【计算机视觉|人脸建模】学习从图像中回归3D面部形状和表情而无需3D监督
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处
标题:Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
链接:[1905.06817] Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision (arxiv.org)
摘要
从单张图像估计3D面部形状必须对光照、头部姿势、表情、面部毛发、化妆和遮挡等变化具有鲁棒性。鲁棒性要求具备大规模的野外图像训练集,而这些图像在构建时缺乏真实的3D形状信息。为了在没有任何2D到3D监督的情况下训练网络,我们提出了RingNet,它能够从单张图像中学习计算3D面部形状。我们的关键观察是,一个人的面部形状在不同图像中是恒定的,不受表情、姿势、光照等影响。RingNet利用一个人的多张图像和自动检测的2D面部特征。它使用一种新颖的损失函数,鼓励当身份相同时,面部形状相似,而对于不同的人则不同。我们通过使用FLAME模型表示面部,实现了对表情的不变性。一旦训练完成,我们的方法接受一张图像并输出FLAME的参数,可以轻松实现动画效果。此外,我们创建了一个新的“不太野外”(NoW)人脸数据库,其中包含3D头部扫描和受试者在各种条件下的高分辨率图像。我们评估了公开可用的方法,并发现RingNet比使用3D监督的方法更准确。该数据集、模型和结果可供研究目的使用,网址为http://ringnet.is.tuebingen.mpg.de。
1. 引言
我们的目标是从一个人的单张图像中估计3D头部和面部形状。与先前的方法不同,我们感兴趣的不仅仅是面部周围的紧密裁剪区域。相反,我们估计完整的3D面部、头部和颈部。这样的表示对VR/AR、虚拟眼镜试穿、动画、生物特征等应用是必要的。此外,我们寻求一种能够捕捉3D面部表情、根据表情因素化面部形状,并能够重新摆姿和动画的表示。虽然计算机视觉文献中已经提出了许多方法来解决面部形状估计问题[40],但没有一种方法满足我们所有的目标。
具体而言,我们训练一个神经网络,直接从图像像素回归到3D面部模型的参数。在这里,我们使用FLAME [21],因为它比其他模型更精确,涵盖了各种形状,对整个头部和颈部进行建模,容易进行动画处理,并且是免费提供的。然而,训练一个网络来解决这个问题是具有挑战性的,因为几乎没有配对的3D头部/面部与人物自然图像的数据。为了使模型对成像条件、姿势、面部毛发、摄像机噪声、光照等具有鲁棒性,我们希望从大量野外图像中进行训练。这样的图像在定义上缺乏受控的真实3D数据。
这是计算机视觉中的通用问题 - 寻找2D训练数据很容易,但当配对的3D训练数据非常有限且难以获取时,从2D到3D的回归学习就变得困难。在没有真实3D的情况下,有几种选择,但每种都有问题。合成训练数据通常不能捕捉真实世界的复杂性。可以将3D模型拟合到2D图像特征,但这种映射是模棱两可的,因此不准确。由于模棱两可性,仅使用观察到的2D特征和投影的3D特征之间的损失来训练神经网络并不能取得良好的结果(参见[17])。
为了解决缺乏训练数据的问题,我们提出了一种新方法,该方法可以在没有任何监督的2D到3D训练数据的情况下,学习从像素到3D形状的映射。为此,我们仅使用OpenPose [29]自动提取的2D面部特征来学习映射。为了使这种可能,我们的关键观察是同一人的多张图像对3D面部形状提供了强有力的约束,因为形状保持不变,尽管其他因素可能发生变化,如姿势、光照和表情。FLAME可以因子化姿势和形状,使我们的模型能够学习什么是恒定的(形状)并排除发生变化的内容(姿势和表情)。
虽然事实上,同一人的面部形状在不同图像中是恒定的,但我们需要定义一种训练方法,让神经网络利用这种形状的恒定性。为此,我们引入了RingNet。RingNet使用一个人的多张图像,并强制要求所有图像对之间的形状应该相似,同时最小化观察到的特征和投影的3D特征之间的2D误差。虽然这鼓励网络以相似的方式编码形状,但我们发现这还不足够。我们还将属于不同随机人的面孔添加到“环”中,并强制要求环中所有其他图像之间的潜在空间距离大于同一人之间的距离。类似的思想已经在流形学习(例如三元组损失)[37]和人脸识别[26]中被使用,但据我们所知,我们的方法以前尚未用于学习从2D到3D几何的映射。我们发现,将三元组扩展到更大的环对学习准确的几何形状至关重要。
虽然我们使用一个人的多张图像进行训练,但请注意,在运行时,我们只需要一张单独的图像。通过这种公式,我们能够训练一个网络,直接从图像像素回归到FLAME的参数。因为我们用“野外”图像进行训练,所以该网络在各种条件下都具有鲁棒性,如图1所示。然而,该方法更为一般化,可以应用于其他2D到3D学习问题。
图1:在没有3D监督的情况下,RingNet学习从单个图像的像素到FLAME模型[21]的3D面部参数的映射。顶部:图像来自CelebA数据集[22]。底部:估计的形状、姿势和表情。

