谷粒商城分布式高级篇总结文档
目录
Elasticsearch
Docker安装Elaticsearch(简称:ES)
Docker安装Kibana (ES可视化界面)
启动Kibana遇到的坑
安装htop
如何删除卸载docker镜像images,重新安装启动docker镜像,查看logs日志
配置网络环境
ES入门操作和进阶操作
安装ik分词器
docker安装nginx
nginx :实现动静分离
nginx的nginx.config文件目录
nginx做静态文件服务器
Nginx反向代理和正向代理
nginx负载均衡 :轮询几种形式
自定义分词器
Elasticsearch-Rest-Client
es存储数据模型分析:
Feign远程调用失败,重复调用?接口幂等性:重试机制?
压力测试
影响性能的考虑要素
JMter安装机使用
性能压测-性能监控-堆内存与垃圾回收
性能压测-性能监控-jvisualvm使用
性能压测-优化-中间件对性能的影响
压力测试表
性能压测-优化-简单优化吞吐量测试
性能压测 ---性能优化----缓存和分布式缓存
缓存-缓存使用-整合redis测试
缓存-缓存使用-缓存穿透、雪崩、击穿
缓存-分布式锁--redis+lua 实现分布式锁
缓存-分布式锁--Redisson
Elasticsearch




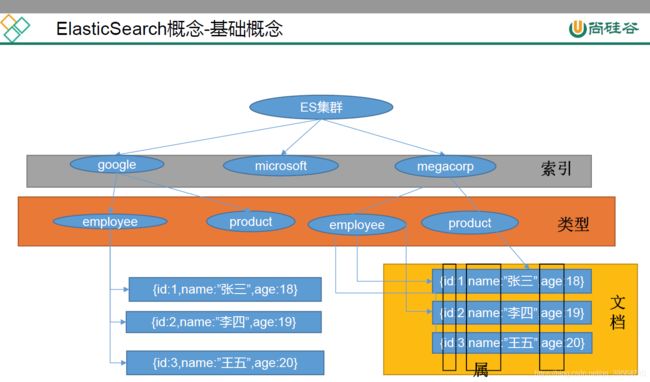
举例,mysql中保存一个数据可能是正向索引,每条数据都有id存在这,在电影表中检索红海行动,用like,mysql匹配所有的记录,看每一条记录中是否是红海行动,这样非常慢。
es首先把红海行动拆成两个单词,红海,行动,es中保存1号文档,额外又维护一张倒排索引表,存了红海,和行动的单词,在一号记录里面有,所以如图所示
查询红海特工行动,会查到12345,五条记录,3号和5号都命中两个,但是3号3个单词命中两个,5号四个单词命中两个,根据相关性得分,从高到低排列,检索出数据还可以对数据进行复杂分析
Docker安装Elaticsearch(简称:ES)
1:docker下载es
--docker pull kibana:7.4.2
2:docker 创建文件夹,挂载es配置目录
--mkdir -p /mydata/elasticsearch/config
--mkdir -p /mydata/elasticsearch/data
//写了一个配置 http.host:0.0.0.0 代表es可以被远程的任何机器访问,注意这里host:后需要有空格
--echo "http.host: 0.0.0.0">> /mydata/elasticsearch/config/elasticsearch.yml3:docker 运行 es
//为容器起一个名字为elasticsearch,-p暴露两个端口 9200 9300, 9200是发送http请求——restapi的端口,9300是es在分布式集群状态下,结点之间的通信端口, \代表换行下一行,
//-e single-node 是以单节点方式运行,ES_JAVA_OPTS不指定的话,es一启动,会将内存全部占用,整个虚拟机就卡死了,
//-v 进行挂载,目录中配置,数据等一一关联 -d 后台启动es使用指定的镜像
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.24:设置挂载目录所有读写权限
--chmod -R 777 文件名
5:设置开机启动
--docker update elasticsearch --restart=always
6:浏览器访问
http://192.168.56.10:9200/
Docker安装Kibana (ES可视化界面)
1:docker下载kibana
--docker pull kibana:7.4.2
2:docker运行 kibana (注意:这里面的ip根据自己的虚拟机地址配置)
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.218.128:9200 -p 5601:5601 -d kibana:7.4.2
3:设置开机启动
--docker update kibana --restart=always
3:浏览器访问
http://192.168.56.10:5601
启动Kibana遇到的坑
1: 日志可能会报错timeout超时
解决:把虚拟机的物理运行内存扩大,因为kibana消耗内存很大,内存扩大步骤链接:https://jingyan.baidu.com/article/e9fb46e1a4292e3420f7661c.html
2:日志中可能会报错 :
If no other Kibana instance is attempting migrations, you can get past this message by deleting index .kibana_1 and restarting Kibana.
