Qt—正则表达式
前面的章节中已经接触过了正则表达式,如3.3.3小节中的行编辑器进行输人验证和5.2.5小节中实现编辑器的语法高亮。
正则表达式(regular expression)就是在一个文本中匹配子字符串的一种模式(pattern) ,它可以简写为regexp。一个regexp 主要应用在以下几个方面:
➢验证。regexp可以测试一个子字符串是否符合一些规范。例如,是否是一个整数或者不包含任何空格等。
➢搜索。regexp提供了比简单的子字符串匹配更强大的模式匹配。例如,匹配单词mail或者letter, 而不匹配单词email、mailman或者letterbox。
➢查找和替换。regexp可以使用一个不同的字符串替换所有匹配的子字符串。例如,使用Mail来替换一个字符串中所有的M字符,但是M字符后面有ail 时则不进行替换。
➢字符串分割。regexp可以识别在哪里进行字符串分割。例如,分割制表符隔离的字符串。
Qt中的QRegExp类实现了使用正则表达式进行模式匹配。QRegExp是以Perl的正则表达式语言为蓝本的,它完全支持Unicode。QRegExp中的语法规则可以使用setPatternSyntax()函数来更改。
正则表达式介绍
Regexps由表达式( expressions)、量词(quantifiers)和断言(assertions)组成。最简单的一个表达式就是一个字符,比如x和5。而一组字符可以使用方括号括起来,例如,[ABC]将会匹配一个A或者一个B或者一个C,这个也可以简写为[A -C],这样若要匹配所有的英文大写字母,就可以使用[A- Z]。
一个量词指定了必须要匹配的表达式出现的次数。例如,x{1,1}意味着必须匹配且只能匹配一个字符x,而x{1,5}意味着匹配一列字符x,其中至少要包含一个字符x,但是最多包含5个字符x。
现在假设要使用一个regexp 来匹配0~ 99之间的整数。因为至少要有一个数字,所以使用表达式[0-9]{1,1}开始,它匹配一个单一的数字一次。要匹配0~99,则可以想到将表达式最多出现的次数设置为2,即[0-9]{1,2}。现在这个regexp已经可以满足我们假设的需要了,不过,它也会匹配出现在字符串中间的整数。如果想匹配的整数是整个字符串,那么就需要使用断言“^”和 $ ,当 ^在regexp中作为第一个字符时,意味着这个regexp必须从字符串的开始进行匹配;当“$”在regexp中作为最后一个字符时,意味着regexp必须匹配到字符串的结尾。所以,最终的regexp为
“^ [0 -9]{1,2} $”。一般可以使用一些特殊的符号来表示一些常见的字符组和量词。例如,[0-9] 可以使用“\d”来替代。而对于只出现一-次的量词{1,1} ,则可以使用表达式本身代替,
例如,x{1,1}等价于x。所以要匹配0~99,就可以写“\d{1,2} $”或者”“\d\d{0,1} $”。而{0,1}表示字符是可选的,就是只出现一次或者不出现,它可以使用“?”来代替,这样regexp就可以写为“\d\d? $”,它意味着从字符串的开始,匹配一个数字,紧接着是0个或一个数字,再后面就是字符串的结尾。
现在写一个regexp来匹配单词mail或者letter其中的一个,但是不要匹配那些包含这些单词的单词,比如email 和letterbox。要匹配mail,regexp可以写成m{1,1}a
{1,1}i{1,1}H{1,1} ,因为{1,1}可以省略,所以又可以简写成mail。下面就可以使用竖线“|”来包含另外-一个单词,这里“|”表示“或”的意思。为了避免regexp匹配多余的单词,必须让它从单词的边界进行匹配。首先,将regexp用括号括起来,即(mail|letter)。括号将表达式组合在一起,可以在一个更复杂的regexp中作为一个组件来使用,这样也可以方便我们检测到底是哪一个单词被匹配了。为了强制匹配的开始和结束都在单词的边界上,就要将regexp包含在“\b"单词边界断言中,即“\b(maillletter)\b”。这个“\b"断言在regexp中匹配一个位置,而不是一个字符,一个单词的边界是任何的非单词字符,如一个空格、新行、或者一个字符串的开始或者结束。如果想使用一个单词,如Mail,替换一个字符串中的字符M,但是当字符M的后面是ail的话就不再替换。这样可以使用(?!E)断言,例如,这里regexp应该写成M(?! Mail)。如果想统计Eric和Eirik在字符串中出现的次数,则可以使用\b(EriclEirik)\b或者\bEi?ri[ck]\b。这里需要使用单词边界断言‘\b’来避免匹配那些包含了这些名字的单词。
下面例子,因为在c++中.\是转义字符,所以在regexp中使用它时候,需要再转义一次,比如使用"\d"就应该写成"\ \d";二如果要使用\本身,就要写成"\ \ \ \ "
新建Qt Widgets 应用,项日名称为myregexp,基类选择QWidget,类名保持Widget不变。建好项目后,首先在
widget.cpp文件中添加头文件井include< QDebug>,然后在构造函数中添加如下代码:
QRegExp rx("^\\d\\d?$"); // 两个字符都必须为数字,第二个字符可以没有
