【自用_Unity面试】
自用_Unity面试
- C#
-
- 1.简述值类型和引用类型的区别
- 2.ArrayList 和 List
- 3.简述GC相关(C# GC,Unity GC,Lua GC)
- 4.简述接口和抽象类的相同和不同
- 5.父类和子类构造函数的执行顺序
- 6.反射
- 7.string和stringBuider的区别,以及字符串池的概念
- 8.简述List的底层
- 9.简述Dictionary的底层
- 10.简述Unity协程底层
- Lua
-
- 1.数据结构和内存占用
- 2.实现面向对象
- 3.元方法
- 4.GC
- 4.Lua与C#的交互(理解不了现在只能硬背)
- 5.Lua的闭包
- 网络相关
-
- 1.帧同步、状态同步和状态帧同步
- 项目相关
-
- 1.UI框架
- 热更
C#
1.简述值类型和引用类型的区别
- 值类型存在栈中,引用类型数据存在堆中,栈里面存着对应堆的地址
- 值类型的数据在引用范围(作用域)结束的时候自动释放,引用类型在托管堆上的数据由C#自带的GC处理回收
- 值类型的数据存取快,引用类型数据存取慢
- 值类型的数据在编译过程中就分配好了内存,引用类型在运行过程中分配内存
- 引用类型的基类是System.Object,值类型的基类是System.ValueType,但是System.ValueType的基类也是System.Object。
2.ArrayList 和 List的区别
- ArrayList不带泛型,会把所有存入的数据当作object类型,从而造成数据类型的丢失,而List是泛型的,在创建的时候就要声明存储的数据类型,从而避免了数据类型的丢失。
- ArrayList应为会把所有的数据都变成object类型(引用类型),所以在使用的时候可能会导致装箱拆箱的过程,造成性能的损失(应为装箱操作首先要在“堆”中开辟一个新的内存空间,然后把栈上的数据内容复制到新开辟的内容中去)而List应为提前声明的数据的类型,所以一般不会造成拆箱或是装箱的操作。
3.简述GC相关(C# GC,Unity GC,Lua GC)
- GC垃圾回收机制,当堆上的数据,失去引用的时候,就会被GC自动回收。
4.简述接口和抽象类的相同和不同
==相同点==
1. 都不能直接的被实例化。
2. 都可以被继承。
3. 都可以用继承的方式在子类里面实现对应的抽象方法。
4. 都可以遵循里氏替换原则
==不同点==
1.接口完全不能被实例化,但是抽象类可以通过子类实现间接的实例化。
2.接口是完全抽象,抽象类可以是部分抽象,类里面可以写方法的具体实现。
3.抽象类只能被单继承,接口可以被多继承。
4.抽象类里面可以有成员变量,接口里面不能有成员变量。
5.抽象类有构造函数,接口没有。
5.父类和子类构造函数的执行顺序
- 当子类被new实例化的时候,父类也被间接实例化了,先执行父类的构造函数再执行子类的构造函数。
- 当子类构造函数后面没东西的时候,默认有一个:base()即默认先执行父类的无参构造函数。
class Father
{
public int fs;
public Father()
{
Console.WriteLine("执行父亲的无参构造函数");
}
}
class Son : Father
{
public int cs;
//下面这两个是等效的
public Son(int b)
{
Console.WriteLine("执行儿子的有参构造函数");
cs = b + 10;
}
public Son(int b):base()
{
Console.WriteLine("执行儿子的有参构造函数");
cs = b + 10;
}
}
6.反射
- 反射的作用
- 能够在程序运行是,动态的访问程序集(dll/exe 文件)Assembly,从而获取到其中的元数据,去访问获取其中的类、属性、方法等。并调用其中的内容。
- 使用反射的几个主要的类
- Assembly 访问程序集
- Type 访问程序集中的类、结构体
- ConstructorInfo 访问Type中的构造函数
- MethodInfo 访问Type中的方法
- FiledInfo 访问Type中的字段
- PropertyInfo 访问Type中的属性
- 反射的实现原理
