Titus网关中的缓存一致性机制
API网关引入缓存可以在不影响数据一致性的前提下,有效优化接口时延。本文介绍了Netflix在Titus网关上引入缓存的实践,比较了有无缓存对访问时延的影响。原文: Consistent caching mechanism in Titus Gateway
前言
Titus是Netflix的云容器运行时,可大规模运行和管理容器。自从Titus最初以高级Mesos框架发布[1]以来,已经从基于Mesos构建演变为基于Kubernetes,并能够处理越来越多的容器。随着Titus用户数逐年增加,系统负载和压力也大幅增加,最初的假设和架构选择已不再可行。本文介绍了当前Titus如何通过水平扩展来处理海量API调用。
为此我们在API网关层引入了缓存机制,可以在不放弃严格数据一致性的前提下,将数据处理从选举为领导者的控制器中卸载,并保证客户端的可观察性。Titus API客户端总是能够获取到最新(不是过时的)版本的数据,而不用管是哪个网关节点为其提供服务,或者以何种顺序提供服务。
概述
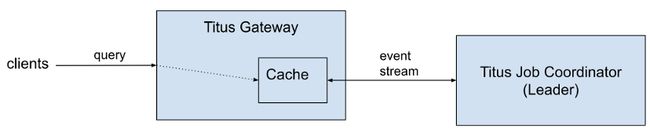
下图介绍了单个Titus集群(又称cell)的简化高层架构:

Titus Job Coordinator是被选举出管理系统活跃状态的领导者进程,活跃数据包括当前正在运行的作业和任务。当新领导者被选出时,需要从外部存储加载所有数据。在变更内存状态之前,变更首先持久化到活跃数据存储中。已完成的作业和任务数据首先移动到归档存储中,然后才从活跃数据存储和领导者的内存中删除。
Titus Gateway负责处理用户请求。用户请求可以是作业创建请求、对活跃数据存储的查询,或者对归档存储的查询(后者在Titus Gateway中直接处理),请求在所有Titus Gateway节点上实现负载均衡。所有节点的读取都是一致的,因此不管哪个Titus Gateway实例都可以为查询提供服务。例如,可以通过一个实例发送写操作,并从另一个实例进行读操作,可以完全保证数据读取一致性。Titus Gateway总是连接到当前Titus Job Coordinator的领导者节点,在领导者节点发生故障转移期间,对活跃数据的所有读写读操作都将被拒绝,直到重新和活跃领导者节点建立连接。
在系统的初始版本中,对活跃数据集的所有查询都被转发到单例Titus Job Coordinator上。所有请求都会接收到最新数据,客户端不会遇到read-your-write或monotonic-read问题[2]:

Titus API上的数据一致性是非常有用的,可以简化客户端实现。因果一致性,包括read-your-writes和monotonic-reads,使客户端不必实现同步机制。在PACELC术语中,我们选择PC/EC,在提高读的理论可用性的同时,对写具有与之前系统相同的可用性。
例如,批处理工作流编排系统可以创建多个作业,这些作业是单个工作流执行的一部分,并在创建作业之后,监视作业的执行进度。如果系统创建了新作业,立即查询以获取其状态,如果存在数据同步滞后的情况,系统可能会认为作业丢失了,必须创建一个替换作业。在这种情况下,系统将需要直接处理数据同步的延迟,例如,可以通过超时或面向客户端的更新跟踪机制。由于Titus API的读取总是反映最新的一致状态,因此不需要这样的变通方式。
随着通信量的增长,处理所有请求的单一领导者节点开始过载,响应延迟开始增加并且领导者服务器正以危险的高利用率运行。为了缓解这个问题,我们决定直接处理来自Titus Gateway节点的所有查询请求,但仍然维持最初的一致性保证:
来自Titus Job Coordinator的状态通过持久流连接复制,具有较低的事件同步延迟。Titus Job Coordinator提供一种新的连接协议允许监控缓存一致性级别,并确保客户端总是接收到最新的数据版本,缓存与当前主进程保持同步。当发生故障转移(由于当前领导者节点发生故障或系统升级)时,从新当选的领导者节点加载新的快照,以替换之前的缓存状态。处理客户端请求的Titus网关现在可以水平扩展,这些机制的细节和工作原理是本文的主要主题。
如何知道缓存是最新的?
对于从一开始就基于数据版本一致性控制方案构建的系统来说,这个问题很简单,并且可以要求客户端遵循既定协议。Kubernetes就是个很好的例子,从Kubernetes集群中读取的每个对象和每个集合都有唯一的版本号,这个版本号是单调递增的,用户可以请求自上次收到的修订版本以来的所有更改。更多细节请参见Kubernetes API概念和共享通知器模式(Shared Informer Pattern)。
在我们案例中,不希望更改API契约,并对用户施加额外的约束和要求。这样做需要将大量客户端从旧有API迁移到受影响的团队(帮助我们解决Titus的内部可伸缩性问题除外)。根据经验,这样的迁移需要消耗大量工作,特别是在迁移时间轴不完全受我们控制的情况下。
为了履行现有API合约,必须确保对于在 时间收到的请求,返回给客户端的数据是从Titus Job Coordinator缓存中读取的包含到 时间为止的所有状态更新。

