设计基础决定上层建筑之go类型
Go语言类型,为什么要有类型?它有多少种呢?为什么会是这么呢?
文章目录
- Go语言类型,为什么要有类型?它有多少种呢?为什么会是这么呢?
-
- 第一,类型的诞生是要解决什么问题
- 第二,多少种呢?
- 第三、为什么会是这些类型呢?
-
- 1. string
- 2.map
- 3. slice
- 4. interface
- 5. embedded
第一,类型的诞生是要解决什么问题
把内存当作数组,具体位置上由0和1组成,地址就是索引,就是位置的坐标;
如果仅仅知道第一个地址,只能知道从哪个位置开始读取数据,但是不知道读多少位后停止,也不知道该怎么转换这些0101
类型这个词其实来自于物理化学中已有的总结或现象描述,是人类对自然管理的结晶
第二,多少种呢?
- 百度/google,让有心人告诉你
- 一手消息的爱好者来自官网
- 原来还可以这样,Junedayday告诉我们
func main() {
for i:= reflect.Invalid; i <= reflect.UnsafePointer; i++{
fmt.Printf("%d:%s\n",i,i.String())
}
}
// 没错 0 ~ 26 ,内部就是用数字和类型的对应关系构建的,基架
0:invalid 1:bool 2:int 3:int8
4:int16 5:int32 6:int64 7:uint
8:uint8 9:uint16 10:uint32 11:uint64
12:uintptr 13:float32 14:float64 15:complex64
16:complex128 17:array 18:chan 19:func
20:interface 21:map 22:ptr 23:slice
24:string 25:struct 26:unsafe.Pointer
- 同时告诉了我们这些类型都占用多少字节,内存对齐等信息
64位机器打出的结果:内存分配时以8字节为分配单位
Type:bool, Size:1, Align:1
Type:int, Size:8, Align:8
Type:int8, Size:1, Align:1
Type:int16, Size:2, Align:2
Type:int32, Size:4, Align:4
Type:int64, Size:8, Align:8
Type:uint, Size:8, Align:8
Type:uint8, Size:1, Align:1
Type:uint16, Size:2, Align:2
Type:uint32, Size:4, Align:4
Type:uint64, Size:8, Align:8
Type:uintptr, Size:8, Align:8
Type:float32, Size:4, Align:4
Type:float64, Size:8, Align:8
Type:complex64, Size:8, Align:4
Type:complex128, Size:16, Align:8
Type:array, Size:24, Align:8
Type:chan, Size:8, Align:8
Type:func, Size:8, Align:8
Type:map, Size:8, Align:8
Type:ptr, Size:8, Align:8
Type:slice, Size:24, Align:8
Type:string, Size:16, Align:8
Type:struct, Size:0, Align:1
Type:unsafe.Pointer, Size:8, Align:8
- 为什么要内存对齐规则呢?
其实很简单,人类的发明 创造一般都是为了方便、高效、减少内存浪费、提高性能等其中一二,想想go语言诞生的初衷
这里需要回去翻翻计算机组成原理了
1、
地址总线每次操作的字节数就是所谓的机器字长。如果内存就像我们逻辑上认为的那样,一个挨一个形成这样一个大矩阵,我们可以访问任意地址,并把它输出到总线
2、但是,实际上为了实现更高的访问效率。看下图,内存的物理设计:这不像我们逻辑上认为的那样连续的存在,但它们共用同一个地址,各自选择同一个位置的一个字节,再组合起来作为我们逻辑上认为的连续8个字节,通过这样的并行操作,提高内存访问效率。但是,通过这样的设计,地址只能是8的倍数。有些地址不能在一次操作中被同一个地址选中,所以这样的地址是不能用的。之所以CPU能支持访问任意地址,背后做了逻辑处理,取两次组合而成
3、但是,这必然会影响性能,所以,为保证程序顺利高效的运行,编译器会把各种类型的数据安排到合适的地址,并占用合适的长度,这就是内存对齐 ;每种类型的对齐值就是它的对齐边界
