【YOWO代码解析】
文章目录
- 1. backbones_2d&backbones_3d
- 2. cfg(config)
-
- 2.1 ava.yaml(jhmdb.yaml、ucf24.yaml)
- 2.2 ava_categories_count.json&ava_categories_ratio.json
- 2.3 defaults.py
- 2.4 parser.py
- 2.5 yolo_cfg.py
- 3. core
-
- 3.1 model.py
- 3.2 cfam.py
- 3.3 utils.py
- 3.4 FocallLoss.py
- 具体需要修改的路径
在Code Runner中使用已经配好的虚拟环境。参考
"python": "python -u",
"python": "set PYTHONIOENCODING=utf8 && $pythonPath -u $fullFileName",

下载之后,详细文件如下:
├── backbones_2d
│ └── darknet.py
├── backbones_3d
│ ├── mobilenet.py
│ ├── mobilenetv2.py
│ ├── resnet.py
│ ├── resnext.py
│ ├── shufflenet.py
│ └── shufflenetv2.py
├── cfg
│ ├── ava_categories_count.json
│ ├── ava_categories_ratio.json
│ ├── ava.yaml
│ ├── custom_config.py
│ ├── defaults.py
│ ├── jhmdb.yaml
│ ├── parser.py
│ ├── ucf24_finalAnnots.mat
│ ├── ucf24.yaml
│ ├── yolo.cfg
│ └── yolo_cfg.py
├── core
│ ├── cfam.py
│ ├── eval_results.py
│ ├── FocalLoss.py
│ ├── model.py
│ ├── optimization.py
│ ├── plot_ava_result.py
│ ├── region_loss.py
│ └── utils.py
├── datasets
│ ├── ava_dataset.py
│ ├── ava_eval_helper.py
│ ├── ava_evaluation
│ │ ├── __init__.py
│ │ ├── label_map_util.py
│ │ ├── metrics.py
│ │ ├── np_box_list_ops.py
│ │ ├── np_box_list.py
│ │ ├── np_box_mask_list_ops.py
│ │ ├── np_box_mask_list.py
│ │ ├── np_box_ops.py
│ │ ├── np_mask_ops.py
│ │ ├── object_detection_evaluation.py
│ │ ├── per_image_evaluation.py
│ │ ├── README.md
│ │ └── standard_fields.py
│ ├── ava_helper.py
│ ├── clip.py
│ ├── cv2_transform.py
│ ├── dataset_utils.py
│ ├── generate_anchors.py
│ ├── image.py
│ ├── list_dataset.py
│ ├── logging.py
│ ├── meters.py
│ └── transform.py
├── evaluation_ucf24_jhmdb
│ ├── groundtruths_jhmdb.zip
│ ├── groundtruths_ucf.zip
│ ├── _init_paths.py
│ ├── lib
│ │ ├── BoundingBoxes.py
│ │ ├── BoundingBox.py
│ │ ├── Evaluator.py
│ │ ├── __init__.py
│ │ └── utils.py
│ ├── LICENSE
│ ├── pascalvoc.py
│ ├── README.md
│ └── results
│ ├── 10.png
│ ├── 11.png
│ ├── 12.png
│ ├── 13.png
│ ├── 14.png
│ ├── 15.png
│ ├── 16.png
│ ├── 17.png
│ ├── 18.png
│ ├── 19.png
│ ├── 1.png
│ ├── 20.png
│ ├── 21.png
│ ├── 2.png
│ ├── 3.png
│ ├── 4.png
│ ├── 5.png
│ ├── 6.png
│ ├── 7.png
│ ├── 8.png
│ └── 9.png
├── examples
│ ├── ava1.gif
│ ├── ava3.gif
│ ├── ava4.gif
│ ├── biking.gif
│ ├── brush_hair.gif
│ ├── catch.gif
│ ├── fencing.gif
│ ├── golf_swing.gif
│ ├── pull_up.gif
│ └── YOWO_updated.pdf
├── main.py
├── README.md
├── test_video_ava.py
└── video_mAP.py
1. backbones_2d&backbones_3d
主要存放所使用的框架算法。如YOLO中的darknet和3D网络等。
├── backbones_2d
│ └── darknet.py
├── backbones_3d
│ ├── mobilenet.py
│ ├── mobilenetv2.py
│ ├── resnet.py
│ ├── resnext.py
│ ├── shufflenet.py
│ └── shufflenetv2.py
2. cfg(config)
配置文件,通过修改文件让代码得以部署。
2.1 ava.yaml(jhmdb.yaml、ucf24.yaml)
这个文件是一个Python配置文件,用于存储和管理各种配置选项。它定义了许多不同的配置参数,用于控制程序的行为和功能。这些配置参数包括输出路径、输入视频路径、模型配置、训练和测试选项、数据集路径等等。通过修改这个配置文件,可以自定义程序的行为和设置。
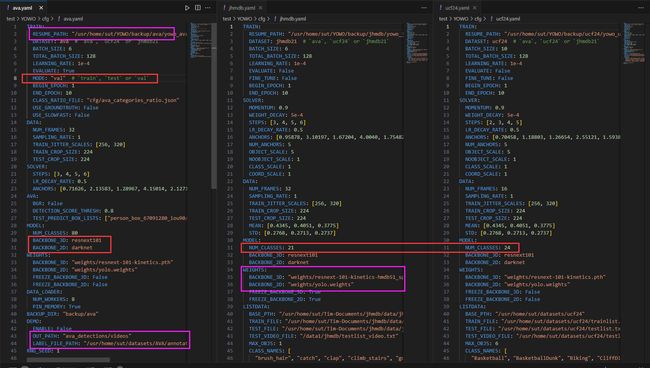
- 红色:代码运行模式。
- 紫色:路径设置!!确保正确!!还有输出的路径看清!
