【C++】-C++11中的知识点(上)--右值引用,列表初始化,声明
作者:小树苗渴望变成参天大树
作者宣言:认真写好每一篇博客
作者gitee:gitee✨
作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!
文章目录
- 前言
- 一、C++11是什么?
- 二、列表初始化
- 三、声明
-
- 3.1 auto
- 3.2decltype
- 3.3 nullptr
- 四、STL中一些变化
-
- 4.1新容器
- 五、右值引用和移动语义
-
- 5.1左值引用和右值引用
- 5.2左值引用和右值引用
- 5.3右值引用的作用
- 5.4新接口
- 六、总结
前言
今天我们来讲解关于c++11的一些知识点,只是学过的只是hi都是c++98出来的,在C++11也出来了很多好用的东西,但是也有很多鸡肋的东西,今天这篇就来介绍一下,话不多说我们开始进入正文。
一、C++11是什么?
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了
C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞
进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。
从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于
C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中
约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,
C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更
强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个
重点去学习。C++11增加的语法特性非常篇幅非常多,我们这里没办法一 一讲解,所以本节课程
主要讲解实际中比较实用的语法
C++11的由来:
1998年是C++标准委员会成立的第一年,本来计划以后每5年视实际需要更新一次标准,C++国际
标准委员会在研究C++ 03的下一个版本的时候,一开始计划是2007年发布,所以最初这个标准叫
C++ 07。但是到06年的时候,官方觉得2007年肯定完不成C++ 07,而且官方觉得2008年可能也
完不成。最后干脆叫C++ 0x。x的意思是不知道到底能在07还是08还是09年完成。结果2010年的
时候也没完成,最后在2011年终于完成了C++标准。所以最终定名为C++11。
二、列表初始化
大家看清楚这是列表初始化不是初始化列表,初始化列表是在构造函数里面的,而列表初始化是给变量进行初始化的。两个是不一样的。
一切都可以使用{}进行初始化。我们来看示例一
int x = 1;
int y = { 2 };
int z{ 3 };
int a1[] = { 1,2,3 };
int a2[] { 1,2,3 };
在日常使用中最好不要去掉=。
示例二:
struct Point
{
//explicit Point(int x, int y)
Point(int x, int y)
:_x(x)
,_y(y)
{
cout << "Point(int x, int y)" << endl;
}
int _x;
int _y;
};
//本质都是调用构造函数
Point p0(0, 0);
Point p1 = { 1,1 }; // 多参数构造函数隐式类型转换
Point p2{ 2,2 };
int* ptr1 = new int[3]{ 1,2,3 };
Point* ptr2 = new Point[2]{p0,p1};
Point* ptr3 = new Point[2]{ {0,0},{1,1} };//里面一定要用{}
在c++11中支持了多参数的隐式类型转换。
列表初始化的最好的作用其实为了下面的操作,我们的vector每次定义出来都需要使用循环来给变量进行赋值,有了列表初始化就可以这样给变量赋值了
vector<int>v{1,2,3,4,5};
这不单单是列表初始化的功劳,也是另一个容器的功劳std::initializer_list我们来看看文档:

意思就是把{}里面的数据自动识别成initializer_list,vector里面也是调用了构造函数,内部类似这样的
vector(initializer_list<T> lt)
{
reserve(lt.size());
for(auto e:lt)
{
push_back(e);
}
}
每个容器的构造都包含了这个容器,我们再来看一下map的。
map<string, string> dict = { "sort", "排序", "left", "左边" };//这是错误的
