用合成数据训练车辆姿态估计神经网络
我们的客户希望开发一款应用程序,引导用户通过 AR 指南和自动照片拍摄来拍摄更高质量的汽车照片。 本文重点介绍构建汽车姿态估计组件的技术。 在应用程序中,用户被引导站在与汽车一定的角度和距离,以标准化的方式捕捉最好的照片。 当用户处于正确位置时,会自动拍摄高分辨率照片。

推荐:用 NSDT编辑器 快速搭建可编程3D场景
我们需要一种方法来大致了解用户在 3D 空间中相对于他们正在拍摄的汽车的站立位置。 由于这是一个原型应用程序,我们只有几周的时间来提出可行的解决方案。 我们还限制了对特定车型的识别,以缩短开发时间。
项目的目标和限制如下:
- 构建可行解决方案的时间很短
- 大致实时的汽车姿态估计(< 150 ms)
- 将范围限制为具有不同颜色/选项的特定车型
- 应用程序应拍摄高质量的照片
1、在构建之前的尝试
希望为 3D 物体姿态估计找到一个快速的现成解决方案,我们测试了几种方法。
1.1 Apple ARKit 3d 物体识别
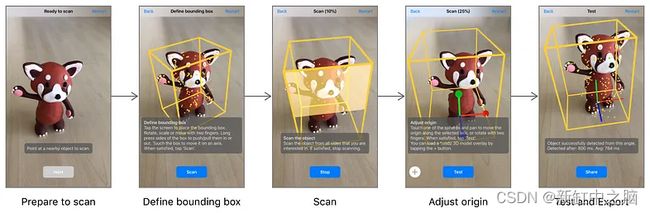
ARKit 物体识别 — 物体扫描应用
ARKit 包含用于扫描和识别 ARKit 中的刚性 3D 对象的 API。 这对我们来说似乎很理想; 实时且内置于 ARKit 中,这将使该功能的开发时间缩短为零。 我们这里主要关心的是识别不同的汽车颜色。 为了测试 ARKit 对此的处理效果,我们购买了一辆具有几种不同颜色的小型模型车。

测试用模型车
我们扫描一种颜色,然后在类似的颜色上进行测试(即扫描白色,在浅蓝色上进行测试。)在某些情况下,识别确实有效。 它并不完美,但也许如果我们扫描一些基色,这将提供足够的不变性来识别我们可能期望看到的汽车的任何颜色。
下一步是在真车上进行尝试。 事实证明,真正的汽车的行为有点不同。 即使在同一辆车上进行扫描和测试也是不可靠的。 有时,识别出的汽车会以某种方式稍微旋转/平移。 我们的猜测是,汽车上的高反光油漆工作使得基于特征的扫描和识别很难发挥作用(Apple 在其文档中特别提到反光物体不适合 3D 识别。)
1.2 第三方 SDK
我们测试了其他一些 SDK,并得到了与 ARKit 类似的结果。 一些库需要特定的“初始化模板”或用户需要匹配的位置才能启动 3D 对象跟踪。 这并不理想,因为我们想要引导用户到某些位置,因此识别需要从各种角度/位置进行。
1.3 照片质量
ARKit 和我们尝试的 SDK 的另一个缺点是使用它们时拍摄的照片的质量和分辨率。 使用 ARKit 时可捕获的最高分辨率为 1920x1440。 使用 ARKit 时,对焦点和曝光的控制也非常有限。 由于该应用程序主要用于拍摄高质量的汽车照片,因此除了大图像分辨率之外,我们还希望对焦点和曝光进行精细控制。
2、构建基于神经网络的姿态估计器

人体姿态估计
鉴于我们使用第三方解决方案不成功,再加上照片质量限制,我们决定考虑构建自己的解决方案,与 Apple 的 AVFoundation 相机 API 一起使用。 我们选择神经网络解决方案,因为它们是姿势估计的最先进技术,并且有很多开源项目和研究可供利用。
2.1 姿态估计方法
给定图像,我们如何预测图像中物体的 3D 姿态? 一种常见的方法涉及预测对象规范模型上一组已知点的图像位置。 例如,给定一张汽车照片,图像中的左侧前灯在哪里? 有了足够的这些预测,我们就可以估计原始汽车模型相对于拍照相机的 3D 姿态。
2.2 网络架构
如今,神经网络在各种任务上都表现出了令人印象深刻的准确性,而且由于网络架构的改进和更快的设备,神经网络也能够在移动设备上实时运行。
最近我们研究了一些基于 CPM 和堆叠沙漏架构的实时移动身体姿势估计项目。
- PoseEstimationForMobile:github
- PoseEstimation-CoreML:github
这些项目包含许多有用的信息,可用于在移动平台上训练和运行你自己的姿势估计器。
他们使用的 CPM 网络有一个 MobileNetV2 基础,并为 14 个身体部位(左肘、右膝等)输出一个 2d 热图:

不同身体部位的热图
从这里,我们基本上可以获取每个关键点层的最大激活位置,然后使用 OpenCV 的 SolvePnP 方法估计 3d 汽车姿势。 这是我们在真实汽车照片上运行的最终神经网络的可视化,以及估计的 3D 姿势。 由于输出热图的分辨率有限,这并不是一个完美的选择。 我们的模型输出分辨率为 192x192 的热图,因此单次传递的准确度是有限的。

模型的最终输出
3、其他方法和资源
我们采用 CPM 来快速启动和运行,但还有其他方法可以解决这个问题。 另一种基于关键点的方法是直接将 2d 关键点输出为 x,y 坐标列表。 这确实限制了我们对单一汽车的估计,但对于我们的用例来说这是可以的。
灵感来自Hart Woolery 的关于手部姿势估计的帖子中,我们测试了简单地在 MobileNet 之上添加一些密集层,最终输出一组 1x28 的 x,y 关键点位置。 令人惊讶的是,这个开箱即用的效果非常好。 如果有更多时间,我们可能会进一步探索该网络,因为它比我们选择的 CPM 模型稍快。
如果您只是在寻找人体姿势估计,请查看Jameson Toole最近的关于 fritz.ai 人体姿势估计器的文章 。
另一种方法是网络直接输出汽车的位姿参数,而不是通过中间的 2d 关键点(参见 BoxCars 、 MultiBin )。 由于时间紧迫,我们没有严格评估我们可以采取的每一个方向——但这些其他方法似乎完全有效。
4、查找汽车数据集
选择网络架构后,下一步是找到可用于训练它的数据集。
用于身体姿势估计的数据集并不缺乏(COCO、DensePose、MPII、身体姿势数据集概述),但带注释的汽车数据不太常见。 存在一些数据集(Apollo、PASCAL 3d+),但每个数据集似乎都有其自己的局限性。 大多数数据集都是针对自动驾驶汽车的,因此来自街道上行驶的汽车视角的图像存在很大的偏差——这与我们期望网络处理的图像有很大不同。
PASCAL 3D 具有 3D 汽车模型标注,但这些汽车通常是从互联网照片中收集的更旧的模型。 由于我们提前知道了汽车模型,因此没有必要对数千个其他模型进行训练(尽管我们希望有更多时间扩展我们的网络以识别更多汽车模型。)最后,一些数据集具有非商业许可限制 。 鉴于这些缺点,我们探索了合成数据,将其作为直接根据我们预期的测试环境定制数据的方法。
5、创建合成汽车数据集

Unity 编辑器截图
当生成许多机器学习方法所需的大量训练数据不可能或不切实际时,合成数据就会派上用场。 感谢视频游戏行业,我们可以利用 Unity 或 Unreal 等图形引擎进行渲染,并使用最初为游戏开发的 3D 资源。 虽然我们还无法获得光线追踪方法的渲染质量,但示例代码的速度和数量以及免费/廉价的资源使其非常有吸引力。 Unity 是我们的选择,因为我们有更多的经验,而且时间也是一个因素。

使用 Unity 合成数据的示例
Unity 甚至发布了一个方便的演示项目,其中包含一些有关合成数据的常见需求。 我们最近还就使用 SceneKit 为 AR 足球比赛训练脚部分割网络进行了简短的演讲。
6、查找车辆模型
幸运的是,有很多高质量的 3D 汽车模型。 对于非常高质量的模型,您可能需要支付几百美元(请参阅 squir ),但是可以直接从 Unity 资产商店获得许多便宜或免费的模型:

https://assetstore.unity.com/categories/3d/vehicles/land
我们收集了大约 10 个形状与我们的目标模型相似的汽车模型,以及我们正在测试的确切汽车的两个变体。
如果你手头有目标对象的3D模型,但是需要转换成3D游戏引擎需要的格式,那么可以直接使用 NSDT 3DConvert 这个强大的在线3D格式转换工具,无需本地安装任何软件:

https://3dconvert.nsdt.cloud
7、数据标注
模型准备好后,下一步就是标注我们正在训练网络识别的关键点。 由于身体姿势网络有 14 个关键点,这似乎是一个合理的起点,因为它将减少对现有训练流程的任何修改。 此步骤需要创建 14 个空游戏对象并为每个车辆模型定位它们:

车辆的14个关键点
通过命名每个关键点游戏对象(例如 left_back_wheel ),在渲染过程中,我们可以在保存标注数据时简单地在汽车游戏对象中搜索每个关键点。 我们还选择使用深度测试来存储该视点的关键点是否被遮挡,但这最终并没有在训练中使用。
8、在数据集中创建变体
对合成数据进行训练时的一个大问题是模型是否能够推广到现实世界的图像。 这是一个活跃且不断发展的研究领域,有许多有趣的方法。 Apple 的机器学习团队发布了一篇有趣的文章,介绍如何使用 GAN 提高合成眼睛图像的真实感。 我们选择的方法称为域随机化。 通过在训练数据分布中创建大量变化,模型应该概括为目标(现实世界)分布,而无需任何微调。
为了实现这一目标,我们尝试在渲染图像之前尽可能多地随机化场景的各个方面。 前面的一个主要问题是网络将学会拾取 3D 汽车模型上的一些小细节,而这些细节不能推广到真实汽车的照片。 有一个经常被提及(可能不真实)的轶事是关于研究人员训练坦克探测器,该探测器只是了解训练集中的坦克在一天中的什么时间被拍照。 无论这个例子是否正确,当你的训练和测试集来自不同的分布时,需要注意确保转移到新数据。
8.1 车辆变体
对于每种汽车模型,我们花了一些时间在车身上创建可编写脚本的小细节变化。 例如油漆反射率、车牌位置和编号、车窗色调、汽车轮辋样式和位置以及其他一些内容。 我们还沿着汽车的局部轴稍微缩放了汽车本身。

仅车身变体的渲染图

不同的轮胎选择
8.2 环境/背景变化
最初,我们开始构建和购买一些包含建筑物和真实 3D 结构的场景。 事实证明,寻找高质量的逼真场景非常困难,而且成本高昂且耗时。 幸运的是,我们发现了一个很棒的网站,hdrihaven.com,它提供了非常高分辨率的免费环境地图。 这些本质上是 360 HDR 全景图,在几何体后面进行渲染,并可以为场景中的对象提供照明和反射。 我们还通过渲染脚本以参数方式改变反射和曝光强度。

来自 HDRI Haven 的环境贴图
除了天空盒之外,我们还创建了一个简单的平面作为汽车下方的地板。 在地板上应用不同的材料并偶尔将它们隐藏在一起可以提供很多视觉多样性:

场景和灯光变化
8.3 后期处理效果
Unity 有一个名为“后期处理栈”的功能,它基本上是 3D 场景的 Instagram 滤镜。 这些效果可能包括模糊、颜色分级等。你可以通过包管理器或资源商店将其添加到场景中,具体取决于Unity 版本。
除了内置的后期处理栈之外,我们还从资产商店下载了另一组名为 SC Post Effects Pack 的滤镜,价格为 25 美元。 以下是一些仅改变后处理滤镜组合的渲染:

后期处理滤波器的变化
影响是微妙的,可能很难发现。 这里看到的一些是景深、噪点、云阴影、环境光遮挡、边缘高光、色调偏移和黑条。 对于每一个,我们还随机调整参数以获得更多变化。
8.4 把它们整合在一起
应用所有的变化,我们最终得到像这样的图像:

启用所有变体的渲染
尽管这些看起来不像真实的街道场景,但背景和照明的多种变化应该迫使网络捕捉到所有照片中保持不变的汽车特征。 如果我们只使用街道场景,我们的检测器可能会将街道场景的各个方面纳入其特征中; 期望某些阴影和照明特征始终伴随着汽车本身。
9、创建小型验证数据集

用Python编写的标注工具
我们对数据集偏差的担忧导致我们使用 3D 关键点手动标注一些汽车的实际图像。 手动逐一标注 14 个关键点相当耗时 - 特别是对于被遮挡的关键点。
为了加快速度,我们构建了一个非常基本的 wxPython 应用程序,只需要为每个图像标记几个关键点。 为此,我们使用 OpenCV 的 SolvePnP 来拟合给定这些初始关键点的 3D 汽车模型,然后将其他关键点投影到图像中。
标注完成后,我们使用 imgaug 库应用随机图像增强。 值得庆幸的是,imgaug 支持将 2d 关键点与图像一起变换,因此你不必手动变换点位置。 增强后,我们有大约 1500 张图像来验证我们的网络。
10、合成数据有效吗?
对于我们的一小部分已知汽车模型的用例,我们对第一轮的结果非常满意。 我们的假设是我们需要将更多真实图像纳入训练中,或者更多地依赖迁移学习,但我们最终不需要这样做。 即使在相当广泛的汽车上进行测试,仍然可以得到合理的结果
正如你在这个视频中看到的那样。 3D 模型拟合不适用于其他汽车形状,因为我们将刚性 3D 对象拟合到另一辆不同尺寸的汽车上。 有关于在给定关键点上拟合灵活的参数化汽车模型的文献,因此我们可能会研究更通用的汽车检测器。
11、实现代码
我们的计划是,如果我们有时间清理管线并在更多车型上进行徐连,则将发布管线的某些方面。
现在,我们已经提供了一个演示 iOS 应用程序的代码,该应用程序使用 ARKit 显示估计的汽车姿势。请记住,该模型是在固定视点范围和汽车模型上进行训练的。
原文链接:合成数据训练车辆姿态估计 — BimAnt