--意思是可以通过删除索引.kibana_1过去这个消息和重新启动Kibana . .
解决办法:
删除索引,重新启动kibana,(注意:命令中的ip,是自己虚拟机的ip,也就是es的地址)
执行命令:curl -XDELETE http://192.168.56.10:9200/.kibana_1
安装htop
1:centos6安装命令
rpm -ivh https://mirrors.tuna.tsinghua.edu.cn/epel/6/x86_64/epel-release-6-8.noarch.rpm rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL yum install htop -y2:centos7安装命令
yum install epel-release -y yum install htop -y3:使用htop
直接输入命令 : htop
4:详细使用htop
链接:https://www.cnblogs.com/programmer-tlh/p/11726016.html
如何删除卸载docker镜像images,重新安装启动docker镜像,查看logs日志
1:首先查看当前运行docker 实例
--docker ps
2:停止docker中的实例
--docker stop 实例名
3:查看contain容器中的镜像实例,并进行删除
--docker ps -a
--docker rm 实例名
4:查看docker镜像,删除卸载镜像
--docker images
--docker rmi 镜像名
5:下载镜像
--docker pull 镜像名
--docker run 镜像
--docker images
6:启动镜像,重启镜像
-- docker start 镜像名
--docker restart 实例名
7:查看logs日志
--docker logs 实例id(前三位即可)
8:设置开机启动
--docker update 实例名 --restart=always
9: 查看可用的物理内存
--free -m
10:清屏
ctrl+l 或者 clear 命令
11:查看当前用户
whoami
12: 查找某个文件
whereis 文件名
13:给文件所有权限
su chmod -R 777
14:查看docker 容器实例的 内存占用情况
--docker stats
配置网络环境
设置finalshell,xshell 软件可以用用户密码连接
1: 修改文件
--vi /etc/ssh/ssh_config
2 :编辑文件,把PasswordAuthentication 改成yes
PasswordAuthentication yes
3 :重启sshd
--service sshd restart
设置可以访问外网
1 :进入文件
--cd /etc/sysconfig/network-scripts/2: 修改文件
--vi ifcfg-eth13: 在ifcfg-eth1文件中加入以下,设置网关 和 域名dns
GATEWAY=192.168.56.1
DNS1=114.114.114.114
DNS2=8.8.8.84://重启网络
--service network restart5:// 测试ping
--ping baidu.com
设置yum国内163镜像,下载速度块
1://备份原来的yum源
--mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup2 :使用新163镜像 yum源
--curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.163.com/.help/CentOS6-Base-163.repo3://运行yum 生成缓存
--yum makecache4:下载wget插件,可以用连接地址下载文件到虚拟机中
