AI绘画-Stable Diffusion笔记
软件:Stable Diffusion
视频教程来自
https://www.bilibili.com/video/BV1As4y127HW/?spm_id_from=333.337.search-card.all.click
提示词
提示词类别
-
内容型提示词
人物主题特征:
服饰穿搭:white dress
发型发色:blonde hair,long hair
五官特点:small eyes,big mouth
面部表情:smiling
肢体动作:stretching arms,Spread legs open,Lower body nudity
场景特征:
室内、室外:indoor/outdoor
大场景:forest,city,street
小细节:tree,bush,white flower
环境光照:
白天黑夜:day/night
特定时段:morning,.sunset
光环境:sunlight,bright,dark
天空:blue sky,.starry sky
画幅视角:
距离:close-up,distant
人物比例:full body,upper body
观察视角:from above,view of back
镜头类型:wide angle, -
标准化提示词
画质提示词:
通用高画质:best quality,ultra-detailed,masterpiece,hires,8k(最佳质量,超精细,杰作,招聘,8k)
特定高分辨率类型:
extremely detailed CG unity8 k wallpaper(超精细的8 Unity游戏CG)
unreal engine rendered(虚幻引擎渲染)
画风提示词:
插画风:lustration,painting,paint brush(光泽,油漆,油漆刷)
二次元:anime,comic,game CG(动漫、漫画、游戏CG)
写实风:photorealistic,realistic,photograph(逼真的,逼真的)
提示词语法
- 权重增减
- 括号加数字
例:(white flower:1.5)
含义:调节白花(White flower)的权重为原来的1.5倍(增强) - 套括号
圆括号(增强):(((white flower))),每套一层,额外x1.1倍。
此处:调节白花(Vhite flower)的权重为原来的1.11.11.1=1.331倍(增强)
大括号(小增强):{{{white flower}}},每套一层,额外x1.05倍。
此处:调节白花(White flower)的权重为原来的约1.15倍(增强)
方括号(削弱):[[[white flower]]],每套一层,额外x0.9倍。
此处:调节白花(White flower)的权重为原来的约0.729倍(削弱)
提示词获取 - 百度翻译自定义需求
- 图生图功能反推提示词
- 参考模型网站例图的提示词
- OpenArt:https://openart.ai/
- ArtHubAi:https://arthub.ai/
- 利用提示词工具
- 一个工具箱:http://www.atoolbox.net/Tool.php?Id=1101
- AI词语加速器:https://ai.dawnmark.cn/
提示词污染
提示词污染可以考虑使用cutoff这个插件,一定程度上能缓解颜色混乱的问题。
但是prompt不听话本质上是个跟SD底层架构有关的问题,具体到你的情况下可能原因非常多,需要自己尝试排除,是个苦功夫:
- 用了炼的不好的模型(包含大模型和LoRA):对提示词依从性不好,模型总是有自己的想法,这种情况下可以换个同类型的模型或者调整对应权重来测试
- 提示词写的有问题:数量太多、顺序不对、分组不对、过度重复、权重分配、拼写错误……等等都有可能,用提示词矩阵和提示词搜索替换来排查
- 参数不优:分辨率、采样算法、采样步数、CFG、高清修复降噪强度等等,用XYZ plot排查
- 你碰到SD的能力极限了:这种时候就得依靠图生图、场外PS和inpainting来回修图了,没啥好办法
出图参数
![[图片]](http://img.e-com-net.com/image/info8/59a09a6355f2458d83ee4a5830cf22e2.jpg)
迭代步数 (Steps):迭代步数越多,画面越清晰,大于20步之后区别不大,推荐最大值40
采样方法 (Sampler):Euler适合插画,画面朴素;DPM2M和2MKarras速度较快;推荐后面几个带有加号的