map<string, string> dict = { {"sort", "排序"}, {"left", "左边"} };//这是正确的,里面的小{}是pair类型,里面内容是多参数的隐式类型转换,大{}是会转换成initializer_list类型,通过map的构造函数给变量dict进行赋值。
std::initializer_list使用场景
std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加
std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值
三、声明
c++11提供了多种简化声明的方式,尤其是在使用模板时。
3.1 auto
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局
部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将
其用于实现自动类型腿断。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初
始化值的类型。
示例:
int main()
{
int i = 10;
auto p = &i;
auto pf = strcpy;
cout << typeid(p).name() << endl;
cout << typeid(pf).name() << endl;
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
//map::iterator it = dict.begin();
auto it = dict.begin();
return 0;
}
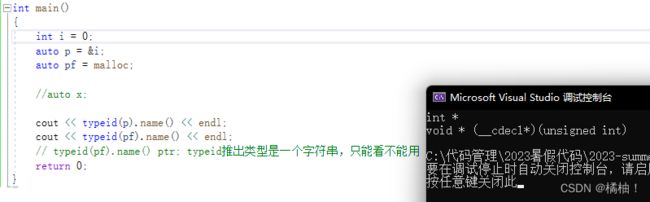
auto的用法的大家应该是非常的清楚了,typeid().name只能将类型的字符串打印出来不能作为类型,只能看不能用,但是我们的auto使用必须要初始化,如果不想初始化就必须使用decltype
3.2decltype
// decltype推出对象的类型,再定义变量,或者作为模板实参
// 单纯先定义一个变量出现
auto pf1;//错误
decltype(pf) pf2;//正确
这种情况适用于下面的场景:
template<class Func>
class B
{
private:
Func _f;
};
B<decltype(pf)> bb1;
使用decltype必须括号里面必须有变量,这样才可以。也可以推演函数的返回值。
3.3 nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示
整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
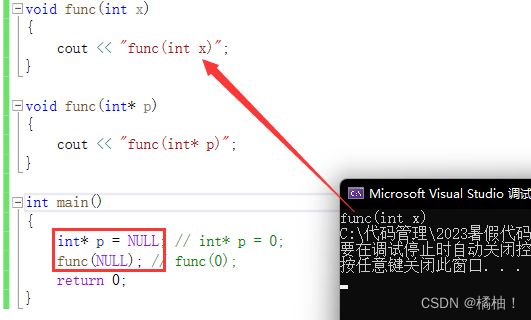
原来的空指针是宏定义的,所以会出现替换,这样就不是去调用我们想要的函数体了,就会出现问题,这也间接的体现了宏的缺点,所以在今后的开发中尽量使用const enum inline去替代宏。
四、STL中一些变化
4.1新容器
用橘色圈起来是C++11中的一些几个新容器,但是实际最有用的是unordered_map和
unordered_set。这两个我们前面已经进行了非常详细的讲解,其他的大家了解一下即可

array在vector那一节就讲过了,这里面就不介绍了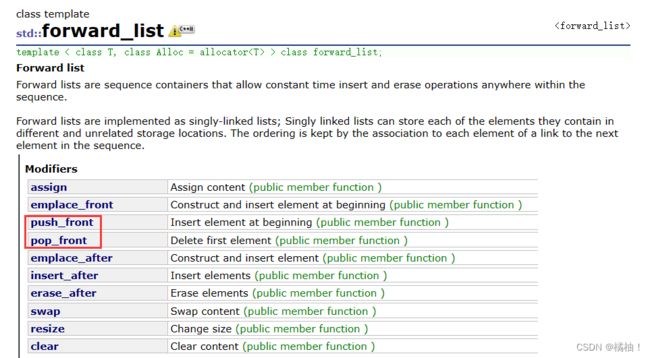
这个容器的实现结构是一个单链表,所以支持了头插头删,尾插尾删效率低,还要找到前面一个结点的位置。这个容器就相当于list的一个子集,array相当于vector的子集,所以这两个容易设计的太鸡肋了,但是initializer_list是以恶个有用的容器。
五、右值引用和移动语义
这两个是为了帮助我们提升性能的,等讲完这些我们再去讲解新接口的优点,接下来讲的知识点优点不好理解的,需要你对前面的知识非常熟悉才可以。
5.1左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们
之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
(1)什么是左值?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋
值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左
值,不能给他赋值,但是可以取它的地址。
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
//字符串常量是一个特殊的左值引用,他可以取到地址
"xxxxx";
const char* p1 = "xxxxx";
p1[2];
(2)什么是右值?