- 基于.Net平台的程序,编写完后会在CLR中生成对应的IL中间语言和对应的元数据,可以通过Dll路径获取到对应的元数据从而获取到对应的IL,来获取并调用对应的方法与字段等。(所以非托管代码无法通过反射获取对应的信息)。
7.string和stringBuider的区别,以及字符串池的概念
- string是不可变字符串,stringBuider是可变字符串,string每次值的改变都会在堆内存中开辟一个新的内存去存放新的内容,如果频繁改变string的内容,就会很容易触发GC导致性能的损失。
- StringBuilder
- 存储
StringBuilder的底层存储是由数组实现的。默认数组容积为16。 - 扩容
StringBuilder的扩容机制是链表式的扩容,且为头插法。当容量超过现有容量时,会新建一个大小与原有数组一样大的数组,并加原StringBuilder中的m_ChunkPrevious指向新的数组。从而达到扩容的效果,总体容量变为原来的两倍。
m_ChunkPrevious StringBuilder中指向前一个扩容出的数组部分的指针。
- 字符串池是CLR提供的一种原理是内部开辟容器通过键值对的形式注册字符串对象,键是字符串对象的内容,值是字符串在托管堆上的引用。这样当新创建的时候,会去检查,如果不存在就在这个容器中开辟空间存放字符串。由下图可以看出字符串a和b指向的地址是相同的,所以可以发现他们所指的地方都是字符串池子中的同一个地方。

- 并不是所有的字符串都会被放入字符串暂存池中,只有以下三种情况会放入字符串暂存池
- 利用字面量值创建string对象
- 利用string.Intern()创建string对象
- 字面量值+字面量值拼接创建string对象
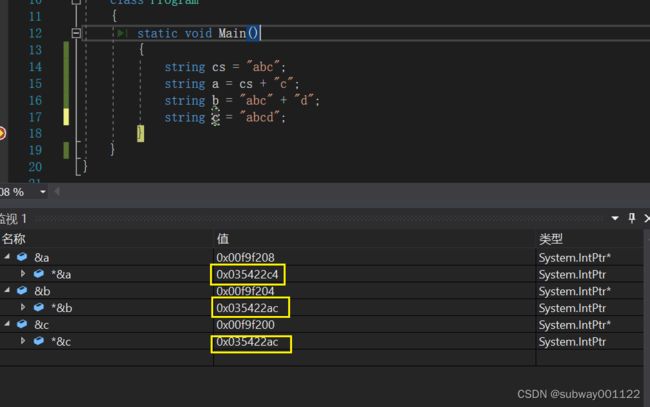
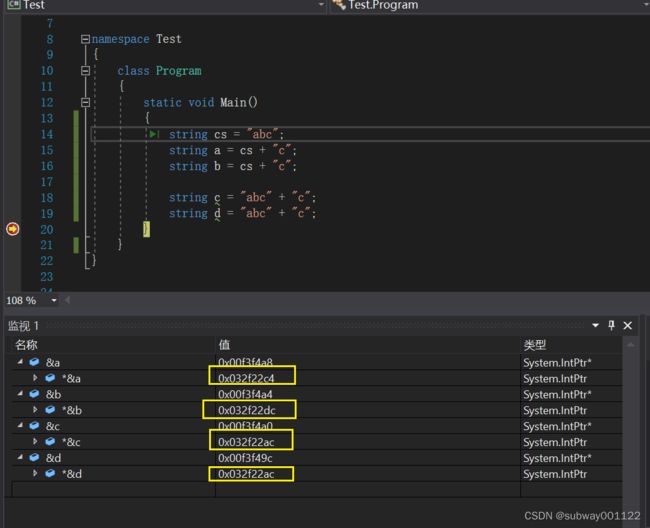
可以看到字符串a并不是由“字面量值+字面量值”拼接出来的而字符串b是“字面量值+字面量值”拼接出来的,所以字符串b和字符串c指向的是字符串暂存池中的变量abcd而字符串a则是指向堆中新开辟的一个内存空间。
下图更能说明,字符串暂存池的特殊性,并且暂存池中的字符串对象哪怕是失去了应用,也不会被C#的GC回收掉,所以在使用的时候需要小心。
8.简述List的底层
- List< T >底层为数组构成,初始化时候容量为零,添加第一个元素后扩容到4,并且之后每次扩容都是在原先的容量基础上进行翻倍。所以最好在一开始就能设定好List的容量,避免List发生多次扩容,触发GC从而导致性能下降。
9.简述Dictionary的底层
- 最小的数据存放Entry
首先Dictionary中存放最小数据的是一个结构体(Entry), 所有被Add加入字典的数据都会被以该形式存储到结构体中。
private struct Entry
{
public int hashCode; // 除符号位以外的31位hashCode值, 如果该Entry没有被使用,那么为-1
public int next; // 下一个元素的下标索引,如果没有下一个就为-1
public TKey key; // 存放元素的键
public TValue value; // 存放元素的值
}
- 桶(Buket)
Dictionary能够实习O(1)复杂度的查询就是应为,首先是通过key值进行hash算法得到对应的HashCode,从而寻找到HashCode所映射的Value,所以同时需要一个存放key值的HashCode的容器,并将Value值和HashCode容器进行关联。因为这样的一个问题,所以人们就将生成的HashCode以分段的形式来映射,把每一段称之为一个Bucket(桶),一般常见的Hash桶就是直接对结果取余,一般常见的Hash桶就是直接对结果取余。如分成8个桶进行存放bucketIndex = HashFunc(key1) % 8 - 冲突
然后我们可以发现,如果引用入桶的概念,那么在计算桶的下标以及将Vlaue值与桶进行映射关联的时候很容易发生冲突,即不同的Key值经过运算之后得到的Bucket index是相同的。即两个桶,一个Key值的HashCode是3,另一个的是5,那么取余过后得到的都会是1。此时如果直接映射,那么后一个的映射就会覆盖掉前一个的映射,此时就叫发生了冲突。 - Dictionary中冲突的解决方案