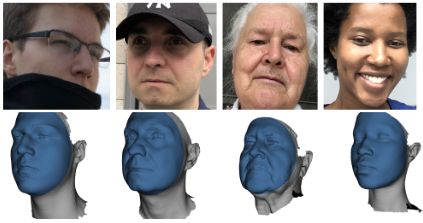
评估3D面部估计方法的准确性仍然是一个挑战,尽管已经发表了许多方法,但在各种成像条件、姿势、光照和遮挡下,没有对3D准确性进行严格的比较。为了解决这个问题,我们收集了一个名为NoW(Not quite in-the-Wild)的新数据集,其中包含100名受试者在各种条件下拍摄的高分辨率真实扫描和高质量图像(图2)。NoW比以前的数据集更复杂,我们使用它来评估所有具有公开实现的最新方法。具体而言,我们与[34]、[35]和[9]进行比较,这些方法都经过3D监督训练。尽管我们的RingNet方法没有任何2D到3D监督,但恢复了更准确的3D面部形状。我们还在具有挑战性的野外人脸图像上定性评估了该方法。
图2:NoW数据集包括在不同条件下拍摄的各种图像(顶部)和高分辨率的3D头部扫描(底部)。深蓝色区域是我们在面部挑战中考虑的部分。
总的来说,我们的论文的主要贡献有:(1)从单一面部图像中进行完整的面部、带颈部的重建。 (2)RingNet - 一种端到端可训练的网络,强制要求在主体的不同视角、光照条件、分辨率和遮挡下实现面部图像的形状一致性。 (3)一种用于从2D输入学习3D几何的新型形状一致性损失。 (4)NoW - 用于定性和定量评估3D面部重建方法的基准数据集。 (5)最后,我们免费提供模型、训练代码和新数据集,以鼓励进行定量比较[25]。
2. 相关工作
有几种方法可以解决从图像估计3D面部形状的问题。一种方法估计深度图、法线等;也就是说,这些方法产生了一个与像素相关但专门用于面部的对象形状表示。另一种方法估计可以进行动画处理的3D形状模型。我们专注于后者的方法。在最近的一篇综述文章中,Zollhöfer等人[40]描述了单目面部重建的现状,并为该领域提供了一个前瞻性的一系列挑战。请注意,监督、弱监督和无监督方法之间的界限是模糊的。大多数方法使用某种形式的3D形状模型,该模型事先从扫描中学习;在这里我们不称之为监督。这里的术语"监督"意味着使用了配对的2D到3D数据;这可能来自真实数据或合成数据。如果首先优化3D模型以适应2D图像特征,那么我们称之为使用了2D到3D的监督。如果在训练网络时使用了2D图像特征,但没有3D数据,那么这通常是弱监督,相对于2D到3D任务而言是无监督的。
量化评估:由于缺乏具有复杂图像和高质量地面实况的共同数据集,方法之间的定量比较一直受到限制。最近,Feng等人[10]组织了一个单图像到3D面部重建的挑战,其中提供了受试者的地面实况扫描。我们的NoW基准与这种方法互补,因为它专注于极端的视角、面部表情和部分遮挡。
优化:大多数现有方法需要紧密裁剪的输入图像和/或仅对适用于人脸的紧密裁剪区域进行重建。大多数当前的形状模型都是原始的Blanz和Vetter 3D可塑模型(3DMM)[3]的后裔。虽然有许多对这个模型的变体和改进,如[13],我们在这里使用FLAME [21],因为它的形状空间和表情空间都是从比其他方法更多的扫描中学到的。只有FLAME在形状空间中包括颈部区域,并且使用头部旋转时模拟颈部的姿势相关变形。紧密裁剪的面部区域使头部旋转的估计变得模棱两可。直到最近,这一直是主导范式[2、30、11]。例如,Kemelmacher-Shlizerman和Seitz [18]使用多图像阴影重建图像集,允许视点和形状的变化。Thies等人[33]在单目视频序列上获得准确的结果。虽然这些方法可以在高逼真度下取得良好的结果,但它们计算成本高昂。
使用3D监督进行学习:深度学习方法迅速取代基于优化的方法[35、39、19、16]。例如,Sela等人[27]使用合成数据集生成图像到深度映射和像素到顶点映射,二者结合生成面部网格。Tran等人[34]直接回归面部模型的3DMM参数,使用密集网络。他们的关键思想是使用同一主体的多个图像,并使用2D标志物拟合每个图像的3DMM。然后,他们取拟合网格的加权平均值用作训练网络的ground truth。Feng等人[9]从图像回归到记录3D面部位置信息的UV位置图,提供对UV空间上每个点的语义含义的密集对应关系。所有上述方法都使用了某种形式的3D监督,如合成渲染、基于3DMM的优化拟合,或使用3DMM生成UV映射或体积表示。在基于拟合的方法中,没有一种方法能够为真实世界的面部图像产生真实的ground truth,而合成生成的面部可能无法很好地推广到真实世界[31]。依赖将3DMM拟合到图像中,使用2D-3D对应关系创建伪地面实况的方法始终受到3DMM的表现力和拟合过程的准确性的限制。
使用弱3D监督进行学习:Sengupta等人[28]通过使用混合合成渲染图像和真实图像来学习模仿Lambertian渲染过程。他们处理了紧密裁剪的面部,不生成可以进行动画处理的模型。Genova等人[12]提出了一种使用可微分渲染过程的端到端学习方法。他们还使用合成数据及其相应的3D参数来训练他们的编码器。Tran和Liu [36]通过使用具有解析可微分渲染层的非线性3DMM模型,以弱监督的方式学习3DMM模型。