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引
用返回)等等,右值可以出现在赋值符号的右边,但是不能出现在赋值符号的左边,右值不能
取地址。
int fmin(int a, int b)
{
return a < b ? a : b;
}
10;
x + y;
fmin(x, y);
//下面是取不到地址的
cout << &10 << endl;
cout << &(x+y)<< endl;
cout << &(fmin(x, y)) << endl;
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值,右值不能出现在赋值符号的左边
10 = 1;
x + y = 1;
fmin(x, y) = 1;
5.2左值引用和右值引用
引用是取别名
左值引用就是给左值的引用,给左值取别名
右值引用就是对右值的引用,给右值取别名
double x = 1.1, y = 2.2;
// 左值引用:给左值取别名
int a = 0;
int& r1 = a;
// 左值引用能否给右值取别名?
// const左值引用可以
const int& r2 = 10;
const double& r3 = x + y;
// 右值引用:给右值取别名
int&& r5 = 10;
double&& r6 = x + y;
// 右值引用能否给左值取别名?
// 右值引用可以引用move以后的左值,但是在有的情况这样使用会出现问题的,所以不推荐这样写。
int&& r7 = move(a);
需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可
以取到该位置的地址,也就是说例如:不能取字面量10的地址,但是rr1引用后,可以对rr1取地
址,也可以修改rr1。如果不想rr1被修改,可以用const int&& rr1 去引用,是不是感觉很神奇,
这个了解一下实际中右值引用的使用场景并不在于此,这个特性也不重要。
相信大家通过上面的案例应该知道知道了什么是右值和右值引用了,所以接下来我要讲的东西才是重点。
5.3右值引用的作用
前期铺垫:
void func(const int& r)
{
cout << "void func(const int& r)" << endl;
}
void func(int&& r)
{
cout << "void func(int&& r)" << endl;
}
上面是否构成函数重载:是,第一个既能接收左值又能接收右值的所以在不改变值的情况都进来加上const.
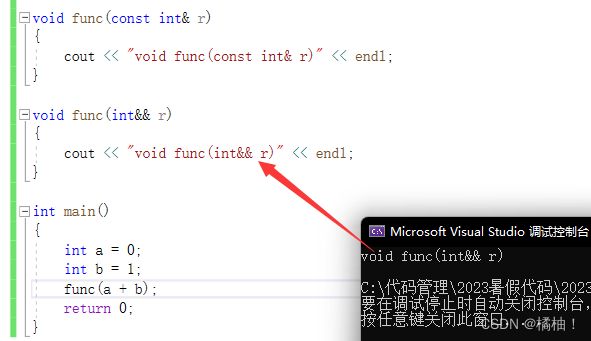
走更匹配的,有右值引用的重载,就会走右值引用版本
有了上面的知识铺垫,我们来看看右值引用是怎么起作用的
(1)移动赋值
我们来看看一段示例代码:
string func()
{
string str("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx");
return str;
}
int main()
{
string ret2;
ret2 = func();
return 0;
}
上面我们返回一个临时变量str只能使用传值返回,不能使用引用返回,引用返回只能是哪些不被销毁的变量,但是通过传值返回的就会有好多层深拷贝。