--yum install -y wget5: 下载 unzip ,解压文件
--yum install -y unzip
ES入门操作和进阶操作
参考这个地址,写的很详细:https://blog.csdn.net/qq_37223597/article/details/109265257
安装ik分词器
注意ik分词器的版本要和 es一样,ik分词器地址连接(版本是7.4.2):https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2
步骤:
1:// 切换到如下目录下,因为在es启动时候已经挂载到这个目录下面了,我们就不需要去es内部安装ik了,在挂载目录安装ik分词器即可
--cd /mydata/elasticsearch/plugins/2:// 创建ik文件夹
--mkdir ik3://下载 ik分词器在/mydata/elasticsearch/plugins/ik 文件夹下
--wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip4:// 给文件设置读写权限
--chmod -R 7775://解压zip
--unzip elasticsearch-analysis-ik-7.4.2.zip6://删除zip
--rm -rf elasticsearch-analysis-ik-7.4.2.zip7://切换 elasticsearch内部的 plugins/ 目录
-- docker exec -it elasticsearch bash8:// 进入bin 目录
-- cd bin/9:// 执行list 命令,查看 ik分词器是否已经装好
elasticsearch-plugin list10:// 重启es
docker restart elasticsearch11:// 然后在kibana中,测试分词
POST _analyze { "analyzer": "ik_smart" , "text": "我是中国人" } POST _analyze { "analyzer": "ik_max_word" , "text": "我是中国人" }
docker安装nginx
nginx :实现动静分离
官方文档:https://nginx.org/en/docs/http/load_balancing.html#nginx_load_balancing_methods
动:反向代理,处理请求;负载均衡
静:静态文件服务器
nginx的nginx.config文件目录
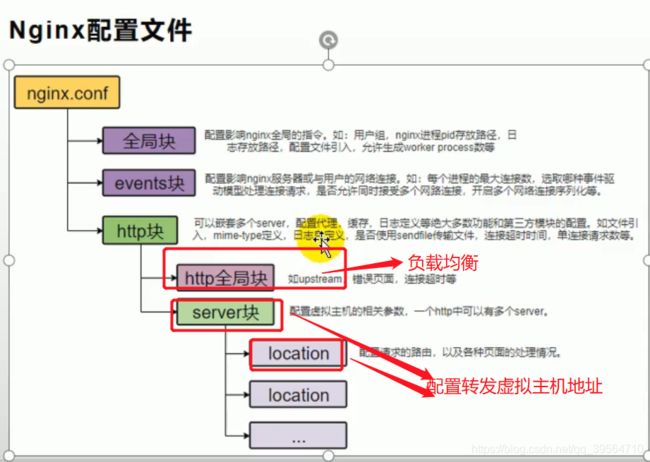
nginx做静态文件服务器
1:// 在/mydata 目录下面创建nginx
--mkdir nginx2:// 本地没有找到镜像,自动去远程下载
--docker run -p 80:80 --name nginx -d nginx:1.103"//copy容器文件到当前目录,注意后面点不能丢
--docker container cp nginx:/etc/nginx .4:// 停止nginx ,删除nginx
--docker stop nginx
--docker rm nginx5:// 切换到mydata后 把nginx改名字为conf
--mv nginx conf6://创建 nginx文件
--mkdir nginx7:// 把整个文件夹移动到 nginx下,以后nginx就在conf下面了
--mv conf nginx/8://启动nginx
注意,\前面是有空格的
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.109://设置启动项
--docker update nginx --restart=always
注意:docker启动nginx的坑,如果没有直接跳过
启动之后,在页面访问不到问题?