没有3D监督进行学习:MoFA [32]估计3DMM的参数,并使用光度损失和可选的2D特征损失进行端到端训练。从本质上讲,它是Blanz和Vetter模型的神经网络版本,因为它模拟了形状、皮肤反射和照明,生成与输入匹配的逼真图像。这种方法的优势在于它比优化方法快得多[31]。MoFA估计了面部的紧密裁剪,产生了看起来很好的结果,但在处理极端表情时存在问题。他们只对真实图像使用FaceWarehouse模型作为“ground truth”进行定量评估;这不是真实3D面部形状的准确表示。
所有没有任何2D到3D监督的学习方法都明确地对图像形成过程进行建模(如Blanz和Vetter),并制定光度损失,通常还结合了与3D模型已知对应关系的2D面部特征检测。光度损失的问题在于图像形成模型总是近似的(例如Lambertian)。理想情况下,人们希望网络不仅能学到面部形状,还能学到真实世界图像的复杂性以及它们与形状的关系。为此,我们的RingNet方法仅使用2D面部特征,没有光度项。尽管(或因为)如此,该方法能够直接从像素到3D面部形状进行学习。这是已发表方法中最少监督的一种。
3. 提出的方法
我们方法的目标是从单张面部图像I中估计3D头部和面部形状。给定一张图像,我们假设已经检测到了面部,进行了松散的裁剪,并大致居中。在训练期间,我们的方法利用2D标志物和身份标签作为输入。在推理期间,它仅使用图像像素;不使用2D标志物和身份标签。
关键思想:
关键思想可以总结如下:
- 一个人的面部形状保持不变,即使面部图像在视角、光照条件、分辨率、遮挡、表情或其他因素上有所变化。
- 每个人都有独特的面部形状(不考虑相同的双胞胎)。我们通过引入形状一致性损失来利用这个想法,体现在我们的环形网络结构中。
RingNet(图3)是一个基于多个编码器-解码器的体系结构,其中编码器之间共享权重,并在形状变量上施加形状约束。环中的每个编码器都是特征提取网络和回归器网络的组合。在形状变量上施加形状约束迫使网络将面部形状、表情、头部姿势和相机参数解耦。我们使用FLAME [21]作为解码器,从语义上有意义的嵌入中重建3D面部,以及在嵌入空间中获得语义上有意义的参数的解耦(即形状、表情和姿势参数)。
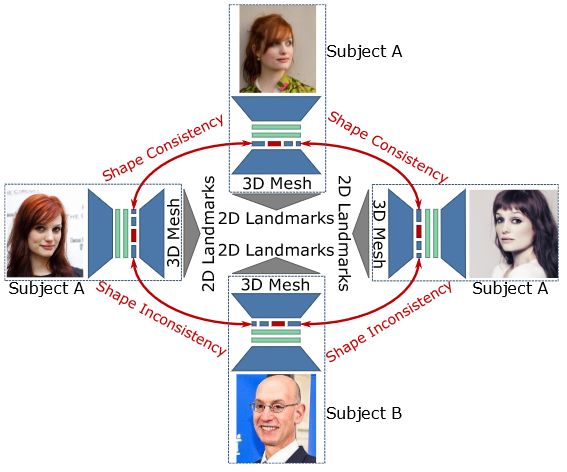
图3:RingNet在训练过程中获取同一人物(主体A)的多个图像和另一个人物(主体B)的图像,并在相同主体之间强制执行形状一致性以及在不同主体之间强制执行形状不一致性。从预测的3D网格计算的3D地标在2D域中投影以计算与地面真实2D地标的损失。在推理过程中,RingNet以单个图像作为输入并预测相应的3D网格。图像来自[6]。该图是为了说明目的而简化的版本。
我们将在接下来更详细地介绍FLAME解码器、RingNet体系结构和损失。
3.1. FLAME模型
FLAME使用线性变换来描述与身份和表情相关的形状变化,并使用标准的线性混合蒙皮(LBS)来模拟围绕 K = 4 K = 4 K=4个关节的颈部、下巴和眼球旋转。由形状系数参数化, β ⃗ ∈ R ∣ β ⃗ ∣ \vec{β} \in \mathbb{R}^{|\vec{β}|} β∈R∣β∣,姿势 θ ⃗ ∈ R ∣ θ ⃗ ∣ \vec{θ} \in \mathbb{R}^{|\vec{θ}|} θ∈R∣θ∣,和表情 ψ ⃗ ∈ R ∣ ψ ⃗ ∣ \vec{ψ} \in \mathbb{R}^{|\vec{ψ}|} ψ∈R∣ψ∣,FLAME返回 N = 5023 N = 5023 N=5023个顶点。
FLAME模型了与身份相关的形状变化 B S ( β ⃗ ; S ) : R ∣ β ⃗ ∣ → R 3 N B_S(\vec{β};\pmb{S}):\mathbb{R}^{|\vec{β}|} \rightarrow \mathbb{R} ^ {3N} BS(β;S):R∣β∣→R3N,校正姿势混合形状 B P ( θ ⃗ ; P ) : R ∣ θ ⃗ ∣ → R 3 N B_P(\vec{θ};\pmb{P}):\mathbb{R}^{|\vec{θ}|} \rightarrow \mathbb{R} ^ {3N} BP(θ;P):R∣θ∣→R3N,以及表情混合形状 B E ( ψ ⃗ ; E ) : R ∣ ψ ⃗ ∣ → R 3 N B_E(\vec{ψ};\pmb{E}):\mathbb{R}^{|\vec{ψ}|} \rightarrow \mathbb{R} ^ {3N} BE(ψ;E):R∣ψ∣→R3N,作为具有学习基础 S \mathcal{S} S、 E \mathcal{E} E和 P \mathcal{P} P的线性变换。给定模板 T ‾ ∈ R 3 N \overline{\pmb{T}} \in \mathbb{R}^{3N} T∈R3N处于“零姿势”,身份、姿势和表情混合形状被建模为相对于 T ‾ \overline{\pmb{T}} T的顶点偏移。