python取出表格_表哥表姐不要愁!5分钟学会用Python从PDF提取表格table
"600300,维维股份,000620,新华联,600090,同济堂,000157,中联重科",2019年上半年财报密集发布!
遇到财报发布的季节了,表哥表姐发愁啊,为什么都是PDF的,还有这么多,周末的安排又泡汤呢?

很多时候我们需要用到PDF文件中的Excel表格,但是PDF文件有不可编辑性,所以想提取PDF文件中的表格还是需要一番功夫的。这是加班都搞不定的!
不要愁,Python大大又来帮助表哥表姐了。不仅教表哥表姐如何提取表格数据,而且还是自动档,一次编写,批量文件几分钟就搞定。
以下将介绍几种使用Python从PDF中抓取表格的方法。友情提示:仅适用于非扫描图像的PDF。
Tabula-PY

是一个非常好的软件包,它允许您同时扫描PDF,以及将PDF直接转换为CSV文件。
安装后,tabula-py很容易使用。安装后,tabula-py很容易使用。下面我们使用它从讨论Iris数据集的分类的论文中提取所有表格)。
import tabula file = "seminar8.pdf" tables = tabula.read_pdf(file, pages = "all", multiple_tables = True)
存储到表中的结果是一个数据框列表,它对应于PDF文件中找到的所有表。要搜索文件中的所有表,您必须指定参数page ="all"和multiple_tables = True。
还可以使用tabula-py将PDF文件直接转换为CSV。下面的第一行将找到PDF中的第一个表并将其输出为CSV。如果我们添加参数all = True,我们可以将所有PDF表格写入CSV。
# output just the first table in the PDF to a CSVtabula.convert_into(file, "iris_first_table.csv") # output all the tables in the PDF to a CSVtabula.convert_into(file, "iris_all.csv", all = True)
tabula-py还可以仅用一行代码读取目录中的所有PDF,并将每个表中的表提取到CSV文件中。
tabula.convert_into_by_batch("/path/to/files", output_format = "csv", pages = "all")
我们可以执行相同的操作,将表格提取到JSON,如下所示。
tabula.convert_into_by_batch("/path/to/files", output_format = "json", pages = "all")
Camelot
是从PDF中抓取表格的另一种解决方案。
Camelot确实有一些额外的依赖项,包括GhostScript安装完成后,我们可以像使用tabula-py一样使用Camelot来抓取PDF表格。
file = "seminar8.pdf" tables = camelot.read_pdf(file, pages = "1-end")
这将返回TableList对象。要访问index找到的任何表,您可以这样做:
# get the 0th-indexed-table tabletables[0].df# get the 3rd-indexed-tabletables[3].df
Camelot的一个很酷的功能是,您还可以获得每个表的"解析报告",其中包含精确度指标,找到表格的页面以及表格中存在的空白百分比。
tables[0].parsing_reporttables[3].parsing_report
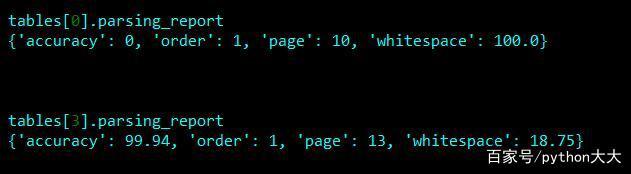
从这里可以看到第0个索引的已识别表基本上是空白。如果查看原始PDF,可以看到该页面未包含表格,因此忽略此空数据框是安全的。
与tabula-py一样,您可以将所有表导出到文件中。 Camelot支持(撰写本文时)CSV,JSON,HTML和SQLite。如果选择CSV,默认情况下,Camelot将为每个表创建单独的CSV文件。您可以通过添加参数compress = True来创建这些CSV的zip文件。选择导出到Excel将创建一个包含每个表的单个工作表的工作簿。
# export all tables at once to CSV filestables.export("camelot_tables.csv", f = "csv")# export all tables at once to CSV files in a single ziptables.export("camelot_tables.csv", f = "csv", compress = True)# export each table to a separate worksheet in an Excel filetables.export("camelot_tables.xlsx", f = "excel")
如果只想导出一个表,就可以像在pandas中那样导出,因为每个表都可以称为数据框对象。
tables[3].to_csv("camelot_third_table.csv")tables[3].to_excel("camelot_third_table.xlsx")
Excalibur
如果您正在寻找用于提取PDF表格的Web应用,您可以查看构建在Camelot之上的Excalibur。

您可以从命令行开始使用Excalibur。打开命令行后,只需键入以下内容:
excalibur initdb
上面的命令将初始化应用程序所需的元数据库。接下来,运行以下命令以通过Flask启动Web服务器:
excalibur webserver
然后您打开Web浏览器,输入127.0.0.1:5000,可以看到如下界面。
点Upload PDF,上传选择的PDF文件后,Excalibur将完成其余所有的工作。
表哥表姐,不用发愁了吧!
有任何意见或建议欢迎大家点赞交流。