1://先在服务器访问一下试试能不能访问到nginx
--curl 192.168.56.10
2:如果能访问到,但是外网访问不到,那就重启docker
-- systemctl restart docker
10 :// 在nginx文件夹下,/html目录下是nginx代理的静态文件的默认路径
cd /html
11 :// 只要这个文件夹下有index.html,就会默认展示
vi index.html12://浏览器访问192.168.56.10 就能访问nginx 的首页面了
nginx就安装完成了,继续往下一步
注意:下面的要了解,不需要配置,只要把静态文件放入html 文件夹下即可
server{}节点下面的配置
#默认访问的加载的页面和路径,加载静态文件
location / {
root html;
index index.html index.htm;
}
Nginx反向代理和正向代理
nginx 的正向和反向代理 其实 就是 对的 客户端的信息 或者 是资源服务器的信息的屏蔽
正向代理:客户端通过正向代理服务器,屏蔽客户端的信息,来访问资源,例如
反向代理:客户端通过反向代理服务器访问资源,期间,通过反向代理服务器屏蔽了资源服务器的信息
反向代理的好处:
1:对外只暴漏nginx的域名,通过nginx转发给后端多个服务,保证了服务的安全性
2:节省ip,我们只需要给nginx申请一个公网ip即可,后面通过nginx转发的服务,我们用虚拟ip即可
3:负载均衡:减缓数据并发的压力,通过配置轮询的规则,减轻后端服务的压力
反向代理(也就是请求转发)实现:
在nginx.config配置中,新增server节点,写上location和proxy_pass,location中的地址也可以配置域名,例如 qiyun.com,根据后面的路径判断进入哪个服务
#配置反向代理请求转发地址,重新写一个server server { listen 9001; # 端口 server_name localhost; # 这块我们可以设置域名,比如我们给我们虚拟机ip设置的域名,例如 : qiyun.com # 教师管理系统,~为模糊匹配,只要访问路径上有edusevice,就请求http://localhost:8001 项目 location ~/eduservice/ { proxy_pass http://localhost:8001; # 这里边的路径也可以配置 域名 :qiyun.com } # 阿里云oss系统,~为模糊匹配,只要访问路径上有edusevice,就请求http://localhost:8001 项目 location ~/ossservice/ { proxy_pass http://localhost:8002; } # 模糊匹配阿里云视频点播接口 location ~ /eduvod/ { proxy_pass http://localhost:8003; } # 模糊首页轮播图接口 location ~ /cmsservice/ { proxy_pass http://localhost:8004; } # 模糊发送短信接口 location ~ /msmservice/ { proxy_pass http://localhost:8005; } # 模糊点单登录接口 location ~ /ssosevice/ { proxy_pass http://localhost:8150; } # 模糊微信扫码登录接口 location ~ /api/ucenter/wx/ { proxy_pass http://localhost:8150; } # 模糊订单接口 location ~ /orderservice/ { proxy_pass http://localhost:8006; } }
nginx负载均衡 :轮询几种形式
Nginx中upstream有以下几种方式:
1、轮询(weight=1)
默认选项,当weight不指定时,各服务器weight相同,
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。upstream bakend { server 192.168.1.10; server 192.168.1.11; }2、weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
如果后端服务器down掉,能自动剔除。
比如下面配置,则1.11服务器的访问量为1.10服务器的两倍。upstream bakend { server 192.168.1.10 weight=1; server 192.168.1.11 weight=2; }3、ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session不能跨服务器的问题。
如果后端服务器down掉,要手工down掉。upstream resinserver{ ip_hash; server 192.168.1.10:8080; server 192.168.1.11:8080; }4、fair(第三方插件)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。upstream resinserver{ server 192.168.1.10:8080; server 192.168.1.11:8080; fair; }5、url_hash(第三方插件)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存服务器时比较有效。
