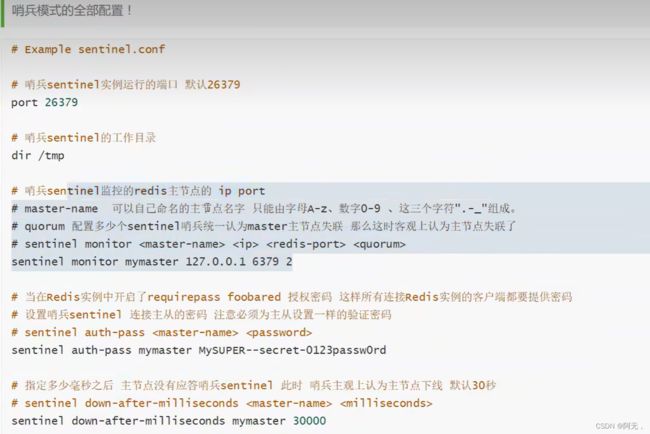
# 创建哨兵配置文件 sentinel.conf
# redis-master 名字
# 要监控的redis的ip port
# 1 代表主机宕机,slave投票看让谁接替成为主机,票数最多的,就会成为主机
sentinel monitor redis-master 172.17.0.4 6379 1
# 用docker启动的话是分别启动三个redis-server,三个哨兵
docker run --name redis-slave5 \
-p 6384:6379 \
-v /mydata/docker/redis/redis-master:/etc/redis \
--restart=always \
-d \
redis:5.0.8 \
redis-sentinel /etc/redis/sentinel.conf
docker run --name redis-slave5 \
-p 6384:6379 \
-v /mydata/docker/redis/redis-master:/etc/redis \
--restart=always \
-d \
redis:5.0.8 \
redis-server /etc/redis/redis.conf
哨兵模式优缺点

哨兵模式的部分配置
全部配置感觉工作的时候再了解,而且这块儿还是偏运维
部分内容转载自:
https://blog.csdn.net/sinat_25207295/article/details/117925174
https://www.bilibili.com/video/BV1S54y1R7SB?p=27&spm_id_from=pageDriver&vd_source=64c73c596c59837e620fed47fa27ada7
https://juejin.cn/post/7137104039753285645
https://zhuanlan.zhihu.com/p/648737280
怄气的人总是绷着脸、阴沉沉的样子,而且安静的很反常。
蛤蟆先生
【英】罗伯特·戴博德