要求:数据存储地址以及占用的字节数都要是它对齐边界的倍数
过程:CPU需要通过地址总线把地址传输给内存,内存准备好数据输出到地址总线交给CPU;
如果地址总线由8根,那么这个地址就有8位,可以标识256个地址;
因为标识不了更大的地址,所以就用不了更大的内存,那么8根总线的内存最大是256byte;
要使用更大的内存,必须有更宽的地址总线;
32根总线 ~ 4G ~ 每次可以操作4字节 ~ 所谓的机器字长
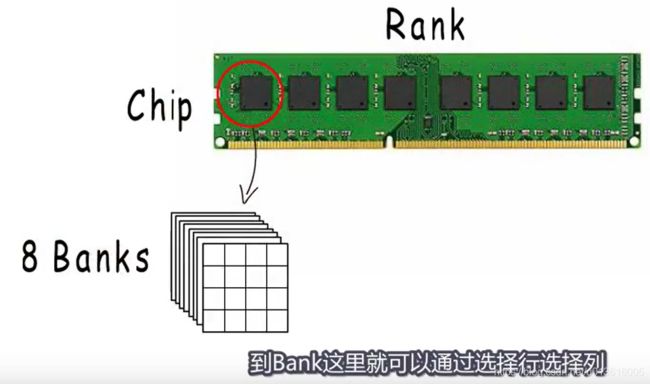
不同BANK上的元素共享同一个地址,那么就行程逻辑上连续的8个字节
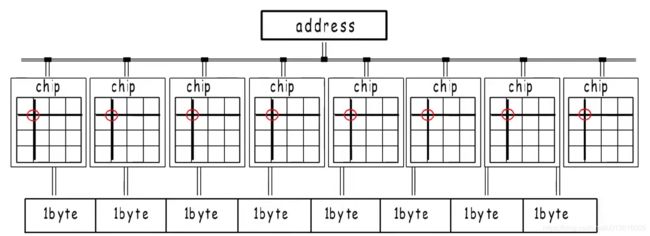
为了保证程序顺利高效的运行
编译器会把各种类型的数据安排到合适的地址 并占用合适的长度,这就是内存对齐
要求:每种类型的对齐值就是它的对齐边界
1、数据存储地址是对齐边界的倍数
2、占用的字节数是对齐边界的倍数
注:只有每个结构体的大小是对齐的整数倍,才能保证数组里每一个都是内存对齐的
怎么确定每种类型的对齐边界呢?这个问题的截图出自幼麟实验室的作品,很生动
- xxx类型的值是一个地址,或者就是常说的引用类型,其余是数值类型
slince 、map、 chan、 func、 ptr
- 各个类型是否可对比
slince map func 不可比较,只能与nil比较
Type:bool, Comparable:true
Type:int, Comparable:true
Type:int8, Comparable:true
Type:int16, Comparable:true
Type:int32, Comparable:true
Type:int64, Comparable:true
Type:uint, Comparable:true
Type:uint8, Comparable:true
Type:uint16, Comparable:true
Type:uint32, Comparable:true
Type:uint64, Comparable:true
Type:uintptr, Comparable:true
Type:float32, Comparable:true
Type:float64, Comparable:true
Type:complex64, Comparable:true
Type:complex128, Comparable:true
Type:array, Comparable:true
Type:chan, Comparable:true
`Type:func, Comparable:false`
`Type:map, Comparable:false`
Type:ptr, Comparable:true
`Type:slice, Comparable:false`
Type:string, Comparable:true
Type:struct, Comparable:true
Type:unsafe.Pointer, Comparable:true
如果'数组'中的元素类型是可比的,则数组也是可比较的;
如果'数组'中对应的元素都相等,那么两个数组是相等的;
数组不能与nil比较
a1 := [3]int{1, 2, 3}
a2 := [3]int{1, 2, 3}
a3 := [3]int{2, 1, 3}
//元素顺序必须一样
//输出:true false
fmt.Printf("%v %v\n", a1 == a2, a2 == a3)
//invalid operation: a3 == nil (mismatched types [3]int and nil)
fmt.Printf("%v\n", a3 == nil)
两个'指针'指向同一个变量,则这两个指针相等,或者两个指针同为nil,它们也相等。指针值可以与nil比较
var num1, num2 int
num1 = 8
num2 = 8
pt1 := &num1
pt2 := &num1
pt3 := &num2
//定义一个空指针
var pt4 *int
//只有指向同一个变量,两个指针才相等
fmt.Printf("%v %v\n", pt1 == pt2, pt1 == pt3)
//输出:true false
//指针可以与nil直接比较
fmt.Printf("%v %v\n", pt4 == nil, pt1 == nil)//true false
//输出:true false
`为什么引用类型chan可以直接对比呢???`
