初识Java语言(三)- 数组
文章目录
-
- 一、数组的概念
- 二、声明数组
- 三、访问数组元素
- 四、数组拷贝与排序
-
- 拷贝与排序
- 深拷贝与浅拷贝的区别
- 五、二维数组以及存储形式

往期文章
一、 初识java数据类型以及运算符(力作)
二、 Java中方法的概念以及递归的讨论
一、数组的概念
数组是存储相同类型值的序列。
数组是一种数据结构,用来存储同一类型值的集合。通过一个整形下标(索引)可以访问数组中的每一个值。
二、声明数组
数组的声明,分为两种: 静态的声明 和 动态的声明。
静态: int[] arr = {1,2,3,4,5};
动态: int[] arr = new int[] {1,2,3,4,5}; 或者这样 : int[] arr = new int[5]; 开辟5个整形内存空间。
注释: int[] , 是这个变量的类型名 ,静态的声明,大括号里直接给的数组,并没有new一块空间,这样的声明,是根据大括号里面的元素个数,来决定这个数组的大小; new int[5] ,会在堆上创建5个int类型的内存空间,并且初始化为0。一旦创建了数组,即就是它的数组长度已经确定了,不能再更改。只能修改数组里面的元素。
在java中,允许长度为0的数组, new elementType[0]。 这样的形式,可能会在以后遇到,切记,长度为0的数组和null是有区别的!!!
切记: arr变量名,是栈上的一块空间。而new int[] , 是在堆上的一块空间。arr里面只是存储了堆上这块空间的首元素地址。
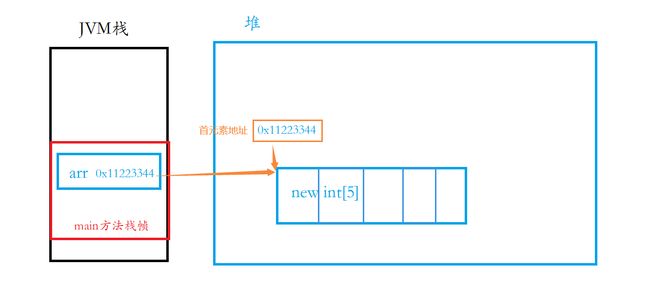
三、访问数组元素
前面的数组的下边范围是0 ~ 4, 而不是1 ~ 5。一旦创建了数组,就可以往数组里面填充元素,如下
int[] arr = new int[0];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
数值类型的数组会初始化为0,boolean数组初始化为false,而引用类型的数组,会初始化为null,而非空串。
如果下标不在数组下标的范围内,就会发生数组越界异常,
int[] arr = new int[5];
for (int i = 0; i < 6; i++) {
arr[i] = i; //此时下标i会变成5,arr[5]就会越界
}
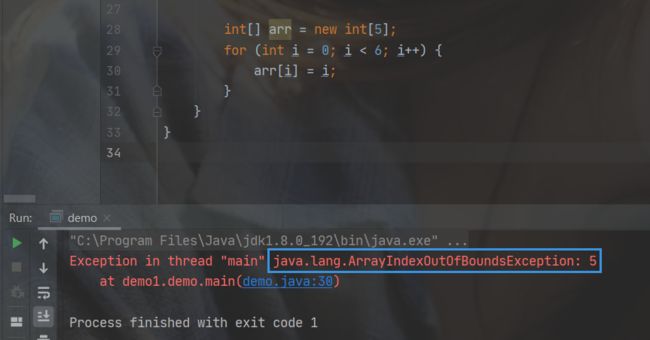
所以java中自带了一个获取数组的长度, 就是 数组名.length,它可以自动获取数组的长度。除了这这样的访问方式,我们还有一种增强for循环。如下
int[] arr = {1,2,3,4,5};
for (int data : arr) {
System.out.println(data);
}
这种循环,不必考虑指定下标值。格式为 for (元素类型 元素 : 数组名)。 元素类型指的是: 这个数组里面存储的元素的类型 ; 元素: 它会将数组的每一个元素暂时存储在这里,用于直接打印或者做其他的事情; 数组名: 就是需要操作的对象。
这个循环应该读作“循环arr中的每一个元素“(for each element in arr)。增强for循环语句显得更加简洁,更不容易出错,因为你不必为下标的起始值和终止值而操心。
注释: 增强for循环语句的循环变量将会遍历数组的每个元素,而不是下标值。
技巧: 有一个更简单的方式可以打印数组中的所有值,即利用Arrays类中的toString方法。调用Arrays.toString(arr),将返回一个包含数组元素的字符串,这些元素包含在括号里面,并且以逗号隔开。

