Kafka集群的安装配置及基本使用
文章目录
- 前言
- 一、Kafka的介绍
- 二、Kafka集群的环境搭建
- 三、Kafka的命令行操作
- 四、Kafka实际操作
前言
此作为记录大三下的十五天企业实训。本文主要包括以下内容:
- Kafka的介绍
- Kafka集群的环境搭建
- Kafka的命令行操作
- Kafka实际操作
整个过程记录详细,每个步骤亲历亲为,实测可用。同时,包含多个脚本文件的编写,便捷集群环境的搭建配置。
此外,本文内容是在 Zookeeper 的安装配置 的基础上进行的。很多脚本文件都在此文给出了相关的代码和具体的用法。例如:ZooKeeper的群起脚本等。
在文章开始前,我们先大致了解一下当前已完善的集群规划:
| hadoop101 | hadoop102 | hadoop103 |
|---|---|---|
| JDK | JDK | JDK |
| Hadoop | Hadoop | Hadoop |
| zk | zk | zk |
一、Kafka的介绍
-
定义: kafka 是一个基于订阅与发布的消息队列(Message Queue),主要适用于大数据实时处理领域。
-
相关概念:
a) Producer : 消息的生产者,也就是向消息队列发消息的客户端。
b) Consumer: 消息的消费者,也就是向消息队列取消息的客户端。
c) Consumer Group: 消费者组。由多个消费者构成。消费Kafka中的数据时,都是以消费者组的基础去消费的,是一个逻辑上的订阅者。 消费者组内的每个消费者负责消费不同分区的数据,一个分区的数据只能由一个消费者组中的一个消费者进行消费。消费者组之间互不影响。
d) Broker: 一台Kafka 主机就是一个Broker。一个集群由多个broker组成。
e) Topic: 可以理解为一个小的消息队列。生产者和消费者面向的都是同一个Topic。做到消息的隔离。 一个Broker 中有多个Topic。
f) Partition: 分区。为了实现扩展性,将一个大的Topic 分布到多个broker 上。故将一个Topic 中的数据分成多个分区,每个分区是一个有序的队列。
g) Replication: 副本。为了实现高可靠性。Kafka对每个分区的数据都进行了备份。即保留了若干个副本。所有分区数据中挑选出一个Leader和多个Follow。(Kafka的选举机制为争抢策略 。简单来说,谁先启动,谁就为Leader)。Consumer 主要消费Leader中的数据。Follower的职责就是同步数据, 等着大哥宕机了以后,再顶上去。
h)leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
i)follower: 每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader。 -
消息队列的两种模式:
a) 点对点模式: 即消费者主动向broker 拉取数据,消息收到后则清除消息。消息只被消费一次。
消息的生产者生产消息到Queue中,由消息的消费者从Queue中消费数据。Queue确定消息被成功消费后,则从队列中删除该消息。也即消费者不可能消费到已经被消费过的消息。Queue 支持多个消费者,但是对于一个消息而言,只会被一个消费者进行消费。
b) 发布/订阅模式: 消费者消费数据后不会清除消息。
与一对一模式不同之处,在于这里引入Topic的概念。消息生产者将消息发布到Topic中后,同时有多个消息消费者(订阅者)消费该消息。与点对点方式不同,发布到Topic中的数据会被所有订阅者消费。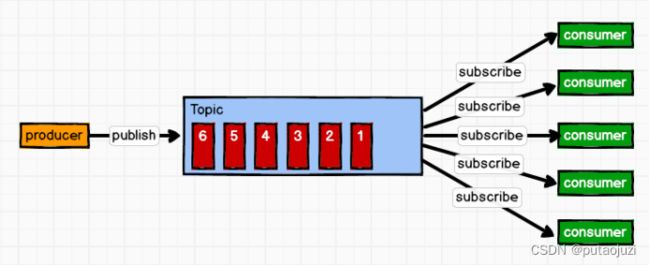
-
Kafka框架深入 :
a) topic 是一个逻辑上的概念,partition 是物理上的概念。
b) 每个partition 文件都对应一个log 文件,该log文件就是存储生产者生产的消息,生产者生产的消息会不断追加到log 文件末尾,并且每条数据都有自己的 offset。由于生产者生产的消息会不断添加到文件末尾,会使得该文件越来越大,数量增多。Kafka 采用了分片和索引机制来解决由于log文件过大导致的数据定位效率低下的问题。
index 文件存储着大量的索引信息,log文件存储大量的数据(消息)。索引文件中元数据指向对应着数据文件中message 的物理偏移量(offset)地址。
上面的内容,我们已经完成了Kafka相关知识的简单介绍了。接下来我们将进行Kafka 的集群环境搭建。
二、Kafka集群的环境搭建
-
上传压缩包到/opt/soft 目录

-
解压压缩包到指定位置:
tar -zxvf ./kafka_2.11-2.4.1.tgz -C /opt/module/ -
修改解压后的文件名称
mv kafka_2.11-2.4.1.tgz kafka
-
配置环境变量
vim /etc/profile
-
将环境变量同步到其他主机
xsync /etc/profile /etc/profile
同步后,每台机器需刷新环境变量:source /etc/profile
-
创建Kafka日志存放目录
mkdir logs