宽度和高度:影响分辨率,但是不建议太高容易出现显存不足和多人多手多脚
提示词引导系数:画面和提示词的相关性,推荐7~12
随机种子数:-1代表随机种子,也可以使用后面的绿色按钮固定种子
总批次数:ai一次性给你绘画多少次,可以调高
单批数量:ai一次给你画几张,不建议调高
图像放大
高分辨率修复
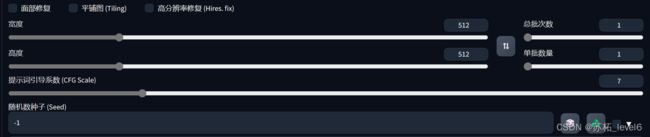
面部修复:通常勾选
平铺图:不要勾选
高分辨率修复:用来增加画面分辨率,放大倍数一般2~3,
重绘幅度:重绘幅度越高作出的画和原作越不像。重绘幅度太低容易出现边缘模糊,重绘幅度太高容易出现不必要的细节和变形,推荐0.30.5或者0.50.7
放大算法:推荐R-ESRGAN 4x+或者R-ESRGAN 4x+Anime6B(二次元)
潜变量算法(Latent)在低分二次元图的重绘中有着超越奇迹的效果,当你的模型在512x512级别的低分质量,缺少细节信息的时候,使用潜变量算法提高到0.6-0.7的重绘幅度能让你的图片直接从死复生。不过潜变量计算较为慢速,这里推荐放大幅度到1.5倍即可。后续在sd图中图插件分块vae中有潜变量空间调用,可以二次增加优化,推荐开启,再次放大1.5 重绘幅度在0.2即可。在分块中越大的重绘越不可取,如果图片细节丰富使用潜变量容易出现蹦图,因为潜变量重绘幅度过高,很容易对整体画面进行一次核打击。
SD Upscale放大脚本
这里的重叠像素为64,因此需要在宽高的部分各加64以此避免拼接区域的割裂
不过我们现在有了更加好用的放大脚本,相当于升级版——Ultimate SD Upscale
后期处理放大
还可以使用后期处理里面的放大,这里的放大就不会涉及重绘幅度,属于原原本本的放大

大模型(Checkpoint)
决定主要绘图质量
大小:大,3~7G
文件目录:models\Stable-diffusion
后缀:.ckpt .safetensors(更小更安全)
模型分类:二次元、真实、2.5D
变分自动编码器(VAE)
调色滤镜,主要影响画面色彩质感
经典通用:kl-f8-anime2.ckpt
文件目录:models\VAE
后缀:.ckpt .pt .safetensors
推荐将模型推荐的VAE改成和模型一样的名字
推荐VAE
二次元模型:
Anything:是最受欢迎的二次元融合模型。针对二次元风格拥有非常好的效果,可以用简单的词语也创造出不错的效果,可以利用它打造出非常接近于类似动漫插画、角色立绘等的画面风格。
Counterfeit:是一款泛用性很广的插画风模型,细节还原度高,可以生产出各种包含复杂、室内外场景的绘画作品,非常适合喜欢精致感风格的创作者。
Dreamlike diffusion:是一个受欢迎且非常有特色的漫画、插画风模型,可以创作出超现实的魔幻主题作品,具有幻想色彩的画面和作品。
真实模型:
Deliberate:目前最好用的真实性模型之一可以生成非常具有真实质感的图像,可以用来做人物、机器等的生成;图片生成自由度高,非常适合设计师和艺术家的头脑风暴可以用来生成各种高度自由度的图片。
realistic vision:可以用来做人像、食物、动物等的生成,非常适合创作者创作非常具有真实感的作品 limitless
originality free from interference(LOF):人物面部处理比较精致,是能真正实现照片级人像输出的大模型。
2.5D模型:
NeverEnding Dream:在造人方面有自己的一套独特审美,被许多创作者拿来结合lara,进行动漫游戏角色的二次创作,提供真实感,恰到好处地满足观众对二次元世界的想象,却又不至于在真实世界里产生过分的陌生感。
protogen:可以算是一个真实性模型,但是在实现效果上的弹性给创作带来了很多额外的自由度,可以用来描绘非常具有魔幻感的超现实画面
protogen建议使用v2.2版本,生成图略偏迪士尼3D画风,这个版本对一些tag敏感度比较奇怪,比如(beautiful detailed eyes),生成的人物眼睛简直勾魂,(detailed face)就大概率生成手办风的图片,对眼睛颜色tag就不怎么敏感。
protogen其他版本更偏真实向,但审美非常西方化,比起其他写实风模型并无优势。
另外整个protogen系列出的东方脸都是刻板印象脸,只要有亚洲相关tag,出的图都很丑逼
GuoFeng3:该模型训练生成自国内作者,整体质感偏2.5D,非常适合用来生成古风的人物服饰场景,产出的女性人像外貌也非常符合国人的审美。
文本嵌入(Embeddings)
在P站也被叫做Textual Inversion
大小:很小
文件目录:\embeddings
后缀:.pt .safetensors(更小更安全)
使用时需要参考作者给出的权重参考,为了防止过度呈现,一般会限制权重在0.9~0.95之间
典型应用:人物三视图、负面提示词(easynegative)
低秩模型(LoRa)
Lora 的意义在于和checkpoint搭配使用,用来实现某些方面的微调
大小:比较大
文件目录:\models\Lora
后缀:.pt .safetensors(更小更安全)
应用在各种游戏、动漫角色的二次创作构建
使用时需要参考作者给出的权重参考
载入模式
提示词载入: Lora:KeQing3in1:0.5
Additional Networks:它支持你同时加载最多5个LoRA并赋予他们分别的权重
应用