每个姿势向量 θ ⃗ ∈ R 3 K + 3 \vec{θ} \in \mathbb{R}^{3K+3} θ∈R3K+3包含 ( K + 1 ) (K+1) (K+1)个轴角表示中的旋转向量;即每个关节加上全局旋转一个向量。混合蒙皮函数 W ( T ‾ , J , θ ⃗ , W ) W (\overline{\pmb{T}}, \pmb{J}, \vec{θ}, \mathcal{W}) W(T,J,θ,W)然后围绕关节 J ∈ R 3 K \pmb{J} \in \mathbb{R}^{3K} J∈R3K旋转顶点,由混合权重 W ∈ R K × N \mathcal{W} \in \mathbb{R} ^ {K \times N} W∈RK×N线性平滑。
更正式地,FLAME表示为:
M ( β ⃗ , θ ⃗ , ψ ⃗ ) = W ( T P ( β ⃗ , θ ⃗ , ψ ⃗ ) , J ( β ⃗ ) , θ ⃗ , W ) , (1) M(\vec{β},\vec{θ},\vec{ψ})=W(T_P(\vec{β},\vec{θ},\vec{ψ}),\pmb{J}(\vec{β}),\vec{θ},\mathcal{W}), \tag{1} M(β,θ,ψ)=W(TP(β,θ,ψ),J(β),θ,W),(1)
其中
T P ( β ⃗ , θ ⃗ , ψ ⃗ ) = T ‾ + B S ( β ⃗ ; S ) + B P ( θ ⃗ ; P ) + B E ( ψ ⃗ ; E ) , (2) T_P(\vec{β},\vec{θ},\vec{ψ})=\overline{\pmb{T}}+B_S(\vec{β};\mathcal{S})+B_P(\vec{θ};\mathcal{P})+B_E(\vec{ψ};\mathcal{E}), \tag{2} TP(β,θ,ψ)=T+BS(β;S)+BP(θ;P)+BE(ψ;E),(2)
由于不同的面部形状需要不同的关节位置,关节被定义为与 β ⃗ \vec{β} β相关的函数。我们使用方程1来解码我们的嵌入空间,以生成完整头部和面部的3D网格。
3.2. RingNet
最近在人脸识别(例如[38])和面部标志检测(例如[4, 29])方面的进展导致了带有身份标签和2D面部标志的大型图像数据集。在训练中,我们假设有一组2D面部图像 I i I_i Ii,对应的身份标签 c i c_i ci和标志 k i k_i ki。
形状一致性假设可以通过 β i ⃗ = β j ⃗ , ∀ c i = c j \vec{β_i} = \vec{β_j},∀c_i = c_j βi=βj,∀ci=cj(即一个主体的面部形状在多个图像中应保持不变),以及 β i ⃗ ≠ β j ⃗ , ∀ c i ≠ c j \vec{β_i} \neq \vec{β_j},∀c_i \neq c_j βi=βj,∀ci=cj(即不同主体的面部形状应该是不同的)来形式化。RingNet引入了一个环形结构,可以同时优化任意数量的输入图像的形状一致性。有关形状一致性的详细信息,请参见第3节。
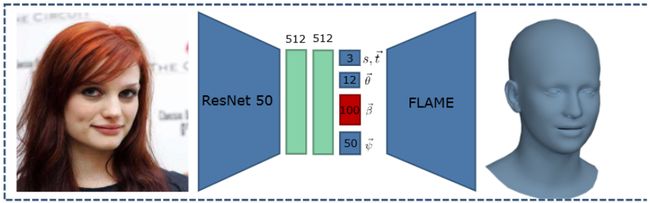
RingNet分为 R R R个环元素 e i = 1 i = R e^{i=R}_{i=1} ei=1i=R,如图3所示,其中每个ei都包括一个编码器和一个解码器网络(见图4)。编码器在 e i e_i ei之间共享权重,解码器在训练期间保持不变。编码器是特征提取网络 f f e a t f_{feat} ffeat和回归网络 f r e g f_{reg} freg的组合。给定图像 I i I_i Ii, f f e a t f_{feat} ffeat输出一个高维向量,然后由 f r e g f_{reg} freg编码成一个语义上有意义的向量(即 f e n c ( I i ) = f r e g ( f f e a t ( I i ) ) f_{enc}(I_i) = f_{reg}(f_{feat}(I_i)) fenc(Ii)=freg(ffeat(Ii)))。这个向量可以表示为相机、姿势、形状和表情参数的串联,即 f e n c ( I i ) = [ c a m i , θ ⃗ i , β ⃗ i , ψ ⃗ i ] f_{enc}(I_i) = [cam_i, \vec θ_i, \vec β_i, \vec ψ_i] fenc(Ii)=[cami,θi,βi,ψi],其中 θ ⃗ i , β ⃗ i , ψ ⃗ i \vec θ_i,\vec β_i,\vec ψ_i θi,βi,ψi是FLAME参数。
图4:输出图像的3D网格的Ring元素。
