零基础Linux_13(基础IO_文件)文件系统接口+文件描述符fd+dup2函数
目录
1. C语言的文件操作
1.1 C语言文件的写入
1.2 当前路径
1.3 文件操作模式
1.4 文件的读取和cat
2. 文件系统接口
2.1 系统调用与封装
2.2 open打开文件
2.2.1 flags标记位
2.2.2 open用法演示
2.3 close关闭文件和write写入文件和rede读取文件
2.3.1 O_TRUNC截断清空
2.3.2 O_APPEND追加写入
2.3.3 O_RDONLY读取
3. 文件描述符fd
3.1 open的返回值
3.2 文件描述符的底层理解
3.3 Linux下一切皆文件
3.4 fd的分配原则
4. 重定向
4.1 dup2函数
4.2 追加重定向和输入重定向
本篇完。
1. C语言的文件操作
我们曾经讲过:文件 = 文件内容 + 文件属性。
文件属性也是数据,这意味着,即便你创建一个空文件,也要占据磁盘空间,所以:
文件操作 = 文件内容的操作 + 文件属性的操作
要读写一个文件,我们首先要做的事就是打开文件,所谓的 "打开" 文件,究竟在做什么?
"打开文件不是目的,访问文件才是目的"
访问文件时,以前学C语言是通过 fread,fwrite,fgets... 这样的代码来完成对文件的操作的,
如果通过这些方式,那么 "打开" 文件就需要 将文件的属性或内容加载到内存中。
因为这是由冯诺依曼体系结构决定的,将来要执行 fread,fwrite 来对文件进行读写的。
既然如此,是不是所有的文件都会处于被打开的状态呢?并不是
那没有被打开的文件在哪里?在磁盘上
对于文件的理解,在宏观上我们可以区分成 内存文件 (打开的文件) 和 磁盘文件。
通常我们打开文件、访问文件和关闭文件,是谁在进行相关操作?
接口函数运行起来的时候,才会执行对应的代码,然后才是真正的对文件进行相关的操作。
实际上是 进程在对文件进行操作! 在系统角度理解是我们曾经写的代码变成了进程。进程执行调度对应的代码到了 fopen,write 这样的接口,然后才完成了对文件的操作。
当我执行 fopen 时,对应地就把文件打开了,所以文件操作和进程之间是撇不开关系。学习文件操作,实际上就是学习 "进程" 与 "打开文件" 的关系
1.1 C语言文件的写入
以前C语言简单学习的文件:(复习一下最好,不看也行)C语言进阶⑱(文件上篇)(动态通讯录写入文件)(文件指针+流的概念+八个输入输出函数)__GR的博客-CSDN博客
先简单回顾一下 C 语言的文件写入操作:
这里新创建linux_13目录,进入然后写Makefile和test.c:

在一个文件写入 20 行数据:
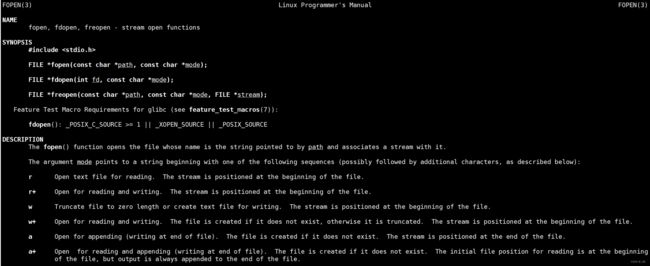


编译运行:
fopen第一个参数应该传入一个路径,如果直接传文件名,它会在当前路径帮你创建这个文件。
什么是当前路径?如果对当前路径的理解,仅仅停留于 "当前路径就是源代码所在的路径" 是远远不够的。
1.2 当前路径
前面提到:文件的本质实际上是进程与打开文件之间的关系。
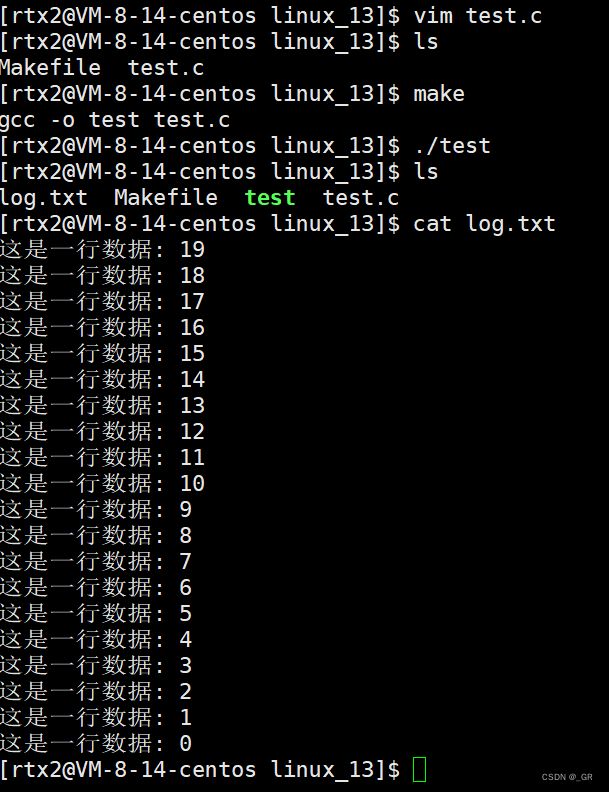
因此文件操作和进程有关系,修改一下的代码,获取进程pid,让它死循环,以便查看进程信息:

编译运行,然后在右边查看:
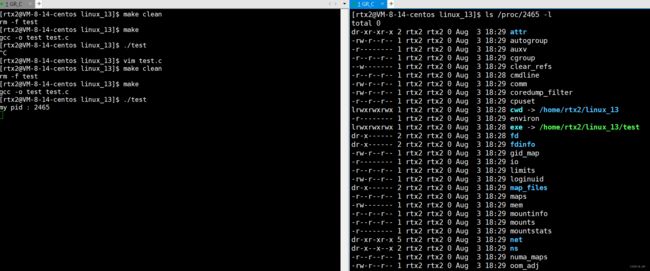

这里ewd就是这个进程的当前工作目录,exe是链接指向可执行程序
每个进程都有一个工作路径,所以我们前面实现的简单 shell 程序可以用 chdir 更改路径。
创建文件时,如果文件在当前目录下不存在,fopen 会默认在当前路径下自动创建文件。
默认创建在当前路径,和源代码、可执行程序在同一个路径下
所以,当前路径更准确的说法应该是:在当前进程所处的工作路径。
" 当前路径指的是在当前进程所处的工作路径 "
只不过默认情况下 (默认路径) ,一个进程的工作路径在它当前所处的路径而已,这是可以改的。所以我们在写文件操作代码时,不带路径默认是源代码所在的路径
1.3 文件操作模式
刚才 man fopen 里的:(fopen的第二个参数传入的是打开文件的模式)

r:只读模式,打开一个已存在的文本文件,允许读取文件。
r+:读写模式,打开一个已存在的文本文件,允许读写文件。
w:只写模式,打开一个文本文件并清除其内容,如果文件不存在,则创建一个新文件。
w+:读写模式,打开一个文本文件并清除其内容,如果文件不存在,则创建一个新文件。
a:追加模式,打开一个文本文件并将数据追加到文件末尾,如果文件不存在,则创建一个新文件。
a+:读写模式,打开一个文本文件并将数据追加到文件末尾,如果文件不存在,则创建一个新文件。
r(read)和 w(write)C语言文件里讲过一点,应该能懂,这里我们重点讲一下 a 和 a+
a 对应的是 appending 的首字母,意为 "追加" 。属于写入操作,不会覆盖源文件内容。

刚才fp文件已经被w写,然后死循环,覆盖掉了,现在写入点东西然后编译运行:

每次运行都会在 test.txt 里追加,我们多试几次看看:

a(append) 追加写入,可以不断地将文件中新增内容。(有没有像追加重定向)
a 不同于 w,当我们以 w 方式打开文件准备写入的时候,其实文件已经先被清空了。
1.4 文件的读取和cat
复习一下文本行输入函数 fgets,它可以从特定的文件流中,以行为单位读取特定的数据:



前面我们的log.txt已经有点内容了,编译运行:

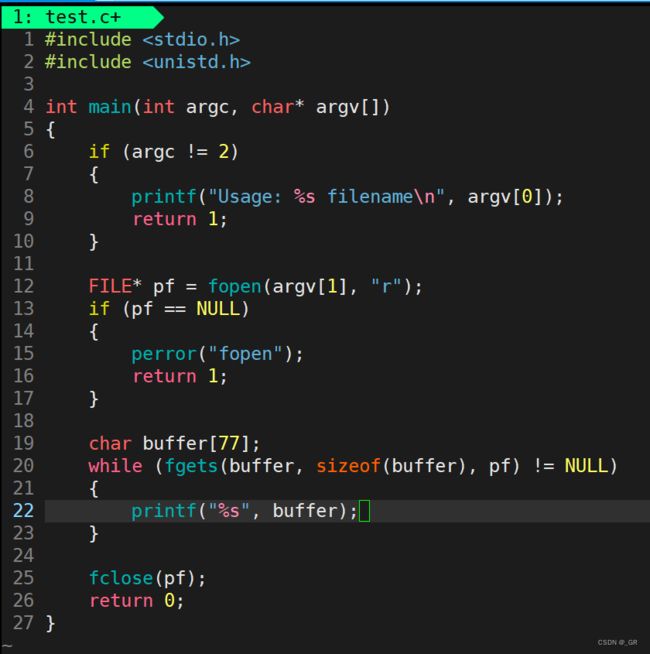
我们下面再来实现一个类似 cat 的功能,输入文件名打印对应文件内容:
#include
#include
int main(int argc, char* argv[])
{
if (argc != 2)
{
printf("Usage: %s filename\n", argv[0]);
return 1;
}
FILE* pf = fopen(argv[1], "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
char buffer[77];
while (fgets(buffer, sizeof(buffer), pf) != NULL)
{
printf("%s", buffer);
}
fclose(pf);
return 0;
} 
编译运行:
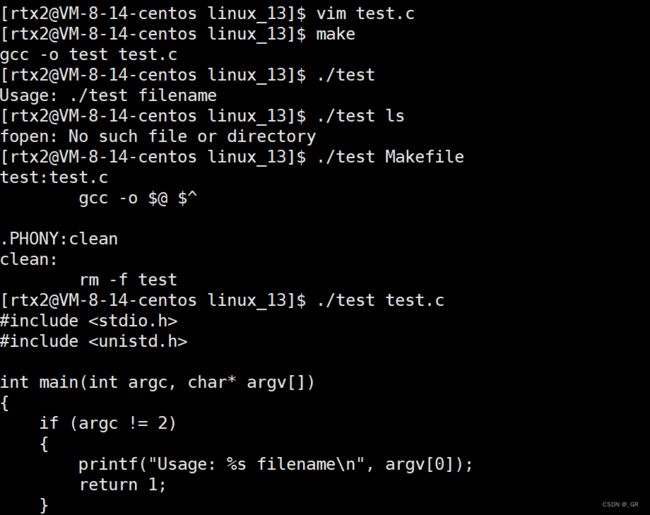
成功实现,如果把名字改成mycat再放入到BASH中就更像了。
2. 文件系统接口
狭义的文件:磁盘文件。广义:一切皆文件
Linux中文件是一个字符流序列:
普通文件,目录,磁盘、打印机、网卡,键盘、显示器等设备都可以称作文件。
不同的编程语言都有文件操作的接口,包括C++,Java,Python,php,Go等等语言,并且它们的操作接口函数都不一样,但是它们所在的系统都是Linux系统。
无论上层语言如何变化,但是进行文件操作的时候,各种语言最终都会调用Linux的文件操作的系统调用接口。

2.1 系统调用与封装
当我们向文件写入时,最终是不是向磁盘写入?是。磁盘是硬件吗?就是硬件。
当我们像文件写入时,最后是向磁盘写入。磁盘是硬件,那么谁有资格向磁盘写入呢?
只能是操作系统。既然是操作系统在写入,那我们自然不能绕开操作系统对磁盘硬件进行访问。
所有的上层访问文件的操作,都必须贯穿操作系统。
想要被上层使用,必须使用操作系统的相关的系统调用。
回顾一下我们学习 C 语言的第一个函数接口:
printf("hello world!\n");如何理解 printf?我们怎么从来没有见过这些系统调用接口呢?
显示器是硬件,我们 printf 的消息打印到了硬件上,是你自己调用的 printf 打印到硬件上的,
但并不是你的程序显示到了显示器上,因为显示器是硬件,它的管理者只能是操作系统,
你不能绕过操作系统,而必须使用对应的接口来访问显示器,我们看到的 printf 一打,
内容就出现在屏幕上,实际上在函数的内部,一定是调用了系统调用接口的。
任何语言都是这样的,用到的接口都是语言提供给你的。
之所以你没有见到系统调用,因为所有的语言都被系统接口做了 封装。
所以你看不到对应的底层的系统接口的差别。为什么要封装?原生系统接口,使用成本比较高。
系统接口是 OS 提供的,就会带来一个问题:如果使用原生接口,你的代码只能在一个平台上跑。
直接使用原生系统接口,必然导致语言不具备跨平台性。
如果语言直接使用操作系统接口,那么它就不具备跨平台性,可是为什么采用封装就能解决?
封装是如何解决跨平台问题的呢?很简单:" 穷举所有的底层接口 + 条件编译 "
我们学习的接口,C 库提供的文件访问接口,系统调用。它们两具有上下层关系,C 底层一定会调用这些系统调用接口。
2.2 open打开文件
打开文件,在 C 语言上是 fopen,在系统层面上是 open。
open 接口是我们要学习的系统接口中最重要的一个。man 2 open:

可以看到,相较于 C 的 fopen 来说,这个接口一上来就显得很复杂。
我们看到,这个 open 接口一个是两参数的,一个是三参数的,这个我们放到后面解释。
- const char* pathname:这是文件路径,也就是我们要打开的文件所在的路径,其中包括文件名,如果没有路径只有文件名的话,默认在当前路径打开。
- int flags:打开方式选项标志位。在使用C语言进行文件操作的时候,打开方式有“w”,“r”,“a”等方式,系统调用open也有,只是将这些标志放在了一个32位的变量中
- mode_t mode:它是权限值,如果这个文件不存在,那么以写的方式打开的时候就会创建这个文件,在创建文件的时候需要给这个文件设定权限(使用八进制数)。如果这个文件存在的话,那么就不用传第三个参数了,因为文件的权限已经确定了。
mode 参数的 "文件操作模式" :
#if (defined _CRT_DECLARE_NONSTDC_NAMES && _CRT_DECLARE_NONSTDC_NAMES) || (!defined _CRT_DECLARE_NONSTDC_NAMES && !__STDC__)
#define O_RDONLY _O_RDONLY
#define O_WRONLY _O_WRONLY
#define O_RDWR _O_RDWR
#define O_APPEND _O_APPEND
#define O_CREAT _O_CREAT
#define O_TRUNC _O_TRUNC
#define O_EXCL _O_EXCL
#define O_TEXT _O_TEXT
#define O_BINARY _O_BINARY
#define O_RAW _O_BINARY
#define O_TEMPORARY _O_TEMPORARY
#define O_NOINHERIT _O_NOINHERIT
#define O_SEQUENTIAL _O_SEQUENTIAL
#define O_RANDOM _O_RANDOM
#endif我们先记一下这几个:
O_RDONLY: (rdonly)只读打开O_WRONLY: (wronly)只写打开O_RDWR : (rdwr)读,写打开这三个常量,必须指定一个且只能指定一个O_CREAT : (creat)若文件不存在,则创建它。需用mode选项,指明新文件的访问权限O_APPEND: (append)追加写
在 Linux 下,C 语言中文件不存在,就直接创建它,创建是不是需要权限?
当然是需要的,我们需要给文件设置初始权限,这个 mode 参数就是干这个活的。
我们再来看看open接口的返回值,居然是 int,而不是我们 fopen 的 FILE*
open接口返回值:成功返回新打开的文件描述符,失败返回 - 1
2.2.1 flags标记位
lags 为 标记位,并且它是个整数类型(C99 标准之前没有 bool 类型)
标记位实际上我们造就用过了,比如定义 flag 变量,设 flag=0,设 flag=1,传的都是单个的。
但如果我想一次传递多个标志位呢?定义多个标记位?flag1, flag2, flag3...
方案:系统传递标记位是通过 位图 来进行传递的。
每个 宏标记一般只需要满足有一个比特位是 1,并且和其它宏对应的值不重叠 即可。
让每一个宏对应不同的比特位,在内部就可以做不同的事情,为了大家能够更好的理解,
下面我们自己设计一个接口,仿照系统传递标记位的做法,把前面写的代码注释掉,通过这种思路去实现一下标记位:
#include
#define PRINT_A 0x1 // 0000 0001
#define PRINT_B 0x2 // 0000 0010
#define PRINT_C 0x4 // 0000 0100
#define PRINT_D 0x8 // 0000 1000
void Show(int flags)
{
if (flags & PRINT_A)
printf("Hello A\n");
if (flags & PRINT_B)
printf("Hello B\n");
if (flags & PRINT_C)
printf("Hello C\n");
if (flags & PRINT_D)
printf("Hello D\n");
}
int main()
{
Show(PRINT_A);
printf("-----------------------------------\n");
Show(PRINT_B);
printf("-----------------------------------\n");
Show(PRINT_A | PRINT_B);
printf("-----------------------------------\n");
Show(PRINT_C | PRINT_D);
printf("-----------------------------------\n");
Show(PRINT_A | PRINT_B | PRINT_C | PRINT_D);
return 0;
} 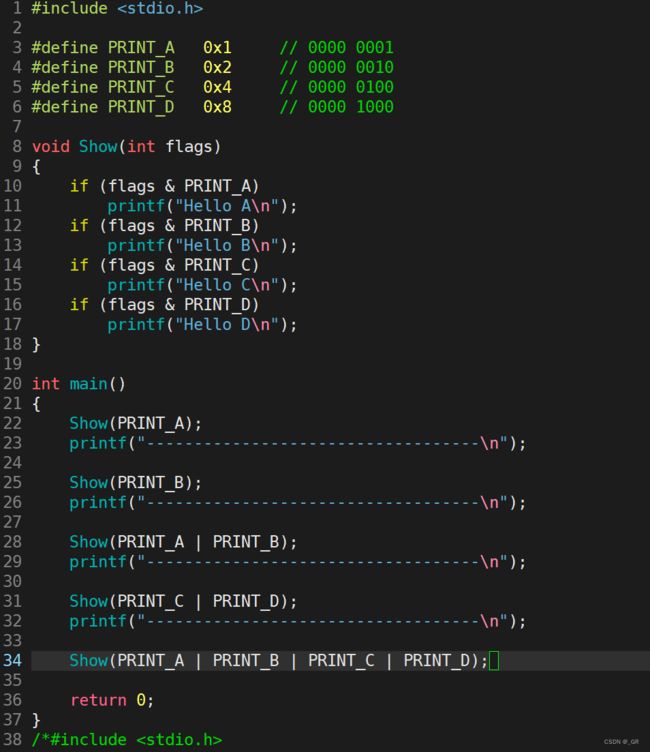
编译运行:
通过标记位,可以在内部做对应的事情。打印 A 就打印 hello A,打印 A 和 B 就打印 hello A 和 hello B,现在我们再理解别人给我们传递宏标志位的做法。我们每一个宏所对应的值,在二进制位上互相都是不重叠的,一人用一个比特位。我们调用时要同时打印多个就按位或,内部再做条件判断,检测条件是否成立,这即是系统传参的做法。一个系统调用接口可以穿十几乃至三十几个的标志位,基本是够用的。
2.2.2 open用法演示
这里把log.txt删掉,然后写test.c:
int open(const char* pathname, int flags); 
① 这里我们选择取名为 fd,而不是我们 fopen 习惯用的 pf/fp,因为 fd 描述文件描述符,这也是我们后面章节要重点讲解的,所以这里取 fd 来接收 open 接口的返回值,
② 只写是 O_WRONLY,如果没有对应文件就创建,创建时 O_CREAT,这里我们用 | 把二者相关联可以了。
③ open 的返回值是 int,如果返回 -1 则表示 error,所以如果 fd < 0 就说明打开失败了,
编译运行:

log.txt的权限为什么是看不懂的?
创建一个文件,你需要告诉操作系统默认权限是什么。
当我们要打开一个曾经不存在的文件,不能使用两个参数的 open,而要使用三个参数的 open。也就是带 mode_t mode 的 open,这里的 mode 代表创建文件的权限:
int open(const char* pathname, int flags, mode_t mode); 删掉log.txt,修改一下我们的代码,使用带 mode 参数的 open:

成功设置,对于umask等权限不熟悉的可以看权限部分篇章复习下。实际上,umask命令设置权限就是调用这个接口(第三个参数)。
fopen创建一个新文件是可以帮设置权限的:

编译运行:

这也说明了语言提供的接口和系统调用的区别。
2.3 close关闭文件和write写入文件和rede读取文件
在 C 语言中,关闭文件可以调用 fclose,在系统接口中我们可以调用close来关闭,man 2 close:

比较简单,只有一个 fd 参数。
看下文件写入:在 C 语言中我们用的是 fprintf, fputs, fwrite 等接口,而在系统中,我们可以调用 write 接口,man 2 write:

write 接口有三个参数:
- int fd:文件描述符
- const char* buf:要写入的缓冲区的起始地址(如果是字符串,那么就是字符串的起始地址)
- size_t count:要写入的缓冲区的大小
删掉log.txt,向文件写入 5 行信息,并关掉文件:
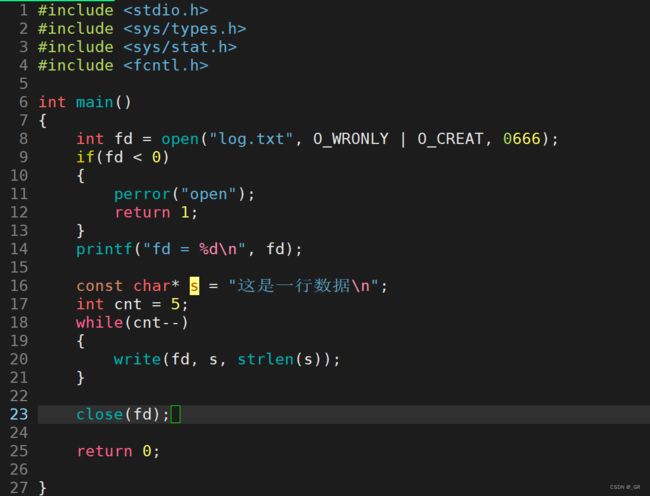
编译运行:

清空文件的小技巧: > 文件名 ,前面什么都不写,直接重定向 + 文件名:

2.3.1 O_TRUNC截断清空
C语言在 w 模式打开文件时,文件内容是会被清空的,但是 O_WRONLY 好像并非如此?
运行一下上面的test,此时我们的 log.txt 内有 5 行数据,现在我们执行下面的代码:
(只改了字符串s,为了方便区分)

编译运行:

似乎没有全部覆盖,曾经的数据被保留了下来,并没有清空。
其实,没有清空根本就不是读写的问题,而是取决于有没有加 O_TRUNC 选项!
因此,只有 O_WRONLY 和 O_CREAT 选项是不够的:
如果想要达到 w 的效果还需要增添 O_TRUNC

让 open() 达到 fopen 中 "w" 模式的效果:

编译运行:

C 的 fopen 调一个 w 就以写的方式打开了,不存在会自动创建,并且会完全覆盖原始内容,
它对应的底层 open 调用,调用接口所传入的选项就是 O_WRONLY, O_CREAT, O_TRUNC。
由此可见,fopen 是多么的好用,open 不仅要传这么多选项,而且属性也要设置。
2.3.2 O_APPEND追加写入
C语言中我们以 a 模式打开文件做到追加的效果。
现在我们用 open,追加是不清空原始内容的,所以我们不能加 O_TRUNC,得加 O_APPEND:

编译运行:
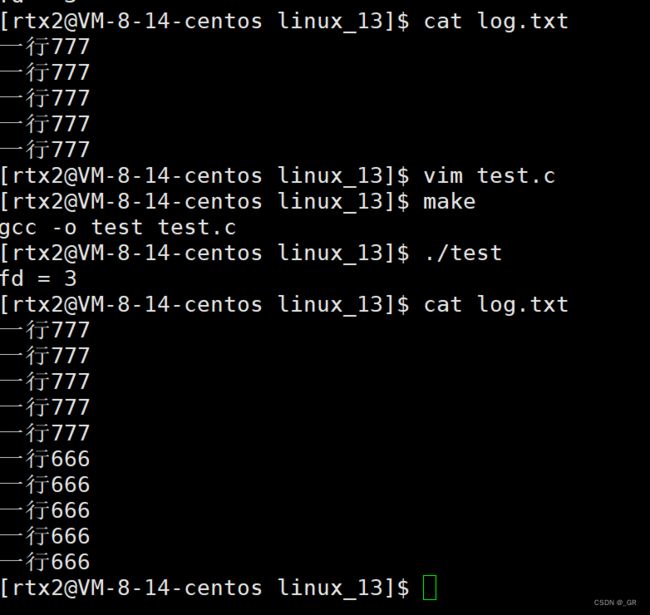
2.3.3 O_RDONLY读取
如果我们想读取一个文件,用rede接口,那么这个文件肯定是存在的,我们传 O_RDONLY 选项:

编译运行:
3. 文件描述符fd
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);我们使用 open 函数举的例子中,一直是用一个叫做 fd 的变量去接收的。
fopen 中我们习惯使用 fp / pf 接收返回值,那是因为是 fopen 的返回值 FILE* 是文件指针,
file pointer 的缩写即是 fp,所以我们就习惯将这个接收 fopen 返回值的变量取名为 fp / pf。
那为什么接收 open 的返回值的变量要叫 fd 呢?
3.1 open的返回值
open 如果调用成功会返回一个新的 文件描述符 (file descriptor) ,如果失败会返回 -1 。
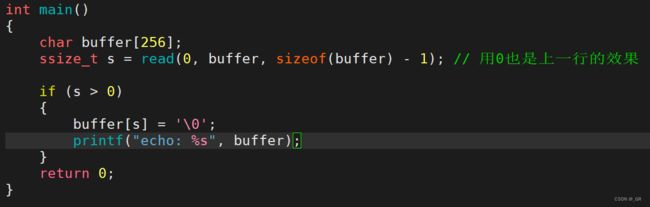
我们现在删掉log.txt,多打开几个文件,观察 fd 的返回值:

编译运行:

我们发现这 open 的 5 个文件的 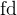 (返回值) 分别是3,4,5,6,7。为什么从 3 开始,而不是从 0 开始?0, 1, 2 去哪了?
(返回值) 分别是3,4,5,6,7。为什么从 3 开始,而不是从 0 开始?0, 1, 2 去哪了?
- 0:标准输入(键盘,stdin)
- 1:标准输出(显示器,stdout)
- 2:标准错误(显示器,stderr)
系统接口认的是外设,而 C 标准库函数认的是:
#include
extern FILE* stdin;
extern FILE* stdout;
extern FILE* stderr; 这三个都是系统调用接口,那么 stdin, stdout, stderr 和上面的 0,1,2 又有什么关系呢?
FILE* 是文件指针,那么 FILE 是什么呢?它是 C 库提供的结构体。
只要是结构体,它内部一定封装了多个成员。
虽然 C 用的是 FILE*,但是系统的底层文件接口只认 fd,也就是说:
C 标准库调用的系统接口,对文件操作而言,系统接口只认文件描述符。
因此,FILE 内部必定封装了文件操作符 fd
下面我们来验证一下,先验证 0,1,2 就是标准IO。
0 是标准输入 (stdin):
编译运行:

stdout 标准写入(1) 和 stderr 错误写入(2) :

编译运行:

1 和 2 的区别我们放到后面再讲,
至此,我们证明了每次我们打开文件虽然打开的是 3,但是可以像 3,4,5,6…… 去写,默认系统就会帮我们打开:0 (标准输入, stdin) ,1 (标准输出, stdout),2 (错误输出, stderr)
下面我们要做的是,验证一下 0,1,2 和 stdin, stdout 和 stderr 的对应关系:


函数接口的对应:fopen / fclose / fread / fwrite : open / close / read / write
这个 0, 1, 2, 3, 4, 5……,是不是有点像数组下标,它就是数组下标。
3.2 文件描述符的底层理解
一个进程可以打开多个文件,所以在内核中,进程与打开的文件之比是1:N的。
所以系统在运行中,有可能会存在大量的被打开的文件,OS 要对这些被打开的文件进行管理。
OS 如何管理这些被打开的文件呢?先描述,再组织
如果你在内核中打开了多个的文件,那么系统会在内核中为文件创建一个 struct file 结构。
可以通过 next 和 prev 将其前后关联起来(内核的链表结构有自己的设计)。
struct file
{
//大部分 内容 + 属性
struct file* next;
struct file* prev;
};既然你打开了一个文件,就会创建一个 struct file,那么你打开多个文件,
系统中必然会存在大量的 struct file,并且该结构我们用链表的形式链接起来:

如此一来,对被打开的文件的管理,就转化成为了对链表的增删改查。
进程如何和打开的文件建立映射关系?打开的文件哪一个属于我的进程呢?
在内核中,task_struct 在自己的数据结构中包含了一个 struct files_struct *files (结构体指针):
而我们刚才提到的 "数组" 就在这个 file_struct 里面,该数组是在该结构体内部的一个数组。
struct file* fd_array[ ]; 该数组类型为 struct file* 是一个 指针数组,
里面存放的都是指向 struct file 的指针。数组元素映射到各个被打开的文件,直接指向对应的文件结构,若没有指向就设为 NULL。
此时,就建立起了 "进程" 和 "文件" 之间的映射关系。

如此一来,进程想访问某一个文件,只需要知道该文件在这张映射表中的数组下标。
上面这些就是在内核中去实现的映射关系了,这个下标 0,1,2,3,4 就是对应的文件描述符 fd。
3.3 Linux下一切皆文件
上面说的 0,1,2 → stdin, stdout, stderr → 键盘, 显示器, 显示器,这些都是硬件啊?
也用上面讲的 struct file 来标识对应的文件吗?
- 每一个硬件,操作系统都会维护一个struct file类型的结构体,硬件的各种信息都在这个结构体中,并且还有对应读写函数指针(对硬件的操作主要就是读写)。
- 每个硬件的具体读写函数的实现方式都在驱动层中,使用到相应的硬件时,操作系统会通过维护的结构体中的函数指针调用相应的读写函数。
站在操作系统的角度来看下层,无论驱动层和硬件层中有什么,在它看来都是struct file结构体,都是通过维护这个结构体来控制各种硬件。
站在操作系统的角度来看上层,无论用户层以及系统调用有什么,在它看来都是一个个进程,都是一个个的task_struct结构体,都是通过维护这个结构体来调度各个进程的。
真正的文件在操作系统中的体现也是结构体,操作系统维护的同样是被打开文件的结构体而不是文件本身。一切皆文件也指:在操作系统中一切都是结构体。
如果想打开一个文件,打开之后把读写方法属性交给 OS,
在内核里给该硬件创建 stuct file,初始化时把对应的函数指针指向具体的设备,
在内核中存在的永远都是 struct file,然后将 struct file 互相之间用链表关联起来。
站在用户的角度看,一个进程看待所有的文件都是以统一的视角看待的,
所以当我们访问一个 file 的时候,这个 file 具体指向底层的哪个文件或设备,
这完全取决于其底层对应的读写方法指向的是什么方法。
这操作像不像多态?C++ 中运行时多态用的虚表和虚函数指针,那不就是函数指针么?
"上层使用同一对象,指针指向不同的对象,最终就可以调用不同的方法"
你可以理解为:多态的前身
再看上面这张图:
这里的标准输入输出等指向的硬件设备是谁,就取决于底层的硬件是怎么设计的了。
通过操作系统层做了一层软件封装,达到了这样的效果。
底层叫硬件,而 具体的硬件读写方法是驱动干的,具体的硬件读写是驱动程序要做的,
OS 只管跟外设要求其提供读写方法,最终 OS 在内核中给它们抽象成 struct file,
把它们都看作文件,然后通过函数指针指向具体的文件对应的设备,就完成了 "一切皆文件" 。
3.4 fd的分配原则
现在再回过头来看这段代码,应该有新认识了吧:

如果我想我们新建的文件的fd是0开始的呢?默认把 0,1,2 打开,那我们直接 close(0) 关掉它们:

编译运行:

此时,新建文件描述符分配的是0,现在我们再把 2 关掉,close(2) 看看:

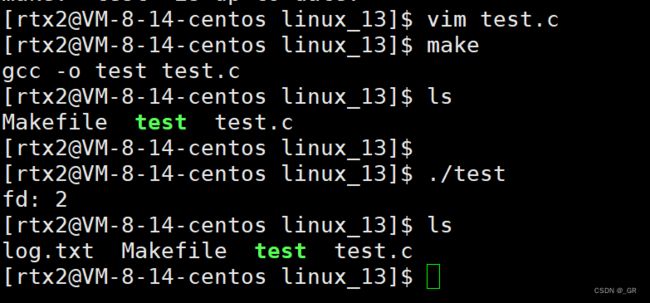
此时,新建文件描述符分配的就是2了,所以,默认情况下 0,1,2 被打开,你新打开的文件默认分的就是 3 (因为 0,1,2 被占了) 。
如果把 0 关掉,给你的就是 0,如果把 2 关掉,给你的就是 2,那是不是把 1 关掉,给你的就是 1 呢?


