【python】数据加载与存储
文章目录
- 读取文本格式的数据
-
- 逐块读取文本文件
- 将数据写出到文本格式
读取文本格式的数据
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数:
【read_csv和read_table最为重要】
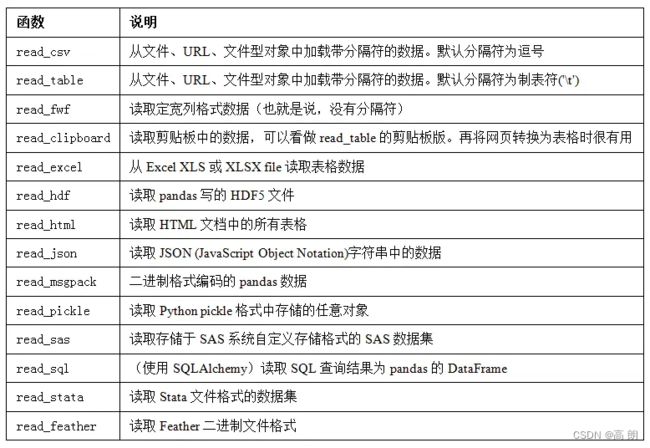
这些函数在将文本数据转换为DataFrame时所用到的一些技术。这些函数的选项可以划分为以下几个大类:
- 索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名。
- 类型推断和数据转换:包括用户定义值的转换、和自定义的缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号隔开的数值数据)。
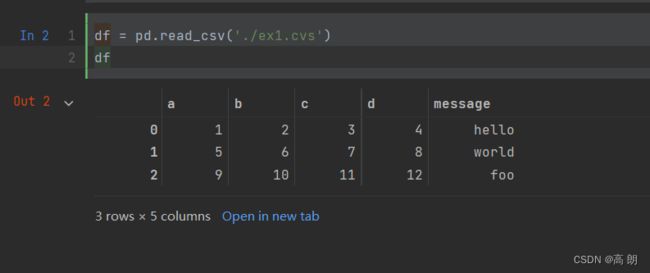
- 读取带标题行的
csv文件(标题行会默认成为DataFrame的列索引)
ex1.csv
a,b,c,d,message
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
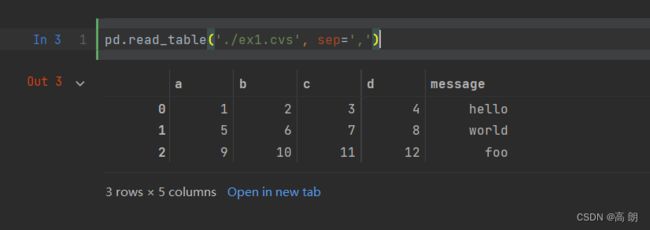
read_table也能读,但是它默认分割数据是按\t,修改一下即可:
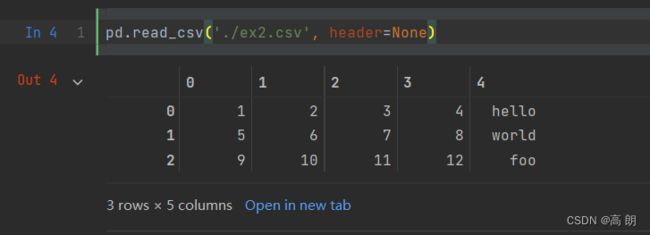
- 读取没有标题行的
csv文件(header=None,生成默认的整数索引)
ex2.csv
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
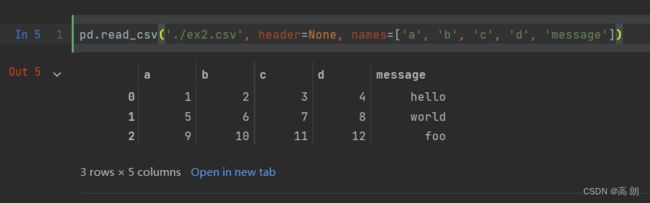
 可以自己定义列名:【
可以自己定义列名:【names=[]】
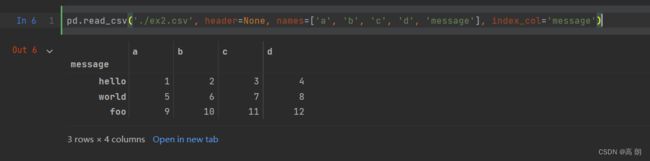
 可以让某一列成为行索引:【
可以让某一列成为行索引:【index_col='某一列索引名'】
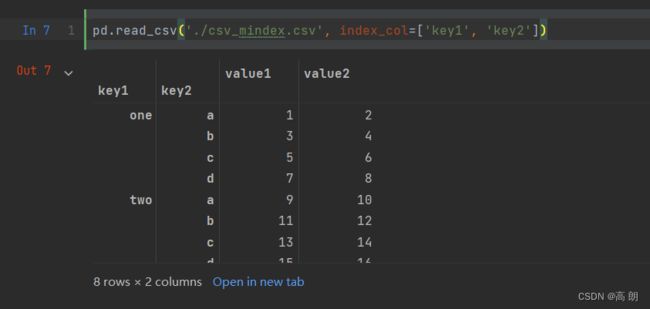
- 将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可:【
index_col=['某一列索引名','列索引名']】
csv_mindex.csv
key1,key2,value1,value2
one,a,1,2
one,b,3,4
one,c,5,6
one,d,7,8
two,a,9,10
two,b,11,12
two,c,13,14
two,d,15,16
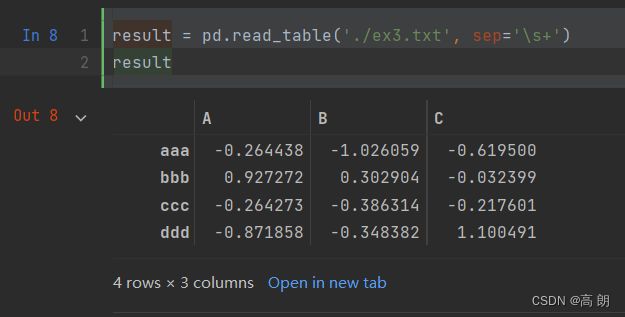