在upstream中加入hash语句,hash_method是使用的hash算法upstream resinserver{
server 192.168.1.10:8080; server 192.168.1.11:8080; hash $request_uri; hash_method crc32; }设备的状态有:
- down 表示单前的server暂时不参与负载
- weight 权重,默认为1。 weight越大,负载的权重就越大。
- max_fails 允许请求失败的次数默认为1。当超过最大次数时,返回proxy_next_upstream 模块定义的错误
- fail_timeout max_fails次失败后,暂停的时间。
- backup 备用服务器, 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
实现负载均衡:示例,
1:nginx直接负载均衡到各个微服务中,里面可以设置轮询规则,如上面
http { # upstream 后面的 edu,和代理的地址名称 一样 upstream edu { # 三个都是 edu的服务,也可以在里面设置轮询规格, http://192.168.56.10:8001; http://192.168.56.10:8002; http://192.168.56.10:8003; 这里面我们可以给下面三个服务设置本地域名,这个随意,上面下面哪个都可以 #http://edudns:8001; #http://edudns:8002; #http://edudns:8003; } server { listen 80; # 端口 server_name qiyun.com; # 这块我们可以设置域名,比如我们给我们虚拟机ip设置的域名,例如 : qiyun.com # 教师管理系统,~为模糊匹配,只要访问路径上有edusevice,就去请求upstream,负载均衡中的地址 location ~/eduservice/ { proxy_pass http://edu; } } }
2:nginx直接负载均衡到网关,在网关gateway中根据路径判断请求的各个微服务
http { # upstream 后面的 gateway,和代理的地址名称 一样 upstream gateway { # 三个都是 网关的服务,也可以在里面设置轮询规格,当请求到了gateway网关以后,然后在网关中根据路径地址判断请求的服务 http://192.168.56.10:8001; http://192.168.56.10:8002; http://192.168.56.10:8003; 这里面我们可以给下面三个网关服务设置本地域名,这个随意,上面下面哪个都可以 #http://gatewaydns:8001; #http://gatewaydns:8002; #http://gatewaydns:8003; } server { listen 80; # 端口 server_name qiyun.com; # 这块我们可以设置域名,比如我们给我们虚拟机ip设置的域名,例如 : qiyun.com # 让所有地址请求完都去gateway网关,就去请求upstream,负载均衡中的地址 location / { # 增加host 请求headr proxy_set_header Host $host; proxy_pass http://gateway; } } }// gateway网关配置

自定义分词器
以上ngixn配置完以后,在继续下面配置
再配置ik分词器的远程词库地址,来到自定义词库,只需要修改ik分词器的配置
13://修改IK配置文件,添加远程分词地址,也就是nginx代理的地址
--cd /mydata/elasticsearch/plugins/ik/config/
-- vim IKAnalyzer.cfg.xml
修改内容为 ,把标注的注释去掉,里面加上 nginx代理的地址,192.168.56.10/es/fenci.txt
14:.//重启es
docker restart elasticsearch
15:在kibana中测试自定义分词
自定义分词成功


Elasticsearch-Rest-Client
Elasticsearch 集成java的客户端,;版本选择7.4版本选择跟随es和kibana版本一样
详细使用参考官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-getting-started-maven.html
详细实例参考:https://blog.csdn.net/qq_37223597/article/details/109265257
1:检索需要给es存储数据,不用mysql的原因,mysql全文检索功能没有es强大,这么复杂的检索分析数据,mysql性能远不及es,es数据是存在内存中的。商品都存在内存中够吗?es是天然支持分布式的,一个es不够可以多装几个es分布在不同服务器里面。然后就会将数据分片存储。容量不够,数量来凑。
2:将商品数据es里面存一份,方便做检索功能。
3:商品从数据库里面保存到es里面这一过程,称为商品的上架。
es存储数据模型分析: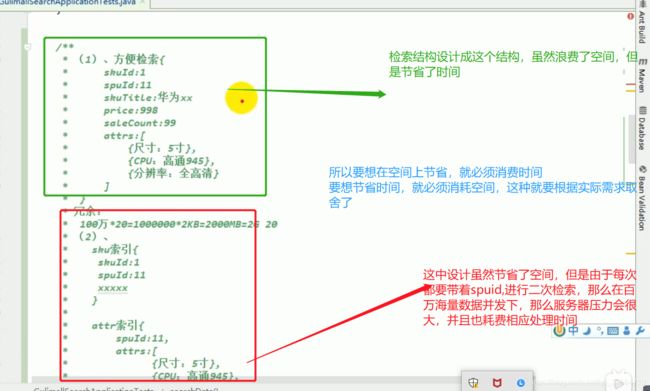

Feign远程调用失败,重复调用?接口幂等性:重试机制?