在Dictionary中冲突的解决方案是“拉链法”,即把发生冲突的元素形成一个单链表,我们可以从Entry中的元素就可以看出,其中的next就是保证了单链表的实现。下图就展示了发生冲突时,拉链法是怎么解决的。

- Dictionary主要的实现
在Dictionary源码的开头就定义了两个组成Dictionary最关键的数组,一个是用来存放Entry的数组entries,一个是整型数组buckets用来存放桶(Buket)的下标。
private int[] buckets; // Hash桶
private Entry[] entries; // Entry数组,存放元素
private int count; // 当前entries的index
private int version; // 当前版本,防止迭代过程中集合被更改
private int freeList; // 被删除Entry在entries中的下标index,这个位置是空闲的
private int freeCount; // 有多少个被删除的Entry,有多少个空闲的位置
private IEqualityComparer<TKey> comparer; // 比较器
private KeyCollection keys; // 存放Key的集合
private ValueCollection values; // 存放Value的集合
- Dictionary的默认容量
当我们发现Dictionary的关键部分为两个数组的时候,那么Dictionary在扩容的时候发生了什么呢?首先在数组最开始被创建出来的时候,如果使用的是无参构造 函数。那么最开始会被分配3的容量,即buckets和entries的初始容量都是3。
// Avoid awfully small sizes
int hashsize = (rawsize > InitialSize) ? HashHelpers.GetPrime((int)rawsize) : InitialSize;
buckets = new bucket[hashsize];
-----
private const Int32 InitialSize = 3;
- Dictionary的扩容(重点)
那么什么情况下Dictionary会发生扩容呢?一般有两种情况- 1 存放数据的Entry的数组entries存满了,此时就会发生扩容
- 2 邪门情况,如果大量数据发生冲突,全部变成链表串在一个桶下,此时查找的效率就会变低,因为要链表的长度越长,那么遍历的Entry也就越长。所以为了避免这种情况,设置了一个最大的碰撞次数,当超过这个次数的时候就会扩容(扩容之后所有的HashCode到桶的映射值会发生改变)。目前.Net Framwork 4.7中设置的碰撞次数阈值为100。
-
public const int HashCollisionThreshold = 100;
private void Resize()
{
Resize(HashHelpers.ExpandPrime(count), false);
}
private void Resize(int newSize, bool forceNewHashCodes)
{
Contract.Assert(newSize >= entries.Length);
int[] newBuckets = new int[newSize];
for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1;
Entry[] newEntries = new Entry[newSize];
-------
此处省略,详细代码见https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,1dca11c8648f5d65
-------
}
我们主要关注其中的newSize这个变量,就是这个变量决定了扩容之后两个关键数组的大小。我们发现是先将当前的容量大小传入ExpandPrime这个函数。
public static int ExpandPrime(int oldSize)
{
int newSize = 2 * oldSize;
// Allow the hashtables to grow to maximum possible size (~2G elements) before encoutering capacity overflow.