如果两个'通道'是由同一个make创建的,或者两个通道值都为nil,那么它们是相等的
ch1 := make(chan int)
ch2 := make(chan int)
var ch3 chan int
ch3 = ch1
var ch4 chan int
var ch5 chan int
var ch6 chan string
//同一个make创建的通道才相等
fmt.Printf("%v %v\n", ch1 == ch2, ch3 == ch1)
//输出:false true
//通道值可与nil比较
fmt.Printf("%v %v\n", ch4 == ch5, ch5 == ch1)
//输出:true true
`两个不同类型的通道,即使都是空值,也不能比较`
//invalid operation: ch5 == ch6 (mismatched types chan int and chan string)
fmt.Printf("%v\n", ch5 == ch6)
'接口值'是一个两个字长度的数据结构,已存储的值的类型信息('动态类型')+ 一个指向所存储值('动态值')的指针
如果两个接口值的动态值和动态类型都相等,或者两个接口值都为nil,那么它们是相等的。接口值可以与nil进行比较
type Speaker interface {
Speak()
}
type Person struct {
name string
}
func (p Person) Speak() {
fmt.Println(p.name)
}
type Student struct {
name string
}
func (s Student) Speak() {
fmt.Println(s.name)
}
func main() {
p1 := Person{"ball"}
p2 := Person{"ball"}
p3 := Person{"luna"}
s1 := Student{"ball"}
fmt.Printf("%v %v %v %v\n",
Speaker(p1) == p2,
Speaker(p1) == Speaker(p3),
Speaker(p1) == Speaker(s1),
Speaker(s1) == nil,
)
// true false false false
}
如果struct中所有的字段都是可比较的,那么两个struct是可比较的
如果struct对应的非空白字段相等,则它们相等。struct不能与nil比较
type person struct {
name string
age int
}
p1 := person{
name: "luna",
}
p2 := person{"ele", 0}
p3 := person{"luna", 0}
fmt.Printf("%v %v\n", p1 == p2, p1 == p3)
//输出:false true
var p4 person
var p5 person
fmt.Printf("%v\n", p4 == p5)
//输出:true
第三、为什么会是这些类型呢?
前面说了,类型是人类生活研究发明的结晶,是类, 类包含形形色色的例子。。。
这些类型的设计能够满足人类所有需求:
1、常用内置类型,因为太常用了 设计者们把他们设计好 方便大家,以免大家瞎搞
2、把业务类型的设计交给用户的方式,可能你们的脑洞比较大 设计师把权力交给你
1. string
- 字符怎么存?什么是字符集
8个比特组成一个字节
一个字节 = 0000 0000 = 0 ~ 255
两个字节 = 0000 0000 0000 0000 = 0 ~ 65535
更多的字节可以表示更大数值范围,整数都是这么存的
字符可以通过数值对应中转
字符集= 符号+编号,促进了字符与二进制之间的转换
ASCII GB2312 BIG5 …Unicode
- 字符集有了,接下来又有新的问题了,编码 解码 ~ 怎么划分字符边界?
定长编码 = 内存浪费
边长编码 = 不同范围的编码用编码模板

- 字符串类型的变量是什么结构? 怎么开始+怎么结尾问题
C用开始地址+\0标识字符串类型变量的结尾
go用开始地址+字节长度的方式标识结尾
go语言的编译器认为字符串是不允许修改的,所以会把字符串内容分配到只读内存段,但,
可以强制转换为字节数组,脱离只读内存的限制,原理是在读写区域拷贝了一份,赋给新的变量
那么我们怎么利用unsafe包和slince的原理,让强制类型转换后依然指向原来只读区域的内存呢?
2.map
Junedayday对基础层面的总结,思考太常用的点在哪里?为什么这么设计?