Feign调用流程:


压力测试



影响性能的考虑要素
数据库,应用程序,中间件(tomcat,nginx) 、网络和操作系统等方面
IO密集型:
网络请求流量大,磁盘读写,数据库读写数据,redis读写
解决:增加内存,增加磁盘,使用缓存,提高网卡传输效率
CPU密集型:
程序中 对大量数据的排序,遍历,以及线程的切换,都会占用cpu
对此我们可以增加cpu,优化程序
JMter安装机使用
我的连接:Jmter如何使用
性能压测-性能监控-堆内存与垃圾回收
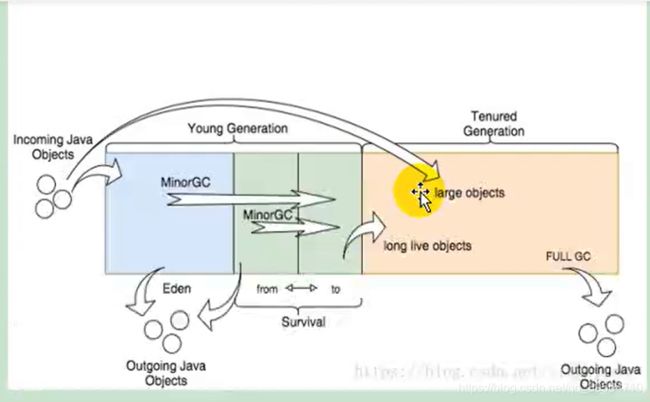
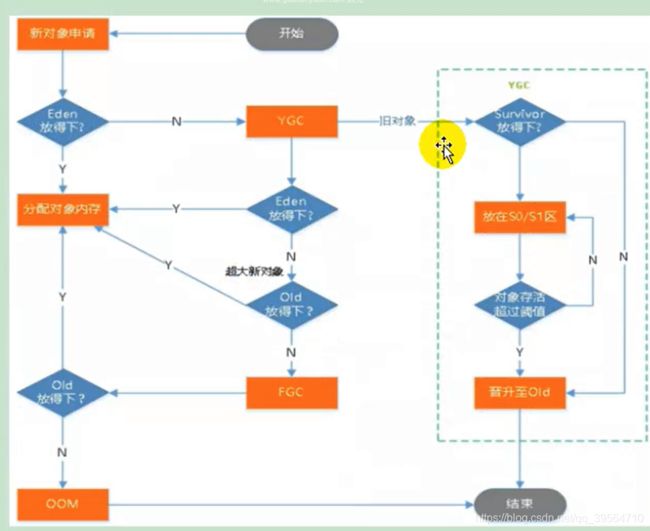
堆垃圾回收的大致过程
new一个list对象,先到新生代的 Eden区,如果内存够就存储,如果不够就新生代就进行一次小GC,把eden区没用的数据放到S0和S1区,如果gc后空间够了就存储,如果新生代还是不够,
那么就只能把list对象存储到old老年区,然后判断老年代空间够不够,如果够就存储,如果不够,就进行一次 新生代和老年代的大 fullGC,把所有的没用的数据都清楚掉,然后在看old老年代能不能存储,
如果还是不能,那么程序就会报错,OOM ,内存溢出异常
注意点:
1:每次大fullGC都特别花费时间,因为要把新生代和老年代的没用的数据都清除,所以我们要尽量这种大对象的创建,避免大fullGC的次数
2:尽量为堆内存值设置大一点:设置 堆内存的最大值 ,初始值,eden区的值, 例如 -Xmx1024m -Xms1024m -Xmn512m

jvm新建一个对象,执行gc的过程
jvm新建一个对象,执行gc的详细过程
性能压测-性能监控-jvisualvm使用
我的链接:jvisualvm的基本使用
性能压测-优化-中间件对性能的影响
JMeter压测中间件Nginx:
用JMeter压测,测试中间件 Nginx,然后在docker中,用docker stats查看nginx,cpu占用情况,然后根据JMeter压测的聚合结果报告看出Nginx的吞吐量
JMeter压测中间件gateway:
用JMeter压测,测试中间件 Nginx,然后用jvisualvm 观察网关cpu 内存占用情况,然后根据JMeter压测的聚合结果报告看出网关的吞吐量
压力测试表
| 压测内容 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 9501 | 3 | 149 |
| Gateway | 50 | 24366 | 3 | 6 |
| 简单服务 | 50 | 40574 | 2 | 6 |
| 首页一级菜单渲染 | 50 | 1294(db,thymeleaf) | 63 | 114 |
| 首页渲染(开缓存) | 50 | 1997 | 30 | 58 |
| 首页渲染(开缓存,优化数据库,关日志) | 50 | 2617 | 23 | 37 |
| 三级分类数据获取 | 50 | 22(db)/31(开缓存,优化数据库关日志后) | 2355 | 2848 |
| 三级分类(优化业务) | 50 | 316 | 269 | 435 |
| 三级分类(使用redis作为缓存) | 50 | 1942 | 34 | 52 |
| 首页全部数据获取 | 50 | 34(静态资源) | ||
| Nginx+Gateway | 50 | |||
| Gateway+简单服务 | 50 | 10313 | 9 | 20 |