// Note that this check works even when _items.Length overflowed thanks to the (uint) cast
if ((uint)newSize > MaxPrimeArrayLength && MaxPrimeArrayLength > oldSize)
{
Contract.Assert( MaxPrimeArrayLength == GetPrime(MaxPrimeArrayLength), "Invalid MaxPrimeArrayLength");
return MaxPrimeArrayLength;
}
return GetPrime(newSize);
}
}
而这个函数显示将老的容量翻倍赋给新的容量,那么Dictionary的扩容是不是就在原先的基础上翻倍的呢,其实不然,我们继续看可以发现返回值是GetPrime(newSize),继续进这个函数去看。
public static int GetPrime(int min)
{
if (min < 0)
throw new ArgumentException(Environment.GetResourceString("Arg_HTCapacityOverflow"));
Contract.EndContractBlock();
for (int i = 0; i < primes.Length; i++)
{
int prime = primes[i];
if (prime >= min) return prime;
}
//outside of our predefined table.
//compute the hard way.
for (int i = (min | 1); i < Int32.MaxValue;i+=2)
{
if (IsPrime(i) && ((i - 1) % Hashtable.HashPrime != 0))
return i;
}
return min;
}
我们发现这是一个取素数的函数,首先会从给定的Primes这个数组中取离原先容量翻倍后数值最接近的素数,如果超过了Primes数组给定的最大值,那么就会直接去寻找离翻倍数值最近的素数,并且改素数减一不是HashPrime(101)的倍数。
public static readonly int[] primes =
{
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369};
总结:Dictionary的本质为两个数组,解决冲突的方式是拉链法,初始化的容量是3,每次扩容先从Primes数组中获取,超过7199369后,扩容为原容量的两倍大相近的素数。
10.简述Unity协程底层
- Unity中的协程主要是由C#中的所以器构成。可以看到协程的返回值为IEnumerator(迭代器),而yield return这个语法糖,会在编译的时候自动生成一个IEnumerator。并且把每个yield return间隔的代码分成一个个代码块,代码块中的内容就是IEnumerator中MoveNext中执行的内容。同时yield return后面的返回值作为IEnumerator中的Current进行返回。
public IEnumerator CS
{
Console.WriteLine("协程启动1");
yield return null;
Console.WriteLine("协程启动2");
yield return break;
}
void Start()
{
StartCroutine(CS());
}
- 这里写一个非常神奇的代码就能确定,Unity的协程就是通过迭代器实现的。熟悉迭代器的同学可以发现,我就是在myClass这个类里面实现了GetEnumerator这个方法,这样我们就可以通过foreach来获取到myClass这个类里面的一些数据。但同时我们可以发现GetEnumerator()这个方法与协程的写法完全一致,我们可以SrartCoroutine来启动这个协程。那么我们就可以发现GetEnumerator()这个方法在执行迭代器和协程的过程中是都可实现的。
public class Szcs : MonoBehaviour
{
myClass myclass = new myClass();
private void Start()
{
StartCoroutine(myclass.GetEnumerator());
foreach (var item in myclass)
{
Debug.Log(item);
}
}
}
class myClass
{