- 有些表格可能不是用固定的分隔符去分隔字段的(比如空白符或其它模式)【可以传递一个正则表达式作为read_table的分隔符】
ex3.txt【这里的字段是被数量不同的空白字符间隔开的】
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
这里是空格数不一,传入 sep='\s+'
 这里,由于列名比数据行的数量少,所以read_table推断第一列应该是DataFrame的索引。
这里,由于列名比数据行的数量少,所以read_table推断第一列应该是DataFrame的索引。
- 这些解析器函数还有许多参数可以帮助你处理各种各样的异形文件格式:


常用:
skip_footer=[] 忽略某些没用的行
# hey!
a,b,c,d,message
# just wanted to make things more difficult for you
# who reads CSV files with computers, anyway?
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
上面忽略1, 3, 4行
pd.read_csv('XX文件', skiprows=[0, 2, 3])
逐块读取文本文件
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部分或逐块对文件进行迭代。
- 设置最多显示多少行:
pd.options.display.max_rows = 10
- 只想读取几行(避免读取整个文件)【
nrows】
pd.read_csv('XX文件', nrows=5)
- 要逐块读取文件,可以指定chunksize(行数):
chunker = pd.read_csv('XX文件', chunksize=1000)
将数据写出到文本格式
利用DataFrame的to_csv方法,我们可以将数据写到一个以逗号分隔的文件中:
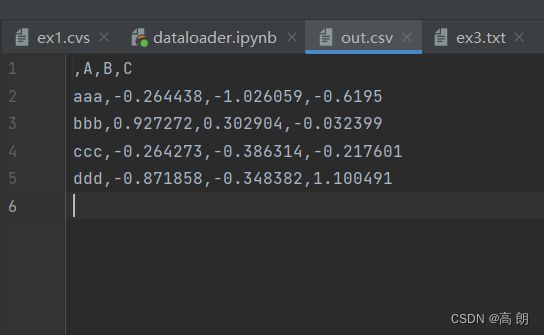 可以使用其他分隔符,指定
可以使用其他分隔符,指定sep= 即可
data.to_csv('XX文件', sep='|')
缺失值在输出结果中会被表示为空字符串。可以将其表示为别的标记值:data.to_csv('XX文件', na_rep='NULL') 用NULL填充空格。
没有设置其他选项,则会写出行和列的标签。如果不需要直接设置False
data.to_csv('XX文件', index=False, header=False)
只写出一部分的列,并按指定的顺序排列:
data.to_csv('XX文件', index=False, columns=['a', 'b', 'c'])