《BPF( 伯克利数据包过滤器 ) Performance Tools》 第二章 技术背景
MarkDown编辑语法
第1章简要介绍了BPF性能工具使用到的各种技术。本章会更加深入地阐述这些技术,涵盖了历史、接口、内部运作方式,以及如何使用BPF工具。本章的技术深度为整本书之最,为了篇幅尽量简短,这里假定你已经具备了一些关于系统内核和指令集级编程方面的知识。本章的学习目标不在于记住每页的具体内容,而是希望你能够:
■了解BPF技术的起源,以及eBPF在今天所扮演的角色。
■理解基于帧指针( frame pointer) 的调用栈回溯和其他相关技术。
■理解如何阅读火焰图。
■理解kprobes和uprobes的使用,并知晓其接口的稳定性问题。
■理解内核跟踪点、USDT探针和动态USDT的作用。.
■了解PMC及其在BPF跟踪工具中的使用。
■了解未来的开发方向: BTF,以及其他BPF调用栈回溯技术等。
学习本章将有助于理解本书后面的内容,不过你也可以先粗略翻阅本章,然后在后面需要时再回来了解相关细节。第3章将指引你使用BPF工具上手解决性能问题。
本章的技术深度为整本书之最,若是因内核知识缺乏而看的很艰难,建议看看《性能之巅:洞悉系统、企业与云计算》
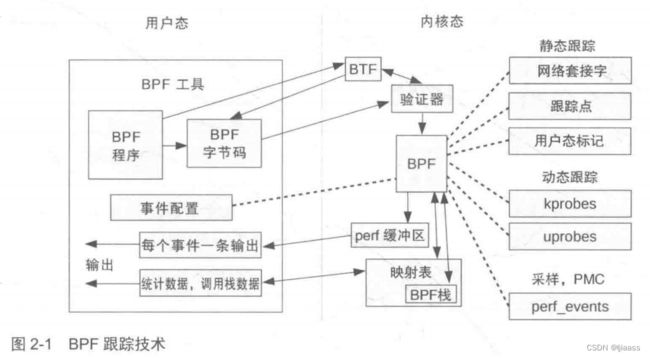
2.1 图释BPF
图2-1展示了本章将涉及的诸多技术,以及它们之间的关系。
2.2 BPF( 伯克利数据包过滤器 )
BPF最初是为BSD操作系统开发的,1992 年的论文“The BSD Packet Filter: A NewArchitecture for User-level Packet Capture”对其进行了阐述。这篇论文公开发表在1993年在圣地亚哥举办的USENIX冬季会议上。当时一起发表的还“Measurement,Analysis, and Improvement of UDP/IP Throughput for the DECstation 5000”7。DEC工作站早已成为历史,但BPF( 伯克利数据包过滤器 )作为包过滤的工业标准解决方案一直沿用至今。
数据包过滤(packet filtering)是一个用软件或硬件设备对向网络上传或从网络下载的数据流进行有选择的控制过程 。
定义:汉语词典中指对事物做出的明确价值描述。
BPF的工作方式十分有趣:最终用户使用BPF虚拟机的指令集定义过滤器表达式,然后传递给内核,由解释器执行 (有时BPF虚拟机的指令集也称BPF字节码)。这使得 包过滤可以在内核中直接进行,避免了向用户态进程复制每个数据包,从而提升了数据包过滤的性能tcpdump(8)就是这样工作的。BPF还提供了安全性保障,因为用户定义的过滤器在执行前必须首先通过安全性验证 。早期的包过滤必须在内核空间执行,安全是一个硬性要求。图2-2显示了这一切是如何工作的。
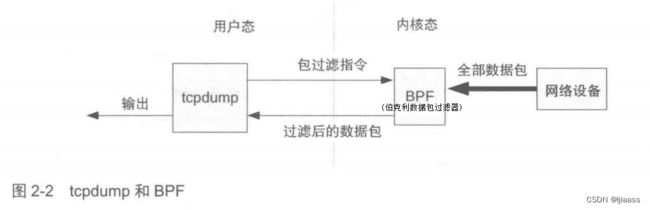
在运行tcpdump(8)时带上命令行参数-d,可以打印出定义过滤器表达式的BPF指令。例如:
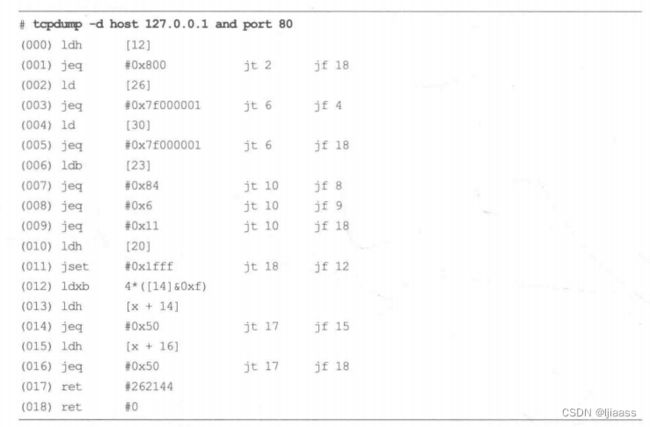
最初的BPF现在被称为“经典BPF",它是一个功能有限的虚拟机。 它有两个寄存器,一个由16个内存槽位组成的临时存储区域和一个程序计数器。以上部件均按32位寄存器大小运行。经典 BPF于1997 年进入Linux内核版本2.1.75。
虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。
自从BPF被添加到Linux内核后,陆续有过一些比较重要的改进。Eric Dumazet在2011年7月发布的Linux 3.0中增加了BPF即时(just-in-time, JIT) 编译器 ,相比解释器来说,其执行效率更高9。Will Drewry在2012年为seccomp (安全计算)系统调用添加了BPF过滤器;这是BPF第一次运用在网络领域之外,也显示出BPF可以作为一个通用执行引擎的潜力。
2.3 扩展版BPF


Alexei Starovoitov 在PLUMgrid公司工作时创造了扩展版BPF (eBPF),当时该公司正在研究一种新的软件定义网络(software-defined networking)解决方案。这是20年来BPF的第一次重大更新,此举也将BPF扩展为一个通用的虚拟机。 当它还处在内核社区的提案阶段时,红帽公司的内核工程师DanielBorkmann就为进行重新设计提供了帮助,以便将其纳入内核并取代现有的BPF实现。扩展版BPF最终成功进入内核,此后得到了众多开发人员的贡献(参见本书致谢)。
扩展版的BPF中增加了更多寄存器 ,并将字长从32位增至64位,创建了灵活的BPF映射型存储 (map),并允许调用一些受限制的内核功能 。同时,eBPF 被设计为可以使用即时编译(JIT), 机器指令与寄存器可以一对一映射 。这就使得先前的处理器本地指令优化技术,可以重用于BPF之上。BPF验证器 也进行了更新以便支持这些扩展,而且能够拒绝任何不安全的代码。
经典BPF和扩展版BPF之间的差异见表2-1。

Alexei最初的提议,是2013年9月一个标题为“extended BPF”的补丁集。到2013年12月,Alexei提议BPF可以用于跟踪过滤。经过与Daniel的讨论和合作开发,2014年3月这些补丁开始并入Linux内核3.12。 2014年6月,JIT组件并入Linux内核版本3.15中。2014年12月,用于控制BPF的bpf(2)系统调用进入Linux 3.18版本中。
之后,Linux 4.x内核又陆续增加了对kprobes、 uprobes、 tracepoints 和perf_events 的BPF支持。
在最早的代码补丁中,这项技术曾被简写为eBPF,不过Alexei随后又将它改回,称其为BPF。现在,在net-dev邮件列表上有关BPF的开发讨论中,都直接使用BPF这种叫法。
Linux BPF运行时(runtime) 的各模块的架构如图2-3所示,图2-3展示了BPF指令如何通过BPF验证器验证,再由BPF虚拟机执行 。 BPF虚拟机的实现既包括一个解释器 (BPF的工作方式十分有趣:最终用户使用BPF虚拟机的指令集定义过滤器表达式,然后传递给内核,由解释器执行 (有时BPF虚拟机的指令集也称BPF字节码)。),又包括一个JIT编译器 :即时编译(JIT)器负责生成处理器可直接执行的机器指令 。验证器会拒绝那些不安全的操作,这包括针对无界循环的检查:BPF程序必须在有限的时间内完成。
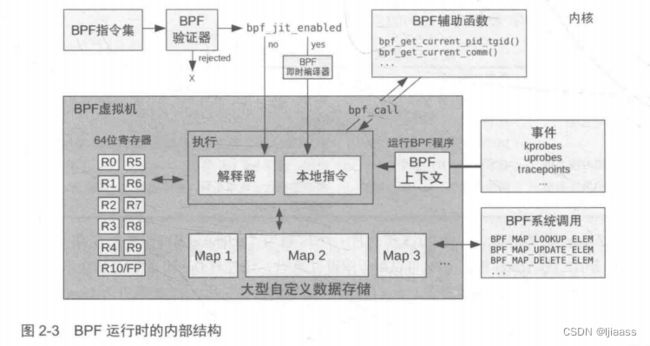
BPF可以利用辅助函数获取内核状态,利用BPF映射表进行存储。BPF程序在特定事件发生时执行,包括kprobes. uprobes 和跟踪点等事件。
本章接下来的部分讨论以下话题:
为什么性能工具需要BPF技术,
如何使用扩展版BPF编程、查看BPF指令集、BPF应用编程接口(API)、 BPF的限制,以及BTF。
这些内容有助于你在使bpftrace和BCC时,理解BPF是如何工作的。
除此之外,附录D涵盖了如何直接使用C语言进行BPF编程,附录E涵盖了BPF指令集。
2.3.1为什么性能工具需要 BPF技术
性能工具使用扩展版BPF来实现可编程性 。BPF程序可以执行自定义的延迟计算和统计摘要等功能。这些特性本身就足够使BPF成为一个有趣的工具,事实上有很多跟踪工具都具备了这些功能。BPF与众不同之处在于,它还同时具备 高效率和生产环境安全性 的特点,并且它已经被内置在Linux内核中。有了BPF,你就可以在生产环境中直接运行这些工具,而无须增加新的内核组件。
下面我们通过一个工具的输出和一幅图来看一下性能工具是如何使用BPF的。这个例子的输出来自笔者以前发布的一个叫作bitehist的BPF工具,它用直方图的形式展示磁盘I/0的尺寸分布 :