qDebug() << rx.indexIn("a1"); // 结果为-1,不是数字开头
qDebug() << rx.indexIn("5"); // 结果为0
qDebug() << rx.indexIn("5b"); // 结果为-1,第二个字符不是数字
qDebug() << rx.indexIn("12"); // 结果为0
qDebug() << rx.indexIn("123"); // 结果为-1,超过了两个字符
qDebug() << "*******************"; // 输出分割符,为了显示清晰
rx.setPattern("\\b(mail|letter)\\b"); // 匹配mail或者letter单词
qDebug() << rx.indexIn("emailletter"); // 结果为-1,mail不是一个单词
qDebug() << rx.indexIn("my mail"); // 返回3
qDebug() << rx.indexIn("my email letter"); // 返回9
qDebug() << "*******************";
rx.setPattern("M(?!ail)"); // 匹配字符M,其后面不能跟有ail字符
QString str1 = "this is M";
str1.replace(rx, "Mail"); // 使用"Mail"替换匹配到的字符
qDebug() << "str1: " << str1; // 结果为this is Mail
QString str2 = "my M,your Ms,his Mail";
str2.replace(rx,"Mail");
qDebug() << "str2: " << str2; // 结果为my Mail,your Mails,his Mail
qDebug() << "*******************";
QString str3 = "One Eric another Eirik, and an Ericsson. "
"How many Eiriks, Eric?"; // 一个字符串如果一行写不完,换行后两行都需要加双引号
QRegExp rx2("\\bEi?ri[ck]\\b"); // 匹配Eric或者Eirik
int pos = 0;
int count = 0;
while (pos >= 0) {
pos = rx2.indexIn(str3, pos);
if (pos >= 0) {
++pos; // 从匹配的字符的下一个字符开始匹配
++count; // 匹配到的数目加1
}
}
qDebug() << "count: " << count; // 结果为3
这里使用了QRegexp的indexIn()函数,它从指定的位置开始向后对字符串进行匹配,默认是从字符串开始进行匹配。如果匹配成功,则返回第一个匹配到的位置的索
引;如果没有匹配到,则返回-1。setPattern()函数用来输人一个regexp。而QString的replace()函数可以使用给定的regexp和替换字符来进行字符串的替换。
正则表达式组成元素
前面已经提到,一个正则表达式regexp由表达式、量词和断言组成,其中的表达式可以是各种字符和字符组,而一些常用的字符集可以使用一些缩写来表示,如表所列。


字符集还有两个特殊的符号“^”和“-”,其中“ ^"在方括号的开始可以表示相反的意思,例如,[ ^ abc]表示匹配任何字符,但是不匹配a或b或c。而“-”可以表示一个范围的字符,例如,[W- Z]表示匹配W或者X或者Y或者Z。
默认的,一个表达式将自动量化为{1,1},就是说它应该出现一次。
表列出了量词的使用情况,其中,E代表一个表达式,一个表达式可以是一个字符,或者一个字符集的缩写,或者在方括号中的一个字符集,或者在括号中的一个表达式。
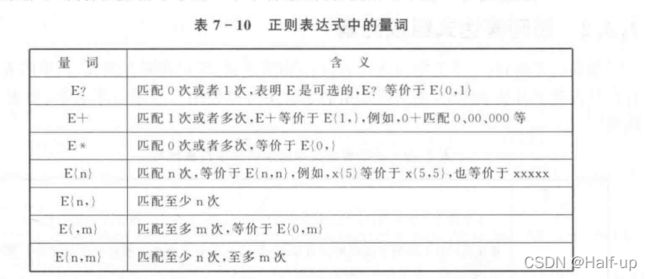
在使用量词时要注意,tag+表示匹配一个t跟着一个a,然后跟着至少一个g。而(tag)+表示匹配tag至少一次。还要说明的是,量词一般是“贪婪的(greedy)”,它会尽可能多地去匹配可以匹配的文本,例如,0+匹配它发现的第一个0及其随后所有连续的0,当应用到字符串20005时,它会匹配其中的3个0。要使量词变得“非贪婪(nongreedy)”,则可以使用setMinimal(true),这样在上面的例子中就会只匹配第一个0。
断言在regexp中做出一些有关文本的声明,它们不匹配任何字符。正则表达式中的断言如表所示,其中,E代表一个表达式。

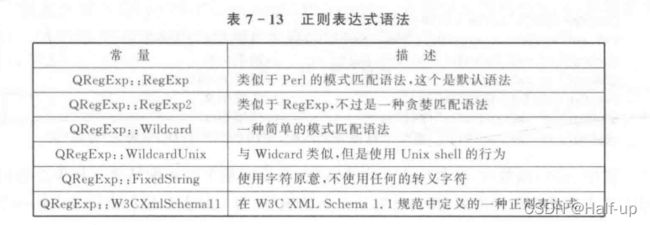
QRegExp类还支持通配符(Wildcard)匹配。很多命令shell(例如bash和cmd.exe)都支持文件通配符(file globbing),可以使用通配符来识别一组文件。QRegExp 的setPatternSyntax()函数就是用来在regexp和通配符之间进行切换的。通配符匹配要比regexp简单很多,它只有4个功能,如表所列。