map读取某个值时 - 返回结果可以为value,bool或者value。注意后者,在key不存在时,会返回value对应类型的默认值map的range方法需要注意 -key,value或者key。注意后者,可以和slice的使用结合起来map的底层相关的实现 - 串联 初始化、赋值、扩容、读取、删除 这五个常见实现的背后知识点,详细参考示例代码链接与源码
/*
源码文件:runtime/map.go
初始化:makemap
1. map中bucket的初始化 makeBucketArray
2. overflow 的定义为哈希冲突的值,用链表法解决
赋值:mapassign
1. 不支持并发操作 h.flags&hashWriting
2. key的alg算法包括两种,一个是equal,用于对比;另一个是hash,也就是哈希函数
3. 位操作 h.flags ^= hashWriting 与 h.flags &^= hashWriting
4. 根据hash找到bucket,遍历其链表下的8个bucket,对比hashtop值;如果key不在map中,判断是否需要扩容
扩容:hashGrow
1. 扩容时,会将原来的 buckets 搬运到 oldbuckets
读取:mapaccess
1. mapaccess1_fat 与 mapaccess2_fat 分别对应1个与2个返回值
2. hash 分为低位与高位两部分,先通过低位快速找到bucket,再通过高位进一步查找,对后对比具体的key
3. 访问到oldbuckets中的数据时,会迁移到buckets
删除:mapdelete
1. 引入了emptyOne与emptyRest,后者是为了加速查找
*/
map如何保证按key的某个顺序遍历? - 分两次遍历,第一次取出所有的key并排序;第二次按排序后的key去遍历(这时你可以思考封装map和slice到一个结构体中)?map的使用上,有什么要注意的? - 遍历时,尽量只修改或删除当前key,操作非当前的key会带来不可预知的结果- 从
map的设计上,我们可以学到 - Go语言对map底层的hmap做了很多层面的优化与封装,也屏蔽了很多实现的细节,适用于绝大多数的场景;而少部分有极高性能要求的场景,就需要深入到hmap中的相关细节。
- map的优点非常明显,需要认真探究一下其
设计思想 - 深入hmap看看
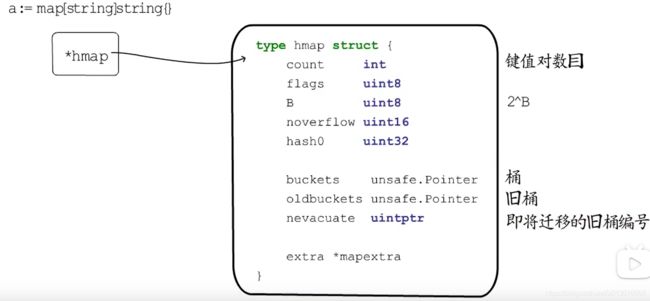
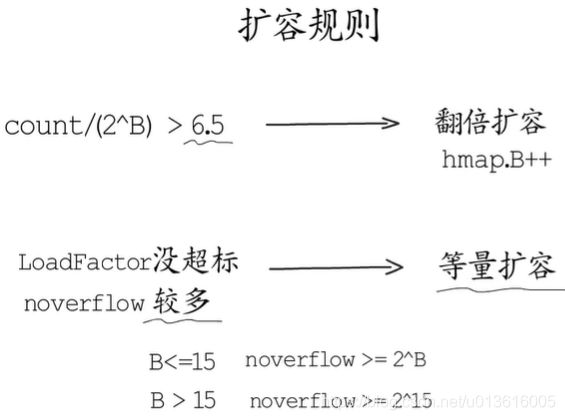
- 再深入理解的话,还是看看饶神的作品
3. slice
声明: 初始化 存哪里+存了多少个元素+可以存多少个元素
初始化的slince通过appen添加元素 通过位置下标修改元素,越界panic
new初始化的slince只提供了起始地址,不分配底层数组,通过append的方式添加元素,为slince开辟底层数组
可以把不同slince关联到同一个array上