超网络(hypemetwork)
也叫做扩展模型
一般被用于改善生成图像的整体风格即改变画风。
文件目录:\models\hypernetwork
使用方法,需要在设置中选择扩展模型然后选择将hypernetwork添加到提示词
![[图片]](http://img.e-com-net.com/image/info8/57a8439100f04037943367ec50082339.jpg)
不过hypemetwork的作用经常可以被lora替代,因此使用频率较少
重绘
当对画面大部分内容满意只需要变动小部分内容时使用重绘
有三种方式分别是:局部重绘、涂鸦重绘、上传重绘蒙版
![**[图片]**](http://img.e-com-net.com/image/info8/fb87266b027947f48421f57533b51716.jpg)
局部重绘
- 保持提示词不变,加上新的需求
- 重绘幅度调整到0.7~0.8
- 使用鼠标在图片上涂抹需要重绘的区域

蒙版区域内容处理不同的选项差别不大有点微妙
重绘区域选择整张图片契合度更高
预留像素类似于缓冲带,重绘区域大时适当调高
蒙版模糊类似于羽化,区域大可以适当增大,控制在10以下比较好
涂鸦重绘
该功能使用步骤和局部重绘大致一致,不过增加了调色盘按钮,可以将你涂鸦的内容也作为参考内容重绘。
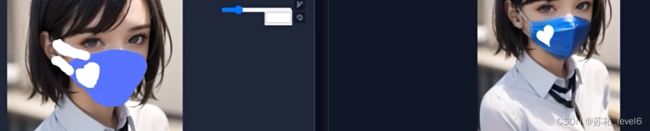
上传重绘蒙版
可以使用PS精确勾勒蒙版进行重绘
扩展
通过自带的拓展列表安装

通过拓展仓库网址安装

直接下包
文件路径:\extensions
每一个拓展是一个单独的文件夹
ControlNet
根据控制模型的不同,它能实现累计共14个不同方面的控制
使用流程
- 在图片区域导入你想要模仿的图片
- 选择不同的控制类型,如姿势等
- 点击爆炸按钮生成骨骼图
- 设置参数,点击启用,进行生成
参数列表

**控制类型:**选择想要控制的内容
**预处理器:**不同的预处理器也会侧重不同的控制类型
**模型:**需要选择和预处理器相同的模型
**控制权重:**决定这个控制效应在图片中呈现出来的强度,默认1
**引导介入/终止时机:**图像不断扩散的过程中什么时候加入影响,开始的时间晚一点可以赋予更多的自由度
**Preprocessor Resolution:**预处理图像分辨率,在性能富裕对精度要求大时可以调高
**控制模式:**控制在提示词的影响与ControlNet的影响之间更倾向于哪一个,多数时候采纳Balanced miode
![[图片]](http://img.e-com-net.com/image/info8/97f56c35ce504bf5a99bb395236fe4ac.jpg)
**完美像素模式:**它可以自动计算预处理器产出图像的最适合分辨率,避免因为尺寸不合导致的图像模糊变形,推荐选中
**允许预览:**在加载想要模仿的图片时可以自动生成骨骼图
常用五大控制模型

openpose:刻画手指动作与面部表情
depth:刻画景深,推荐带两个+的,尤其是带有肢体交叉的场景,甚至和OPENPOSE联合使用
canny:刻画外形,可以用在线稿上色。对于白底黑线的线稿图选用invert (from white bg& black line)处理
softedge:在使用canny太过约束时可以使用,只会保留大轮廓
scribble: 比softedge更自由奔放,可以实现灵魂画手丰富想象
多重混合模型
![**[图片]**](http://img.e-com-net.com/image/info8/ba8bc7fb218642c58d5dda26cc04907c.jpg)
可以使用多个ControlNet模型结合使用
更多词汇参考:
学习笔记-Stable Diffusion篇

风格系列
lora:奇幻炫彩
1girl, fish, goldfish, solo, blue eyes, bag, japanese clothes, kimono,
profile, upper body, white hair, from side, backpack, letterboxed,
bubble, red kimono, hair ornament, bangs, floral print, blush,
underwater lora:shoal-000018:1 Negative prompt: extra fingers,fewer
fingers,(low quality, worst quality:1.65), (bad anatomy), (inaccurate
limb:1.2),bad composition, inaccurate eyes, extra digit,fewer
digits,(extra arms:1.2),nipples ENSD: 31337, Size: 448x832, Seed:
2154325080, Model: Counterfeit-V3.0_fp16, Steps: 26, Sampler: DPM++ 2M
Karras, CFG scale: 8, Clip skip: 2, Model hash: cbfba64e66, Hires
steps: 20, Hires upscale: 2, Hires upscaler: Latent (nearest-exact),
Denoising strength: 0.56