为简单起见,我们在以下省略 I I I,使用 f e n c ( I i ) = f e n c , i f_{enc}(I_i) = f_{enc,i} fenc(Ii)=fenc,i和 f f e a t ( I i ) = f f e a t , i f_{feat}(I_i) = f_{feat,i} ffeat(Ii)=ffeat,i。回归网络通过迭代误差反馈循环[17, 7]迭代地回归 f e n c , i f_{enc,i} fenc,i,而不是直接从 f f e a t , i f_{feat,i} ffeat,i回归 f e n c , i f_{enc,i} fenc,i。在每个迭代步骤中,从先前的估计中进行渐进性移动,以达到当前估计。形式上,回归网络将串联的 [ f f e a t , i t , f e n c , i t ] [f^t_{feat,i}, f^t_{enc,i}] [ffeat,it,fenc,it]作为输入,并输出 δ f e n c , i t δf^t_{enc,i} δfenc,it。然后我们通过以下方式更新当前估计,
f e n c , i t + 1 = f e n c , i t + δ f e n c , i t (3) {f_{enc,i}}^{t+1} = {f_{enc,i}}^{t} + δ{f_{enc,i}}^{t} \tag{3} fenc,it+1=fenc,it+δfenc,it(3)
该迭代网络在整个RingNet训练的每个迭代中执行多个回归迭代。初始估计设置为 0 ⃗ \vec 0 0。然后,将回归网络的输出馈送到可微的FLAME解码器网络,该解码器网络输出3D头部网格。
环元素 R R R的数量是我们网络的一个超参数,它确定在 β ⃗ \vec β β上进行优化一致性的并行处理的图像数量。RingNet允许同时使用同一主体的图像和不同主体的图像的任意组合。然而,为了不失一般性,我们将相同身份的面部图像提供给 { e j } j = 1 j = R − 1 {\{e_j\}}^{j=R−1}_{j=1} {ej}j=1j=R−1,将不同身份的图像提供给 e R e_R eR。因此,对于每个输入训练批次,每个切片包含 R − 1 R-1 R−1个相同人的图像和另一个人的一个图像(见图3)。
3.3. Shape Consistency Loss
为简化起见,让我们称具有相同身份标签的两个主体为“匹配对”,而具有不同身份标签的两个主体为“不匹配对”。我们工作的一个关键目标是创建一个强大的端到端可训练的网络,可以从同一主体的图像中产生相同的形状,并对不同主体产生不同的形状。换句话说,我们希望使我们的形状生成器具有区分性。我们通过要求匹配对在形状空间中的距离比不匹配对小一个边界值 η η η来强制执行这一点。距离是在面部形状参数的空间中计算的,这对应于中性姿势下顶点的欧几里得空间。
在RingNet结构中, e j e_j ej和 e k e_k ek产生 β ⃗ j \vec β_j βj和 β ⃗ k \vec β_k βk,当 j ≠ k j \neq k j=k且 j , k ≠ R j,k \neq R j,k=R时,它们是匹配对。类似地, e j e_j ej和 e R e_R eR产生 β ⃗ j \vec β_j βj和 β ⃗ R \vec β_R βR,当 j ≠ R j \neq R j=R时,它们是不匹配对。我们的形状一致性项为:
∥ β j ⃗ − β k ⃗ ∥ 2 2 + η ≤ ∥ β j ⃗ − β R ⃗ ∥ 2 2 (4) \left\| \vec {\beta_j} - \vec {\beta_k} \right\|_2^2 + \eta \leq \left\| \vec {\beta_j} - \vec {\beta_R} \right\|_2^2 \tag{4} βj−βk 22+η≤ βj−βR 22(4)
因此,我们在训练RingNet端到端时最小化以下损失:
L S = ∑ i = 1 n b ∑ j , k = 1 R − 1 max ( 0 , ∥ β i j ⃗ − β i k ⃗ ∥ 2 2 − ∥ β i j ⃗ − β i R ⃗ ∥ 2 2 + η ) (5) L_S = \sum_{i=1}^{n_b} \sum_{j,k=1}^{R-1} \max\left(0, \left\| \vec {\beta_{ij}} - \vec {\beta_{ik}} \right\|_2^2 - \left\| \vec {\beta_{ij}} - \vec {\beta_{iR}} \right\|_2^2 + \eta\right) \tag{5} LS=i=1∑nbj,k=1∑R−1max(0, βij−βik 22− βij−βiR 22+η)(5)
其可以归一化为:
L S C = 1 n b × R × L S (6) L_{SC} = \frac{1}{n_b \times R} \times L_S \tag{6} LSC=nb×R1×LS(6)
n b n_b nb是环中每个元素的批处理大小。