public IEnumerator GetEnumerator()
{
Debug.Log("cs");
yield return new WaitForSeconds(1.0f);
Debug.Log("One Seconds later");
yield return 12;
}
}
- 那么我们就把目光放到StartCoroutine这个Unity提供的API上面来,当我们把一个协程通过这个API传入的时候,Unity内部会维护一个结构用来存储所有的协程,并标记好所有协程的当前状态。理论上就是通过yield return 讲函数分成一个一个的代码块,通过MoveNext去依次执行他们。这里提供一个简陋版本的协程实现的代码。
class CS
{
//一个返回值是IEnumerator的方法
//yield语法糖会自动构建IEnumerator
//协程1
public IEnumerator enumerableFuc1()
{
int i = 0;
Console.WriteLine("Enumerator1:" + i);
yield return i;
i++;
Console.WriteLine("Enumerator1:" + i);
yield return i;
i++;
Console.WriteLine("Enumerator1:" + i);
yield break;
}
//协程2
public IEnumerator enumerableFuc2()
{
int i = 100;
Console.WriteLine("Enumerator2:" + i);
yield return i;
i++;
Console.WriteLine("Enumerator2:" + i);
yield return i;
i++;
Console.WriteLine("Enumerator2:" + i);
yield return i;
Console.WriteLine("继续执行");
yield break;
}
}
class CoroutinesManager
{
public List<IEnumerator> coroutines = new List<IEnumerator>();
public void StartCoroutine(IEnumerator coroutine)
{
coroutines.Add(coroutine);
}
}
class Program
{
static void Main(string[] args)
{
int i = 0;
CoroutinesManager coroutinesManager = new CoroutinesManager();
CS cs = new CS();
//注册协程
//在开启协程的时候把协程注册到维护的表里面去
coroutinesManager.StartCoroutine(cs.enumerableFuc1());
coroutinesManager.StartCoroutine(cs.enumerableFuc2());
//模拟Unity生命周期循环
while (true)
{
Console.WriteLine("frame:" + i++);
//判断协程容器中是否还存在协程
if (coroutinesManager.coroutines.Count <= 0)
{
return;
}
List<IEnumerator> delete = new List<IEnumerator>();
foreach (var item in coroutinesManager.coroutines)
{
//如果item的MoveNext不为空
if (!item.MoveNext())
{
delete.Add(item);
}
}
foreach (var item in delete)
{
coroutinesManager.coroutines.Remove(item);
}
}
}
}
Lua
1.数据结构和内存占用
- 基础数据类型
lua中总共有8中基础类型- nil 表示无效值
- Boolean 布尔值 表示 是或否
- number 表示双精度类型的实浮点数
- string 字符串类型
- funciont 函数类型
- userdata 表示任意存储在变量中的C数据结构
- thread 线程
- tabel 表
- String类型
lua中的String又会细分为长字符串和短字符串,以40个字符长度作为分界线,大于40个字符长度的字符串为长字符串。短字符串LUA_TSHRSTR,由全局的stringtable进行管理,即相同的短字符串只会有一份实际数据的拷贝,所以再重复创建相同短字符串的时候并不会产生大量的内存消耗。