- 熟悉
slice的底层数据结构 - 实际存储数据的array,当前长度len与容量cap slice的扩容机制- 不严格来说,当长度小于1024时,cap翻倍;大于1024时,增加1/4slice有很多特性与map一致 - 记住一点,代码中操作的slice和map只是上层的,实际存储数据的是array与hmap
/*
slice 的源码部分
slice基础结构slice:
包括保存数据的array、长度len与容量cap
初始化函数makeslice:
math.MulUintptr:根据元素大小和容量cap,计算所需的内存空间
mallocgc: 分配内存, 32K作为一个临界值,小的分配在P的cache中,大的分配在heap堆中
扩容growslice:
当长度小于1024时,cap翻倍;大于1024时,增加1/4。 但这个并不是绝对的,会根据元素的类型尽心过一定的优化
拷贝slicecopy:
核心函数为memmove,from=>to移动size大小的数据,size为 元素大小 * from和to中长度较小的个数
拷贝slicestringcopy:
基本与上面类似,字符串的拷贝
*/
- 扩容三步走,step 1
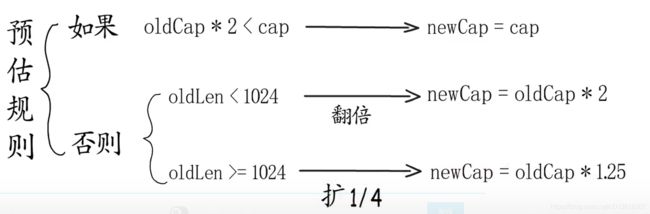
- 扩容三步走,step 2
需要多大内存 ?= 预估容量 x 元素类型大小
- 扩容三步走,step 3
需要了解go语言的内存管理机制

- eg:

4. interface
- 铺垫
接口 类型断言 内存管理 反射都依赖类型元数据
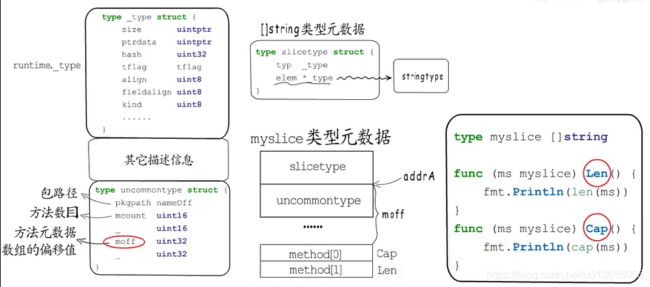
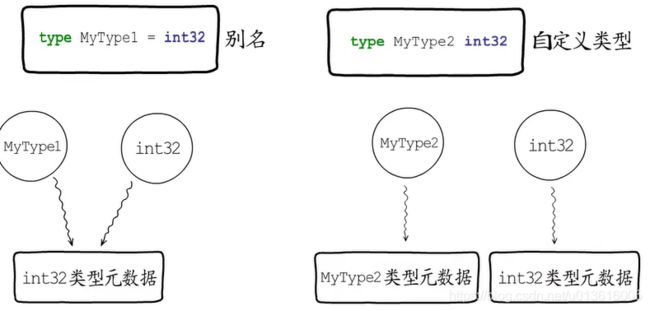
- eface

- iface

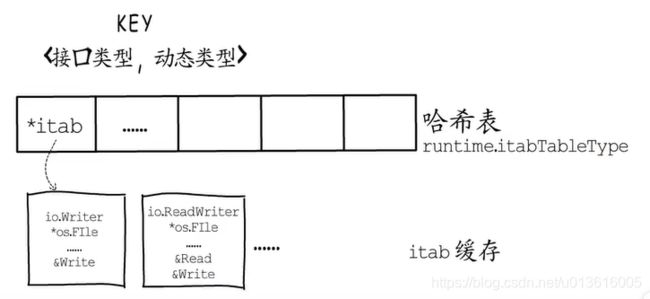
- go对itab的处理
itab结构体是可复用的
实际上Go语言会把用到的itab结构体缓存起来
并且以接口类型和动态类型的组合为key
以itab结构体指针为value构造一个哈希表,用于存储与查询itab缓存信息
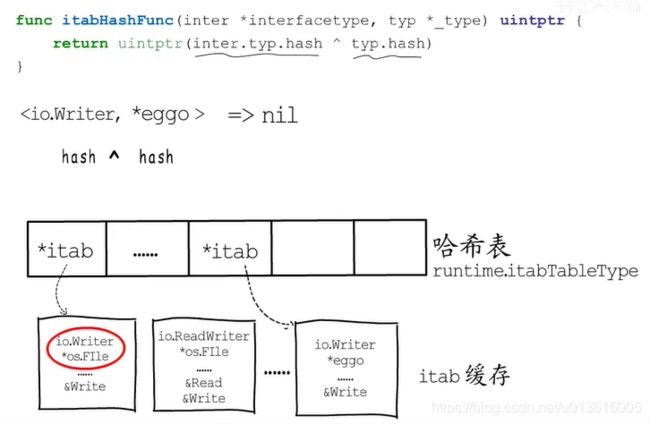
-
assert
-
summary
- interface的两种类型 -
数据结构的interface,侧重于类型;面向对象中接口定义的interface,侧重于方法的声明 - 了解interface的底层定义 -
eface和iface,都分为两个部分:类型与数据 iface底层对类型匹配进行了优化 -map+mutex组合
5. embedded
embedded的核心思想 - 面向对象中的组合思想,主要体现出了代码复用- 项目实战中,常见用到embedded的场景 - 结构体之间存在大量的复用的逻辑,抽象出一个
基类来作为embedded interface的设计原则 - 方法尽量少,通过组合来实现复杂的interface