-
修改配置文件
vim server.properties

- 修改broker id ,全局唯一编号,Kafka集群中的此编号不能重复。

- 设置 Kafka运行日志存放的路径(路径为刚才创建的logs 目录)。

- 配置连接Zookeeper集群地址(Kafka也依赖于zk 来管理集群)。

- 修改broker id ,全局唯一编号,Kafka集群中的此编号不能重复。
-
将Kafka同步到hadoop102和hadoop103
xsync /opt/module/kafka /opt/module/kafka同步后,记得修改分别修改配置问价中的broker id 为2,3 。(不能重复)
-
启动集群
a) 先启动Zookeeper集群,然后启动kafka集群。
zk startb) 依次在hadoop101、hadoop102、hadoop103节点上启动kafka
在此目录下,执行
kafka-server-start.sh -daemon ./server.properties
-
关闭集群:依次在hadoop101、hadoop102、hadoop103节点上关闭kafka
kafka-server-stop.sh stop -
没错,一个一个启动、关闭实在是太不优雅了。这里提供Kafka群起和群闭的脚本。
在此目录下,创建kfk 脚本文件:
touch kfk
kfk脚本文件内容如下:
#!/bin/bash if(($#==0)) then echo "PLEASE USE:{start|stop}" exit; fi case $1 in start) for i in hadoop101 hadoop102 hadoop103 do echo "----------->$i<------------" ssh $i kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties done echo "Kafka is Running" ;; stop) for i in hadoop101 hadoop102 hadoop103 do echo "----------->$i<------------" ssh $i kafka-server-stop.sh done echo "Kafka is Shutdown"再给此文件添加执行权限,
chomod +x ./kfk。即可优雅的启动Kafka集群了。# 启动zk 集群 zk start # 启动kafka集群 kfk start # 关闭zk 集群 zk stop # 关闭kafka 集群 kfk stop
到此为止,我们已经大概了解了Kafka的相关概念,以及完善了Kafka 集群的搭建了。接下来我们将学习一些Kafka的命令行操作。
三、Kafka的命令行操作
1. 查看topic 列表:
kafka-topics.sh --list --bootstrap-server hadoop102:9092

2. 创建topic:
kafka-topics.sh --create --bootstrap-server hadoop102:9092 --topic [yourTopicName]
kafka-topics.sh --create --bootstrap-server hadoop102:9092 --topic [yourTopicName] --partitions 2 --replication-factor 3

3. 查看topic 详情:
kafka-topics.sh --describe --bootstrap-server hadoop102:9092 --topic [yourTopicName]
![]()
4. 修改topic分区数量: (只能往大的改)
xxx
5. 删除topic:
kafka-topics.sh --delete --bootstrap-server hadoop102:9092 --topic first
6. 启动生产者:
kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
![]()
7. 启动消费者:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --from-beginning
![]()
此时,启动两个终端。一个打开生产者,一个打开消费者。即可实现数据发发送和接收了。


8. 启动消费者组:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --consumer.config /opt/module/kafka_2.11-2.4.1/config/consumer.properties
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --group aa
下面对Kafka实操进行简答的讲解
四、Kafka实际操作
本次项目使用Kafka 做消息队列。数据生成器发送数据到指定的地址(也可以理解为生产者),消费者对数据进行清洗,然后将数据发送到不同主题的消息队列中。
此外,借助SparkStreaming 来充当消费者,从Kafka 的执行话题中消费数据,做到数据的实时流式处理。
这里只介绍生产者的相关代码,SparkStream 的代码,在后续的Spark 篇中进行讲解。
- 导入Kafka 相关依赖 以及fastjson 依赖。
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.62version>
dependency>
- 代码编写
@RestController
public class LoggerController {
@Autowired
private KafkaTemplate kafkaTemplate;
/*
模仿用户操作软件,并且已经接收到用户具体操作数据的流程
用户行为日志:
1. 启动日志(统计用户每日活跃量,用户每日首次启动)。
2. 正常行为日志。
*/
@RequestMapping("/applog")
public void appLog(@RequestBody String mockLog){
// 接收到的用户行为数据输出查看
System.out.println(mockLog);
// 根据数据的类型,将数据发送到不同的Kafka主题中
// 启动日志: start => key ---- start topic
// 正常行为数据: ---- event topic
// 生产者 生产数据。
JSONObject jsonObject = JSON.parseObject(mockLog);
JSONObject startJson = jsonObject.getJSONObject("start");
if(startJson != null){
kafkaTemplate.send("start",mockLog);
}else {
kafkaTemplate.send("event",mockLog);
}
}
}
这里借助KafkaTemplate 进行数据的发送。
到目前为止,我们已经能够向Kafka 消息队列中发送数据啦。接下来就需要接收数据,以及对数据进行后续的处理啦!
以上就为本篇文章的全部内容啦!
如果本篇内容对您有帮助的话,请多多点赞支持一下呗!