为什么什么都没有输出?
原因很简单,1 是 stdout,printf 打印是往 stdout 打印的,你把 1 关了当然就没有显示了。
分配规则:从头遍历数组 fd_array[ ] ,找到一个最小的且没有被使用的下标分配给新的文件。
根据 fd 的分配规则,新的 fd 值一定是 1,所以虽然 1 不再指向对应的显示器了,但事实上已经指向了 log.txt 的底层 struct file 对象了。
4. 重定向
照上面的说法,能不能知道我们打印的东西到底是什么?log.txt里有东西吗?:

没有吗?实际上并不是没有,而是没有刷新,用 fflush 刷新缓冲区后,log.txt 内就有内容了。
在上面代码加上fflush(stdout);


还是什么都没有打印?看下log.txt:

这次有东西了,我们自己的代码中调用的就是 printf,printf 本来是往显示器打印的,
现在不往显示器打了,而是写到了文件里,它的 "方向" 似乎被改变了。
这不就是重定向吗?如果要进行重定向,上层只认识 0,1,2,3,4,5 这样的 fd,我们可以在 OS 内部,通过一定的方式调整数组的特定下标的内容 (指向),我们就可以完成重定向操作。
4.1 dup2函数
上面重定向的实现总感觉怪怪的,还需要close(1);,然后再打开新文件,而且也不是很方便,所以操作系统提供了一个系统调用,可以直接实现重定向。

int dup2(int oldfd, int newfd);dup2 可以让 newfd 拷贝 oldfd,如果需要可以将 newfd 先关闭。
newfd 是 oldfd 的一份拷贝,将后者 (newfd) 的内容写入前者 (oldfd),最后只保留 oldfd。
至于参数的传递,比如我们要输出重定向 (stdout) 到文件中:
我们要重定向时,本质是将里面的内容做改变,所以是要把 fd 的内容拷贝到 1 中的:

因为要将显示器的内容显示到文件里,所以 oldfd 就是 fd,newfd 就是 1 了。
dup2代码演示:


现在没加dup2,所以是打印到屏幕上,加上dup2:
编译运行重复上一次的指令:

这就实现了重定向的效果。
4.2 追加重定向和输入重定向
追加重定向只需要将我们 open 的方式改为 O_APPEND 就行了:
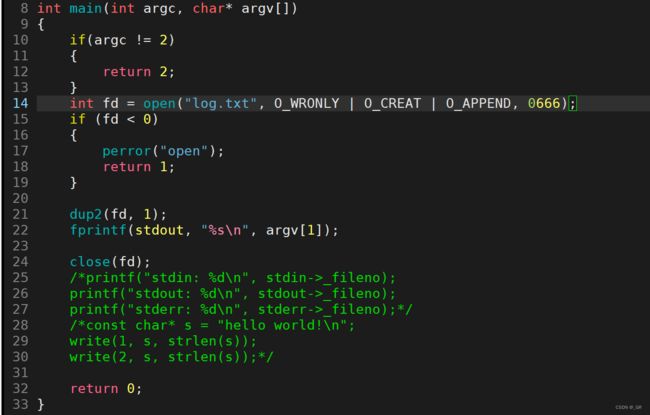
输入重定向将 open 改为 O_RDONLY,dup(fd, 0) :

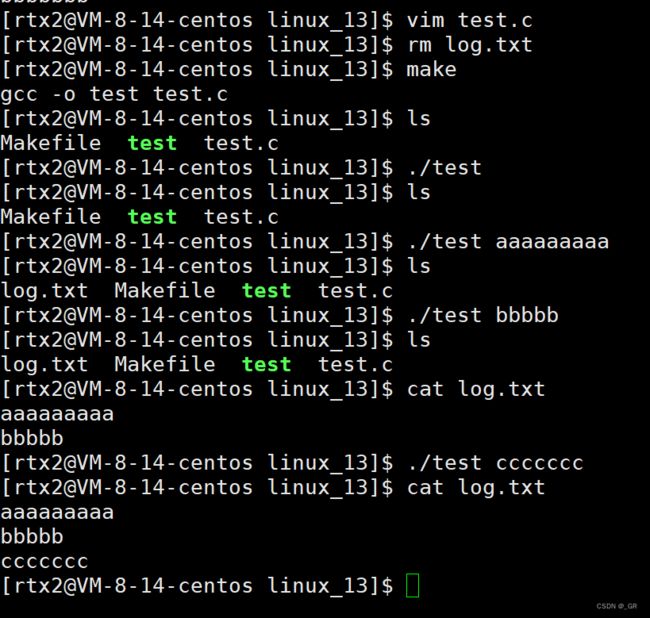
编译运行:

成功追加。
本篇完。
下一篇:零基础Linux_14(基础IO_文件)缓冲区+文件系统。