四、数组拷贝与排序
拷贝与排序
请问,这样算拷贝了一个数组吗?
int[] arr1 = {1,2,3,4,5,6,7,8,9};
int[] arr2 = arr1; //这样算拷贝了吗?
其实并没有,好好看一下上文中的声明数组的内存图。我们就知道,其实arr1存储的只是一个内存地址,我们直接将这个地址赋值给了arr2,此时,达到的效果是 arr1 和arr2,两个变量都指向同一块内存空间,并没有拷贝出一个新的数组。
拷贝的方式:
-
Arrays.copyOf(被拷贝数组, 新数组的长度),返回值就是一个新数组的地址。
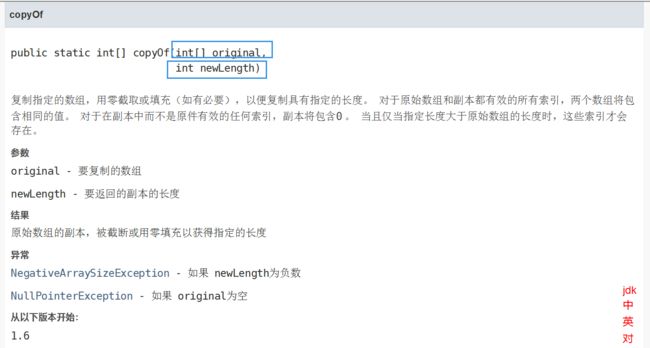
int[] arr = {1,2,3,4,5}; int[] newArr = Arrays.copyOf(arr, 5);此时我们再往深处查看,Arrays.copyOf(),底层是怎么实现的?
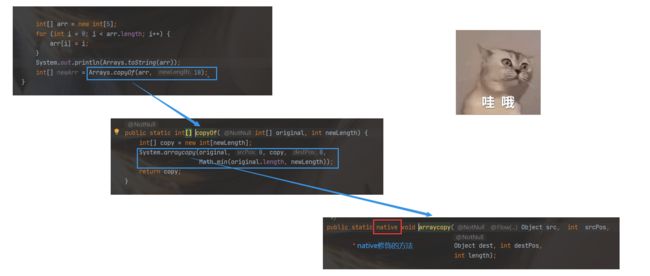
Arrays.copyOf(),底层调用了一个System.arraycopy(),这个方法是被 native修饰的。也被称为本地方法。
问: native是什么?
答: JVM 是一个基于 C++ 实现的程序.。在 Java 程序执行过程中, 本质上也需要调用 C++ 提供的一些函数进行和操作系统底层进行一些交互。 因此在 Java 开发中也会调用到一些 C++ 实现的函数。这里的 Native 方法就是指这些 C++ 实现的, 再由 Java 来调用的函数
-
Arrays.copyOfRange(被拷贝数组, 左下标, 右下标)。切记这里拷贝的范围是 [左下标, 右下标),也就是说,这里是左闭右开区间。
·
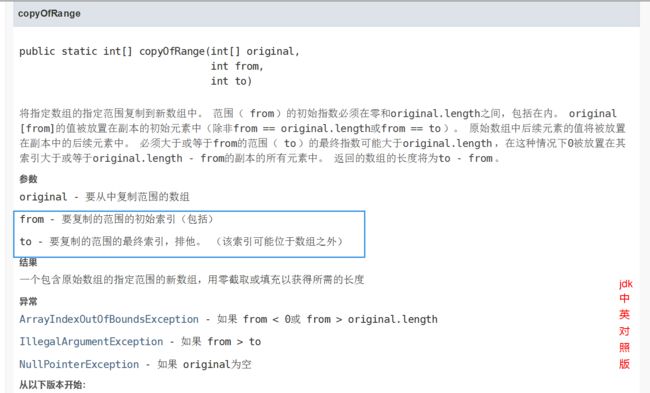
-
要想对数组里面的元素进行排序,也可以使用Arrays里面的sort方法。这个方法使用了优化的快速排序算法。快速排序算法对于大多数数据集合来说都是效率比较高的。
Arrays.sort(被排序的数组)。(升序)