3.4. 2D Feature Loss
最后,我们计算在训练过程中提供的地面真实标志和预测标志之间的L1损失。请注意,我们不直接预测2D标志,而是从已知拓扑结构的3D网格中检索。
给定FLAME模板网格,我们为每个OpenPose [29]关键点定义了网格表面上对应的3D点。请注意,这是我们提供连接2D和3D的监督的唯一地方。这只做一次。嘴巴、鼻子、眼睛和眉毛关键点具有固定的对应3D点(称为静态3D标志),轮廓特征的位置随头部姿势而变化(称为动态3D标志),与[5, 31]类似,我们将轮廓标志建模为随全局头部旋转动态移动(见Sup. Mat.)。为了自动计算这个动态轮廓,我们将FLAME模板在左右旋转-20到40度之间,用纹理渲染网格,运行OpenPose预测2D标志,并将这些2D点投影到3D表面。得到的轨迹在脸的左右两侧对称传输。
在训练期间,RingNet输出3D网格,为这些网格计算静态和动态3D标志,并使用编码器输出中预测的相机参数将这些标志投影到图像平面。因此,我们计算投影标志kpi和地面真实2D标志ki之间的以下L1损失:
L proj = ∥ w i × ( k p i − k i ) ∥ 1 (7) L_{\text{proj}} = \|w_i \times (k_{pi} - k_i)\|_1 \tag{7} Lproj=∥wi×(kpi−ki)∥1(7)
其中 w i w_i wi是由2D标志预测器提供的每个地面真实标志的置信度得分。如果置信度高于0.41,则将其设置为1,否则设置为0。训练RingNet端到端的总损失 L t o t L_{tot} Ltot是:
L tot = λ SC L SC + λ proj L proj + λ β ~ ∥ β ~ ∥ 2 2 + λ ψ ~ ∥ ψ ~ ∥ 2 2 (8) L_{\text{tot}} = \lambda_{\text{SC}} L_{\text{SC}} + \lambda_{\text{proj}} L_{\text{proj}} + \lambda_{\tilde{\beta}} \|\tilde{\beta}\|_2^2 + \lambda_{\tilde{\psi}} \|\tilde{\psi}\|_2^2 \tag{8} Ltot=λSCLSC+λprojLproj+λβ~∥β~∥22+λψ~∥ψ~∥22(8)
其中 λ λ λ是每个损失项的权重,最后两项对形状和表情系数进行正则化。由于 B S ( β ⃗ ; S ) B_S(\vec β; \mathcal S) BS(β;S)和 B E ( ψ ⃗ ; E ) B_E( \vec ψ; \mathcal E) BE(ψ;E)被平方方差缩放, β ⃗ \vec β β和 ψ ⃗ \vec ψ ψ的L2范数表示正交形状和表情空间中的马哈拉诺比斯距离。
3.5. 实现细节
特征提取网络使用预训练的 ResNet50 [15] 架构,在训练期间也进行了优化。特征提取网络输出一个 2048 维向量,作为回归网络的输入。回归网络包括两个维度为 512 的全连接层,带有 ReLu 激活和 dropout,接着是一个最终的线性全连接层,输出为 159 维。对这个 159 维的输出向量,我们连接了相机、姿势、形状和表情参数。前三个元素表示比例和 2D 图像平移。接下来的 6 个元素是全局旋转和颚部旋转,都是在轴角表示法中。由于 FLAME 的颈部和眼球旋转不对应于面部标记,因此不进行回归。接下来的 100 个元素是形状参数,然后是 FLAME 的 50 个表情参数。可微分的 FLAME 层在训练期间保持不变。我们使用学习率为 1e-4 的 Adam [20] 优化器对 RingNet 进行 10 轮训练。不同的模型参数为 R = 6 R = 6 R=6, λ S C = 1 λ_{SC} = 1 λSC=1, λ p r o j = 60 λ_{proj} = 60 λproj=60, λ β ⃗ = 1 e − 4 λ_{\vec β} = 1e − 4 λβ=1e−4, λ ψ ⃗ = 1 e − 4 λ_{\vec ψ} = 1e − 4 λψ=1e−4, η = 0.5 η = 0.5 η=0.5。RingNet 架构在 Tensorflow [1] 中实现,并将公开发布。我们使用 VGG2 人脸数据库 [6] 作为训练数据集,其中包含面部图像及其相应的标签。我们在数据库上运行 OpenPose [29] 并计算面部的 68 个标记点。OpenPose 对许多情况都无法成功。在清理了失败的情况后,我们得到了大约 80 万张图像,以及相应的标签和面部标记,用于我们的训练语料库。我们还考虑了由 [4] 提供的约 3000 张具有极端姿势的图像及其相应的标记。由于对于这些极端图像我们没有任何标签,我们通过随机裁剪和缩放来复制每个图像,以考虑匹配对。
4. 基准数据集和评估指标