| 全链路 | 50 | 2129 | 9 | 20 |
结论:中间件越多,性能损失越大,大多都损失到网络交互了;
业务代码:尽量减少对数据库的请求查询次数,然后做数据处理尽量用代码处理,在内存中处理更快
数据库: 读写分离,设置索引等,mysql优化一整套
页面展示:模板的渲染速度(cpu 内存,最重要缓存),需要用缓存来提高效率
静态资源:(tomcat还要分一些线程来处理静态资源,吞吐量下降很多,大多请求静态资源占用了后台好多线程),我们就用nginx做静态文件的管理,这样就把压力分担到nginx上了
性能压测-优化-简单优化吞吐量测试
首页渲染(开缓存,优化数据库,关日志)
数据库 :记录建索引前的消耗时间,建立索引
首页展示的静态文件:nginx动静分离
现在首页的静态资源,全部都由nginx返回,首页的数据,全部都是由tomcat返回,这就是nginx的动静分离配置,最起码现在的tomcat只处理动态请求,占用的资源就会很小了。
设置各个的服务的堆内存:尽量设置大 -Xmx1024 -Xms1024 -Xmn512
性能压测 ---性能优化----缓存和分布式缓存
哪些数据要放入缓存中:

业务实现缓存流程

注意:我们设置缓存时候一定要设置过期时间,避免业务崩溃后,会造成缓存数据与数据库永久不一致现象
缓存分析:
本地缓存,我们可以定义一个map来缓存本地数据,但是这只符合单机情况,如果多台机器服务 负载的情况下,那么map缓存不能做到同步多服务,
所以在我们分布式服务中,我们需要分布式缓存,来解决这个问题。那么我们就可以应用第三方组件redis,来专门做分布式的缓存
缓存-缓存使用-整合redis测试
官网链接: https://docs.spring.io/spring-boot/docs/2.2.10.RELEASE/reference/html/using-spring-boot.html#using-boot-starter
想看redis在springboot中的实现源码,去看RedisAutoConfiguration.class 和RedisTemplate 类
引入依赖
org.springframework.boot spring-boot-starter-data-redis 配置application.xml
redis: host: 192.168.56.10 port: 6379测试代码
String vue = redisTemplate.opsForValue().get("key"); if (!StringUtils.isEmpty(vue)){ redisTemplate.opsForValue().set("key", "123"); return "redis中的值:"+"123"; }
注意问题:
视频中讲到,依赖lettuce客户端实现的redis,在大并发请求下,是有内存泄漏的问题的,但是lettuce的5.2.1.RELEASE ,应该是没有这个问题了,我压测了,限制了最大堆内存为100m,没有出现泄漏问题
如果我们想用jredis客户端去实现 redis的话,只需要修改依赖即可:
还是建议用lettuce提供的redis,他是基于netty实现,传输速率更快,而且jedis好久没有更新了
org.springframework.boot spring-boot-starter-data-redis io.lettuce lettuce-core redis.clients jedis luttuce 和jedis只需修改依赖,不需要更改任何业务中的代码即可,redis自动装配导入了这两个