我们来画图看一下:

我们来看运行结果:
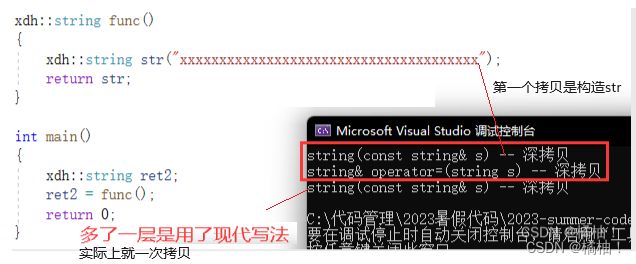
我们看到并没有和我们分析的结果是一样的啊,一会来解释。
重点:
- 内置类型的右值:是纯右值。
- 自定义类型的右值:是将亡值。
将亡值的意思就是作用域就在这一行,离开这一行就被销毁了,所以我们的func是一个函数,他本身就是一个右值,他的临时对象就是将亡值(也就是右值),然后把通过临时对象把数据拷贝给ret2,中间就是多了一层通过str把数据拷贝给临时对象,如果直接把str设置成右值,那么是不是就可以直接把数据给ret2,有了这个想法,我们来传右值,然后直接把数据交换给ret2就行了
上面代码返回值没有带引用是因为返回的是临时变量,这个带是赋值运算符的函数,两个不是同一个函数。这是移动赋值·
string& operator=(string&& s)
{
cout << "string& operator=(string s) -- 移动赋值" << endl;
swap(s);
return *this;
}
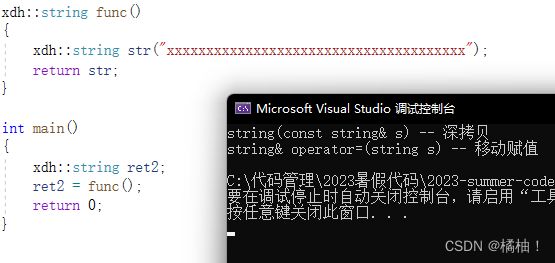
还记得知识铺垫吗,通过这个结果,我们发现调用的移动赋值,这就是说明func的返回值被解析成了右值。
再来解释一下,我们刚才没有这样写也只有一层拷贝,原因是再之前就说过,编译器会做优化的,你不写西东赋值,编译器也会把str识别成右值,就相当于编译器帮你move了一下
你要抓住传值返回的时候会构造临时对象,这个临时对象就是将亡值,也就是右值,那返回值一开始就是右值就不需要创建临时变量了。
(2)移动拷贝
示例代码:
string func()
{
string str("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx");
return str;
}
int main()
{
string ret2 = func();
return 0;
}
我们来按照上面的思路来写一个移动拷贝,构造ret2,这个不是赋值了,再类和对象的博客就说到,不是看到=就是赋值运算符,再这里是构造函数,这是移动构造
string(string&& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 移动构造" << endl;
swap(s);
}
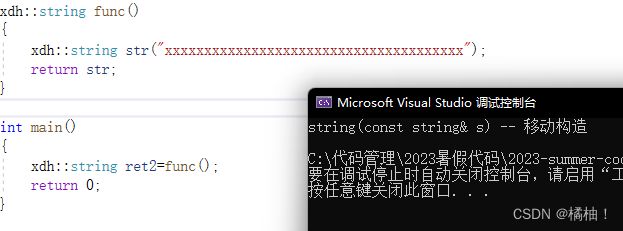
可以理解为将str与外层的ret2直接进行操作,不需要中间商的临时变量来捣乱
所以说右值引用和移动语义大大的解决了多次深拷贝的问题,所以c++11再次方面也做了较大了改变。
5.4新接口
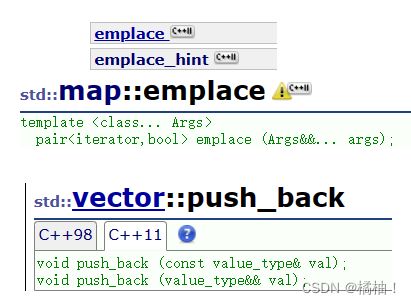
大家可以去文档官网上去查看哪些接口使用这样的操作
大家现在知识这个就行了,到时候知道为什么需要这样设计就可以提高性能,大家也可以去尝试一下怎么去使用,因为现在编译器都自己去做处理,不需要人为的进行去操作了。
所以大家写用c写题目的时候,参数有好多,尤其是数组的都是这样的,c++就不会出现这样的情况。

六、总结
相信大家学完这篇,应该也了解了c++11也出来了一些比较人性化的东西,方便我们去使用,但是也出现了一些鸡肋的东西,增加了我们的学习成本,还是希望大家下来再好好理解一下右值引用,毕竟是新的东西