例如:要匹配所有.txt类型的文件,那么可以在前面的程序中添加如下代码来实现:
QRegExp rx3("*.txt");
rx3.setPatternSyntax(QRegExp::Wildcard);
qDebug() << rx3.exactMatch("README.txt"); // 结果为true
qDebug() << rx3.exactMatch("welcome.txt.bak"); // 结果为false
除了通配符,QRegExp还支持其他一些语法,如表所示。这些语法都可以使用setPatternSyntax()函数来切换
文本捕获
在regexp中使用括号可以使一些元素组合在一起,这样既可以对它们进行量化,也可以捕获它们。例如,使用表达式mail|letter 来匹配一个字符串,知道有一个单词被匹配了,但是却不能知道具体是哪一个,使用括号就可以捕获被匹配的那个单词,比如使用(mail|letter)来匹配字符串“I Sent you some email”,这样就可以使用cap()或者capturedTexts()函数来提取匹配的字符。还可以在regexp中使用捕获到的文本,为了表示捕获到的文本,使用反向引用“\n”,其中n从1开始编号,比如“\1”表示前面第一个捕获到的文本。例如,使用“\b(\w+)\W+\1\b”在一个字符串中查询重复出现的单词,这意味着先匹配一个单词边界,随后是一个或者多个单词字符,随后是一个或者多个非单词字符,随后是与前面第一个括号中相同的文本,随后是单词边界。
如果使用括号仅仅是为了组合元素而不是为了捕获文本,那么可以使用非捕获语法,如“(?:green /blue)”。非捕获括号由“(?”开始,由“)”结束。使用非捕获括号比使用捕获括号更高效,因为regexp引擎只须做较少的工作。
QRegExp rx4("(\\d+)");
QString str4 = "Offsets: 12 14 99 231 7";
QStringList list;
int pos2 = 0;
while ((pos2 = rx4.indexIn(str4, pos2)) != -1) {
list << rx4.cap(1); // 第一个捕获到的文本
pos2 += rx4.matchedLength(); // 上一个匹配的字符串的长度
}
qDebug() << list; // 结果12,14,99,231,7
QRegExp rxlen("(\\d+)(?:\\s*)(cm|inch)");
int pos3 = rxlen.indexIn("Length: 189cm");
if (pos3 > -1) {
QString value = rxlen.cap(1); // 结果为189
QString unit = rxlen.cap(2); // 结果为cm
QString string = rxlen.cap(0); // 结果为189cm
qDebug() << value << unit << string;
}
QRegExp rx5("\\b(\\w+)\\W+\\1\\b");
rx5.setCaseSensitivity(Qt::CaseInsensitive); // 设置不区分大小写
qDebug() << rx5.indexIn("Hello--hello"); // 结果为0
qDebug() << rx5.cap(1); // 结果为Hello
QRegExp rx6("\\b你好\\b"); // 匹配中文
qDebug() << rx6.indexIn("你好"); // 结果为0
qDebug() << rx6.cap(0); // 整个字符串完全匹配,使用cap(0)捕获,结果为“你好”
使用cap()函数时,参数0表示完全匹配,会返回整个的匹配结果。如果想返回括号中子表达式的匹配结果,那么就要从1开始编号,为1时表示最左边括号中第一个匹配到的结果。
讲解行编辑器的输人验证时,使用了验证器QValidator类,当时也提到了QRegExpValidator类,它是基于正则表达式的验证器。QRegExpValidator使用一个regexp来决定一个输入的字符串是否是可以接受的(Acceptable),无效的(Invalid).在两者之间的(Intermediate)。
新的QRegularExpression类
Qt 5中引入了新的QRegularExpression类,实现了与Perl兼容的正则表达式,并在QRegExp基础上进行了很大的改进。建议编写Qt 5程序时使用QRegularExpression来代替QRegExp。
在QRegularExpression中,一个正则表达式由两部分构成:一个模式字符串和一组模式选项,模式选项用来更改模式字符串的含义。可以在构造函数中直接设置模式字符串:
QRegularExpression re("a pattern");
也可以使用setPattern为已有的QRegularExpression对象设置模式字符串:
QRegularExpression re;
re.setPattern("another pattern");
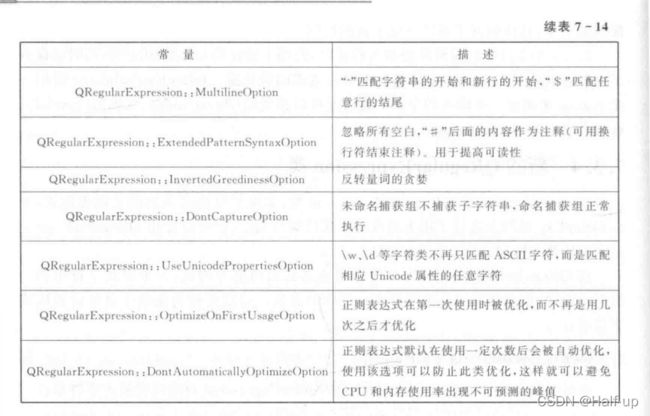