图2-4显示了使用BPF之前和之后的直方图生成过程。这里的关键变化是,直方图可以在内核上下文中生成,这大大减少了需要复制到用户空间的数据量 。这里的效率提升是如此的显著,以至于工具的额外开销减小到可以在生产环境下直接运行的程度。
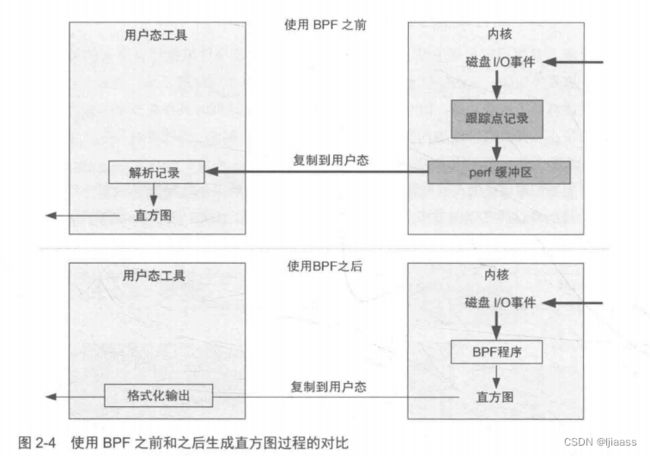
具体来说,在使用BPF之前,制作这一直方图摘要的完整步骤如下。
- 1)在内核中:开启磁盘I/O事件的插桩观测。
- 2)在内核中,针对每个事件:向perf缓冲区写入一条记录。如果使用了跟踪点技术(推荐方式),记录中会包含关于磁盘I/O的几个元数据字段。
- 3)在用户空间:周期性地将所有事件的缓冲区内容复制到用户空间。
- 4)在用户空间:遍历每个事件,解析字节字段的事件元数据字段。其他字段会被忽略。
- 5)在用户空间:生成字节字段的直方图摘要。
其中 步骤2到步骤4对于高IO的系统来说性能开销非常大。可以想象一下,将10 000个磁盘IO跟踪记录复制到用户空间程序中,然后解析以生成摘要信息——每秒执行 1次。使用BPF后,bitesize程序执行的步骤如下。
- 1)在内核中:启用磁盘I/O事件的插桩观测,并挂载一个由bitesize工具定义的BPF程序。
- 2)在内核中,对每次事件:运行BPF程序。它只获取字节字段,并将其保存到自定义的BPF直方图映射数据结构中。
- 3)在用户空间:一次性读取BPF直方图映射表并输出结果。
这个过程避免了将事件复制到用户空间并再次对其处理的成本,也避免了对未使用的元数据字段的复制。如前面的程序输出截图所示,唯一需要复制到用户空间的数据是“count” 列,其是一个数字数组。
2.3.2 BPF 与 内核模块 的对比
probes n.探针
还有一种方法可以理解BPF在可观测性方面的优势:将其与内核模块进行比较。kprobes和跟踪点已经出现多年了,可以直接从可加载的内核模块中使用。与使用内核模块相比,使用BPF进行跟踪的优势如下:
- BPF程序会通过验证器的安全性检查;内核模块则可能会引入bug (内核崩溃)或安全漏洞。
- BPF通过映射提供丰富的数据结构支持。
- BPF程序可以一次编译,然后在任何地方运行,因为BPF指令集、映射表结构、辅助函数和相关基础设施属于稳定的ABI。(当然,有些BPF程序包含了不稳定的因素,比如使用了kprobes来观测内核数据结构,这会影响BPF程序的自身稳定性:关于解决方案,请参见后面2.3.10节的内容。)
- BPF程序的编译不依赖内核编译过程的中间结果。
- 与开发内核模块所需的工程量相比,BPF编程更加易学,可以让更多人上手。
请注意,在网络领域应用BPF还有额外的好处,包括原子性替换BPF程序的能力。如果使用内核模块,则需要先从内核中将其完全卸载,然后再次加载,这可能会导致相关服务中断。
使用内核模块的一个好处是:在模块中可以使用其他内核函数和内核设施,而不仅限于BPF提供的辅助函数。不过,如果调用任意内核函数的能力被滥用,也会带来引入bug的额外风险。
2.3.3 编写BPF程序
BPF程序可以直接使用BPF指令编写,也可以借助前端工具LLVM、BCC、bpfrace,使用高级语言C语言、python编写。
有很多前端工具可以用来支持BPF编程。在跟踪观测方面,主要的前端按照开发语言从低级到高级排列如下:
- LLVM
- BCC
- bpftrace
LLVM编译器支持将BPF作为编译目标体系结构。BPF程序可以使用LLVM支持的更高级语言编写,比如C语言(借助Clang)或LLVM中间表示形式( IntermediateRepresentation),然后再编译成BPF。LLVM自带一个优化器,可以对它生成的BPF指令进行效率和体积上的优化。
虽然使用LLVM中间表示形式开发BPF已经是一个改进,但切换到BCC或bpftrace,体验会更好。BCC允许用C语言来编写BPF程序,bpftrace 则提供了自己的高级语言。在内部实现上,它们都使用LLVM中间表示形式和一个LLVM库来实现BPF的编译。
本书中的性能工具是使用BCC和bpfrace开发的。直接利用BPF指令编程,还是采用LLVM中间表示形式编程,是BCC和bpftrace内部组件开发人员关心的事情,这已经超出了本书的范围。对于只是使用和开发BPF性能工具的人来说,这不是必须了解的内容。如果你想成为BPF指令的开发人员,或者对此具有强烈的好奇心,那么可以去阅读下面这些资源。
附录E提供了BPF指令集和宏的简要信息:
- 在Linux源代码中有BPF指令的相关文档,位置在Documentation/networking/filtertxt"。
- LLVM IR的相关文档可以看在线的LLVM参考手册;可以从ll:RBuilderBase类的相关部分08]开始了解。
- Cilium BPF和XDP参考指南
虽然大多数人永远不会直接通过BPF指令编程,但不少人在使用工具遇到问题时,会有查看相关指令的需求。接下来的两小节会展示一些例子,分别使用了bpftool(8) 和bpftrace.
2.3.4使用 BPF查看指令集: bpftool
Linux 4.15中添加了bpftool(8) 这个工具,可用来查看和操作BPF对象,包括BPF程序和对应的映射表。它的源代码位于Linux源代码的tools/bpf/bpftool中。在本节中,我们将了解如何使用bpftool(8)来展示加载的BPF程序并打印它们的指令。
bpftool
bpftool的默认输出展示了它所操作的BPF( 伯克利数据包过滤器 )对象类型。比如在Linux5.2上:

上图可以位:
用法: bpftool [选项] 对象 { 命令 | help }
bpftool batch file FILE
bpftool version
对象:= { prog | map | cgroup | perf| net | feature | btf }
选项:= { {-j1–json} [{-p|–pretty}] | {-f|–bpffs} | {-m|–mapcompat} | {-n|–nomount} }
对于每一类对象,都有一个专门的帮助文档。比如,对于“prog”(程序)对象:

perf和prog子命令可以用来查找和打印跟踪程序。
这里我们不对bpfool(8)的以下功能做展开讨论:
挂载程序、向映射表中读写数据、对cgroups进行操作,以及列举BPF特性等。
bpftool perf
perf子命令显示了哪些BPF程序正在通过perf_event_open()进行挂载,这在Linux4.17以及之后属于BCC和bpfrace程序的常规动作。比如:


以上输出显示有3个不同的PID,分属不同的BPF程序:
- PID 1765是Vector BPF PMDA代理,用来做实例性能分析(细节见第17章)。
- PID 21993是bpftrace版本的biolatency(8)。 它显示使用了两个uprobes, 即bpftrace中的BEGIN和END探针,还有两个kprobes用于对块I/O的起始和结束进行插桩(第9章有这个程序的源代码)。
- PID 25440是BCC版本的biolatency(8),它正在对另一个块I/O的起始函数进行插桩。
offiset字段显示了被插桩对象的偏移量。(BPF工具经常使用动态插桩技术,在内核函数或应用函数的开始或结束位置进行插桩。)
对于bpftrace,偏移量1 781 920匹配了bpfrace二进制文件中的BEGIN_ trigger 函数,
偏移量1 781 927匹配了END_trigger 函数 (可以使用readelf -sbpftrace 来进行验证)。
prog_id是BPF的程序ID,可以使用下面的子命令进行打印。
bpftool prog show
progshow子命令会列出全部的BPF程序(不只是那些基于perf_event_open)的):

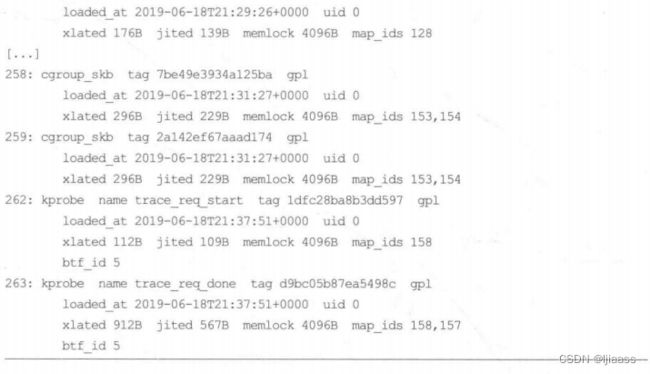
上面的输出显示了bpftrace 的程序ID (232 到235)、BCC的程序ID (262和263),以及其他加载的BPF程序。注意,BCC的kprobe程序中带有BTF (BPF Type Format)信息,这可以从上面输出显示的btf_ id看出来。2.3.9 节会更详细地介绍BTF,此刻只需知道BTF是BPF版本的调试信息(debuginfo)就可以了。
bpftool prog dump xlated
每个BPF程序都可以通过它的ID被打印(dump) 出来。xlated 模式将BPF指令翻译为汇编指令打印出来。下 面是程序234、bpftrace 块I/O完成跟踪程序的输出1:


上述输出显示了可被BPF调用的受限的内核辅助函数之一:bpf_ probe_ read()。 表2-2中列出了更多辅助函数。
现在,比较上面的输出和观测块IO完成事件的程序输出,该程序基于BTF编译,ID是263:

上面的输出包含了从BTF中获取的源代码的信息(用黑体标记)。注意,这是另外一个程序(不同的指令和调用)。
如果程序中包含了BTF信息,那么可以使用linum修饰符在输出中增加源代码文件和行信息(用黑体进行标记):
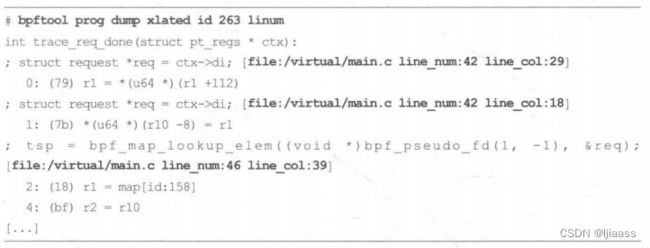
在这个例子中,代码行数信息指向了BCC在运行时动态生成的虚拟源代码文件。
使用opcodes修饰符可以在输出中包含BPF指令的opcode (用黑体标记):

BPF指令集的opcodes在附录E中有解释。
还有一个修饰符visual,可以以DOT格式输出控制流信息,支持用外部可视化软件打开。下面这个例子使用的是GraphViz软件和它的绘制有向图工具dot(1):

从生成的PNG格式的图片中可以看到指令的流向。
GraphViz提供了不同的布局工具:
笔者:通常使用dot(1)、neato(1)、 fdp(1) 以及sfdp(1) 来对DOT数据进行绘图。这些工具允许各种自定义配置(比如设定边的长度: -Elen)。图2-5展示的是使用GraphViz的osage(1)工具对BPF程序进行可视化呈现的结果。

这真是一个复杂的程序!
有一些GraphViz工具可以把代码块分散开,以避免鸟窝状的各种箭头连线,但这会使文件变得更大。如果你需要使用这样的工具来帮助阅读BPF程序,应该使用不同的工具进行实验,以确定最合适的那一个。
bpftool prog dump jited
prog dump jited 子命令显示了经过JIT编译之后的机器码。这里显示的是x86_ 64 体系结构; BPF已经支持Linux内核支持的大多数体系结构的JIT功能。下面是BCC的块IO完成跟踪程序:


和前面的例子类似,由于有BTF的支持,bpfool(8) 可以包含源代码相应行的信息;反之则不会有相关输出。
bpftool btf
bpfoo(8)可以打印BTF的ID。比如, BTF ID 5是BCC的块I/O的完成事件的输出:


上面的输出显示了BTF中包含了类型和结构体信息。
2.3.5 使用bpftrace查看BPF指令集
tcpdump(8)可以通过参数-d输出BPF指令,bpftrace 也可以通过添加-V参数达到同样目的

如果bpftrace出现了内部错误,也会输出类似的内容。如果你需要修改bpfrace内部实现,就会发现很容易和BPF验证器发生冲突,从而导致内核拒绝加载程序。每当这个时候就会出现上面的输出内容,需要研究这些内容来确定原因并修复问题。大多数人不会碰到bpfrace或者BCC的内部错误,也不会直接见到BPF指令。如果你确实遇到了此类问题,请将问题提交bpfrace和BCC项目社区,或者可以考虑直接贡献一个修复补丁。
2.3.6 BPF API
为了更好地理解BPF的能力,在这里我们列举一部分扩展版BPF的API,选自Linux 4.20内核源代码中的include/uapi/linux/bpf.h 文件。
BPF辅助函数
由于BPF不允许随意调用内核函数,为了完成某些任务,内核专门提供了BPF可以调用的辅助函数。表2-2展示了其中的一部分。


上面列出的一些辅助函数在之前的bpftool xlated命令下可以显示,bpfrace使用命令行加-v参数也行。
辅助函数中的“current”一词指的是当前正在运行的线程——也就是当前正在CPU上执行的线程。
源文件include/uapi/linux/bpf.h中一般会提供对这些辅助函数进行详解的文档。下面这段文字节选自对bpf_get_stackid() 的注释:

Linux的源代码文件可以通过一些网站在线浏览, 比如可参见链接3所指示的文件。除此之外,还有很多可用的辅助函数,大部分用于软件定义网络。当前的Linux版本(5.2) 有98个辅助函数。
bpf_probe_read()
bpf_probe_read() 是一个特别重要的辅助函数。BPF中的内存访问仅限于BPF寄存器和栈空间(以及通过辅助函数访问的BPF映射表)。如果需要访问其他内存(比如BPF之外的其他内核地址),就必须通过bpf_probe_read() 来读取。这个辅助函数会进行安全性检查并禁止缺页中断的发生,以保证在probe上下文中不会发生缺页中断(否则可能会引发内核问题)。
除了可以用来读取内核内存之外,bpf_probe_read()辅助函数还可以用来将用户空间的内容读取到内核空间中。具体的机制和具体体系结构相关:在x86_ 64上,用户空间和内核空间没有重叠部分,所以可以通过地址进行区分。对有些体系结构,如SPARC则不是如此则,BPF为了支持这些体系结构,需要借助其他辅助函数的支持,比如bpf_ probe_read_kermel()和bpf_probe_read_ user()。
BPF系统调用命令
表2-3显示了一部分用户程序可以呼叫的BPF系统调用。

表2-3中第1列的动作会作为bpf(2)系统调用的第1个参数进行传递,使用strace(1)可以看到。比如,通过下面的操作可以看到BCC版的execsnoop(8)工具用到了哪些bpf(2)系统调用:


具体的动作用黑体进行了标记。请注意,笔者通常避免直接使用strace(1),因为它当前的ptrace()实现会严重降低目标进程的运行速度——性能下降为不足原来的1%21。在这里使用它,只是因为它已经支持了bpf(2) 系统调用参数的翻译,可将一个数字翻译为一个可读的字符串(例如,BPF_PROG_LOAD)。.
BPF程序类型
不同的BPF程序类型定义了BPF程序可以挂载的事件类型,以及事件的参数。主要用于跟踪用途的BPF程序类型如表2-4所列。

之前展示的strace(1)程序的输出,包含了两个对BPF_PROG_TYPE_KPROBE 事件类型的BPF_PROG_LOAD挂载系统的调用,因为那个版本的execsnoop(8)使用了kprobe和kretprobe来对execve() 系统调用的开始和结束位置进行插桩。
在bpf.h中还有一些程序类型用于网络以及其他用途,表2-5 列举了其中的一部分。

BPF映射表类型
BPF映射表类型定义了不同类型的映射表数据结构。表2-6展示了一部分映射表类型。

之前展示的strace(1)程序的输出,包含通过BPF_ MAP_CREATE方式创建的BPF_MAP_TYPE_PERF_EVENT_ ARRAY类型的映射表数据结构。execsnoop(8) 工具使用该映射表来向用户空间传递事件用于打印。
在bpf.h中还定义了许多有专门用途的映射表类型。
2.3.7 BPF 并发控制
在Linux 5.1中增加spin lock辅助函数之前,BPF 中没有并发控制支持。(然而,目前spin lock还不能在跟踪程序中直接使用)。在进行跟踪时,并行的多个线程可能会同时对映射表数据进行查找和更新,造成一个线程破坏另一个线程的数据。这被称为“丢失的更新”问题,是由当前的读和写发生了重叠造成的。跟踪程序所使用的BCC和bpftrace前端,使用了per-CPU (每CPU)的哈希和数组映射类型,以尽可能避免冲突的问题。它们为每个逻辑CPU创建了独享的数据结构实例,避免了并行的线程对共享的位置进行更新。例如,一个对事件进行计数的映射表,可以通过对每个CPU.上的映射表数据结构进行更新,然后再将每个CPU对应的映射表中的值相加,以得到事件总数。作为一个具体的例子,这个bpftrace单行程序使用了per-CPU哈希映射来进行计数:

而下面这个bpftrace单行程序使用了普通的哈希映射来进行计数

![]()
在一个8-CPU的系统上同时运行这两个程序来跟踪一个频繁调用且可能同时运行的函数,代码如下:

通过比较两个结果可以发现,比起每个CPU设置专用映射,普通的哈希映射会丢失大约0.01%的统计值。除了每个CPU专用的映射之外,还有其他一些机制进行并发控制,包括互斥的相加操作(BPF_ XADD)、“映射中的映射”机制(可以对整个映射进行原子更新操作),以及BPF的自旋锁等机制。使用bpf_map_update_elem()对常规的哈希和LRU映射进行操作也是原子性的,不会产生写竞争。在Linux 5.1中引入的自旋锁,可以通过bpf_spin_lock() 和bpf spin_unlock()进行控制。
2.3.8 BPF sysfs接口
在Linux 4.4中,BPF引入了相关命令,可以将BPF程序和BPF映射通过虚拟文件系统显露出来,位置通常位于/sys/fs/bpf。这个能力,用术语表示为“钉住”(pinning),有多个使用场景。它允许创建持续运行的BPF程序(像daemon程序那样),即使创建程序的进程已经退出,程序仍然可以运行。这个机制还提供了用户态程序和正在运行的BPF程序交互的另一种方式:用户态程序可以读取和修改BPF映射表。
本书中的BPF跟踪工具并没有使用pinning方式,而是采用了标准的UNIX程序模型,具有开始和结束。当然,如果有需要,这些工具也可以改写为可以使用pinning的模式。这在网络互联方面的BPF程序中是很普遍的(比如Cillium软件)。
作为一个使用pinning的例子,Android操作系统使用了pinning机制自动加载和固定BPF程序,位置在/system/etc/bpf 。Android 库函数提供了和这些pinning的程序进行交互的功能。
2.3.9 BPF类型格式
本书中反复提到的一个问题是,由于缺少对被跟踪程序的源代码信息,书写BPF工具很困难。本节我们介绍一个理想的解决方案: 一种称为BTF的技术。
元数据(Metadata)是描述其它数据的数据(data about other data),或者说是用于提供某种资源的有关信息的结构数据(structured data)。
BTF (BPF Type Format, BPF 类型格式)是一个元数据的格式(描述其他数据的数据的格式),用来将BPF程序的源代码信息编码到调试信息中。调试信息包括BPF程序、映射结构等很多其他信息。一开始选BTF这个名字,是因为它描述了数据类型;不过后来它已经扩展到包含函数的信息、源代码/行信息,以及全局变量信息等。
BTF调试信息可以内嵌到vmlinux二进制文件中,或者随BPF程序一同使用原生Clang编译时生成,或者通过LLVM JIT生成。这样BPF程序就更容易被加载器( 例如,libbpf)或者工具( 例如,bpftool) 所使用。检测和跟踪工具,包括bpfoo(8)和perf(1),可以获取这些信息,以得到源代码标记的BPF程序,或者可以基于它们的C结构表示美观地打印映射表的键/值,而不需要使用裸十六进制形式打印(应该就是可以用十进制这样自然习惯的形式打印)。之前使用bpfool(8)打印一个使用了LLVM-9编译后的BCC程序的例子演示了这一点。
除了描述BPF程序之外,BTF正在成为一个通用的、用来描述所有内核数据结构的格式。在某些方面,它正在成为内核的调试信息文件的一种轻量级替代方案,而且比使用内核头文件更加完整和可靠。
BPF跟踪工具通常需要在机器上安装内核头文件(一般是通过linux-headers包),这样才可以访问各种C结构。这些头文件有时没有包含全部的内核结构定义,对有些BPF跟踪工具来说还是有困难的:作为一个临时解决方案,可以在BPF工具中重新定义
这些结构体。有的时候过于复杂的头文件无法正确被处理;bpfrace在遇到这种情况时,可能会选择直接终止,而不会带着错误数据结构继续运行。BTF可以通过提供对所有数据结构的准确定义来解决这些问题。(之前的bpftool btf输出展示了task结构体是如何被显示的。)在未来,一个带着BTF信息的Linux内核vmlinux二进制文件,将会是自描述的。
程序是自描述的:通俗点的说就是你写的程序符合编程习惯,不起奇奇怪怪的变量名,系统的功能一目了然。
在本书编写过程中,BTF 仍在开发过程中。为了支持“一次编译,到处执行”这个特性,正在向BTF中加入更多的信息。关于最新的BTF相关的信息,请看内核源文件的Docunmentip/bp/bt.st2s.
2.3.10 BPF CO-RE
BPF的“一次编译,到处执行”(Compile Once - Run Everywhere, CO-RE) 项目,旨在支持将BPF程序一次性编译为字节码,保存后分发至其他机器执行。这样可以避免要求运行环境安装BPF编译器(LLVM和Clang),这对于空间本来就紧张的嵌入式
Linux尤为关键。在BPF性能观测工具运行时,还能将编译所需的CPU和内存资源节省出来。
CO-RE项目和其开发者Andri Nakryiko,正在努力解决一些技术挑战, 例如,在不同系统中内核数据结构的偏移量不同,要根据需要对BPF代码中的访问偏移量进行重写。另一个挑战是不可见的数据结构成员,这需要根据不同的内核版本、内核配置选项信息,以及用户提供的运行时信息来动态调整访问。CO-RE项目也会使用BTF信息,在本书编写时仍处于开发阶段。
2.3.11 BPF的局限性
BPF程序不能随意调用内核函数:只能调用在API中定义的BPF辅助函数。在后续版本中随着需求的增加,在API中会加入更多的辅助函数。BPF程序在执行循环时也有限制:允许BPF在一个无限循环插入kprobes是不安全的,因为这些线程可能还持有重要的锁,从而导致整个系统死锁。解决方法包括循环展开,以及在使用循环的通用场景中增加特定的辅助函数等。Linux 5.3内核支持BPF受限循环,该循环的上限可以通过验证器验证。
BPF栈的大小设定为不能超过MAX_ BPF_ STACK,值为512。这个限制在编写BPF观测工具时会碰到,尤其是在往栈上存放多个字符缓冲区时:一个char[256]缓存就可以消耗一半的栈空间。目前并没有增大这个限制的计划。解决方法是使用BPF映射
存储空间,映射存储空间是有大小限制的。在bpfrace项目中,将字符串的存储位置从栈空间转移到映射的工作已经开始。
BPF程序的总指令的数量,最初限制为4096。长的BPF程序有时会碰到这个限制(如果没有LLVM的编译优化,可能会更早碰到这个限制)。Linux 5.2 内核极大地提升了这个值的上限,使得它不再是一个需要考虑的问题。BPF验证器的作用是接受一切安全的程序,指令数量限制不应该成为问题。
2.3.12 BPF 扩展阅读资料
为了更好地理解BPF,下面提供了更多的BPF信息源:
- 内核 代码的Documentation/networking/filter.txt 文件。
- 内核代码的Documentation/bpf/bpf_design_QA.txt 文件
- bpf(2)man 帮助文档。
- bpf-helper(7)man帮助文档。
- “BPF: the universal in-kernel virtual machine", 作者为Jonathan Corbet。
- “BPF internals- II”, 作者为Suchakra Sharma。
- Cilium项目的“BPF and XDP Reference Guide" 。
- 本书第4章和附录C、D、E中提供了更多的BPF程序的例子。
2.4 调用栈回溯
调用栈是一个非常有价值的工具,它用于理解导致某事件产生的代码路径,也可以用于剖析内核和用户代码,以观测代码执行开销的具体产生位置。BPF提供了存储调用栈信息的专用映射表数据结构,可以保存基于帧指针或基于ORC的调用栈回溯信息。BPF将来也许还会支持其他调用栈回溯技术。
2.4.1基 于帧指针的调用栈回溯
帧指针技术依赖的是以下惯例:
函数调用栈帧链表的头部,始终保存于某个寄存器中(在x86_64体系结构中这个寄存器是RBP),
并且函数调用的返回地址永远位于RBP的值指向的位置加上一个固定偏移量(+8)。
这意味着任何调试器或跟踪器都可以在中断程序执行后,通过读取RBP后遍历以RBP的值为头部的链表,同时在固定偏移位置获取返回地址,从而轻松地进行栈回溯。具体过程如图2-6所示。

AMD64ABI中提到,RBP作为帧指针寄存器来使用是一种惯常做法,而非强制要求。为了节省函数前言(prologue) 和结语(epilogue) 的指令数量,也可以不将RBP用作帧指针寄存器,而是将其作为通用寄存器来使用。
目前,gcc编译器默认不启用函数帧指针,而将RBP作为通用寄存器来使用,这样就无法基于帧指针进行栈回溯。不过我们可以通过使用gcc的命令行参数-fno-omit-frame-pointer来改变这个默认行为。至于为什么gcc的默认行为是不启用帧指针,可以参考当时引入这个特性的补丁中的解释:
- 首先,补丁是为 i386而引入的,由于i386只有4个通用寄存器,将RBP释放出来后,使可用的寄存器数目提高至5个,这会带来明显的性能提升。然而对于x86_64来说,因为其本来就有16个寄存器了,这个改动的收益并不那么明显(35。
- 该补丁认为栈回溯有其他的解决办法,gdb(1)提供了其他的解决方案。不过这没有考虑到我们在跟踪过程中需要进行的栈回溯需求。因为在程序跟踪过程中,通常是无法使用中断的,也没有其他的上下文信息可以利用。
- gcc需要和Intel的icc编译器进行性能比拼。
今天在x86_64 体系结构上,大多数软件在编译时采用了gcc的默认选项,由此也导致了基于帧指针的调用栈不可用。笔者实际测量了生产环境下不使用帧指针带来的性能提升往往不足百分之一,而且很多时候由于这个值太接近0而无法精确测量。Netlix公司运行的很多微服务都特意开启了帧指针,支持CPU剖析得到的性能优化提升潜力,远远超过了启用帧指针所带来的小小性能损失。
帧指针并不是进行栈回溯的唯一方法, 还可以使用调试信息(debuginfo)、LBR以及ORC。
2.4.2调试信息
软件的额外调试信息以软件的调试信息包(debuginfopackage)的形式提供,这其中包含了DWARF格式的ELF调试信息。ELF调试信息中包含了供gdb(1)这样的调试器来做调用栈的文件段信息,这样即使没有启用帧指针寄存器也可以进行栈回溯。ELF中的调试相关文件段是.eh_ frame 和.debug_ frame。
调试信息文件中的某些段也包含程序的源代码和行号信息,这样往往会导致文件的调试信息尺寸远远大于被调试的原始二进制文件的尺寸,这就是为什么调试信息文件格式称为DWARF的原因。第12章有这样一个例子: libjvm.so 文件只有17 MB,而其调试信息文件则高达222 MB。在一些环境中,调试信息文件由于体积过大而不会被默认安装。BPF目前还不支持这种栈回溯技术,因为这种技术太耗费处理器资源,而且需要读取可能并没有加载到内存中的ELF段信息。这使得在禁用中断的受限BPF上下文中实现相关支持几乎不可能。
不过请注意,BPF的前端——BCC 和bpfrace是支持使用调试信息文件进行符号解析的。
2.4.3最后分支记录
最后分支记录(Last Branch Record, LBR)是Intel处理器的一项特性:程序分支, 包括函数调用分支信息,被记录在硬件缓冲区中。这项技术没有额外开销,可以用来进行调用栈重组。但是,支持记录的深度有限制,根据处理器型号不同,可以记录的分支数量在4到32个之间。生产环境中软件的栈回溯深度可能会超过32帧,特别是Java。目前BPF并不支持LBR,不过未来可能会增加支持。有限的栈信息也比完全没有好!
2.4.4 ORC
针对栈回溯需求专门设计了一种新的调试信息格式——Oops 回滚能力(OopsRewind Capability, ORC)。 相比DWARF格式,使用这种格式对处理器要求较低。ORC使用名为.orc_unwind 和.orc_unwind_ip 的ELF文件段,目前Linux内核已经实现了相关支持。在寄存器数量受限的体系结构上,有人可能希望在不开启帧指针的情况下编译内核,然后用ORC技术进行栈回溯。
在内核中基于ORC的调用栈回溯可以通过perf_callchain_kernel()函数支持,BPF可以调用该函数,这意味着BPF也支持基于ORC的调用栈。目前还没有开发用户态对ORC调用栈的支持。
2.4.5符号
调用栈信息目前在内核中是以地址数组形式记录的,这些地址可以通过用户态的程序翻译为符号(比如函数的名字)。在收集和翻译两个操作之间,符号映射表可能发生变化,这会导致翻译无效或有些符号信息丢失。这个问题将在12.3.4节中进行详细讨论。未来可能的工作包括在内核中支持符号翻译,这样内核就可以在收集完调用栈信息后立即进行符号翻译了。
2.4.6 扩展阅读
关于调用栈和帧指针,第12章会针对C语言和Java语言进行进一一步讨论:第18章也会提供一个概括摘要。
2.5 火焰图
好好看看下列两图:

在本书后面的章节中会经常使用到火焰图,所以本节将概括介绍如何使用和阅读火焰图。
火焰图是笔者(Brendan Gregg )在研究MySQL性能问题时发明的调用栈的可视化方法。当时笔者需要直观地比较两个长达数千页的文本格式的CPU性能剖析文件。除了用于CPU性能剖析之外,火焰图还可以用来可视化来自任何剖析器或跟踪器所记录的调用栈信息。在本书的后面部分,笔者会展示火焰图如何应用于off-CPU事件和页错误等场景的BPF跟踪。本节先讲述可视化相关内容。
2.5.1 调用栈信息
调用栈信息,也称为栈回溯跟踪或调用跟踪信息,是一串展示了代码流向的函数名字。
例如,如果func_a()调用了func_b(),后者又调用了func_c(),那么那里的调用栈信息可以写成:

栈的底部( func_a)是起点,它之上的行显示了代码流向。换句话说,栈的顶部( func_c)是当前函数,向下移动则显示了它的派生关系:先是父亲函数,然后是祖父函数,依此类推。
2.5.2对调用栈信息的剖析
以定时采样方式收集调用栈信息,一.般会收集数千个调用栈信息,每个调用栈都有几十或几百行那么长。
为了使这样体量的数据易于分析的做法:
- Linux 的perf(1)剖析器将其样本摘要为调用树格式,显示每个分支所占的百分比。
- BCC的profile(8)工具则采用了另外一种摘要方式:对每个独特的调用栈分别计数。
第6章中有perf(1)和profile(8)的真实使用案例。使用这两种工具时,如果有某个调用栈占用大量CPU运行时间,那么此类问题可以很快被识别出来。不过对于许多其他分析场景,包括一些微小的性能回归测试,定位“罪魁祸首”可能需要研究数百页的剖析器输出。火焰图就是为了解决这个问题而创建的。
要理解火焰图,请考虑以下这个人为制作的CPU剖析器的输出,它展示了每个调用栈的频率计数:

上述输出显示了一个调用栈和对应的累计数,总计10个样本。举例来说,func_a()——>func_b()——>fun_c()这个代码路径有7次采样。这个代码路径显示了func_c() 正在CPU上运行。而func_ a()——> fiunc_b()(这个代码路径,即func_b()正在CPU上运行,被采样了2次。然后一个以func_e()结束的调用栈被采样了1次。
2.5.3火焰图
图2-7展示了基于前面的剖析文件所生成的火焰图。

火焰图具备以下特点:
- 每个方块代表了调用栈中的一个函数(一个“栈帧”)。
- Y轴显示了栈的深度(栈中帧的数量),顺序是底部代表根,顶部代表叶子。从下往上看时,展示的是代码执行的方向;从上往下看时,则看到的是函数的调用层次关系。
- X轴包括了全部的采样样本的数量。要注意的一点是,和一般的图不同,火焰图从左到右并不代表时间流动的方向。火焰图从左到右只是按照字母顺序排列,目的是将位于栈中同一层的函数最大化地合并。和Y轴的函数栈帧一起看,图的原点在左下方(和一般的图一样),表示[0,a]区间。 X轴上方块的长度确实也有它的意义:方块的长度表示了该函数在剖析文件中出现次数的比重。较长的方块所对应的函数比较短的方块所对应的函数在采样样本中出现的次数多。
火焰图实际上是一个反转的冰柱布局图(icicle layout) [Bostock 10],这种布局图可用于对一组栈的调用关系进行可视化。
在图2-7中,出现频次最高的栈以中间最宽的“塔”的形式呈现:从func_ a( 调用到func_cO)。由于这是一张CPU火焰图,我们可以说顶部的方块就是此刻运行在CPU上的函数。这部分在图2-8中用黑色粗线强调了。

从图2-8中可以看到,函数func_c() 在CPU上运行占据了70%左右的时间,func_b()的占比为20%,func_e() 的占比为10%。另外两个函数func_a()和func_d(),没有直接运行的采样。
阅读一张火焰图,应该先找到最宽的部分并去理解它。
对于一个有几千个采样的大剖析文件,可能会有一些代码路径只被采样了几次,在火焰图.上它就会很窄,窄到无法显示出函数的名字。不过这事实上是一个优点:你的注意力会被更宽的、有名字的“塔”所吸引,看到它们有助于先去理解剖析文件中的大块部分。
2.5.4火焰图的特性
笔者最初设计的火焰图所支持的特性如下。
1)调色板
火焰图可以使用不同的着色方案。默认使用随机的暖色调对函数栈帧进行着色,这有助于从视觉上区分相邻的塔。多年来,笔者又不断增加了更多的着色方案。笔者发现,以下几个方面对于火焰图的使用者来说是十分有用的。
-
色调(Hue): 以色调表明代码类型。例如,红色代表原生用户态代码,橙色用来展示内核态代码,黄色用于C++,绿色用于解释运行的函数,浅绿色用于表示内联函数,依此类推,具体颜色取决于所使用的语言。洋红色用于高亮显示搜索命中。有的开发者对火焰图进行了定制,让火焰图以一定的颜色永远高亮他们自己的代码,以便能够快速定位。
-
饱和度(Saturation):饱和度由函数名的哈希值决定 。这样做可以在不同的高塔之间提供一些颜色区分度,同时又可以在不同的火焰图中针对同一-类函数使用同样的颜色,以便对比。
-
背景颜色(Background color):背景颜色提供了对火焰图类型的提示。比如,可以使用黄色作为CPU火焰图,蓝色作为off-CPU或者I/O火焰图,绿色作为内存火焰图。
另一个有用的着色方案用在了IPC (每个时钟周期中的指令数,instructions per cycle)火焰图中。那里使用了从蓝到白再到红的渐变颜色这种视觉效果,以表示IPC这个额外的维度。
2)鼠标悬浮
原始的火焰图软件生成的SVG文件内置了JavaScript, 可以被加载到浏览器中,用于实现实时交互。其中的一个特性是,当鼠标指针移动到相应的栈帧上时,会有一行信息显示出来,表明该栈帧在整个剖析文件中所占的比例。
3)缩放
可以单击栈帧实现横向缩放”。这可将较窄的栈帧展开放大,这样就能看到它们的名字。
4)搜索
使用搜索按钮,或者按Ctrl+F组合键,允许输入搜索关键词,命中的栈帧会以洋红色高亮显示出来,同时显示搜索命中结果在所有堆栈中所占的百分比。这就使得计算特定代码区域在整个文件中所占的比例十分容易。举一个例子,你可以搜索“tcp_ ”来看到内核中tcp代码所占的比例。
2.5.5火焰图的变体
Nettlix公司内部开发了一个基于d3的更具交互性的火焰图。该程序已经开源,被包含在Netlix公司的FlameScope软件中。