深拷贝与浅拷贝的区别
上面,我们讲完了数组的拷贝,大家想没想过上面的拷贝是深拷贝还是浅拷贝?
何为深拷贝?何为浅拷贝?
深拷贝指的是: 我拷贝一个数据后,此时一个是原数据,一个是拷贝的数据。如果此时我们去修改拷贝的数据,看是否会影响原数据的内容。 如果不影响原数据的内容就是深拷贝。反之就是浅拷贝。 举例:

上图所示的就是,上文中拷贝的数据,拷贝的是基本数据类型,所以拷贝后,数据存储一块新的内存区域中,此时我们去修改newArr指向的内存空间的数据,是不会影响到arr数组的数据的。此时我们就叫做深拷贝。

此时如果去修改s字符串里面的内容,那么newS字符串里面的内容也会被修改。这就是浅拷贝。
总结: 当面试官问你拷贝的数据是深拷贝还是浅拷贝时。你该怎么回答?
拷贝的对象是什么?
假设1: 引用数据类型: 只是单纯的使用拷贝的方法进行拷贝,就是浅拷贝。如果拷贝方法本身就处理了深拷贝的情况,就是深拷贝。
假设2: 基本数据类型: 深拷贝。
五、二维数组以及存储形式
二维数组,也被称为矩阵。可以使用两个下标值进行访问。二维数组的本质其实还是一维数组, 由一维数组 组成。
在Java中,声明一个二维数组非常简单,如下:
int[][] array1 = new int[3][]; //合法的
int[][] array2 = new int[3][3];
和一维数组的声明差不多。但是这里需要注意的是: 在C语言中,二维数组的声明,可以省略行的大小,但是在Java中,只能省略列的大小。
二维数组的存储形式:与C语言二维数组的存储形式不一样。

C语言二维数组内存区域:
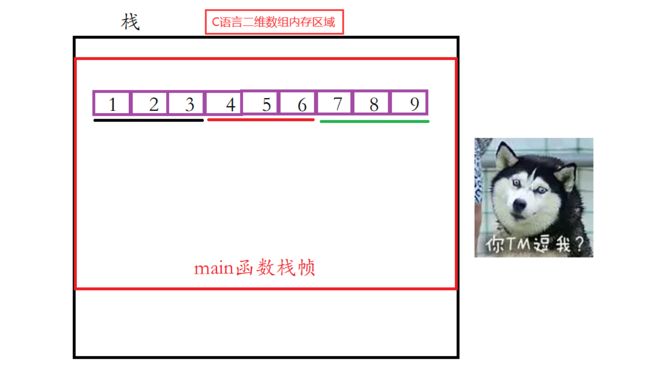
要想遍历二维数组,其实跟一维数组的遍历方式差不多:
-
//普通for循环 int[][] array = {{1,2,3},{4,5,6},{7,8,9}}; for (int i = 0; i < array.length; i++) { for (int j = 0; j < array[0].length; j++) { System.out.print(array[i][j] + " "); } } -
//增强for循环 int[][] array = {{1,2,3},{4,5,6},{7,8,9}}; for (int[] row : array) { //此时每一个元素,其实就是一个 一维数组。 对比上面的内存分布图 for (int data : row) { System.out.print(data + " "); } }要想像一维数组那样,将元素转换为字符串的形式输出。Arrays.toString() 。已经行不通了,这个只对一维数组起作用。二维数组该这样玩:
//字符串形式输出 int[][] array = {{1,2,3},{4,5,6},{7,8,9}}; System.out.println(Arrays.deepToString(array));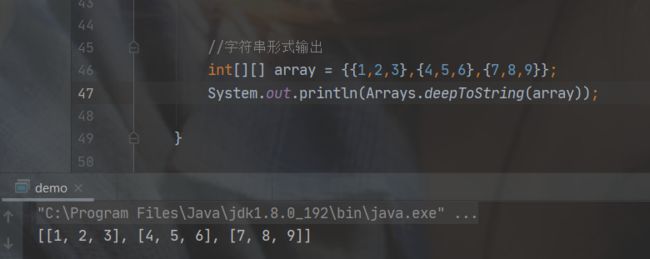
好啦,本期更新就到此结束啦,各位朋友,下期见!!!