可以通过pattern()来获取已设置的模式字符串。QRegularExpression中通过模式选项来改变模式字符串的含义,例如,可以通过设置QRegularExpression::CaseInsensitiveOption使匹配时不区分字母大小写:
QRegularExpression re("Qt rocks",QRegularExpression::CaseInsensitiveOption);
这时候除了匹配Qt rocks,还会匹配QT rocks、QT ROCKS、QT rOcKs等字符串。
也可以通过setPatternOptions()来设置模式选项,通过patternOptions()来获取设置的模式选项:
QRegularExpression re("^\\d +$");
re.setPatternOptions(QRegularExpression::MultilineOption);
QRegularExpression::patternOptions options=re.patternOptions();
模式选项由QRegularExpression::PatternOption枚举类型进行定义,其取值如表所示。这些选项可以按位或操作联合使用
下面新建一个项目myregularexpression,在构造函数中:
QRegularExpression re("^(\\d\\d)/(\\d\\d)/(\\d\\d\\d\\d)$");
QRegularExpressionMatch match = re.match("08/12/1985");
if (match.hasMatch()) {
QString matched = match.captured(0);
QString day = match.captured(1);
QString month = match.captured(2);
QString year = match.captured(3);
qDebug() << "matched: " << matched << endl
<< "day: " << day << endl
<< "month: " << month << endl
<< "year: " << year;
可以使用match()函数进行匹配,返回值为QRegularExpressionMatch类对象。QRegularExpressionMatch类提供了正则表达式的匹配结果,可以通过hasMatch()来判断匹配是否成功。如果匹配成功,则可以使用captured()返回模式字符串中捕获组(模式字符串中每组小括号表示一个捕获组)捕获的子字符串,捕获组从1开始编号。
例如,这里的“(\d\d)/(\d\d)/(\d\d\d\d)”就是3个捕获组﹐编号分别是1,2,3,还有一个隐式捕获组,其编号为0,它捕获整个正则表达式完全匹配的结果。另外,如果是部分匹配成功,则可以使用hasPartialMatch()来判断。继续在构造函数中
QString pattern("^(Jan|Feb|Mar|Apr|May) \\d\\d?, \\d\\d\\d\\d$");
QRegularExpression re1(pattern);
QString input("Jan 21,");
QRegularExpressionMatch match1 = re1.match(input, 0, QRegularExpression::PartialPreferCompleteMatch);
bool hasMatch = match1.hasMatch();
bool hasPartialMatch = match1.hasPartialMatch();
qDebug() << "hasMatch: " << hasMatch << "hasParticalMatch: " << hasPartialMatch;
这里使用match函数的另外二个参数,第2个参数用来设置偏移量,例如:
QRegularExpression re("\\d\\d\\w+");
QRegularExpression match=re.match("12 abc 45 def",1);
会从“12 abc”之后进行匹配,因为设置了偏移量为1,所以会跳过第一个匹配到的字符串。
第3个参数用来设置匹配类型,这里使用QRegularExpression: : PartialPreferCompleteMatch来进行部分匹配,但是如果发现了完全匹配,那么会返回完全匹配到的字符串;QRegularExpression ::PartialPreferFirstMatch 也可以用来进行部分匹配,会返回第一个匹配到的部分匹配字符串并停止继续匹配;如果想使用正常的匹配,那么可以设置QRegularExpression : : NormalMatch。
正则表达式的学习较为困难复杂,可以参考《Qt 及 Qt Quick开发实战精解(第⒉版)》中的音乐播放器实例进行歌词文件的解析就使用了正则表达式,可以参考一下。正则表达式的内容可以查看QRegExp和QRegularExpression的参考文档。