本节介绍了我们的 NoW 基准测试,用于从单眼图像进行 3D 面部重建的任务。该基准测试的目标是引入一个标准评估指标,以测量在视角、光照和常见遮挡变化下 3D 面部重建方法的准确性和鲁棒性。
数据集:该数据集包含 100 名受试者的 2054 张 2D 图像,使用 iPhone X 拍摄,并为每个受试者单独提供了一个 3D 头部扫描。这个头部扫描用作评估的地面真实。选择的受试者包含年龄、BMI 和性别的变化(55 名女性,45 名男性)。
我们将捕获的数据分为四个挑战:中性(620 张图像)、表情(675 张图像)、遮挡(528 张图像)和自拍(231 张图像)。中性、表情和遮挡包含所有受试者的中性、富有表情和部分遮挡的面部图像,从正面视图到侧面视图不等。表情包含不同的表情,如快乐、悲伤、惊讶、厌恶和恐惧。遮挡包含具有不同遮挡的图像,如眼镜、太阳镜、面部毛发、帽子或兜帽等。对于自拍类别,参与者被要求使用 iPhone 自拍,而不对执行的面部表情施加任何限制。这些图像在室内和室外捕获,以提供自然和人工光的变化。
对于所有类别的挑战都是在给定单眼图像的情况下重建一个中性的 3D 面部。请注意,几张图像中存在面部表情,这需要方法来分离身份和表情,以评估预测的身份的质量。
捕获设置:对于每个受试者,我们使用主动立体系统(3dMD LLC,亚特兰大)捕获中性表情的原始头部扫描。多摄像头系统包括六对灰度立体摄像头、六个彩色摄像头、五个斑点图案投影仪和六个白色 LED 面板。重建的 3D 几何对于每个受试者包含约 12 万个顶点。每个受试者在扫描过程中佩戴头巾,以避免由于头发导致的面部或颈部区域的遮挡和扫描仪噪声。
数据处理:大多数现有的 3D 面部重建方法需要对面部进行定位。为了减轻这个预处理步骤的影响,我们为每个图像提供一个覆盖面部的边界框。为了获得所有图像的边界框,我们首先对所有图像运行一个面部检测器 [38],然后为每个检测到的面部预测关键点 [4]。我们对失败案例手动选择 2D 地标。然后,我们将地标的边界框向每一侧扩展 5%(底部)、10%(左右)和 30%(顶部),以获得涵盖整个面部,包括前额的框。对于面部挑战,我们遵循类似于 [10] 的处理协议。对于每个扫描,选择面部中心,并通过删除指定半径外的一切来裁剪扫描。所选半径是特定于主体的,计算方法为 0.7 × (外眼距离 + 鼻距离)(见图 2)。
评估指标:在给定单眼图像的情况下,挑战是重建一个 3D 面部。由于预测的网格出现在不同的本地坐标系中,通过使用预测和扫描之间的一组相应的地标对重建的 3D 网格进行刚性对齐(旋转、平移和缩放)。我们进一步执行基于扫描到网格距离的刚性对齐(即每个扫描顶点与网格表面上最近点之间的绝对距离),使用地标对齐作为初始化。然后,计算每个图像的误差,即地面真实扫描与重建网格之间的扫描到网格距离。然后报告不同的错误,包括所有距离的累积错误图,中位距离,平均距离和标准偏差。
如何参与:要参与挑战,我们提供一个网站 [25],用于下载测试图像,并上传每个注册的重建结果和选定的地标。然后,自动计算并返回误差指标。请注意,我们不提供地面真实扫描,以防止在测试数据上进行微调。
5. 实验
我们对RingNet进行了定性和定量评估,并与公开可用的方法进行了比较,这些方法包括:PRNet(ECCV 2018 [9])、Extreme3D(CVPR 2018 [35])和3DMM-CNN(CVPR 2017 [34])。
定量评估:我们在[10]和我们的NoW数据集上比较了不同方法。
Feng等人的基准:Feng等人[10]描述了一个用于评估从单个图像进行3D面部重建的基准数据集。他们提供了一个测试数据集,其中包含面部图像及其对应于Stirling/ESRC 3D面部数据库子集的3D地面真实面部扫描。测试数据集包含2000张2D中性面部图像,包括656张高质量(HQ)图像和1344张低质量(LQ)图像。高质量图像是在受控场景中拍摄的,而低质量图像则是从视频帧中提取的。该数据侧重于中性面部,而我们的数据在表情、遮挡和照明方面具有更高的变化性,如第4节所述。
请注意,我们与之比较的方法(PRNet、Extreme3D、3DMM-CNN)在训练时使用了3D监督,而我们的方法没有。PRNet [9] 要求非常紧密地裁剪面部区域才能获得良好的结果,并且在给定基准数据库的松散裁剪输入图像时表现不佳(参见补充资料)。我们没有尝试为PRNet裁剪图像,而是在给定图像上运行它,并注意其成功的情况:对于低分辨率测试图像,它输出了918个网格,对于高质量图像,输出了509个网格。为了与PRNet进行比较,我们仅在PRNet成功的1427张图像上运行所有其他方法。
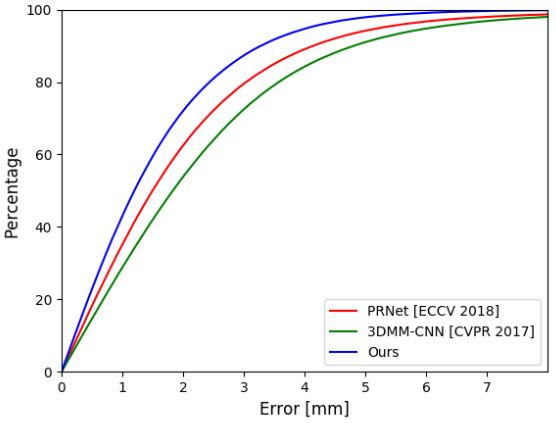
我们使用[10]中的方法计算误差,该方法计算从地面真实扫描点到估计的网格表面的距离。图5(左和中)显示了不同方法在低质量和高质量图像上的累积误差曲线;RingNet优于其他方法。表1报告了均值、标准差和中值误差。
图5:累积误差曲线。从左到右:[10]的低质量数据。[10]的高质量数据。NoW数据集面部挑战。