2.2 ava_categories_count.json&ava_categories_ratio.json
- ava_categories_count.json:该文件的作用是存储一个JSON对象,其中包含了各种动作及其对应的计数。这个文件可能用于记录和跟踪特定动作的频率或统计数据。
- ava_categories_ratio.json:该文件的作用是存储某些类别的比例值。该文件中的内容是一个 JSON 对象,键是类别的标识符,值是对应类别的比例值。
2.3 defaults.py
from . import custom_config
cfg/custom_config.py文件进行一些操作。在当前的文件中,有一个名为add_custom_config的函数,它似乎是用来添加自定义配置和默认值的。然而,目前这个函数没有任何实现,只有一个pass语句。
如果您想要添加自定义配置和默认值,您可以在add_custom_config函数中编写您自己的代码。您可以在pass语句的位置添加您的配置代码。例如,您可以使用_C参数来访问和修改配置。
以下是一个示例,展示了如何向add_custom_config函数中添加一个名为custom_option的自定义配置项,并为其设置一个默认值:
def add_custom_config(_C):
# Add your own customized configs.
_C.custom_option = "default_value"
相当于原本要在custom_config中写的配置挪到了defaults中。
根据提供的文件内容,这些代码是一个配置文件,用于设置各种选项和参数。该文件包含了许多配置项,用于控制不同的功能和行为。
在文件中,您可以看到以_C开头的变量,这些变量定义了各种配置选项。您可以根据您的需求修改这些选项的值。
这个文件的作用是为您的程序提供一个统一的地方来定义和管理各种配置选项。您可以根据需要修改这些选项的值,以满足您的具体需求。例如,您可以更改批归一化的epsilon值、学习率、训练批次大小等等。
此外,该文件还包含一个名为add_custom_config的函数,它允许您添加自定义配置和默认值。您可以在这个函数中编写您自己的代码来添加额外的配置选项和默认值。
# Batch norm options
# Training options.
# Testing options
# ResNet options
# Nonlocal options
# Model options
# SlowFast options
# Data options
# Optimizer options
# Demo options
...............

2.4 parser.py
该文件的作用是解析命令行参数并加载配置文件。它包含两个主要函数:parse_args()和load_config()。
parse_args()函数使用argparse模块创建一个参数解析器,并定义了一些命令行参数。它返回解析后的参数对象。
# 实例化创建一个ArgumentParser对象。
parser = argparse.ArgumentParser(
description="Provide YOWO video training and testing pipeline."
)
# 添加参数
parser.add_argument(
"--cfg",
dest="cfg_file",
help="Path to the config file",
default="cfg/ava.yaml",
type=str,
)
load_config()函数接受parse_args()返回的参数对象作为输入,并根据参数中指定的配置文件路径加载配置。它还可以通过命令行参数覆盖配置文件中的设置。最后,它返回一个配置对象。
def load_config(args):
"""
给定参数,加载并初始化配置。
参数:
args (argument): 包括 `shard_id`, `num_shards`, `init_method`, `cfg_file` 和 `opts`。
"""
# 设置 cfg。
cfg = get_cfg() # Get a copy of the default config.
# 从 cfg 文件加载配置。
if args.cfg_file is not None:
cfg.merge_from_file(args.cfg_file)
# 从命令行加载配置,覆盖 opts 中的配置。
if args.opts is not None:
cfg.merge_from_list(args.opts)
# 从 args 继承参数。
# 创建检查点目录。
return cfg
这个文件的目的是为了方便在命令行中指定配置文件和其他参数,并将它们加载到程序中使用。
2.5 yolo_cfg.py
提供的代码似乎是一个较大程序的一部分,该程序处理解析和打印神经网络模型的配置。
parse_cfg 函数读取配置文件并返回块列表,其中每个块代表网络中的一个层或操作。 print_cfg 函数获取块列表并打印有关每个层的信息,例如其类型、过滤器、大小、输入和输出维度。
该代码还包括用于保存和加载卷积层和全连接层的函数,以及用于保存和加载批量归一化卷积层的函数。
该代码的目的是提供用于处理神经网络模型的实用功能,例如解析配置文件、打印层信息以及保存/加载模型参数。
3. core
3.1 model.py
这个文件保存的是YOWO的神经网络模型。YOWO模型用于时空动作定位。它由一个2D骨干网络和一个3D骨干网络组成,以及注意力机制和最终的卷积层。
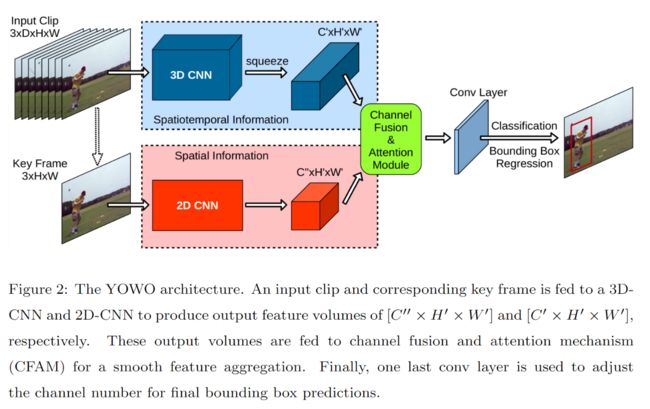
3.2 cfam.py
Channel fusion and attention mechanism for aggregating output feature maps coming from 2D-CNN and 3D-CNN branches.