而长字符串则不同,相同的长字符串在内存中都是单独的一份数据拷贝,所以大量创建相同长字符串,会有比较大的内存消耗。
注意:在lua5.1的时候并没有长短字符串之分,所有的字符串都由全局的stringtable进行管理。 - Table类型
Table的底层是用array + hashtable的方式管理数据的。每条对外的数据都是通过key-value的方式来读写的。- Array
如果key是整型,并且key > 1 and key < max_array_size,就会直接获取array[key]的数据。 - HashTable
其他情况下,默认读取HashTabel。如果key值放生冲突的时候,会用链表来维护这些冲突的节点。
其中HashTable的扩容大小的增长为2的倍数,即触发扩容的时候会重新分配一块oldsize*2的内存。
注意所以为了避免应为频繁扩容导致的cpu消耗,可以在数量比较小的时候执行预填充扩容,即在table创建的时候就填入对应的key_value值。
- Array
2.实现面向对象
--基础父亲表
Father = {}
Father.state = "元表"
--实现父亲表的new方法
function Father:new()
--创建实体父亲表
local father = {}
--将父亲表设置为实体父亲表的元表
setmetatable(father,self)
--设置父亲表的__index保证父亲表中的变量能被实体父亲访问到
self.__index = self
--将设置好的实体父亲表返回
return father
end
--实现父亲表的说话方法
function Father:Speak()
print(self.state.."说话了")
end
--实现父亲表的继承方法
function Father:Inherit(sonName)
--通过大G表创造出子表实例
_G[sonName] = {}
local son = _G[sonName]
--将父亲表设置为子表的元表
setmetatable(son, self)
--实现base来复用父类方法
son.base = self
end
--实例化一个父亲表
father = Father:new()
father.state = "父亲"
father:Speak()
--设置Boy表继承于father表
Father:Inherit("Boy")
--设置Boy表的信息
Boy.state = "儿子"
--重写Boy表里面的Speak方法
function Boy:Speak()
--这种调用父类方法时会使用子类字段
self.base.Speak(self)
--这种调用父类方法时会使用父类字段(慎用)
self.base:Speak(self)
--子类自己的方法
print("我是儿子"..self.state.."说话了")
end
--实例化一个儿子表
boy = Boy:new()
boy:Speak()
father:Speak()
3.元方法
__index 索引查询
如果有表中不存在的字段内容,就会去表的元表的__index中去寻找
__newindex 索引更新
如果有表中不存在的字段内容设置,就会去表的原表中的__newindex中去新建并设置
rawset() 更新
这个方法会不触发任何元方法进行字段跟新
rawget() 查询
这个方法不触发任何元方法进行字段查询
__call
如果元表中定义了__call,那么就可以通过变量名来当做函数来调用
class = setmetatable({},{__call = function (self,index)
print(index)
end})
class(1) --打印1
__tostring
可以更改表的输出行为
__add = B, --加法
__sub = B, --减
__mul = B, --乘
__div = B, --除
__mod = B, --取模
__pow = B, --乘幂
__unm = B, --取反
__concat = B, --连接
__len = B, --长度
__eq = B, --相等
__lt = B, --小于
__le = B, --小于等于
4.GC
- luaGC的原理简述
lua的GC主要用了标记清扫算法(Mark-Sweep)
标记:在GC发生的时候从根节点(静态变量,调用栈中的变量以及指向堆内存中的指针)开始逐个把与之相关联的节点打上标记。
清扫:将没有被打上标记的节点一一删除。 - luaGC中的三种颜色
lua在GC过程中的对象一共有白(新白,旧白),灰,黑三种状态。所有对象的初始阶段都为(白色)。-
白色(新)