数据从Titus Job Coordinator传输到Titus Gateway缓存的路径可以描述为具有不同处理速度的事件队列序列:

事件源生成的消息可以在任何阶段进行缓冲。此外,由于从Titus Gateway到Titus Job Coordinator的每个事件流订阅都建立了处理流水线的不同实例,因此每个网关实例中的缓存状态可能有很大不同。
我们假设一系列事件 … ,在 时间的两个Titus Gateway实例流水线中的位置:

如果客户端在 时间访问Titus Gateway 2,将会读取到 版本的数据。如果向Titus Gateway 1发出请求,其缓存相对于另一个网关是旧的,因此客户端可能读取到旧版本的数据。
在这两种情况下,缓存中的数据都不是最新的。如果客户端在 时间创建了一个新对象,而对象的值被事件更新 获取,那么在 时,该对象在两个网关中都不存在。成功完成创建请求的客户端也许会感到惊讶,因为后续查询返回了not-found错误(违反read-your-write一致性)。
解决方案是刷新时间T₁之前创建的所有事件,并迫使客户端等待缓存接收到所有事件。这项工作可以分为两个步骤,每个步骤都有自己独特的解决方案。
实现细节
我们通过结合两种策略解决了缓存同步问题(如上所述):
- Titus Gateway <-> Titus Job Coordinator在线同步协议。
- 在单个服务器进程中使用高分辨率单调时间源,如Java的nano时间。Java的nano时间被用作JVM中的逻辑时间,以定义JVM进程中发生的事件顺序。也可以用基于原子整数值生成器对事件进行排序作为替代解决方案。使用本地逻辑时间源可以避免 分布式时钟同步问题。
如果Titus Gateway订阅了没有同步步骤的Titus Job Coordinator事件流,则无法估计有多少数据过时。为了保证Titus Gateway接收到在某个时间 之前发生的所有状态更新,两个服务之间必须显式同步。下面是我们实现的协议:
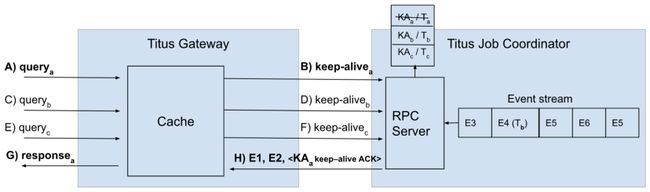
- Titus Gateway接收客户端请求( )。
- Titus Gateway向本地缓存请求获取最新版本数据。
- Titus Gateway中的本地缓存记录本地逻辑时间,并以keep-alive消息( )的形式将其发送给Titus Job Coordinator。
- Titus Job Coordinator将保持活跃请求与请求到达的本地逻辑时间 一起保存在本地队列( , )中。
- Titus Job Coordinator向Titus Gateway发送状态更新,直到前者观察到状态更新事件,其时间戳超过了所记录的本地逻辑时间( , )。
- 这时,Titus Job Coordinator为keep-alive消息发送确认事件( keep-alive ACK)。
- Titus Gateway接收到keep-alive确认,因此知道本地缓存包含了直到发送keep-alive请求时发生的所有状态更改。
- 此时,可以从本地缓存处理初始客户端请求,确保客户端获得足够新的数据版本( )。
整个流程如下图所示:
以上流程解释了如何将Titus Gateway缓存与Titus Job Coordinator中的真实源同步,但没有说明Titus Job Coordinator中的内部队列是如何处理直到所有消息都处理完毕的。这里的解决方案是向每个事件添加逻辑时间戳,并确保在事件流中发出的消息之间有最小的时间间隔。如果由于数据更新而没有创建足够的事件,则生成模拟消息并将其插入到流中。模拟消息确保每个keep-alive请求在限定的时间内得到确认,从而避免无限期等待系统中发生某些更改。例如:

、 、 、 和 是高分辨率单调逻辑时间戳。在 时间插入模拟消息,因此事件流中两个连续事件之间的间隔总是低于一个可配置的阈值。将这些时间戳值与keep-alive请求到达时间戳进行比较,以了解何时可以发送keep-alive确认。
此外还有一些优化技术,以下是在Titus中实现的:
- 在为每个新的客户端请求发送keep-alive请求之前,等待固定的间隔,并为在此期间到达的所有请求发送一个keep-alive请求。因此keep-alive的最大请求速率受1/max_interval的限制。例如,如果max_interval设置为5ms,则keep-alive最大连接请求速率为200 req/sec。
- 在Titus Job Coordinator中分解多个keep-alive请求,向最新的一个请求发送响应,该请求的到达时间戳小于通过网络发送的最后一个事件的时间戳。在Titus Gateway端,具有给定时间戳的keep-alive响应确认所有挂起的请求,其keep-alive时间戳早于或等于接收到的请求。
- 对于没有时序要求的请求,不要等待缓存同步,从每个Titus Gateway上的本地缓存提供数据。能够容忍最终一致性的客户端可以选择使用这个新的API,以减少响应时间并提高可用性。
根据到目前为止所介绍的机制,我们尝试估算不同场景下到达Titus Gateway的客户端请求的最大等待时间。假设最大keep-alive间隔是5ms, Titus Job Coordinator中发出的事件之间的最大间隔是2ms。
假设系统处于空闲状态(对数据不做任何更改),并且客户端请求到达的时间是新的keep-alive请求等待时间开始的时间,那么缓存更新延迟等于7毫秒+网络传播延迟+处理时间。如果忽略处理时间,并假设网络传播延迟<1ms(因为只需发回很小的keep-alive响应),那么在典型情况下,应该预期延迟为8ms。如果客户端请求不需要等待发送keep-alive请求,并且在Titus Job Coordinator中立即确认keep-alive请求,则延迟等于网络传播延迟+处理时间,估计小于1ms。缓存同步带来的平均延迟约为4ms。
随着状态更改事件和客户端请求的增加,网络传播延迟和流处理时间开始成为更重要的因素。然而,Titus Job Coordinator现在可以将其服务高带宽流的能力提供给有限数量的Titus Gateway,依靠网关实例服务客户端请求,而不是自己为所有客户端请求提供有效负载。Titus Gateway可以横向扩展,以匹配客户端请求量。
我们对低请求量和高请求量的场景进行了经验测试,结果将在下一节中介绍。
性能测试结果
为了展示系统在使用和不使用缓存机制时的表现,我们运行了两个测试:
- 低/中等负载的测试显示,由于缓存同步机制的开销,延迟中位数增加了,但P99的延迟更低。
- 负载接近Titus Job Coordinator容量峰值时的测试,超过峰值后原始系统将崩溃。以前的结果是成立的,显示缓存解决方案具有更好的可伸缩性。
下面测试中的单个请求由一个查询组成,该查询大小适中,是100条记录的集合,序列化后响应大小约为256KB。总有效负载(请求大小乘以并发请求数)在第一个测试中需要大约2Gbps的网络带宽,在第二个测试中需要大约8Gbps的网络带宽。
中等负载水平
该测试展示了中等负载系统中缓存同步对查询延迟的影响。此测试的查询速率设置为每秒1000个请求。
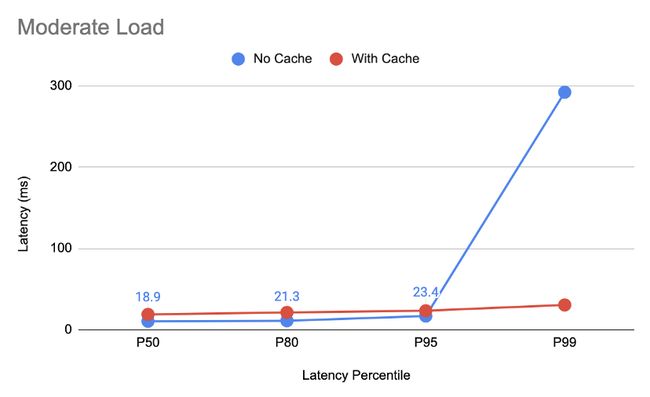
由于增加了同步延迟,在没有缓存的情况下,延迟中位数是我们在引入缓存机制后观察到的延迟的一半。但好处是在最差情况下的P99延迟降低了90%,从没有缓存时的292毫秒下降到有缓存时的30毫秒。
负载水平接近Titus Job Coordinator的最大值
如果Titus Job Coordinator必须处理所有查询请求(当缓存未启用时),那么其处理流量的能力将达到每秒4000查询,并在大约4500查询/秒时崩溃(延迟急剧增加并且吞吐量快速下降)。因此,最大负载测试保持在每秒4000查询。