用于聚合来自 2D-CNN 和 3D-CNN 分支的输出特征图的通道融合和注意力机制。
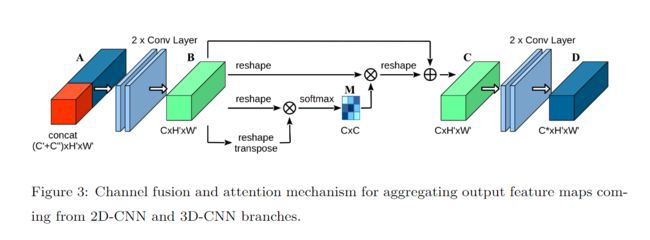
CFAMBlock(
(conv_bn_relu1): Sequential(
(0): Conv2d(2473, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv_bn_relu2): Sequential(
(0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(sc): CAM_Module(
(softmax): Softmax(dim=-1)
)
(conv_bn_relu3): Sequential(
(0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv_out): Sequential(
(0): Dropout2d(p=0.1, inplace=False)
(1): Conv2d(1024, 145, kernel_size=(1, 1), stride=(1, 1))
)
)
input: torch.randn(18, 2473, 7, 7)
output:torch.Size([18, 145, 7, 7])
class CAM_Module(nn.Module):
""" Channel attention module """
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X H X W )
returns :
out : attention value + input feature
attention: B X C X C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1) # 将输入的特征图x变形为(m_batchsize, C, height*width)
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1) # 将输入的特征图x变形为(m_batchsize, height*width, C)
energy = torch.bmm(proj_query, proj_key) # 计算query和key的内积,得到能量图
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy # 对能量图进行归一化处理,得到注意力图
attention = self.softmax(energy_new)
proj_value = x.view(m_batchsize, C, -1) # 将输入的特征图x变形为(m_batchsize, C, height*width)
out = torch.bmm(attention, proj_value) # 计算加权后的特征向量
out = out.view(m_batchsize, C, height, width) # 将加权后的特征向量变形为(m_batchsize, C, height, width)
# 将加权后的特征向量与原始特征向量相加
out = self.gamma*out + x
return out
3.3 utils.py
- 类AverageMeter:计算并存储平均值和当前值
- 很多函数:保存checkpoints、学习率调整、softmax、sigmoid、bbox_iou、video_iou、bbox_ious、nms、nms_3d
实现了很多功能,包括plot_box。后续需要的话,就要好好读!!
3.4 FocallLoss.py
focalloss
根据当前文件的内容,core/FocalLoss.py 文件是一个实现 Focal Loss 的 Python 模块。Focal Loss 是一种用于密集目标检测的损失函数,用于解决类别不平衡问题。 该文件定义了一个名为 FocalLoss 的类,继承自 nn.Module,并实现了前向传播方法 forward。该类的构造函数接受参数 class_num、alpha、gamma 和 size_average,并根据这些参数初始化模型的属性。forward 方法接受输入 inputs 和目标 targets,并计算 Focal Loss。



具体需要修改的路径
- defaults.py:_C.WEIGHTS.BACKBONE_3D = “”&_C.WEIGHTS.BACKBONE_2D = “”
- ava.yaml:TRAIN: RESUME_PATH: /usr/home/sut/YOWO/backup/ava/yowo_ava_32f_s1_best_ap_01905.pth"
python train.py --dataset ucf101-24 --data_cfg cfg/ucf24.data --cfg_file cfg/ucf24.cfg --n_classes 24 --backbone_3d resnext101 --backbone_2d darknet --backbone_2d_weights weights/yolo.weights - -resume_path weights/yowo_ucf101-24_16f_best.pth
python train.py --dataset ava --data_cfg cfg/ava.data --cfg_file cfg/ava.cfg --n_classes 80 --backbone_3d resnext101 --backbone_2d darknet --backbone_2d_weights weights/yolo.weights - -resume_path weights/yowo_ava_32f_s1_best_ap_01905.pth