是当GC的标记阶段结束但是清扫阶段没开始的时候给新被建立的对象标记的状态。此时应为并没有发现此对象的引用关系,所以会被标记成白色,理应被清除掉,但很明显这是不合理的,所以会白色(新)状态,GC在Sweep阶段只会删除白色(旧)状态的对象,而在Sweep阶段结束后白色(新)就会转变成白色(旧)状态。 -
白色(旧的)
可回收状态 -
灰色
中间状态——当前对象在Mark阶段已被访问,但是该对象引用的其他对象还没有访问完。 -
黑色
不可回收状态——当前对象和该对象引用的所有对象都已经被标记。
3.GC流程
首先在lua的全局状态机(global_State)中存在着几个与GC流程息息相关的链表。这里只简单说明一下接下来要说到的链表。
分别是- allgc 所有可回收对象的链表 (初始阶段的白色)
- finobj 需要被回收的对象的链表
- tobefnz 最终需要被GC处理的对象链表
- fixedgc 不需要被回收的对象链表 (黑色对象)
- gray 存放灰色对象的链表 (灰色对象)
(简要说明–实际内容更复杂
可以看这篇文章本节内容也参考此文: lua垃圾回收机制)- 首先所有被创造出来的可回收的对象,一开始都会被放到allgc这个链表中。
- 在GC的sweep阶段,从数据根节点出发,将所有能够访问的对象放入gray这个链表中。
- 然后从gray链表中提取出一个对象把其放入fixedgc,并遍历其所引用的所有对象都放入fixedgc中。
- 最后遍历allgc、finobj、tobefnz中的对象,把里面的白色对象给释放掉。

-
4.Lua与C#的交互(理解不了现在只能硬背)
5.Lua的闭包
unity面试——Lua 闭包 这个大佬已经说的很详细了。
网络相关
1.帧同步、状态同步和状态帧同步
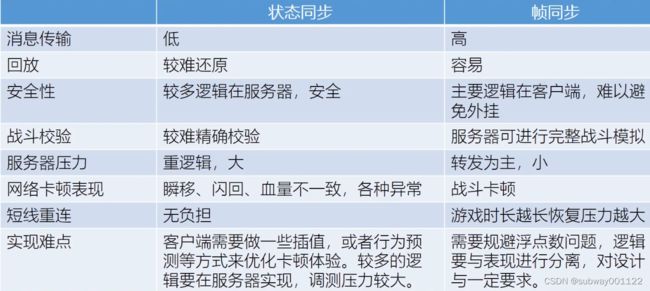
- 帧同步
服务端与客户端之间按照固定的逻辑帧率(30FPS 60FPS)发送数据,称之为帧同步。而为了实现帧同步的这一概念,所以需要引入定点数,来保证服务端与不同客户端之间保证帧率的一致。- 操作系统内部
操作系统内部总共就有两类数据- 定点数
小数点位置固定的数,通常为纯整数或者纯小数。 - 浮点数(存在一定限制性)
额外使用尾数和解码表示的一种小数点位置可变的数据。但是各种编译语言,编译器,CPU指令集在浮点运算舍入实现上各不相同。存在着差异。
- 定点数
- 定点数(应用级)
应为存在有一种帧同步服务器,只负责转发玩家的操作指令,而浮点数在不同客户端的差异性,可能会导致在不同的客户端游戏的展示的画面都不同,为了保证客户端的表现一致性,定点数应运而生。- 定点数(应用级)
使用确定精度的整形,长整型来实现浮点精度的一种数据结构,由于是应用级的实现,所以在任意编译语言,编译器,CPU指令集上的计算结果都一致。 - 状态同步
只有当状态数据发生变化的时候才进行同步。
如mmorpg游戏,为了增加同屏人数,会采用服务端运行全量逻辑+AOI(详情见AOI)同步优化,并且只同步玩家释放的技能指令,血量改变,蓝量改变等状态数据来优化带宽占用。 - 状态帧同步
按固定的逻辑帧搜集变化的状态数据并进行网络同步。
- 定点数(应用级)
- 操作系统内部
- 总结
- 特点
- 帧同步 :具有明确的逻辑帧的概念,并且按照逻辑帧来同步网络数据
- 状态同步:按照状态发生变化来同步网络数据
- 状态帧同步:按照逻辑帧对发生了变化的状态数据进行搜集并同步。
- 可能存在的误区
- 是否在客户端接受指令并进行模拟计算不能判定是否为帧同步,应为状态同步同样可以为了快速响应而在客户端进行模拟计算
- 是否使用定点数并不能半段是否为帧同步,因为状态同步一样可以为了及时响应和低概率回滚行为而在本地使用定点数跑逻辑。
- 是否在服务器跑全量逻辑并不能判断是否为状态同步,因为帧同步同样可以为了防止玩家作弊的情况下而在服务器跑逻辑。
- 特点
项目相关
1.UI框架
- UI框架的MVC-S
- C(Ctrl层)模块系统的管理层
- M(Model层)维护持久化数据
- V(View层)窗口组件子业务逻辑操作
- S(Service层)负责模块系统协议的接受与发送
- UI层级管理
- 手动参数
PlanceDistance 越大越先渲染(越先渲染就离屏幕距离越远)
Sorting layer 越小越先渲染
Order in Layer 越小越先渲染 - 运行时改变UI层级
transform.SetAsFirstSibling(); --最先渲染
transform.SetSiblingindex(N); --中间渲染 N=0 时,类似FirstSibling
transform.SetAsLastSibling(); --最后渲染
- 手动参数