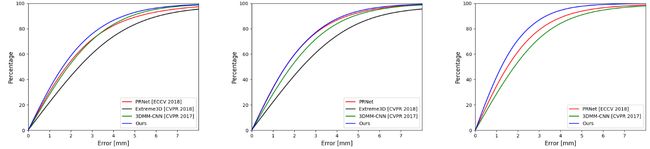
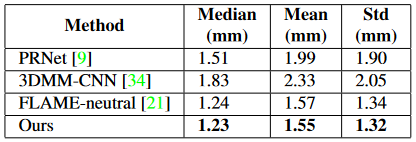
表1:Feng等人[10]基准的统计信息

NoW面部挑战:对于这个挑战,我们像[10]一样使用了裁剪的扫描来评估不同方法。我们首先对所有比较方法的预测网格执行刚性对齐。然后,我们计算上述预测网格与扫描之间的扫描到网格距离[10]。图5(右)显示了不同方法的累积误差曲线;再次,RingNet优于其他方法。我们在表2中提供了均值、中值和标准差误差。
表2:NoW数据集面部挑战的统计信息。
定性结果:这里我们展示了从单个CelebA [22]和MultiPIE数据集 [14]人脸图像估计3D面/头网格的定性结果。图1展示了RingNet的一些结果,说明了它对表情、性别、头部姿势、头发、遮挡等的鲁棒性。在图6和图7中,我们展示了我们的方法在不同条件下,如照明、姿势和遮挡下的鲁棒性。在Sup. Mat.中提供了定性比较。
图6:RingNet对不同照明条件的稳健性。图像来自MultiPIE数据集[14]。

图7:RingNet对遮挡、姿势变化和照明变化的稳健性。图像来自NoW数据集。

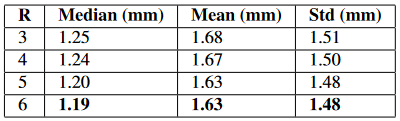
剔除研究:在这里,我们通过在表3中比较不同 R R R值的选择,为在RingNet中使用环形架构提供了一些动机。我们在包含10个受试者的验证集上评估这些值(其中六个来自[8],四个来自[21])。对于每个受试者,我们选择一个中性扫描和两到四个扫描仪图像,为图像重建3D网格,并在刚性对齐后测量扫描到网格的重建误差。使用具有更多元素的环形结构与仅使用单个三元组损失相比,误差减小,但它也增加了训练时间。为了在时间和误差之间取得平衡,我们在实验中选择了 R = 6 R = 6 R=6。
表3:不同环元素数量R的影响。我们在消融研究中描述的验证集上进行评估。
6. 结论
我们解决了从单一2D图像学习估计3D、关节化和可变形形状的具有挑战性的问题,而没有配对的3D训练数据。我们将RingNet模型应用于人脸,但该公式是通用的。关键思想是利用一系列成对损失,鼓励解决方案在相同人物的图像中共享相同的形状,在它们不同的情况下具有不同的形状。我们利用FLAME面部模型将面部姿势和表情分解为形状,以便RingNet可以在形状固定的同时允许其他参数变化。我们的方法需要一个数据集,其中一些人会多次出现,以及2D面部特征,可以通过现有方法估计。我们仅提供标准2D面部特征与3D FLAME模型的顶点之间的关系。与以前的方法不同,我们不优化3DMM到2D特征,也不使用合成数据。竞争方法通常利用使用面部反照率、反射和阴影的近似生成模型的光度损失。RingNet不需要这样做来学习图像像素与3D形状之间的关系。此外,我们的公式捕捉了整个头部及其姿势。最后,我们创建了一个具有准确的地面真实3D头部形状和在各种条件下拍摄的高质量图像的新的公共数据集。令人惊讶的是,RingNet优于使用3D监督的方法。这为未来的研究开辟了许多方向,例如扩展RingNet与[24]。在这里,我们侧重于没有3D监督的情况,但我们可以放宽这一点,并在可用时使用监督。我们预期少量的监督会提高准确性,而野外图像的大数据集将提供对照明、遮挡等的稳健性。我们的2D特征检测器不包括耳朵,尽管耳朵是非常独特的特征。添加2D耳朵检测将进一步改善3D头部姿势和形状。虽然我们的模型停在颈部,但我们计划将模型扩展到全身[23]。有趣的是看到RingNet是否可以扩展到仅使用2D关节从图像中重建3D身体姿势和形状。这可能超越当前的方法,如HMR [17],以学习关于身体形状的信息。虽然RingNet学习了到现有面部3D模型的映射,但我们可以放宽这一点,并且还可以在低维形状空间上进行优化,从示例中学习更详细的形状模型。为此,整合阴影线索[32, 28]将有助于约束问题。
致谢:我们感谢T. Alexiadis建立NoW数据集,J. Tesch提供渲染结果,D. Lleshaj提供注释,A. Osman提供补充视频,以及S. Tang进行有益的讨论。
披露:Michael J. Black收到了Intel、Nvidia、Adobe、Facebook和Amazon的研究礼金。他是Amazon的兼职员工,并在Amazon和Meshcapade GmbH拥有财务利益。他的研究仅在MPI进行。
References
(……)
附录
在接下来的部分,我们展示了NoW数据集的各个挑战(中性,图8;表情,图9;遮挡,图10;自拍,图11)的累积误差图。图5的右侧显示了跨所有挑战的累积误差。
图8:中性挑战的累积误差曲线。
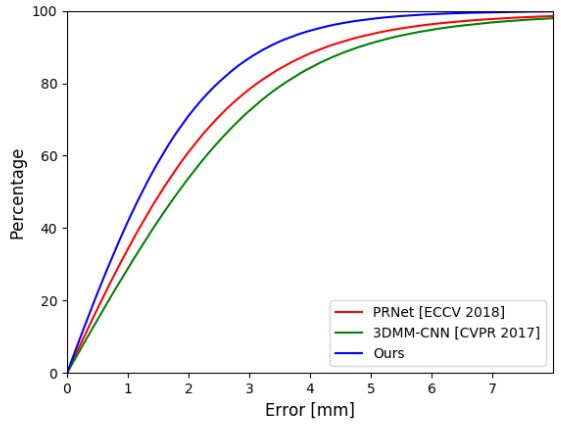
图9:表情挑战的累积误差曲线。
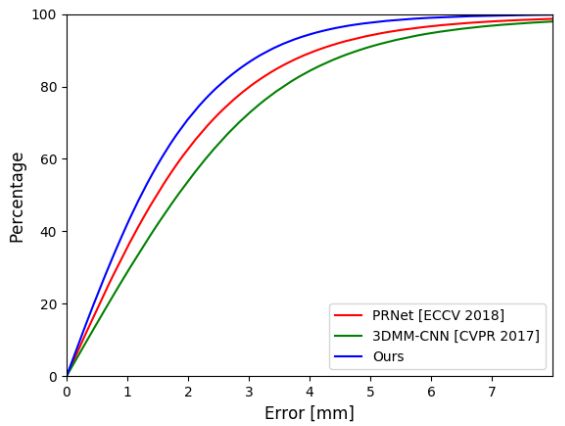
图10:遮挡挑战的累积误差曲线。

图11:自拍挑战的累积误差曲线。