有些火焰图的实现将Y轴的方向进行了反转,生成了一个“冰柱图”,就是调用栈的根在顶部。如果有特别深的调用栈超过了屏幕的高度时,这个反转能确保调用栈的根部和其相邻的部分打开时直接可见。笔者的火焰图软件也提供了命令行选项–inverted来支持这个反转功能。笔者本人倾向于使用另外一种“冰柱图”的反转模式,这也是火焰图的另一个变体:在合并相邻函数时,先合并调用栈的叶子节点,然后再合并根节点。这适用于以下场景:首先从运行在CPU上的常见函数开始合并,然后再看它们的调用来源,比如在调试spin locks问题的时候尤其合适。
火焰时序图(flame charts) 受到火焰图启发,与火焰图类似(iookl),不过X轴代表了时间的流向,而不是字母顺序。火焰时序图在Web浏览器的分析工具中很流行,它可以用来观测JavaScripts行为,很适合帮助理解单线程应用中基于时间的模式。有些剖析工具同时支持火焰图和火焰时序图。
差分火焰图(differential flame graph)可以用来对比两个跟踪结果的不同。
2.6 事件源
2.6 事件源
图2.9展示了可以被跟踪的事件源和一些例子。这幅图还显示了这些事件在Linux内核中的BPF绑定点。
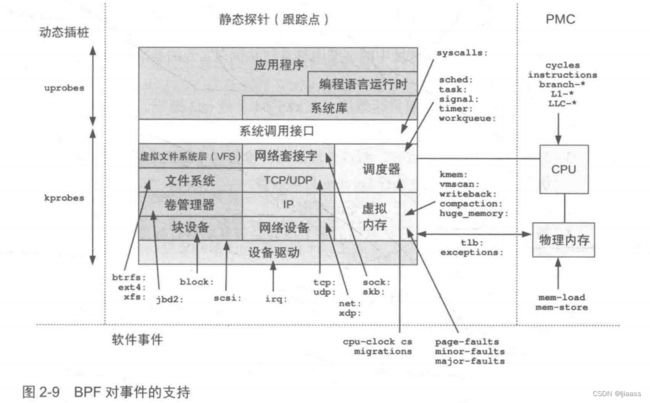
接下来的部分会对这些事件源进行分别解释。
2.7 kprobes提供了针对内核的动态插桩支持。
2000 年IBM公司的一个团队,基于他们的DProbes跟踪器开发了这项技术。然而,最终进入Linux内核的是kprobes而非DProbes。2004 年,kprobes 正式加入Linux内核2.6.9版本。
kprobes可以对任何内核函数进行插桩,它还可以对函数内部的指令进行插桩。它可以实时在生产环境系统中启用,不需要重启系统,也不需要以特殊方式重启内核。这是一项令人惊叹的能力,这意味着我们可以对Linux中数以万计的内核函数任意插桩,根据需要生成指标。
kprobes技术还有另外一个接口,即kretprobes,用来对内核函数返回时进行插桩以获取返回值。当用kprobes和kretprobes对同一个函数进行插桩时,可以使用时间戳来记录函数执行的时长。这在性能分析中是一个重要的指标。
2.7.1 kprobes 是如何工作的
使用kprobes对内核函数进行动态插桩的过程如下。
-
A.对于一个kprobe插桩来说:
1.将在要插桩的目标地址中的字节内容复制并保存(为的是给单步断点指令腾出位置)。
2.以单步中断指令覆盖目标地址:在x86_ 64上是int3指令。(如果kprobes开启了优化,则使用jmp指令。)
3.当指令流执行到断点时,断点处理函数会检查这个断点是否是由kprobes注册的,如果是,就会执行kprobes处理函数。
4.原始的指令会接着执行,指令流继续。
5.当不再需要kprobes时,原始的字节内容会被复制回目标地址上,这样这些指令就回到了它们的初始状态。 -
B.如果这个kprobe是一个Ftrace 已经做过插桩的地址(一般位于函数入口处),那么可以基于Ftrace进行kprobe优化,过程如下:
1.将一个Ftracek probe处理函数注册为对应函数的Ftrace处理器。
2.当在函数起始处执行内建入口函数时(x86 架构上的gcc4.6是__fentry__ ),该函数会调用Ftrace,Ftrace 接下来会调用kprobe处理函数。
3.当kprobe不再被使用时,从Ftrace中移除Ftrace-kprobe处理函数。 -
C.如果是一个kretprobe :
1.对函数入口进行kprobe插桩。
2.当函数入口被kprobe命中时,将返回地址保存并替换为一个“蹦床”(trampoline)函数地址。
3.当函数最终返回时(ret 指令),CPU将控制交给蹦床函数处理。
4.在kretprobe处理完成之后再返回到之前保存的地址。
5.当不再需要kretprobe时,函数入口的kprobe就被移除了。
根据当前系统的体系结构和一些其他因素,kprobe的处理过程可能需要禁止抢占或禁止中断。
在线修改内核函数体的内容,听起来是风险极大的操作,但是kprobes 从设计上已经保证了自身的安全性。在设计中包括了一个不允许kprobes动态插桩的函数黑名单,kprobes函数自身就在名单之列,可防止出现递归陷阱的情形。
断点,调试器的功能之一,可以让程序中断在需要的地方,从而方便其分析。
kprobes同时利用的是安全的断点插入技术,比如使用x86内置的int3指令。当使用jmp指令时,也会先调用stop_machine()函数,来保证在修改代码的时候其他CPU核心不会执行指令。在实践中,最大的风险是,在需要对一个执行频率非常高的函数进行插桩时,每次对函数调用的小的开销都将叠加,这会对系统产生一定的性能影响。
kprobes在某些ARM 64位系统上不能正常工作,出于安全性的考虑,这些平台上的内核代码区不允许被修改。
2.7.2 kprobes 接口
最初使用kprobes技术时需要先写一个内核模块,通常用C语言来书写入口处理函数和返回处理函数,再通过调用register_kprobe() 来注册。接下来需要加载该内核模块,使用printk()输出一些定制化的信息。当一切工作完成后,再调用unregister_kprobe() 作为结束。
除了2010年在安全电子杂志Phrack上看到过自称为EIfMaster的研究员写的一篇文章“Kermel Instrumentation using kprobes" 外,笔者没有见过有人直接使用kprobes 接口。这也许不应该视作kprobes的失败,毕竟它从一开始的定位就是通过Dprobes来使用,而不是直接使用的。现在有以下三种接口可访问kprobes。
- kprobe API:如register_kprobe() 等。
- 基于Ftrace的,通过/sys/kerme/debug/tracing/kprobe_ events: 通过向这个文件写入字符串,可以配置开启和停止kprobes。
- perf_event_open(): 与per(1)工具所使用的一样,近来BPF跟踪工具也开始使用这些函数。在Linux内核4.17中加入了相关支持(perf_ kprobe pmu)。
最主要的使用方法还是借助前端跟踪器,包括perf(1)、SystemTap,以及BPF跟踪器,如BCC和bpftrace。
kprobes原先的实现还包含一个变体,名为jprobes,也是用来在内核函数的入口处进行插桩,这个接口并不是必需的。2018 年,kprobes 的维护者Masami Hiramatsu将它从内核中移除了。
2.7.3 BPF 和kprobes
kprobes向BCC和bpftrace提供了内核动态插桩的机制,在很多工具中都用到了它。相关接口如下所示。
- BCC : attach_ kprobe() 和attach_ kretprobe()。
- bpftrace : kprobe和kretprobe探针类型。
BCC的kprobes接口可以用来对函数的开始或某一偏移量位置进行插桩,而目前bpfrace只支持在函数入口位置插桩。kretprobes接口对两个跟踪器都是在函数返回处进行动态插桩。
举一个BCC的例子: vfsstat(8)工具对VFS接口中的一些关键调用进行了插桩,每秒打印概要信息:
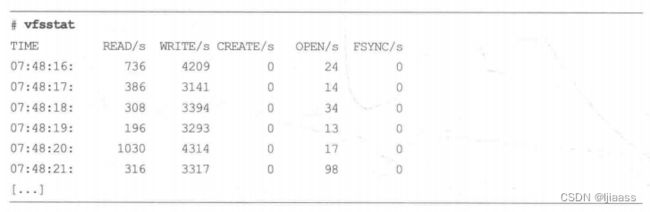
在vfsstat的源代码文件中,能看到kprobe跟踪了哪些函数:

这里使用了attach_kprobe0函数进行插桩操作,具体插桩的内核函数是参数“event=”后面的值。
再举一个bpfrace的例子,这个单行程序通过匹配“vfs_ ”开头的函数,统计了所有VFS函数的调用次数:


上面的输出显示,在上述命令执行期间,vfs_unlink()函数被调用了2次,而vfs_read()函数被调用了5581次。
从内核中统计任意函数的调用次数是个非常有用的一特性,可以对内核子系统的业务负载进行定性分析。
2.7.4关 于kprobes的更多内容
可以通过下面的资料更深入地理解kprobes:
- Linux 内核源代码下的Documentation/kprobes.txt文件。
- “An introduction to kprobes",作者为Sudhanshu Goswami。
- “Kernel Debugging with kprobes",作者为Prasanna Panchamukhil。
2.8 uprobes提供了用户态程序的动态插桩。
相关工作在很多年前就开始了,其utrace接口和kprobes接口十分类似。uprobes最终于2012年7月被合并到Linux 3.5内核中uprobes与kprobes类似,只是在用户态程序使用。uprobes可以在用户态程序的以下位置进行插桩:函数入口、特定偏移处,以及函数返回处。
uprobes也是基于文件的,当一个可执行文件中的 一个函数被跟踪时,所有使用到这个文件的进程都会被插桩,包括那些尚未启动的进程。这样就可以在全系统范围内跟踪系统库调用。
2.8.1 uprobes 是如何工作的
uprobes的工作方式和kprobes类似:将一个快速断点指令插入目标指令处,该指令将执行转交给uprobes处理函数。当不再需要uprobes时,目标指令会恢复成原来的样子。对于uretprobes,也是在函数入口处使用uprobe进行插桩,而在函数返回之前,则使用一个蹦床函数对返回地址进行劫持(强行占有),和kprobes类似。
可以使用调试器看到这个行为。比如,从bash(1)中反汇编readline()函数:

接下来使用uprobes (或者uretprobes) 进行插桩:
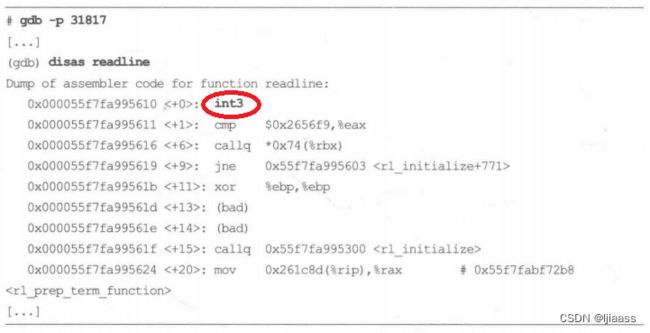
注意,第一个指令已经被替换成int3单步中断。
笔者使用一个bpftrace单行程序来对readline()进行插桩:
![]()

这个程序对当前正在运行的,以及后续会运行的bashshell的readine()进行跟踪。打印出统计计数,在按Ctrl+C组合键时退出。当bpftrace停止运行时,uprobe 会被移除,原始的指令被恢复回去。
2.8.2 uprobes 接口
uprobes有以下两个可使用的接口。
- 基于Ftrace的,通过/sys/kernel/debug/tracing/uprobe_events: 可以通过向这个配置文件中写入特定字符串打开或者关闭uprobes。
- perf_event_open():和perf(1)工具的用法一样, 而且最近BPF跟踪工具也开始频繁这样使用了。相关支持已经加入内核4.17版本内核(per_uprobe pmu)。
在内核中同时包含了register_uprobe_event()函数,和register_kprobe() 类似,但是并没有以API形式显露。
2.8.3 BPF 与uprobes
uprobes为BCC和bpftrace提供了用户态程序的动态插桩支持,这在很多个工具中都有使用。接口包括如下两个。
- BCC : attach_uprobe()和attach_uretprobe()。
- Bpftrace : uprobe和uretprobe探针类型。
BCC中的uprobes接口支持对函数入口处的插桩,也支持任意地址的插桩,而bpftrace则仅支持函数入口处的插桩。两个跟踪器都仅支持uretprobe进行函数返回处插桩。从BCC中选取一个例子:gethostlatency(8)工具利用对库函数getaddrinfo(3)和gethostbyname(3)的插桩对主机名解析(DNS)访问进行跟踪:

被跟踪的函数可以通过源代码看到:
grep attach_ gethostlatency.py #查找文件gethostlatency.py中,有attach_的内容,并打印。