在不启用缓存的情况下,P99徘徊在1000毫秒左右,P80徘徊在336毫秒左右,而启用缓存的P99为46毫秒,P80为22毫秒。在没有缓存的情况下,中位数在17ms时看起来比在启用缓存时的19ms更好。但应注意的是,在保持相同的延迟百分比的情况下,启用缓存的系统可以线性扩展支持更多的请求负载,而没有缓存的系统只能支持大约15%的额外负载。
在启用缓存时,将负载翻倍并不会增加延迟。以下是每秒运行8000查询请求时的延迟百分比:

结论
在达到之前系统的垂直扩展极限之后,我们很高兴实现了真正的解决方案,使(在实际意义上)Titus只读API实现了无限可伸缩性。当流量较低时,能够通过牺牲一定的时延中位数来实现更好的尾部延迟,并获得了横向扩展API网关处理层的能力,以处理流量的增长,而无需更改API客户端。升级过程完全透明,没有一个客户端在迁移期间以及之后察觉到API行为的任何异常或更改。
这里介绍的机制可应用于任何依赖单一领导者组件作为托管数据真实源(数据适合在内存中存储)的系统,并能够实现较低的时延。
至于参考技术,有大量关于缓存一致性协议的文献,包括多处理器体系架构(Adve & Gharachorloo, 1996[3])和分布式系统(Gwertzman & Seltzer, 1996)。我们的工作符合Gwertzman和Seltzer(1996)在调查报告中探索的客户轮询和失效协议机制。在读取副本中促进线性化的集中时间戳与Calvin[4]系统(例如FoundationDB[5]等系统中的实际实现)以及AWS Aurora[6]中的副本水印类似。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
[1]Titus, the Netflix container management platform, is now open source: https://netflixtechblog.com/titus-the-netflix-container-management-platform-is-now-open-source-f868c9fb5436
[2]Consistency model: https://en.wikipedia.org/wiki/Consistency_model#Session_guarantees
[3]Shared memory consistency models: a tutorial: https://ieeexplore.ieee.org/abstract/document/546611
[4]Calvin: Fast Distributed Transactions for Partitioned Database Systems: https://cs.yale.edu/homes/thomson/publications/calvin-sigmod12.pdf
[5]FoundationDB: A Distributed Unbundled Transactional Key Value Store: https://www.foundationdb.org/files/fdb-paper.pdf
[6]Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases: https://web.stanford.edu/class/cs245/readings/aurora.pdf
- END -本文由 mdnice 多平台发布