缓存-缓存使用-缓存穿透、雪崩、击穿

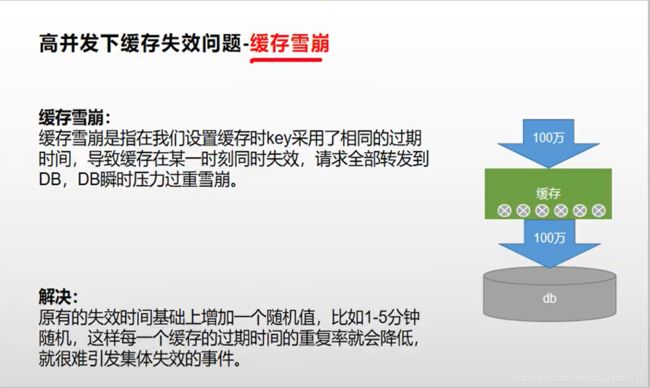

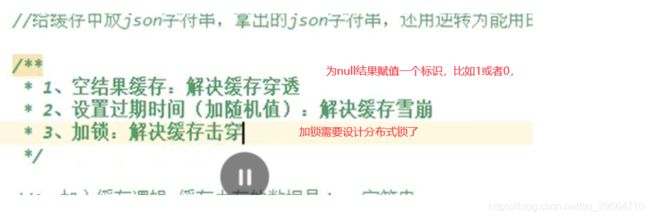
总结:
所以对这些高频数据我们加入缓存时,一定要考虑并解决 缓存穿透,雪崩,击穿的问题,否则,大并发下我们数据库时刻可能会崩溃,
并且,在解决缓存击穿的问题上,我们分布式的项目,我们需要引入分布式锁来解决,缓存击穿的问题,本地锁已经不能在分布式中使用了,使用分布式锁,那么就往下看。。。
缓存-分布式锁--Jedis/lettuce+lua 原子性 来实现分布式锁
1:为什么要用分布式锁,不用本地锁
--在分布式程序中,本地锁(sych,lock锁)已经不能解决分布式下的问题,所以我们要用redis作为分布式锁来实现
2:redis实现分布式锁的分为几个步骤?
--1:(先占有锁并设置失效时间)--2:执行应用程序--3:(获取锁的值判断 并 对比成功删除锁),但一定要保证1,3步都是原子操作
3:为什么 先占有锁 和 设置失效时间这两个操作必须要保证原子性呢?
--因为如果占有了锁,执行设置失效时间这个操作时候,这台服务程序崩溃了,就会导致这个锁永久被锁止,也就是死锁了
4:为什么我们要把 获取锁的值判断 和 对比成功删除锁 两个操作 作为一个原子操作
--因为在获取锁的值以及进行判断这个时间是有请求和执行时间的,一旦这期间正刚好锁过期时间到了,就会有别的线程进来获取锁操作数据,那么删除锁的时候就不能保证删除的是自己的那把锁了,
所以我们用lua实现,删除锁(判断+删除)的原子性,而且lua只是对redis发送一次请求。
5:在redis语法操作中哪些是原子行的
--set key value EX 30 NX ;EX 30,就表示过期时间30秒,NX,表示占有锁,这个设置EX和NX都是原子操作,
--查看剩余过期时间命令:ttl key值
5:具体代码实现
//设置占有锁 和 设置 失效时间 的 原子行 ,setIfAbsent()方法
代码: redisTemplate.opsForValue().setIfAbsent("lock","111",1, TimeUnit.MINUTES);
//设置删除锁(判断/+删除)的原子行,lua实现
String lua = "if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" + "then\n" + " return redis.call(\"del\",KEYS[1])\n" + "else\n" + " return 0\n" + "end"; //RedisScriptscript, List keys, Object... args RedisScript luaScript = RedisScript.of(lua, Long.class); //删除锁 Long lock1 = stringRedisTemplate.execute(luaScript, Arrays.asList("lock"), token);
缓存-分布式锁--Redisson
由于用jedis/lettuce+lua 实现分布式锁,还是比较麻烦,因为锁的自动加时的问题也不太好解决,所以我们直接使用Redisson,
Redisson分布式锁其实是锁的一个集合,类似我们的本地锁 有lock锁,sych锁,等等,分布锁,其实也是分布式下,这些锁的统称,其用法和我们juc下的本地锁用法类似