这里我们能看到attach_uprobe() 和attach_uretprobe() 调用。用户态函数可以在“sym='之后看到。
作为一个bpftrace的例子,这些单行程序列出并统计了libe 系统库中gethost函数的调用次数:
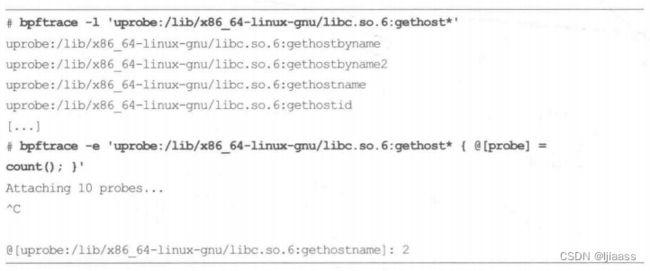
输出显示了gethostname(函数在跟踪过程中被调用了两次。
2.8.4 uprobes 的开销和未来的工作
uprobes可能会被挂载到每秒执行数百万次的事件上,比如用户态的内存分配函数:malloc0和free()。尽管BPF已经经过性能调优,但任何小的开销乘以百万次这个量级都会把开销放大。在某些情况下,对malloc()和free()的跟踪,本来应该是BPF的典型应用场景,但会导致目标应用程序10倍以上的性能损耗。这就影响了BPF的可用性。这种程度的性能损耗只能应用于测试环境中的故障排查过程,或者只能用于已经出现问题的生产环境中。第18章中包含了一节,专门讨论针对这些局限性的解决方案。简单来说,在跟踪时,要知道哪些事件是高频事件,尽量避免跟踪这些事件,尝试针对你的问题找一些低频事件来跟踪。
未来,肯定会出现用户态的跟踪的大幅性能改进——下次你再来读本书的时候,肯定已经有所改进。现在正在讨论使用共享库来替换目前的、需要往返内核的uprobes实现,这样可以使BPF跟踪完全在用户态内进行。这项技术已经被LTTng-UST使用几年了,性能与目前的实现相比快10到100倍。
2.8.5 扩展阅读
关于uprobes的更多信息,可以参考Linux源代码的Docurmentaton/trace/uprobetracer.txt文件。
2.9 跟踪点:可以用来对内核进行静态插桩。
跟踪点(tracepoints)可以用来对内核进行静态插桩。内核开发者在内核函数中的特定逻辑位置处,有意放置了这些插桩点;然后这些跟踪点会被编译到内核的二进制文件中。
2007年,Mathieu Desnoyers开发了跟踪点实现,最初被称为内核标记(Kernel Markers),并且正式出现在2009年发布的Linux 2.6.32 内核中。表2-7对kprobes和跟踪点进行了比较。

对内核开发者来说,跟踪点有一定的维护成本,而且它的使用范围比kprobes要窄得多。使用跟踪点的主要优势是它的API比较稳定:基于跟踪点的工具,在内核版本升级后一般仍然可以正常工作。而基于kprobes的工具在内核版本升级时,如果被跟踪的函数被重命名或者功能改变,则会导致其不可用。
如果条件允许,你应当优先尝试使用跟踪点,只有在条件不满足时才使用kprobes作为替代。
跟踪点的格式是“子系统:事件名”(subsystem:eventname,如kmem:kmalloc) 。对于格式中的前半部分,不同跟踪工具有不同的叫法:系统、子系统、类、提供商等。
2.9.1如何添加跟踪点
作为一个例子,本节来看一下sched:sched_ process_ exec 是如何被加入内核的。在内核源代码目录树include/trace/events下有跟踪点相关的头文件。以下代码片段截取自sched.h:

这段代码将跟踪点系统名定义为sched,还定义了跟踪点的名字: sched_ process_exec。之后的代码定义了元数据信息,包括TP_ printk()中的 “格式字符串”(formatstring):这样当用perf(1)记录跟踪点时可以打印出有意义的摘要信息。
上面代码中的信息也会在运行时通过/sys目录下的Ftrace框架显露出来,对于每一个跟踪点会有一个对应的格式文件。例如:
![]()

各种跟踪器使用此格式文件来理解跟踪点上绑定的元数据信息。
下面这个跟踪点是在内核源代码fs/exc.c 中通过trace_sched_process_exec()调用的:

trace_ sched_ process _exec() 函数标记了跟踪点的位置。
2.9.2跟踪点的工作原理
跟踪点处于不启用状态时,性能开销要尽可能小,这是为了避免对不使用的东西“交性能税”。Mathieu Desnoyers使用了一项叫作 “静态跳转补丁”(static jump patching)的技术。这项技术是这样工作的,它依赖编译器支持–个编译选项,具体如下所述。
-
1.在内核编译阶段会在跟踪点位置插入一条不做任何具体工作的指令。在x86_64架构上,这是一个5字节的nop指令。个长度的选择是为了确保之后可以将它替换为一一个5字节的jump指令。
-
2.在函数尾部会插入一个跟踪点处理函数,也叫作蹦床函数。这个函数会遍历一个存储跟踪点探针回调函数的数组。这样做会导致函数编译结果稍稍变大。(之所以称之为蹦床函数,是因为在执行过程中函数会跳入,然后再跳出这个处理函数),这有可能对指令缓存有一些小影响。
-
3.在执行过程中,当某个跟踪器启用跟踪点时(该跟踪点可能已经被其他跟踪器所启用):
a.在跟踪点回调函数数组中插入一条新的跟踪器回调函数,以RCU形式进行同步更新。
b.如果之前跟踪点处于禁用状态,nop指令的地址会重写为跳转到蹦床函数的指令。 -
4.当跟踪器禁用某个跟踪点时:
a.在跟踪点回调函数数组中删掉该跟踪器的回调函数,并且以RCU形式进行同步更新。
b.如果最后一个回调函数也被去除了,那么将jimp指令再重写为nop指令。
这样可以最小化处于禁用状态的跟踪点的性能开销,几乎可以忽略不计。如果asm goto指令不可用,那么会使用以下替代方案:不再用jmp来替换nop,改为使用一个从内存中读取一个变量的状态分支。
通过扩展asm,可以让你在汇编程序中使用C中的变量,并从汇编代码跳转到C语言标号。
goto:该限定符告诉编译器汇编声明中的指令可能会跳转到所列出的跳转标号中去。
2.9.3跟踪点的接口
跟踪点有以下两个接口。
-
基于Ftrace的接口,通过/sys/kernel/debug/tracing/events: 每个跟踪点的系统有一个子目录, 每个跟踪点则对应目录下的一个文件(通过向这些文件中写入内容开启或关闭跟踪点)。
-
perf event_ open(): 这是perf(1) 工具一直以来使用的接口,近来BPF跟踪也开始使用(通过perf_tracepoint PMU)。
2.9.4跟踪点和 BPF
跟踪点为BCC和bpftrace提供了内核的静态插桩支持。接口如下。
- BCC: TRACEPOINT_PROBE()。
- bpftrace:跟踪点探针类型。
在Linux4.7中,BPF支持了跟踪点,但是笔者在此之前已经开发了许多BCC工具, 当时只能使用kprobes。这样一来,BCC中跟踪点的实际应用例子比笔者希望的要少,主要是由于对其的支持加入得比较晚。
BCC中使用跟踪点的一个有趣的例子是tcplife(8)。这个工具会为每个TCP会话打印一行摘要信息,其中包含各种细节信息(这会在第10章详加叙述):

笔者在Linux内核中增加相应的跟踪点支持之前就写完了这个工具,所以当时笔者用了一个tcp_set_state() 内核函数的kprobe,在Linux 4.16中增加了一个合适的跟踪点:sock:inet_ sock_ set_ state。 于是笔者修改了这个工具,使得它能够同时支持两种探针方式,这样无论在新旧内核上就都可以运行了。tcplife(8)这工具定义了两个程序—— 一个使用跟踪点,另一个使用kprobes——然后它会通过下面的测试来决定运行哪一个 :

作为bpftrace使用跟踪点的例子,下面的单行程序会对之前展示过的sched:sched_process_exec 进行插桩:

2.9.5 BPF 原始跟踪点
Alexei Starovoitov开发了一个新的跟踪点接口,叫作BPF_RAW_ TRACEPOINT,于2018年加入Linux4.17。它向跟踪点显露原始参数,这样可以避免因为需要创建稳定的跟踪点参数而导致的开销,因为这些参数可能压根没必要。这有点像以kprobes方式使用跟踪点:最终得到了一个不稳定的API,但是却可以访问更多的字段,也不需要承担跟踪点的性能损失。此种方式相比kprobes更加稳定,因为跟踪点探针的名字是稳定的,不稳定的只是参数。
Alexei用以下压测结果展示说明BPF_RAW_TRACEPOINT的性能要好于kprobes和标准跟踪点:
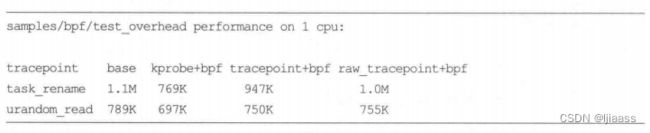
这对于那些需要7X 24小时对跟踪点进行插桩的技术来说尤其有吸引力,可以将开启跟踪点的开销降到最低。
2.9.6扩展阅读
关于跟踪点的更多信息,可以参考内核源代码树下的Documentation/trace/tracepoints.rst文件,作者是Mathieu Desnoyers’
2.10 USDT用户态跟踪点
下图是Sasha Goldshtein

用户态预定义静态跟踪(user-level statically defined tracing, USDT)提供了一个用户空间版的跟踪点机制。BCC的USDT支持是Sasha Goldshtein实现的,bpfrace的USDT支持是由笔者和Matheus Marchini完成的。
用户态的软件有很多与跟踪和日志相关的技术,而且许多应用程序自身也内置了自定义的事件日志系统,可以根据需要随时开启。USDT与众不同之处在于,它依赖于外部的系统跟踪器来唤起。如果没有外部跟踪器,应用中的USDT点不会做任何事,也不会开启。
USDT是随Sun公司的DTrace工具火起来的,现在已经被多种应用程序支持了。Linux对USDT的支持,最早来自SystemTap项目的跟踪器。BCC 和bpftrace跟踪工具建立在上述工作基础之上,两者都支持USDT.
在USDT的使用上,至今尚留有DTrace的痕迹:许多应用默认不开启USDT,显式开启需要使用配置参数–enable-dtrace-probes或者–with-dtrace.
2.10.1添加 USDT探针
给应用程序添加USDT探针,有两种方式可选:通过systermtap-sdt-dev包提供的头文件和工具,或者使用自定义的头文件。这些探针定义了可以被放置在代码中各个逻辑位置上的宏,以此生成USDT的探针。在BCC项目的examples/usdt_ sample目录下包含了USDT示例,这个例子可以使systemtap-sdt-dev头文件,或者使用Facebook的Folly2C++库。下一节笔者将使用Folly完成一个例子。
Folly(Facebook Open Source LibraryFacebook开源库)
使用Folly添加USDT探针的过程如下所述。
- 1.在目标代码中增加头文件:
#include "fol1y/tracing/ StaticTracepoint .h"
- 2.在目标位置增加USDT探针,采用如下格式:
FOLLY_SDT(provider, name, arg1, arg2, ...)
“provider” 对探针进行分类,“name” 是探针的名字,后面是可选的参数。在BCC的USDT代码中包含了:
FOLLY_SDT(usdt_sample_lib1, operation_start, operationId,request_ input().c_str());
这定义了一个usdt sample_ lib1:operation_start 探针,带有两个参数。USDT 例子中同时包含了operatio_end 探针。
- 3.编译软件。你可以使用readelf(1)工具来确认USDT探针是否已经存在:
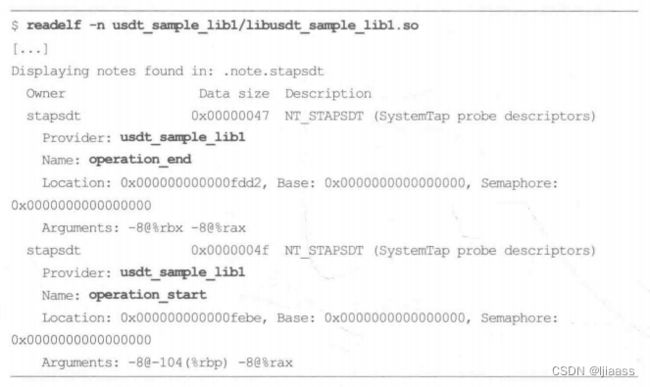
readelf(1)的命令行参数-n打印了notes文件段,在这里显示了编译进去的USDT探针的信息。 - 4.可选步骤:有时你准备添加的参数,在探针的位置处没有现成的,必须使用耗费CPU的函数调用来构建。为了在这些探针未被使用时避免这些调用,可以在函数外面增加一个探针信号量:
FOLLY_SDT_DEFINE SEMAPHORE (provider, name)
然后探针就变成了:

这样昂贵的参数处理只会在探针启用(激活)后才会发生。这个信号量地址可以通过readelf(1)查看,跟踪工具可以在探针启用的时候对它进行设定。
这让跟踪工具变得稍微复杂了一些:当信号量所保护的探针在使用时,这些跟踪工具通常需要指定一个PID,这样才可以设定该PID的信号量。
2.10.2 USDT 是如何工作的
当编译应用程序时,在USDT探针的地址放置了一个nop指令。在插桩时,这个地址会由内核使用uprobes动态地将其修改为一个断点指令。
和uprobes类似,笔者接下来会展示USDT的工作原理,但是我们还要做一些额外的工作。前面readelf(1)的输出中的探针位置是0x6a2。这是二进制段的偏移量,所以必须首先知道二进制段的起始位置在哪里。如果采用了位置无关代码(PIE) 技术,这项技术能够提高地址空间排布随机化(ASLR)的效果,那么这个值可能是变化的。
gdb -p 4777 #调试正在执行中的进程4777

起始地址是0x55a75372a000。打印出起始地址加探针的偏移量( 0x6a2) :

将USDT探针激活之后:


nop指令被修改为int3 (x86_ 64上的断点指令)。当该断点被触发时,内核会执行相应的BPF程序,其中带有USDT探针的参数。当USDT探针被禁用后,nop指令会被替换回来。
2.10.3 BPF 与USDT
USDT为BCC和bpftrace提供了用户态的静态探针支持。接口如下所示。
- BCC : USDT.enable_ probe()。
- bpftrace : USDT探针类型。
举个例子,对前一个例子中的循环探针进行观测:

这个bpfrace单行程序也打印了传递给探针的整数参数。
2.10.4 USDT 的更多信息
以下资料有助于你更深入地理解USDT :
- “Hakcing Linux USDT with Ftrace”, 作者是Brendan Gregg
- “USDT Probe Support in BPF/BCC",作者是Sasha Goldshtein。
- “USDT Tracing Report”,作者是Dale Hamel。
2.11 动态USDT
前面介绍的USDT探针技术,是需要被添加到源代码并编译到最终的二进制文件中的,在插桩点留下nop指令,在ELF notes 段中存放元数据。然而有一些语言,比如Java/JVM,是在运行的时候解释或者编译的。动态USDT可以用来给Java代码增加插桩点。
JVM已经内置在C++代码中,并包含了许多USDT探针——比如对GC事件、类加载,以及其他高级行为。这些USDT探针会对JVM的函数进行插桩。但是USDT探针不能被添加到动态进行编译的Java代码中。USDT需要一个提前编译好的、带一个包含了探针描述的notes段的ELF文件,这对于以JIT方式编译的Java代码来说是不存在的。动态USDT以如下方式解决该问题:
-
预编译一个共享库,带着想要内置在函数中的USDT探针。这个共享库可以用C/C++语言编写,它其中有一个针对USDT探针的ELF notes区域。它可以像其他USDT探针一样被插桩。
-
在需要时,使用dlopen(3)加载该动态库。
-
针对目标语言增加对该共享库的调用。这些可以使用一个适合该语言的API, 以便隐藏底层的共享库调用。
Matheus Marchini 已经为Node,js和Python实现了一个叫作libstapsdt的库,以提供在这些语言中定义和呼叫USDT探针的方法。对其他语言的支持通常可以通过封装这个库实现,比如Dale Hamel就通过使用Ruby的C扩展支持对Ruby进行了支持。
举个例子,在Nodejs中运行如下JavaScript代码: .

probe1.fire()调用只有在外部发起对探针的插桩时,才会执行它的匿名函数。在这个函数中,参数在传递到探针之前被处理( 如果必要的话),同时不必担心探针不启用时会产生参数处理的CPU开销,因为探针未启用时这步直接被跳过了。
libstapsdt会在运行时自动创建包含USDT探针和ELF notes 区域的共享库,而且它会将这些区域映射到运行着的程序的地址空间。
2.12 性能监控计数器
性能监控计数器(Performance monitoring counter, PMC) 还有其他一些名字,比如:
性能观测计数器( Performance instrumentation counter,PIC)、
CPU性能计数器(CPUPerformance Counter, CPC)、
性能监控单元事件(performance monitoringunit event,PMU event)。
这些名词指的都是同一个东西:处理器上的硬件可编程计数器。
PMC数量众多,Intel 从中选择了7个作为“架构集合”,这些PMC会对一些核心功能提供全局预览。可以使用CPUID指令来确认这些“架构集”PMC是否存在于当前处理器中。表2-8 列出了这个集合,其可作为有用的PMC的例子。
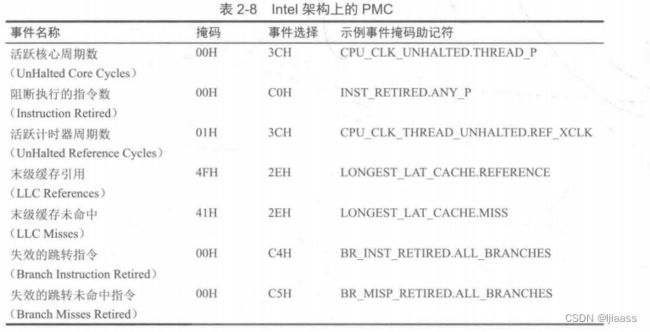
PMC是性能分析领域至关重要的资源。只有通过PMC才能测量CPU指令执行的效率、CPU缓存的命中率、内存/数据互联和设备总线的利用率,以及阻塞的指令周期等。在性能分析方面使用这些方法可以进行各种细微的性能优化。
不过PMC这个资源也有些奇怪。尽管有数百个可用的PMC,但任一时刻在CPU中只允许固定数量的寄存器(可能只有6个)进行读取。在实现中需要选择通过这6个寄存器来读取哪些PMC,或者可以以循环采样的方式覆盖多个PMC集合(Linux 中的perf()工具可以自动支持这种循环采样)。其他软件类计数器则没有这种限制。
2.12.1 PMC 的模式
PMC可以工作在下面两种模式中。
- 计数:在此模式下,PMC能够跟踪事件发生的频率。只要内核有需要,就可以随时读取,比如每秒获取1次。这种模式的开销几乎为零。
- 溢出采样:在此模式下,PMC在所监控的事件发生到一定次数时通知内核,这样内核可以获取额外的状态。监控的事件可能会以每秒百万、亿级别的频率发生,如果每次事件都进行中断会导致系统性能下降到不可用。解决方案是利用一个可编程的计数器进行采样,具体来说,是当计数器溢出时就向内核发信号(比如,每10000次LLC缓存未命中事件,或者每100万次阻塞的指令时钟周期)。
采样模式对BPF跟踪来说更值得关注,因为它产生的事件给BPF程序提供了执行的时机。BCC和bpfrace都支持PMC事件跟踪。
2.12.2 PEBS
由于存在中断延迟(通常称为“打滑”)或者乱序执行,溢出采样可能不能正确地记录触发事件发生时的指令指针。对于CPU周期性能分析来说,这类“打滑”可能不是什么问题,而且有些性能分析器会故意在采样周期中引入一些微小的不规则性,避免锁步采样(lockstep sampling) (或者使用一个自带偏移量的采样频率,例如,99Hz)。但是对于测量另外一些事件来说,比如LLC的未命中率,这些采样的指令指针就必须是精确的。
Intel开发了一种解决方案,叫作精确事件采样(precise event-based sampling,PEBS)。PEBS 使用硬件缓冲区来记录PMC事件发生时正确的指令指针。Linux 的perf_events框架机制支持PEBS。
2.12.3云计算
许多云计算环境不提供对虚拟机上的PMC访问请求。这在技术上是有可能开启它的,比如,Xen 虚拟化内核中提供了vpmu命令行选项,可以支持将不同的PMC显露给客体机器(5]。1 Amazon公司也对其Nitro虚拟化主机开启了许多PMC支持。
2.13 perf_events
perf_ events 是perf(1)命令所依赖的采样和跟踪机制,它于2009年被加入Linux 2.6.31版本。值得一提的是,近些年来,perf(1) 和perf events 机制得到了很多关注和研发投入,现在BPF跟踪工具可以调用perf events 来使用它的特性。BCC和bpfrace先是使用perf_ events 作为它们的环形缓冲区,然后又增加了对PMC的支持,现在又通过perf_event_open()来对所有的事件进行观测。
在BPF跟踪工具使用perf(1)的时候,perf(1) 也开发了一个使用BPF的接口,这就让perf(1)成为又一个BPF跟踪器。与BCC和bpftrace不同,perf(1) 的代码位于Linux内核代码树中,因此,perf(1) 也是唯一内置在Linux中的BPF前端。
perf(1)的BPF功能还在不断开发中,目前在使用上还有一些不方便的地方。相关内容超出了本书的范围,因为本书聚焦在BCC和bpfrace工具上。附录D中有一个关于perf BPF的例子。